本文主要是介绍Eland上传bge-base-zh-v1.5向量化模型到ElasticSearch中,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近需要做一些向量检索,试试ES
一、准备
系统:MacOS 14.3.1
ElasticSearch:8.13.2
Kibana:8.13.2
本地单机环境,无集群,也不基于Docker
BGE是一个常见的文本转向量的模型,在很多大模型RAG应用中常常能见到,但是ElasticSearch中默认没有。BGE模型有很多版本,本次采用的是bge-base-zh-v1.5。下载地址:
HuggingFace:https://huggingface.co/BAAI/bge-base-zh-v1.5
Modelscope:魔搭社区
在国内的话还是从modelscope上下载会更快一些:
git lfs install
git clone https://www.modelscope.cn/AI-ModelScope/bge-large-zh-v1.5.git下载完后有如下文件(注:可以把其中的.git文件夹删掉以减少体积):
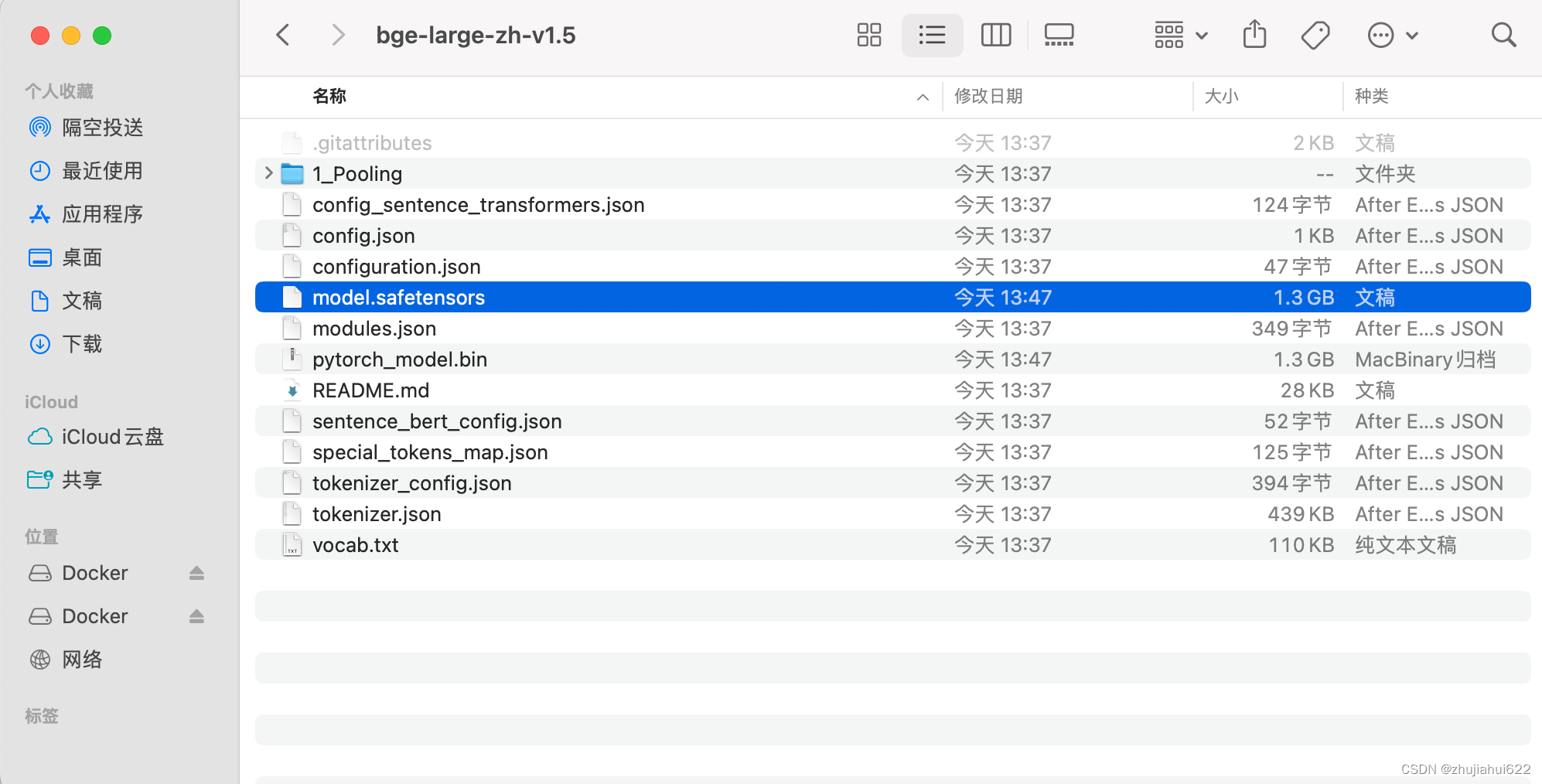
将下载好的文件放到用户当前目录下。
二、Kibana申请试用【机器学习】
导入其他模型必须要使用ES的Machine Learning(机器学习)功能,该功能是收费的,白金版才能使用,因此需要先点击【试用】,试用没有任何复杂的操作和套路,直接点击就行(试用期限为一个月)。
点【模型管理】->【已训练模型】,初始状态下内置以下几个模型:

三、安装Eland工具上传模型
新建终端,安装Eland
pip install eland安装完后直接运行以下命令:
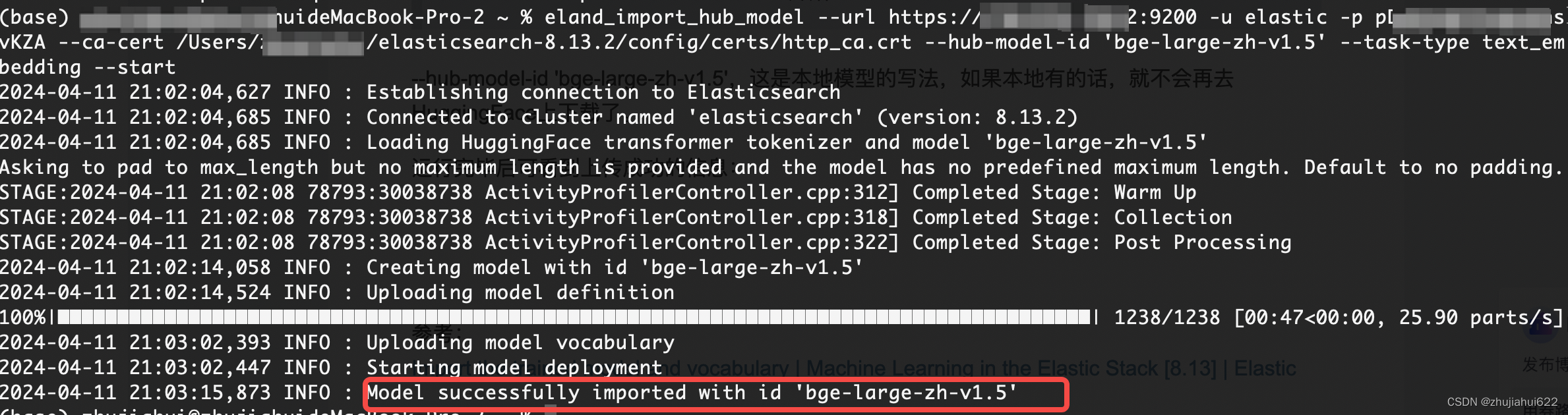
eland_import_hub_model --url https://XX.XXX.XXX.XXX:9200 -u elastic -p XXXXXXXXX --ca-cert /Users/XXXXXXX/elasticsearch-8.13.2/config/certs/http_ca.crt --hub-model-id 'bge-large-zh-v1.5' --task-type text_embedding --start换行模式:
eland_import_hub_model --url https://XX.XXX.XXX.XXX:9200 \
-u elastic -p XXXXXXXXX \
--ca-cert /Users/XXXXXXX/elasticsearch-8.13.2/config/certs/http_ca.crt \
--hub-model-id 'bge-large-zh-v1.5' \
--task-type text_embedding \
--start逐行解释:
eland_import_hub_model -- 上传本地或HuggingFace模型到ES中
--url https://XX.XXX.XXX.XXX:9200 --指定ES地址,注意:用https,且尽量用真实的IP地址,不要用localhost
-u elastic -p XXXXXXXXX --指定用户名和密码
--ca-cert /Users/XXXXXXX/elasticsearch-8.13.2/config/certs/http_ca.crt --指定证书路径
--hub-model-id 'bge-large-zh-v1.5' --指定上传的模型的本地路径,注意:前面不要带/
--task-type text_embedding --指定上传的模型的类型,BGE是一个embedding模型
--start --开始
--hub-model-id 'bge-large-zh-v1.5',这是上传本地模型的写法,如果本地有的话,就不会再去HuggingFace上下载了,免得需要科学上网不好办。
运行完毕后可看到上传成功的信息:
----------------------------------------------------------
注意事项:
实际不会像上面一样一帆风顺,运行eland_import_hub_model这一步可能会出现若干问题,往往会令人抓狂,网上相关的资料也比较少。笔者遇到了如下几个问题:
问题1. zsh: no matches found: XXXXX

解决方案:
打开.zshrc
vi ~/.zshrc添加以下内容:
setopt no_nomatch:wq保存后,再运行以下命令生效:
source ~/.zshrc问题2:出现elastic_transport.ConnectionError
具体报错信息:
elastic_transport.ConnectionError: Connection error caused by: ProtocolError(('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')))
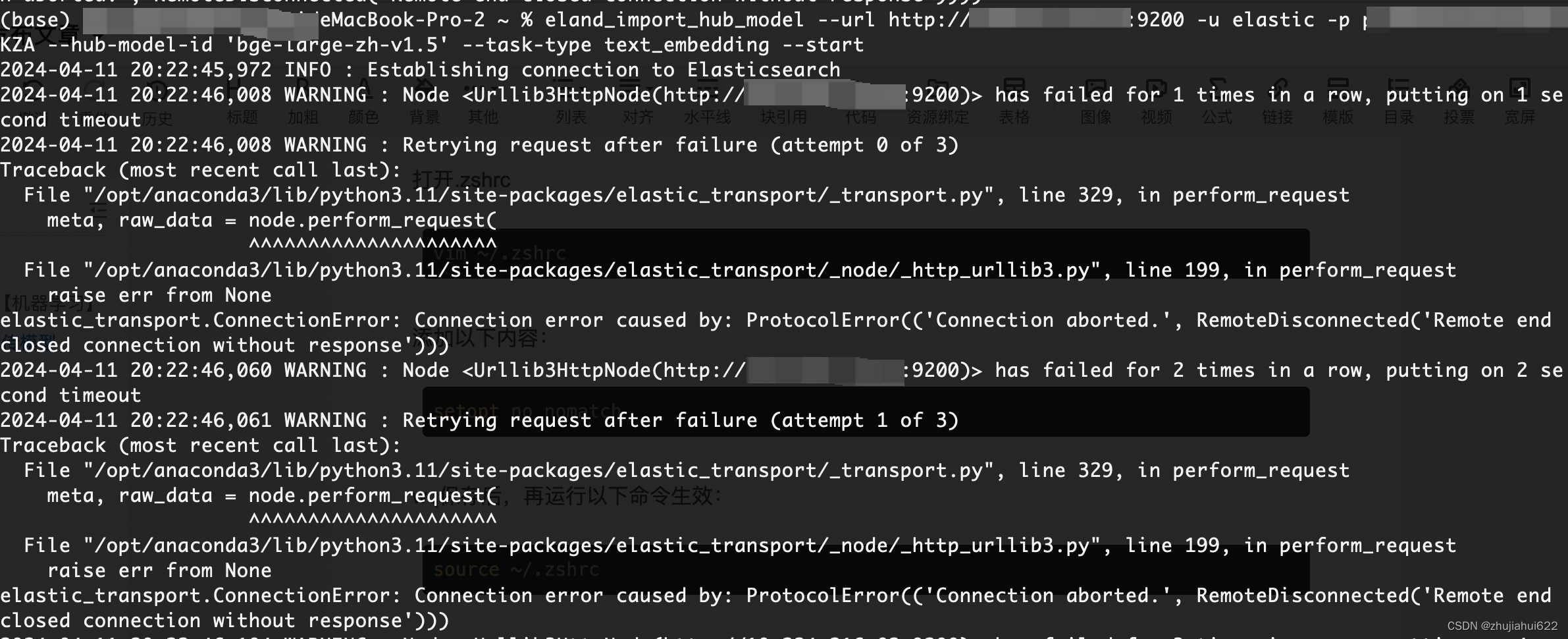
这个问题是最复杂的,网上找了很久都没有解决方案。
原因:因为要使用机器学习的功能,开了试用,必须配置x-pack,因此也必须要在用Eland传输数据时指定安全证书。因为官网的Eland示例里是不包含证书的,因此一直都没注意到,直到看到这篇文章后才意识到是证书的问题:使用 Elasticsearch 检测抄袭 (二)。
解决方案:
x-pack的配置在elasticsearch.yml中,这两行默认都是true,不用更改。
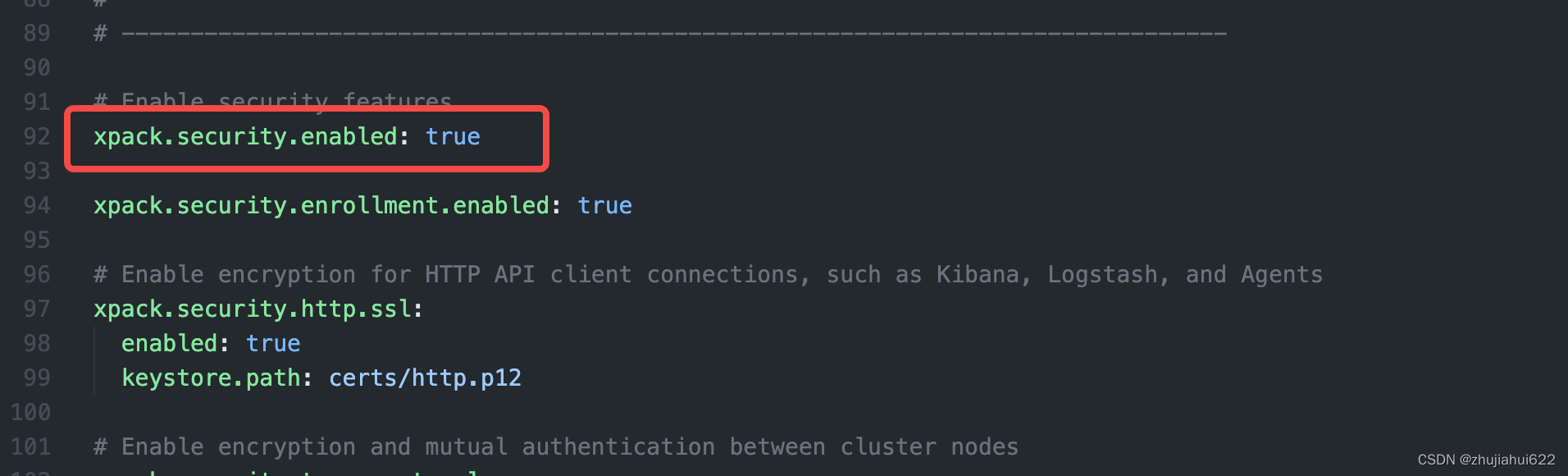
指定证书:
--ca-cert /Users/XXXXXXX/elasticsearch-8.13.2/config/certs/http_ca.crt
注意注意:此时千万不要随便瞎改elasticsearch.yml和kibana.yml中的其他配置。
问题3:ValueError: TLS options require scheme to be 'https'
raise ValueError("TLS options require scheme to be 'https'")
ValueError: TLS options require scheme to be 'https'
原因:--url http://XX.XXX.XXX.XXX:9200的URL中没有用https。
解决方案:URL改为用https即可。
参考:Import the trained model and vocabulary | Machine Learning in the Elastic Stack [8.13] | Elastic
四、Kibana中查看
至此模型已经上传成功,启动或刷新Kibana,在其中查看。
点到【模型管理】->【已训练模型】,发现有如下信息(提示:需要同步 ML 作业和已训练模型):
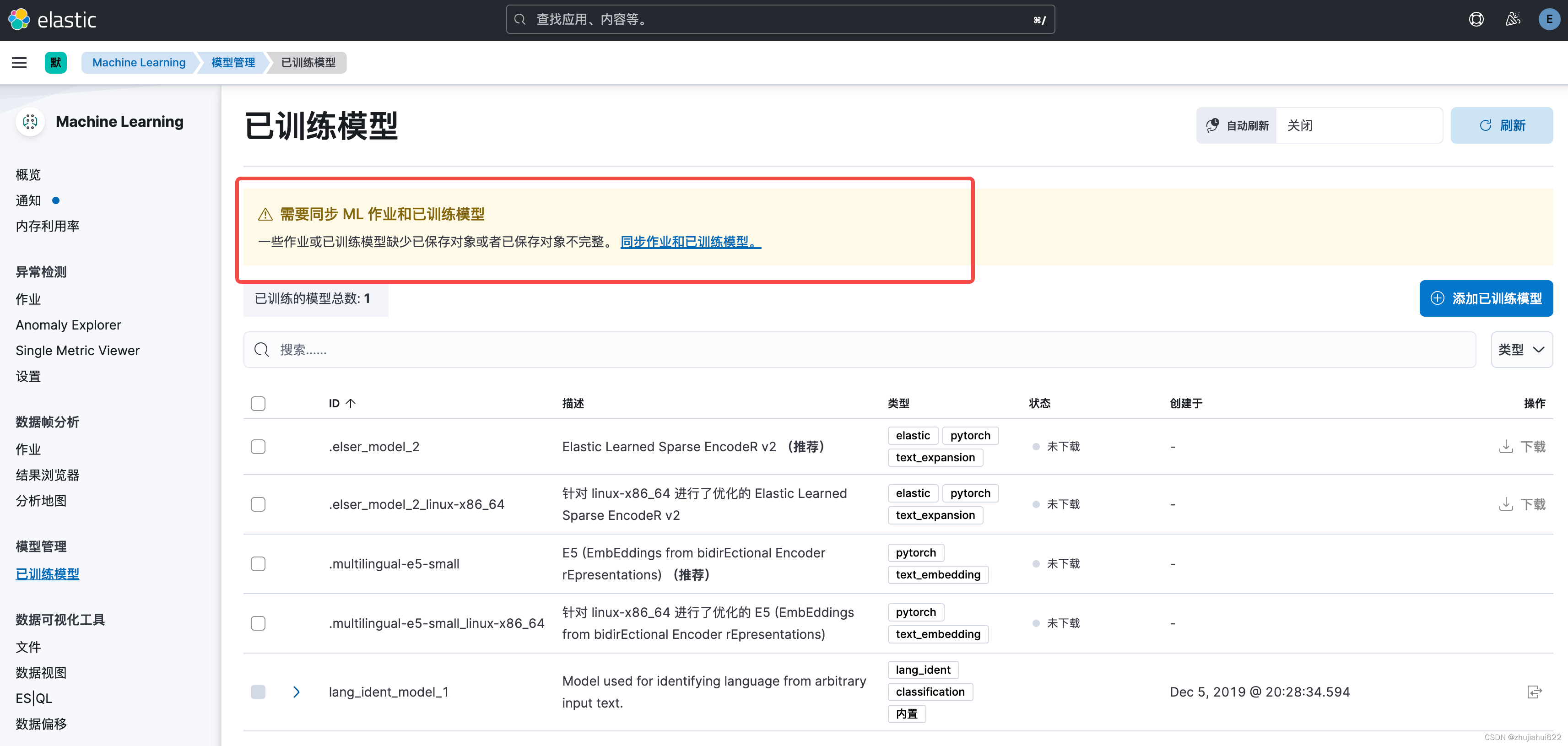
点击【同步作业和已训练模型】->【同步】
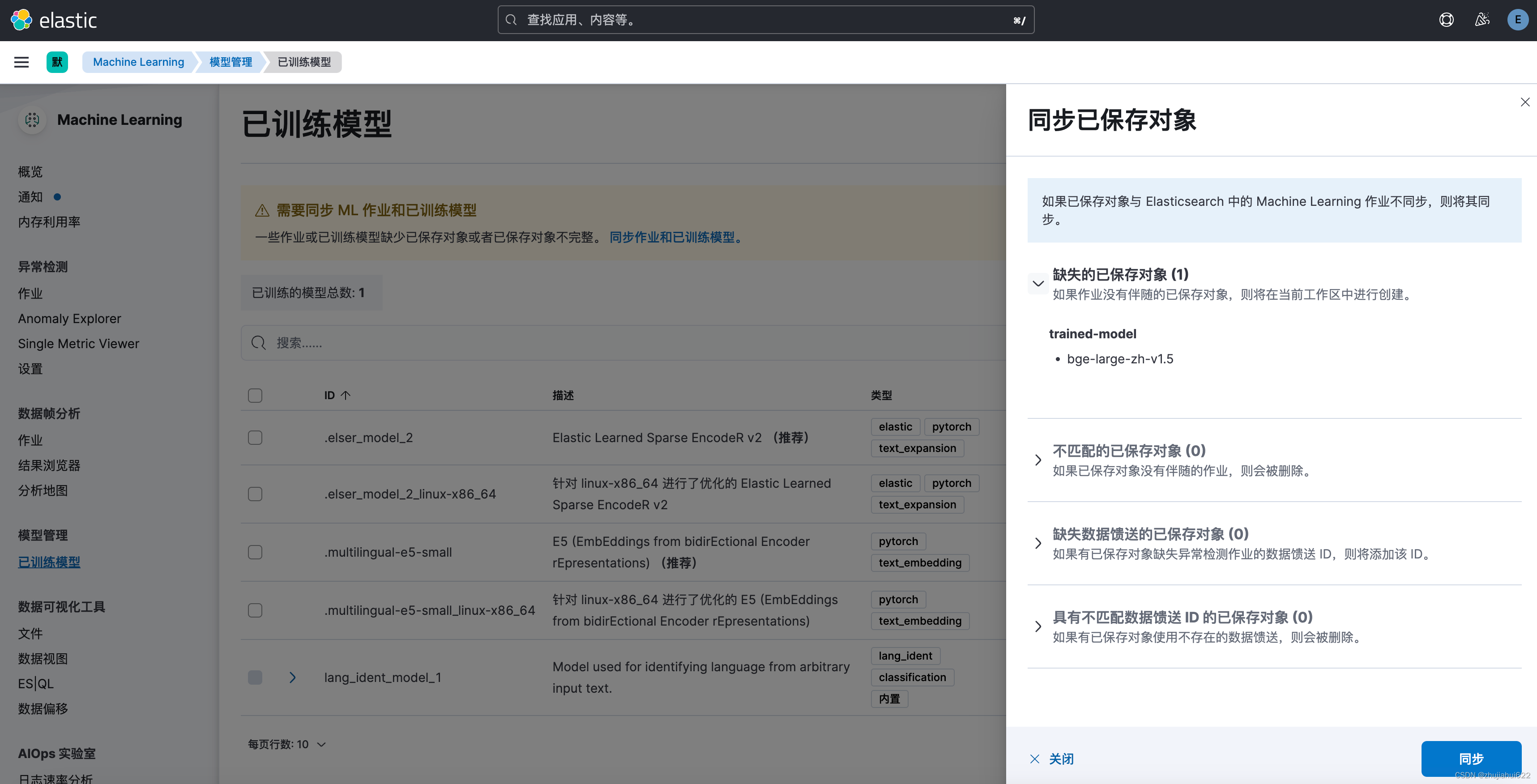
同步完后即可看到多了一行,显示状态为“已部署”:
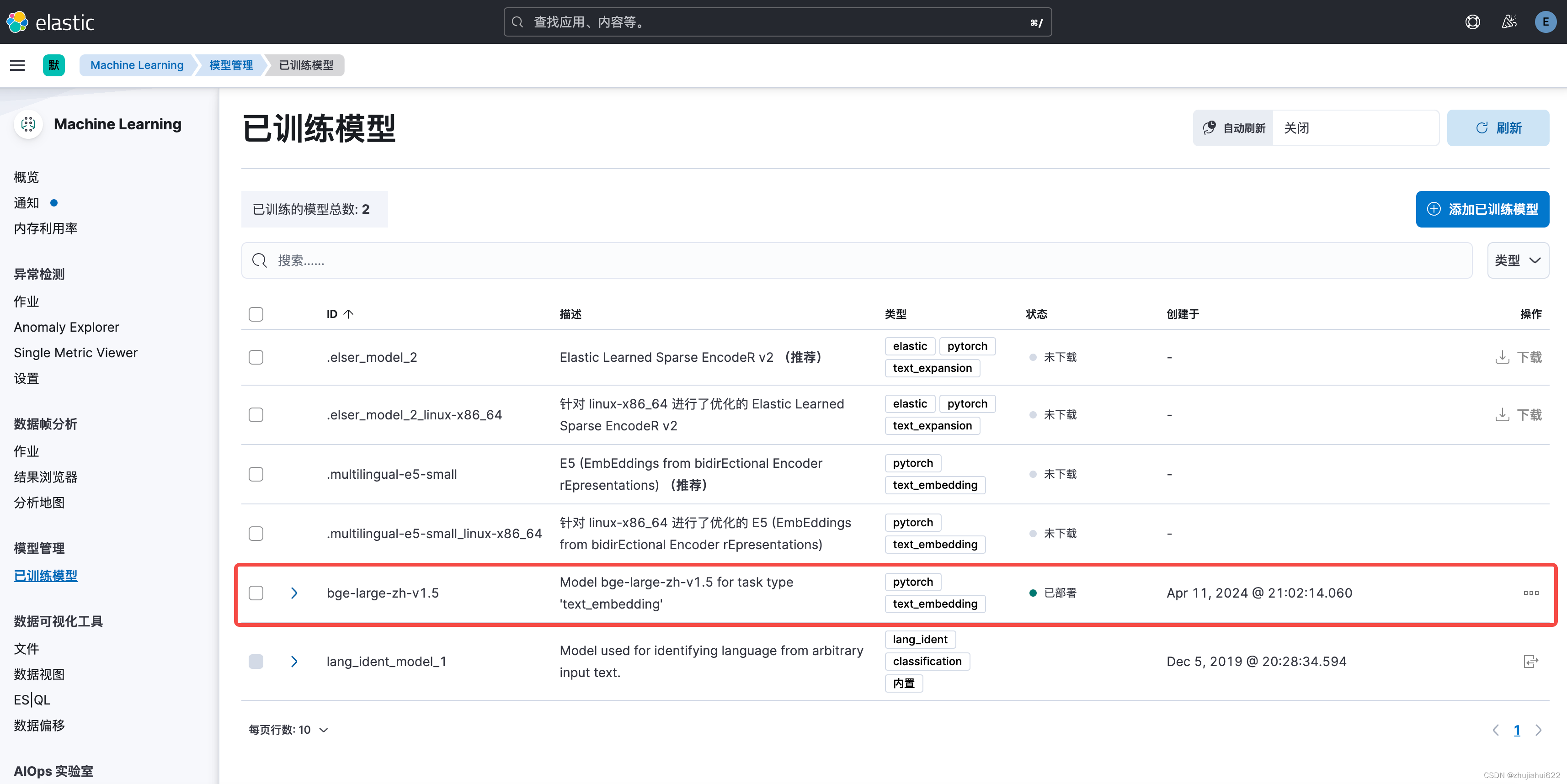
~~至此,bge-base-zh-v1.5模型已成功导入ES,待后续使用啦~~
-----------------------------------------------------------------------------------------------------------
五、其他错误的尝试
本来想看能不能不用Eland,直接把模型放到一个固定的路径下,让ES启动时去加载,也就是采用file-based上传的方式,实际不太行。
参考:ELSER – Elastic Learned Sparse EncodeR | Machine Learning in the Elastic Stack [8.13] | Elastic
切换到elasticsearch-8.13.2/config目录下,新建models文件夹
把下载好的bge模型整个放到models下
编辑elasticsearch-8.13.2/config下的elasticsearch.yml文件,增加一行并保存:
xpack.ml.model_repository: file://${path.home}/config/models/重启ES和Kibana,发现【模型管理】->【已训练模型】下啥都没变化。
这篇关于Eland上传bge-base-zh-v1.5向量化模型到ElasticSearch中的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






