本文主要是介绍[论文笔记]BGE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
今天介绍论文BGE,是智源开源的语义向量模型,BAAI General Embedding。
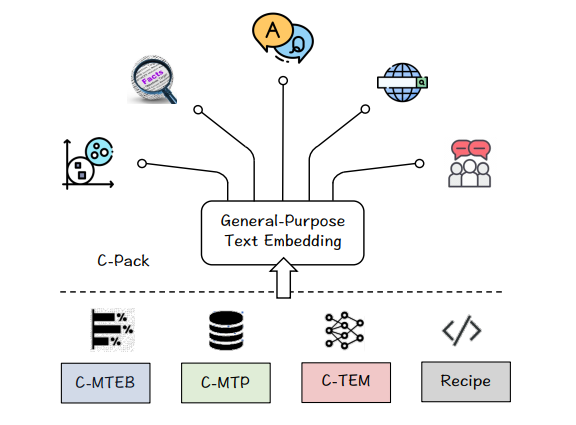
作者发布了C-Pack,一套显著推进中文嵌入领域的资源包。包括三个重要资源: 1) C-MTEB是一个全面的中文文本嵌入基准,涵盖了6个任务和35个数据集。 2) C-MTP是一个从标记和未标记的中文语料库中选择的大规模文本嵌入数据集。 3) C-TEM是一个覆盖多种规模的嵌入模型系列。
作者提出的BGE在C-MTEB上的表现超过了先前所有的中文文本嵌入模型,还整合和优化了C-TEM的整套训练方法。
总体介绍
文本嵌入是NLP中一个长期的主题。广泛的应用场景需要一个统一的嵌入模型,能在任何应用场景下处理各种任务。比如,问答、语言建模、对话等。然而,学习通用文本嵌入比任务专一的文本嵌入具有更多的挑战,在于:
- 数据 开发通用领域文本嵌入对于训练数据在规模、多样性和质量方面提出了更高的要求。为了实现嵌入的高区分能力,可能需要亿级别的训练样本。这比典型的特定任务数据集大几个数量级。除了规模之外,训练数据还需要从更广泛的来源收集,以提高在不同任务重的普适性。但规模和多样式同时会引入噪声,因此还需要对数据进行清理。
- 训练 训练通用文本嵌入取决于两个关键要素&#
这篇关于[论文笔记]BGE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







