本文主要是介绍BGE M3:论文解读与代码实践,检索增强RAG实践新策略,BGE M3-Embedding方法实践与解读;检索增强生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation 》
1. 论文解读
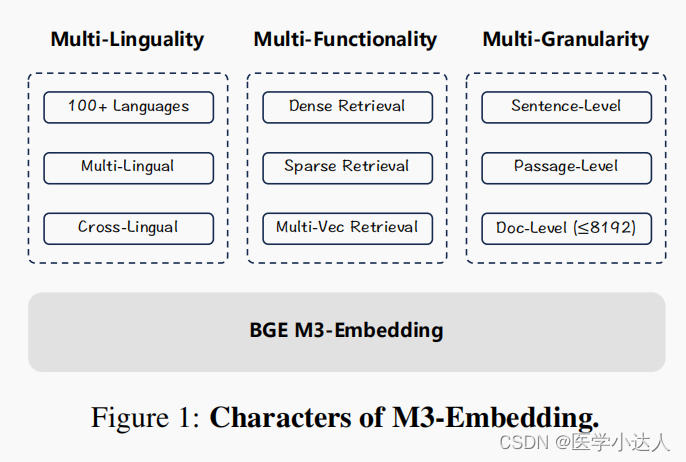
In this project, we introduce BGE-M3, which is distinguished for its versatility in Multi-Functionality, Multi-Linguality, and Multi-Granularity.
- Multi-Functionality: It can simultaneously perform the three common retrieval functionalities of embedding model: dense retrieval, multi-vector retrieval, and sparse retrieval.
- Multi-Linguality: It can support more than 100 working languages.
- Multi-Granularity: It is able to process inputs of different granularities, spanning from short sentences to long documents of up to 8192 tokens.
(1) 摘要介绍
本文提出了一种新的嵌入模型,称为m3嵌入模型,该模型具有多语言、多功能和多粒度的通用性。它可以支持超过100种工作语言,在多语言和跨语言检索任务上带来新的最先进的性能。它可以同时实现嵌入模型中常用的三种检索功能:密集检索、多向量检索和稀疏检索,为实际IR应用提供了统一的模型基础。它能够处理不同粒度的输入,从短句子到多达8192个token的长文档。
我们提出了一种新的自知识蒸馏方法,其中来自不同检索功能的相关分数可以被整合为教师信号,以增强训练质量。我们还优化了批处理策略,实现了大批量和高训练吞吐量,以确保嵌入的判别性。据我们所知,m3嵌入是第一个实现如此强通用性的嵌入模型。

尽管文本嵌入广泛流行,但现有方法的通用性仍然有限。首先,大多数嵌入模型只针对英语量身定制,对于其他语言几乎没有可行的选择。其次,现有的嵌入模型通常是针对单一的检索功能进行训练的。然而,典型的IR系统需要多种检索方法的复合工作流。第三,由于压倒性的训练成本,训练一个有竞争力的长文档检索器是具有挑战性的,其中大多数嵌入模型只能支持短输入。
m3嵌入精通多语言,可支持100多种世界语言。通过学习不同语言的共同语义空间,既能实现每种语言内的多语言检索,又能实现不同语言间的跨语言检索。此外,它能够生成通用的嵌入,以支持不同的检索功能,不仅是密集检索,还可以稀疏检索和多向量检索。最后,学习m3嵌入来处理不同的输入粒度,从句子和段落等短输入到多达8,192个输入令牌的长文档。
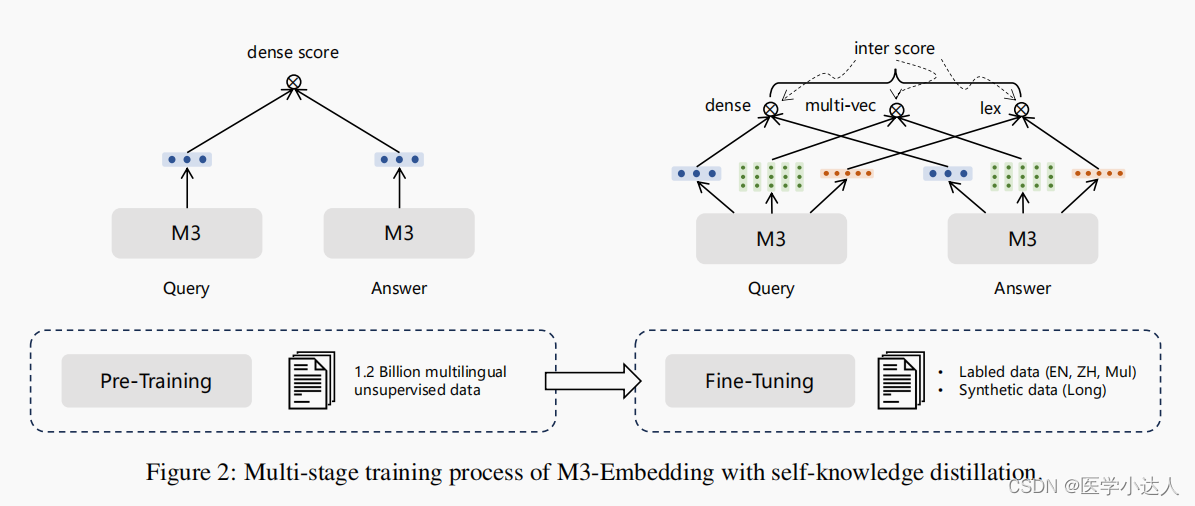
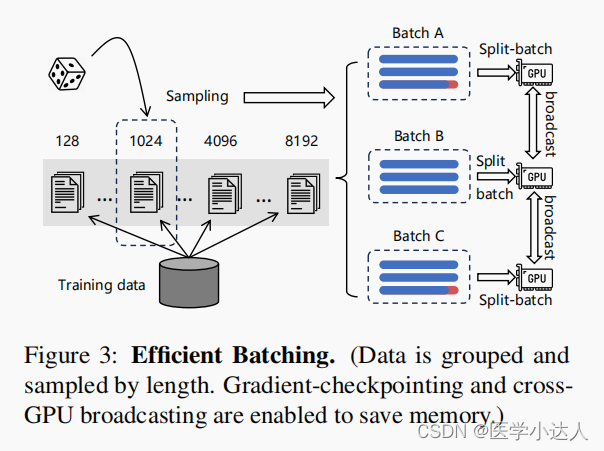
我们提出了一种新的自知识蒸馏框架,其中多种检索功能可以共同学习和相互加强。在m3嵌入中,[CLS]嵌入用于密集检索,而其他序列的嵌入用于稀疏检索和多向量检索。基于集成学习的原理(Buhlmann,2012),这样的异质预测器可以组合成更强的预测器。因此,我们将来自不同检索函数的相关分数整合为教师信号,用于通过知识蒸馏来增强学习过程。其次,我们优化了批处理策略,以实现大批量和高训练吞吐量,这实质上有助于嵌入的判别性。最后同样重要的是,我们执行全面和高质量的数据策略。我们的数据集由三个来源组成:1)从海量多语言语料库中提取无监督数据,2)整合密切相关的监督数据,3)合成稀缺的训练数据。这三个数据源相辅相成,并应用于训练过程的不同阶段,这为通用的文本嵌入奠定了基础。

(2) 方法实现



三种检索方式组合拳:
1)密集检索:在embedding的时候应用【CLS】 作为query和passage表示向量,然后计算两个向量的内积作为得分值:S-dense
2)稀疏检索:首先计算query中每个词的权重,如果出现多次取最高的权重,其次计算quy和passage公共部分词汇的权重(文中称为联合重要度,即两部分公共向量的乘积),最后求和表示得分:S-lex
3)多向量检索:是密集检索的扩展,应用query和passage所有的表示向量,乘以一个可学习矩阵并且norm之后,计算两部分的交互得分,有点像注意力机制:S-mul
由于嵌入模型的多功能,检索过程可以在混合过程中进行。首先,候选结果可以由每种方法单独检索(多向量方法由于成本过高,可以免除这一步)。然后,根据综合相关分数对最终的检索结果重新排序:srank←sdense+slex+smul



第三部分:自知识蒸馏
1)损失函数-1:InfoNCE loss(Noise Contrastive Estimation Loss)是一种用于自监督学习的损失函数,通常用于学习特征表示或者表征学习。它基于信息论的思想,通过对比正样本和负样本的相似性来学习模型参数。
2)损失函数-2:对类似于交叉熵损失函数,分别计算三部分得分的损失,求和取均值,见公式2-4
3)最后的损失函数:前两部分求和:L-final = L + L'
知识补充:何为 InfoNCE loss:

文本编码器使用海量的无监督数据进行预训练,其中只有密集检索以对比学习的基本形式进行训练。将自知识蒸馏应用于第二阶段,对嵌入模型进行微调,以建立三个检索功能。在这一阶段同时使用标记数据和合成数据,按照ANCE方法为每个查询引入硬负样本。
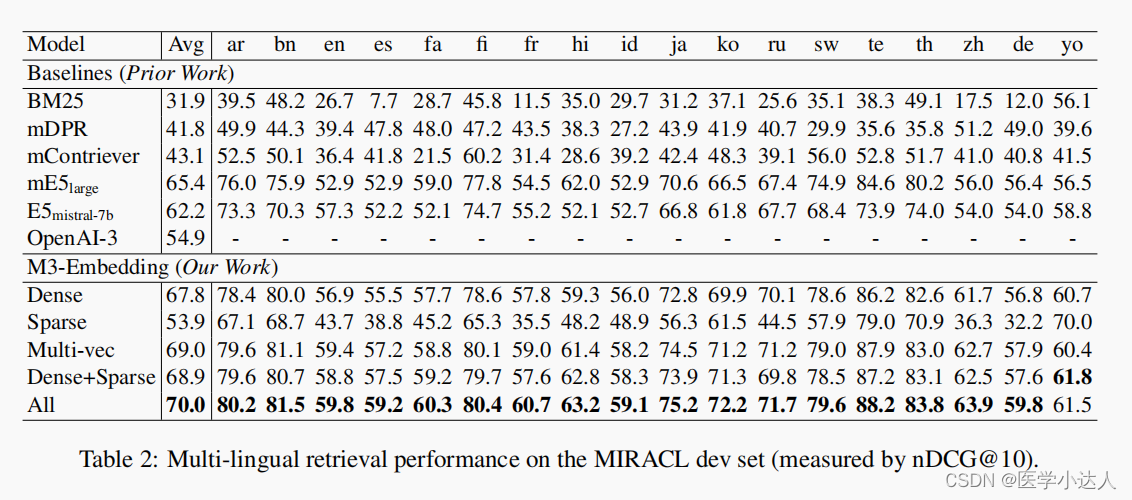
(3)实验结果
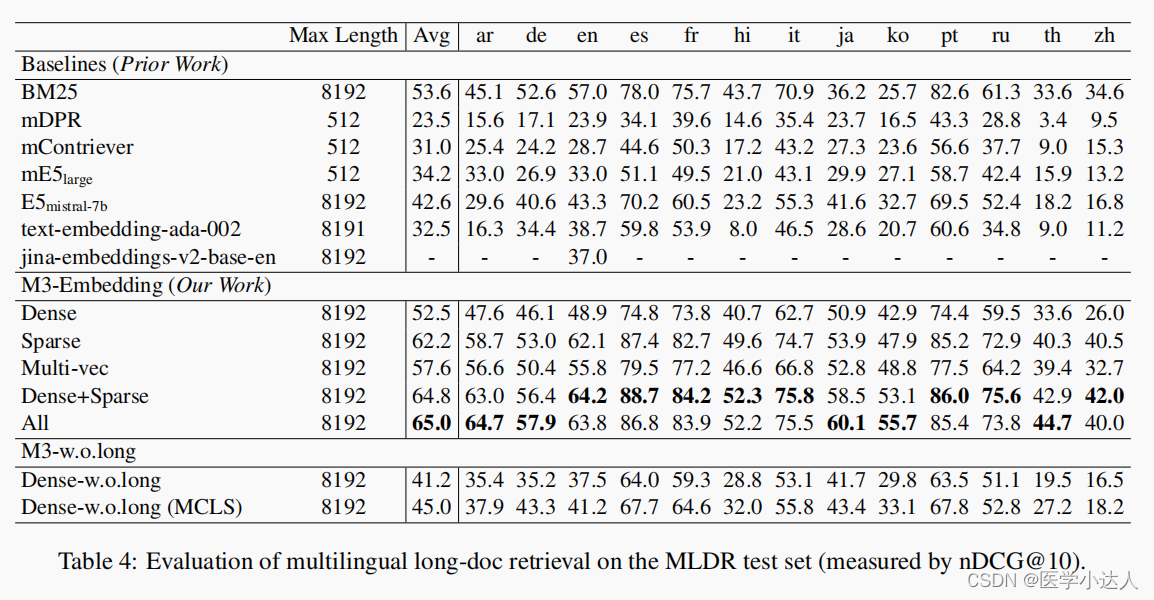
 2. 代码实践
2. 代码实践
环境配置:
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install -e .或者
pip install -U FlagEmbedding(1) Dense Embedding 密集嵌入
from FlagEmbedding import BGEM3FlagModelmodel = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradationsentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.", "BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]embeddings_1 = model.encode(sentences_1, batch_size=12, max_length=8192, # If you don't need such a long length, you can set a smaller value to speed up the encoding process.)['dense_vecs']
embeddings_2 = model.encode(sentences_2)['dense_vecs']
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# [[0.6265, 0.3477], [0.3499, 0.678 ]](2) Sparse Embedding (Lexical Weight)
from FlagEmbedding import BGEM3FlagModelmodel = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradationsentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.", "BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]output_1 = model.encode(sentences_1, return_dense=True, return_sparse=True, return_colbert_vecs=False)
output_2 = model.encode(sentences_2, return_dense=True, return_sparse=True, return_colbert_vecs=False)# you can see the weight for each token:
print(model.convert_id_to_token(output_1['lexical_weights']))
# [{'What': 0.08356, 'is': 0.0814, 'B': 0.1296, 'GE': 0.252, 'M': 0.1702, '3': 0.2695, '?': 0.04092},
# {'De': 0.05005, 'fin': 0.1368, 'ation': 0.04498, 'of': 0.0633, 'BM': 0.2515, '25': 0.3335}]# compute the scores via lexical mathcing
lexical_scores = model.compute_lexical_matching_score(output_1['lexical_weights'][0], output_2['lexical_weights'][0])
print(lexical_scores)
# 0.19554901123046875print(model.compute_lexical_matching_score(output_1['lexical_weights'][0], output_1['lexical_weights'][1]))
# 0.0(3) Multi-Vector (ColBERT)
from FlagEmbedding import BGEM3FlagModelmodel = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) sentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.", "BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]output_1 = model.encode(sentences_1, return_dense=True, return_sparse=True, return_colbert_vecs=True)
output_2 = model.encode(sentences_2, return_dense=True, return_sparse=True, return_colbert_vecs=True)print(model.colbert_score(output_1['colbert_vecs'][0], output_2['colbert_vecs'][0]))
print(model.colbert_score(output_1['colbert_vecs'][0], output_2['colbert_vecs'][1]))
# 0.7797
# 0.4620(4) Compute score for text pairs
Input a list of text pairs, you can get the scores computed by different methods.
from FlagEmbedding import BGEM3FlagModelmodel = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) sentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.", "BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]sentence_pairs = [[i,j] for i in sentences_1 for j in sentences_2]print(model.compute_score(sentence_pairs, max_passage_length=128, # a smaller max length leads to a lower latencyweights_for_different_modes=[0.4, 0.2, 0.4])) # weights_for_different_modes(w) is used to do weighted sum: w[0]*dense_score + w[1]*sparse_score + w[2]*colbert_score# {
# 'colbert': [0.7796499729156494, 0.4621465802192688, 0.4523794651031494, 0.7898575067520142],
# 'sparse': [0.195556640625, 0.00879669189453125, 0.0, 0.1802978515625],
# 'dense': [0.6259765625, 0.347412109375, 0.349853515625, 0.67822265625],
# 'sparse+dense': [0.482503205537796, 0.23454029858112335, 0.2332356721162796, 0.5122477412223816],
# 'colbert+sparse+dense': [0.6013619303703308, 0.3255828022956848, 0.32089319825172424, 0.6232916116714478]
# }
这篇关于BGE M3:论文解读与代码实践,检索增强RAG实践新策略,BGE M3-Embedding方法实践与解读;检索增强生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





