bagging专题
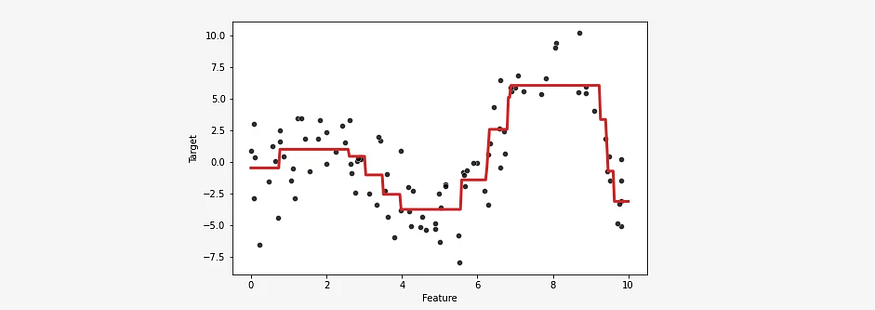
Bagging: 数量,而不是质量。
由 AI 生成:过度简化的树、引导聚合、集成方法、弱学习器、减少方差 集成方法 — 数量,而不是质量 一、说明 机器学习中的集成方法是指组合多个模型以提高预测性能的技术。集成方法背后的基本思想是聚合多个基础模型(通常称为弱学习器)的预测,以生成通常比任何单个模型更准确、更稳健的最终预测。一般而言,我们通常遵循质量胜于数量的原则。然而,在这种情况下,事实证

什么是机器学习中的 Bagging?带有示例的指南
文章目录 一、说明二、理解集成学习2.1 什么是 Bagging?2.2 Bagging 与 Boosting2.3 套袋的优点 三、Python 中的 Bagging:简短教程3.1 数据集3.2 训练机器学习模型3.3 模型评估 四、装袋分类器4.1 评估集成模型4.2 最佳实践和技巧 五、结论 一、说明 集成方法是机器学习中强大的技术,它可以结合多种模型来提高

【机器学习】集成学习的基本概念、Bagging和Boosting的区别以及集成学习方法在python中的运用(含python代码)
引言 集成学习是一种机器学习方法,它通过结合多个基本模型(通常称为“弱学习器”)来构建一个更加强大或更可靠的模型(“强学习器”) 文章目录 引言一、集成学习1.1 集成学习的核心思想1.2 常见的集成学习方法1.2.1 Bagging(装袋)1.2.2 Boosting(提升)1.2.3 Stacking(堆叠) 1.3 集成学习的优势1.4 集成学习的挑战1.5 总结 二、Bag

机器学习学习--Kaggle Titanic--LR,GBDT,bagging
参考,机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 http://www.cnblogs.com/zhizhan/p/5238908.html 机器学习(二) 如何做到Kaggle排名前2% http://www.jasongj.com/ml/classification/ 一、认识数据 1.把csv文件读入成dataframe格式 import pandas as

6.0 —随机森林原理(RF)和集成学习(Bagging和Pasting)
我们这边先介绍集成学习 什么是集成学习 我们已经学习了很多机器学习的算法。比如KNN,SVM.逻辑回归,线性回归,贝叶斯,神经网络等等,而我们的集成学习就是针对某一个问题,我们使用多个我们已经学过的算法,每个算法都会得出一个结果。然后采用投票的方法,少数服从多数,得出最终结果。这就是voting classifier 我们看下代码: 我们手写的集成学习方法,和scikit-learn
boosting,Adaboost,Bootstrap和Bagging的含义和区别
弱分类器:分类效果差,只是比随机猜测好一点。 强分类器:具有较高的识别率,较好的分类效果。(在百度百科中有提到要能在多项式时间内完成学习) 弱和强更大意义上是相对而言的,并没有严格的限定。比如准确率低于多少就是弱分类器,高于多少是强分类器,因具体问题而定。 1988年,有学者提出是否可以通过一些弱分类器来实现强分类器的分类效果。基于这个问题,之后两三年陆续的有早期的boosting算法

Boosting和Bagging: 如何开发一个鲁棒的机器学习算法
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Ben Rogojan 编译:ronghuaiyang 导读 机器学习和数据科学需要的不仅仅是将数据放入python库中并利用得到的结果。数据科学家需要真正理解数据和数据背后的过程,才能实现一个成功的系统。这篇文章从Bootstraping开始介绍,让你听懂什么是Boosting,什么是Bagging。 机器学习和数据科学

集成学习方法:Bagging与Boosting的应用与优势
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119@qq.com] 📱个人微信:15279484656 🌐个人导航网站:www.forff.top 💡座右铭:总有人要赢。为什么不能是我呢? 专栏导航: 码农阿豪系列专栏导航 面试专栏:收集了java相关高频面试题,面试实战
bootstrap, boosting, bagging的区别和联系
Bootstraping: 名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法。其核心思想和基本步骤如下: (1) 采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样。 (2) 根据抽出的样本计算给定的统计量T。
Boosting Bagging Stacking整理
一. 知识点 Bias-Variance Tradeoff bias-variance是分析boosting和bagging的一个重要角度,首先讲解下Bias-Variance Tradeoff. 假设training/test数据集服从相似的分布,即 yi=f(xi)+ϵi, y i = f ( x i ) + ϵ i , y_i = f(x_i) + \epsilo
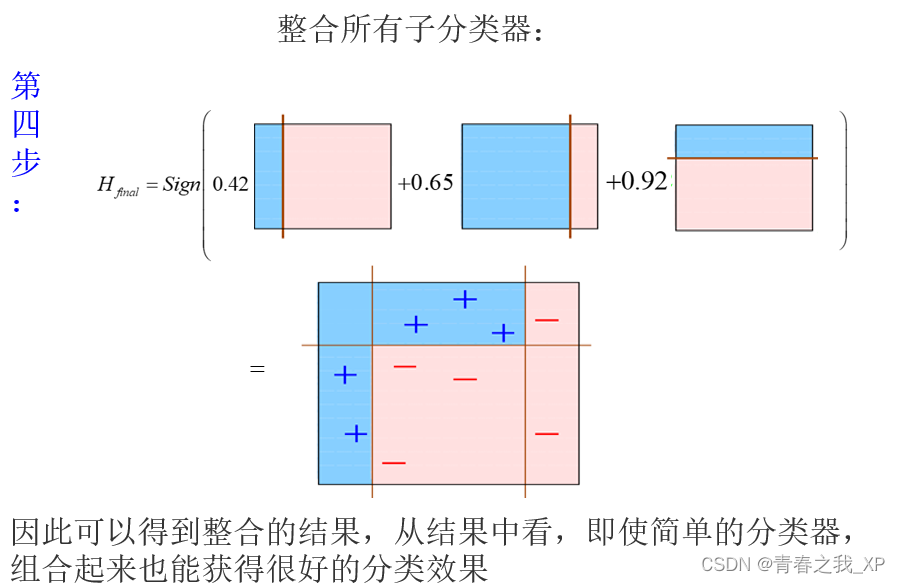
【机器学习系列】深入理解集成学习:从Bagging到Boosting
目录 一、集成方法的一般思想 二、集成方法的基本原理 三、构建集成分类器的方法 常见的有装袋(Bagging)和提升(Boosting)两种方法 方法1 :装袋(Bagging) Bagging原理如下图: 方法2 :提升(Boosting) Boosting工作原理 目前已有几个Boosting算法,其区别在于: 四、随机森林(Bagging集成方法的一种) (一)随

bootstrap, boosting, bagging
介绍boosting算法的资源: 视频讲义,介绍boosting算法,主要介绍AdaBoosing http://videolectures.net/mlss05us_schapire_b/在这个网站的资源项里列出了对于boosting算法来源介绍的几篇文章,可以下载: http://www.boosting.org/tutorials一个博客介绍了许多视觉中常用算法,作者的实验和理解,这里附录
【机器学习】集成学习---Bagging之随机森林(RF)
【机器学习】集成学习---Bagging之随机森林(RF) 一、引言1. 简要介绍集成学习的概念及其在机器学习领域的重要性。2. 引出随机森林作为Bagging算法的一个典型应用。 二、随机森林原理1. Bagging算法的基本思想2. 随机森林的构造3. 随机森林的工作机制 三、随机森林的伪代码四、随机森林的优点五、案例分析六、总结与展望 一、引言 1. 简要介绍集成学习的概念

Bagging RF
Bagging 算法流程如下: 从原始样本中使用Bootstraping方法有放回地随机抽取 n n n 个训练样本,共进行 k k k 轮抽取,得到 k k k 个训练集;对于 k k k 个训练集,分别训练出 k k k 个模型;在对预测输出进行结合时: 分类:简单投票法回归:简单平均法 RF RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程
[机器学习] 第八章 集成学习 1.Boosting(GBDT Adaboost Xgboost) Bagging(随机森林)
https://www.cnblogs.com/techflow/p/13445042.html 文章目录 一、Boosting ↓bias1. GBDT回归(划分结点:mse)1.1 Regression Decision Tree:回归树1.2 Boosting Decision Tree:提升树算法1.3 Shrinkage (避免GBDT过拟合,学习率) 2. GBDT分类(划分结点
![[机器学习必知必会]集成学习Boosting、Boostrap和Bagging算法介绍](https://img-blog.csdn.net/20180604142302143)
[机器学习必知必会]集成学习Boosting、Boostrap和Bagging算法介绍
集成学习算法简介: (1)原理: 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高。目前接触较多的集成学习主要有2种:基于Boosting的和基于Bagging,前者的代表算法有Adaboost、GBDT、XGBOOST、后者的代表算法主要是随机森林。 集成学习的主要思想是利用一定的手段学习出多个分类器,而且这多个分类器要求是弱分

机器学习建模中的Bagging思想!
来源:偶数科技本文约3200字,建议阅读9分钟 本文带你了解了Bagging思想及其原理,以及基于Bagging的随机森林相关知识。 我们在生活中做出的许多决定都是基于其他人的意见,而通常情况下由一群人做出的决策比由该群体中的任何一个成员做出的决策会产生更好的结果,这被称为群体的智慧。集成学习(Ensemble Learning)类似于这种思想,集成学习结合了来自多个模型的预测,旨在比集成该学

【机器学习】集成学习 Bagging Boosting 综述
集成学习 Ensemble learning: 主要包括三种形似的集成方式【Bagging、Boosting、Stacking】 指将若干弱分类器 (或基(础)分类器) 组合之后产生一个强分类器 (可以是不同类型的分类器) ·并不算是一种分类器,而是一种分类器的结合方法; ·一个集成分类器的性能会好于单个分类器; 1
Boosting、Bagging和Stacking知识点整理
全是坑,嘤嘤哭泣= = 简述下Boosting的工作原理 Boosting主要干两件事:调整训练样本分布,使先前训练错的样本在后续能够获得更多关注 集成基学习数目 Boosting主要关注降低偏差(即提高拟合能力)描述下Adaboost和权值更新公式 Adaboost算法是“模型为加法模型、损失函数为指数函数、学习算法为前向分布算法”时的二类分类学习方法。 Adaboost有两项内容:

DataWhale集成学习【中】:(二)Bagging
这篇博文是 DataWhale集成学习【中】 的第二部分,主要是介绍Bagging参考资料为DataWhale开源项目:机器学习集成学习与模型融合(基于python)和scikit-learn官网学习交流欢迎联系 obito0401@163.com 文章目录 原理案例 原理 在DataWhale集成学习【中】:(一)投票法我们提到过:要想让整体模型取得更好的效果,应该增加模型之

集成学习boosting和bagging
集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。这对“弱学习器”尤为明显,因此集成学习的很多理论研究都是针对弱学习器进行的,而基学习器有时也被直接称为弱学习器。弱学习器指泛化性能略优于随机猜测的学习器,例如在二分类问题上,精度略高于50%的分类器。个体学习器应该“好而不同”,即个体学习器性能不能太坏,且个体学习器之间要存在差异性。根据个体学习器的生成方式,目前的集成学习方

oob(out-of-bag)和关于bagging的更多讨论
不用 train_test_split #%% 使用oobfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.ensemble import BaggingClassifierbagging_clf = BaggingClassifier(DecisionTreeClassifier(),n_estimators=500,m

Bagging和Pasting
同样实验前加载和上一节相同的数据集 #%% 使用Baggingfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.ensemble import BaggingClassifierbagging_clf = BaggingClassifier(DecisionTreeClassifier(), #使用决策树模型n
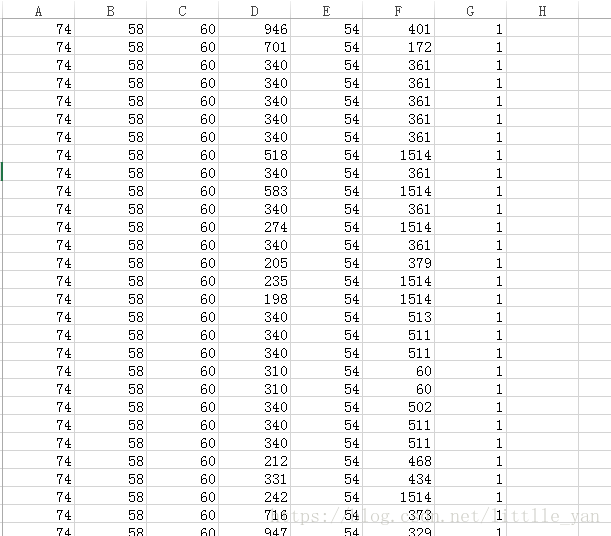
基于sklearn实现Bagging算法(python)
基于sklearn实现Bagging算法(python) 本文使用的数据类型是数值型,每一个样本6个特征表示,所用的数据如图所示: 图中A,B,C,D,E,F列表示六个特征,G表示样本标签。每一行数据即为一个样本的六个特征和标签。 实现Bagging算法的代码如下: from sklearn.ensemble import BaggingClassifierfrom sk
集成学习bagging与boosting
集成学习是机器学习中的一种策略,旨在结合多个学习器的预测结果,以提高总体性能,减少过拟合,增强模型的泛化能力。Boosting和Bagging是集成学习中两种非常著名的方法,它们虽然共享集成多个学习器以达到更好性能的共同目标,但在方法论和应用上存在一些关键的区别。 Bagging (Bootstrap Aggregating) 并行训练:Bagging通过在原始数据集上构建多个训练集的方式来创

随机森林 bagging袋装法(基于bootstrap重抽样自举法)的原理与python实现——机器学习笔记之集成学习 Part 1
* * * The Machine Learning Noting Series * * * 导航 1 Bootstrap重抽样自举法 2 袋装法(Bagging) 3 随机森林 4 python实现——一个实例 ⚫袋装法和随机森林过程基本一样,都是根据bootstrap的一系列样本分别建立决策树,然后用这些决策树投票出结果。最大区别,也就是随机森林更好的原因在于:随机森林在建立