attacks专题

监控领域的物理对抗攻击综述——Physical Adversarial Attacks for Surveillance: A Survey
介绍 文章贡献 框架提出:提出了一个新的分析框架,用于理解和评估生成和设计物理对抗性攻击的方法。全面调查:对物理对抗性攻击在监控系统中的四个关键任务—检测、识别、跟踪和行为识别—进行了全面的调查和分析。跨领域探索:讨论了物理对抗性攻击在可见光域之外的应用,包括红外、LiDAR和多光谱谱段。方法分析:从四个关键任务的角度回顾、讨论、总结了现有的攻防策略。未来研究方向:从监控角度指出生成成功的物理

【论文阅读】Model Stealing Attacks Against Inductive Graph Neural Networks(2021)
摘要 Many real-world data(真实世界的数据) come in the form of graphs(以图片的形式). Graph neural networks (GNNs 图神经网络), a new family of machine learning (ML) models, have been proposed to fully leverage graph data(

规避攻击和毒化攻击Evasion Attacks and Adversarial Examples
"规避攻击(evasion attacks)"和"毒化攻击(poisoning attacks)"是两种常见的网络安全攻击类型,它们针对机器学习和深度学习模型进行攻击。 规避攻击(Evasion Attacks) 规避攻击是指攻击者通过修改输入数据,使得机器学习模型无法正确分类或预测。这种攻击通常利用模型对输入数据的处理方式来产生意想不到的结果,从而误导模型做出错误的判断。规避攻击可以通过以下
Windows Vista Security: Securing Vista Against Malicious Attacks
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp It's not the computer. The hacker's first target is YOU! A dirty little secret that vendors don't want

Securing Windows Server 2008: Prevent Attacks from Outside and Inside Your Organization
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Microsoft hails the latest version of its flagship server operating system, Windows Server 2008, as "th
论文翻译 - Defending Against Alignment-Breaking Attacks via Robustly Aligned LLM
论文链接:https://arxiv.org/pdf/2309.14348.pdf Defending Against Alignment-Breaking Attacks via Robustly Aligned LLM Abstract1 Introduction2 Related Works3 Our Proposed Method3.1 Threat Model3.2 Our Pr

Understanding adversarial attacks on deep learning based medical image analysis systems(2021 PR)
Understanding adversarial attacks on deep learning based medical image analysis systems----《理解基于深度学习的医学图像分析系统的对抗攻击》 背景: 最近的一项研究表明,医学深度学习系统可能会因精心设计的对抗性示例/攻击以及难以察觉的小扰动而受到损害。作者发现医学DNN模型比自然图像模型更容易受到攻击,
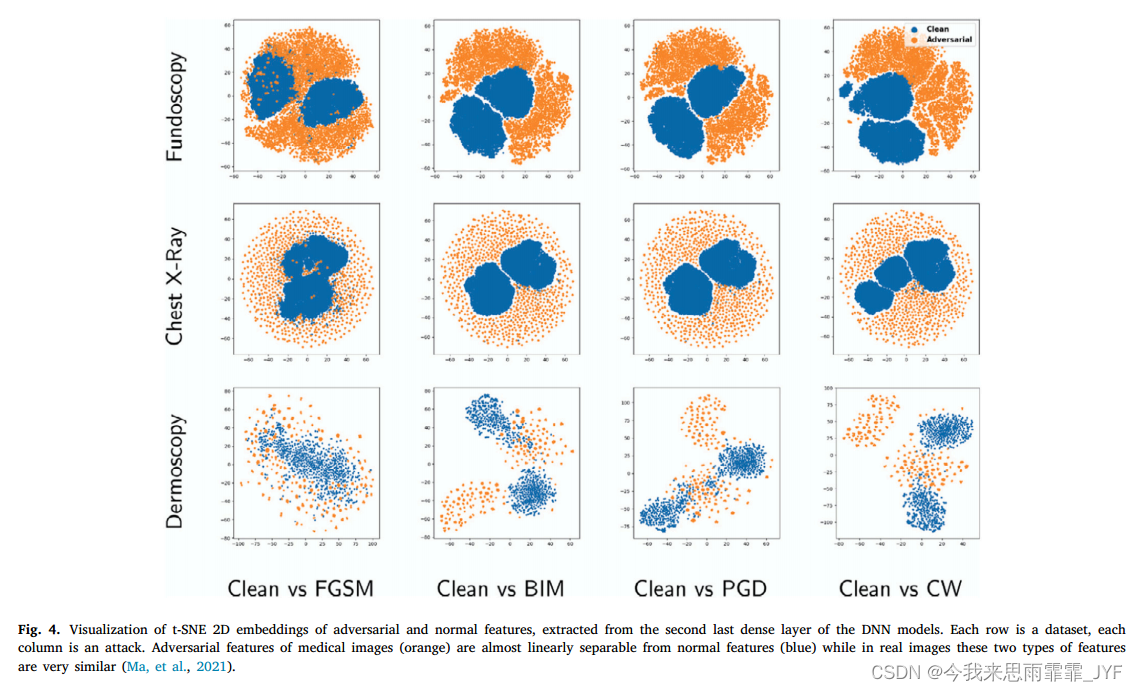
Adversarial attacks and defenses on AI in medical imaging informatics: A survey(2022)
Adversarial attacks and defenses on AI in medical imaging informatics: A survey----《AI在医学影像信息学中的对抗性攻击与防御:综述》 背景: 之前的研究表明,人们对医疗DNN及其易受对抗性攻击的脆弱性一直存在疑虑。 摘要: 近年来,医学图像显着改善并促进了多种任务的诊断,包括肺部疾病分类、结节检测、脑
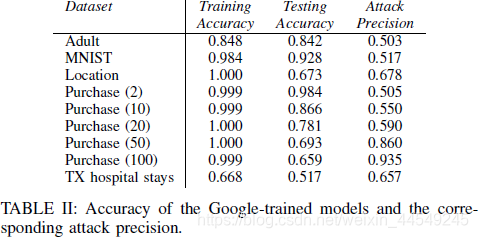
【论文阅读】Membership Inference Attacks Against Machine Learning Models
基于confidence vector的MIA Machine Learning as a Service简单介绍什么是Membership Inference Attacks(MIA)攻击实现过程DatasetShadow trainingTrain attack model Machine Learning as a Service简单介绍 机器学习即服务(Machine

【图对抗】Local-Global Defense against Unsupervised Adversarial Attacks on Graphs
原文标题: Local-Global Defense against Unsupervised Adversarial Attacks on Graphs 原文代码: https://github.com/jindi-tju/ULGD/blob/main 发布年度: 2023 发布期刊: AAAI 摘要 Unsupervised pre-training algorithms for gr
Memory Deduplication Attacks
原文 最近看到了一系列描述Memory Deduplication Attacks的研究,它已被用于指纹系统[1]、破解 (K)ASLR[2,3,4]、泄漏数据库记录[4],甚至利用 rowhammer[ 5]。这是一类非常酷的攻击,以前从未听说过,但我没有太多运气找到这些攻击的任何 POC……所以,我想我应该写下我学到的关于这些攻击如何运作的知识,并写下我自己的其中一种攻击版本可用于破坏当前

【论文翻译】Robust Physical-World Attacks on Deep Learning Visual Classification
Robust Physical-World Attacks on Deep Learning Visual Classification 对深度学习视觉分类的鲁棒物理世界攻击 Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Ko
Spectre Attacks Exploiting Speculative Execution-1
Spectre Attacks: Exploiting Speculative Execution 摘要: 推测式执行在如何执行方面是不可靠的,因为它可以访问受害者的内存和寄存器,并且可以执行具有可测量的副作用的操作幽灵攻击:诱导受害者在执行在正确的程序执行过程中不会发生的推测性操作,并通过一个侧信道将受害者的敏感数据泄露出去论文提出了一种实用的攻击方法,通过结合侧信道攻击,fault攻击和R

Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks(2018)
Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks----《毒蛙!面向神经网络的有针对性的干净标签投毒攻击》 背景: 非干净标签数据投毒的后门攻击要求攻击者对训练数据的标签进行控制,即需要在数据上增加触发器并修改标签, 这种攻击方法在审查数据集时仍然很容易发现数据被恶意篡改,隐蔽性不足。 意义: 目前
【论文记录】Membership Inference Attacks Against Machine Learning Models
基于本文的几个跟踪研究 ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learn MemGuard: Defending against Black-Box Membership Inference Attacks via Adversarial Examples背

MoLE: Mitigation of Side-channel Attacks against SGX via Dynamic Data Location Escape【ACSAC`22】
目录 摘要引言挑战解决方案贡献全面防御无法追踪的混淆综合评价 背景Intel SGXIntel TSX侧信道攻击和相关攻击缓存侧通道攻击页表侧通道攻击瞬态执行攻击 威胁模型MoLE设计概述RCX和RDX中的随机数 MoLE的隧道Escape函数Feint访问 部署安全分析缓存SCA页面表SCAMeltdow攻击攻击窗口单步跟踪 评估环境设置安全评估性能评估 相关工作讨论在没有执行的情况

decision-based adversarial attacks_reliable attacks against black-box machine learning models
Decision-based adversarial attacks: Reliable attacks against black-box machine learning models Decision-based adversarial attacks: Reliable attacks against black-box machine learning models 本文提出了一种b

Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
文章目录 概主要内容Auto-PGDMomentumStep Size损失函数AutoAttack Croce F. & Hein M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In International Confe

论文那些事—DECISION-BASED ADVERSARIAL ATTACKS:RELIABLE ATTACKS AGAINST BLACK-BOX MACHINE LEARNING MODELS
DECISION-BASED ADVERSARIAL ATTACKS:RELIABLE ATTACKS AGAINST BLACK-BOX MACHINE LEARNING MODELS(ICLR2018) 1、摘要/背景 目前用于生成对抗扰动的大多数方法要么依赖于详细的模型信息(基于梯度的攻击),要么依赖于置信度分数,例如类概率(基于分数的攻击),这两种能力在大多数现实世界场景中都不可用。
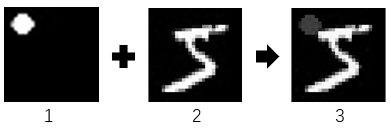
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning 论文复现
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning 论文复现 代码链接:点我🙂 1. 模型说明 网络使用的是LeNet-5,只包含两个卷积层和若干全连接层,参数量很小数据集使用的mnist手写数据集(训练集:60000 测试集:10000)实现了Backdoor的两种攻击形式(instance

Tik-Tok: The Utility of Packet Timing inWebsite Fingerprinting Attacks
code 过去对于时序没有足够的重视。 贡献: 开发了新的突发级定时功能,并使用WeFDE信息泄露分析框架使用新的数据表示用于深度指纹识别(DF)攻击并揭示其影响,这种新的表现形式称为Tik-Tok攻击对洋葱服务器上深度学习分类器的性能进行了第一次调查,发现DF攻击的准确率仅为53%,而原始定时为66%在Tor中开发了Walkie-Talkie(W-T)防御的第一个完整的实现并使用它来评估我

论文阅读——DaST: Data-free Substitute Training for Adversarial Attacks
摘要 对于黑盒设置,当前的替代战术需要预先训练的模型来生成对抗样本。然而,在现实世界的任务中很难获得预先训练的模型。本文提出了一种无数据替代训练方法(DaST),在不需要任何真实数据的情况下获得对抗黑箱攻击的替代模型。作者针对generative moddel设计了一个multi-branch 结构和label-control loss来解决合成样本分布不均匀的问题 缺陷 替代模型仅针对与某
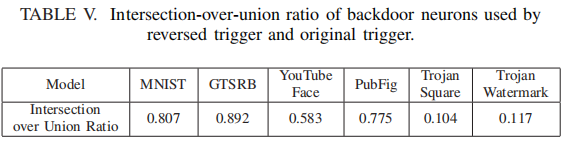
【翻译】Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
文章目录 ABSTRACTI. INTRODUCTIONII. BACKGROUND: BACKDOOR INJECTION IN DNNSIII. OVERVIEW OF OUR APPROACH AGAINST BACKDOORSA. Attack ModelB. Defense Assumptions and GoalsC. Defense Intuition and Overview

rl-policies-attacks 代码 Debug 记录
Dependencies(探索出可行的版本) cuda==11.0 pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 python==3.8.13 advertorch==0.2.3 tianshou==0.3.1 atari-py==0.2.9 gym==0.18.0 (atari-py

BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning-基于自监督学习预训练编码器的后门攻击
BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning 摘要 本文提出了 BadEncoder,这是针对自监督学习的第一个后门攻击方法。用 BadEncoder 将后门注入到预训练的图像编码器中,基于该编码器进行微调的不同下游任务会继承该后门行为。我们将 BadEncoder 描述为一个优