本文主要是介绍Understanding adversarial attacks on deep learning based medical image analysis systems(2021 PR),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Understanding adversarial attacks on deep learning based medical image analysis systems----《理解基于深度学习的医学图像分析系统的对抗攻击》
背景: 最近的一项研究表明,医学深度学习系统可能会因精心设计的对抗性示例/攻击以及难以察觉的小扰动而受到损害。作者发现医学DNN模型比自然图像模型更容易受到攻击,但医疗对抗性攻击也能很容易检测到。
意义: 为设计更可解释和更安全的医学深度学习系统提供有用的基础。
引言
深度神经网络 (DNN) 是强大的模型,已被广泛用于各种自然图像分析任务上实现接近人类水平的性能,例如图像分类 [1]、目标检测 [2]、图像检索 [3] 和 3D分析[4]。由于目前在自然图像(例如 CIFAR-10 和 ImageNet 等自然场景中捕获的图像)方面取得的成功,DNN 已成为医学图像处理任务的流行工具,例如癌症诊断 [5]、糖尿病视网膜病变检测 [6] ]和器官/地标定位[7]。尽管性能优越,但最近的研究发现,最先进的 DNN 很容易受到精心设计的对抗性示例(或攻击)的影响,也就是说,轻微扰动的输入实例可以欺骗 DNN 做出高置信度的错误预测[8,9]。这引起了人们对自动驾驶[10]、行为分析[11]和医疗诊断[12]等安全关键应用中部署深度学习模型的担忧。
虽然现有的对抗机器学习研究工作主要集中在自然图像上,但对医学图像领域的对抗攻击的全面理解仍然是开放的。医学图像可以具有与自然图像截然不同的领域特定特征,例如,独特的生物纹理。最近的一项工作证实,医学深度学习系统也可能受到对抗性攻击的损害[12]。如图1所示,在眼底镜检查[6]、胸部X光检查[13]和皮肤镜检查[14]这三个医学图像数据集上,诊断结果可以通过对抗性攻击任意操纵。这种漏洞也在三维立体医学图像分割中得到了讨论 [15]。考虑到支撑医疗保健经济的巨额资金,这不可避免地会带来风险,潜在的攻击者可能会寻求通过操纵医疗保健系统来获利。例如,攻击者可能会操纵他们的检查报告来实施保险欺诈或虚假的医疗报销索赔[16]。另一方面,攻击者可能试图通过不知不觉地操纵图像来造成疾病的误诊,这可能会对有关患者的决策产生严重影响。更糟糕的是,由于 DNN 以黑盒方式工作 [17],这种伪造的决策很难被识别。随着深度学习模型和医学成像技术越来越多地应用于医学诊断、决策支持和药品审批过程中[18],安全、稳健的医学深度学习系统变得至关重要[12,16]。第一步也是重要的一步是全面了解该领域的对抗性攻击。
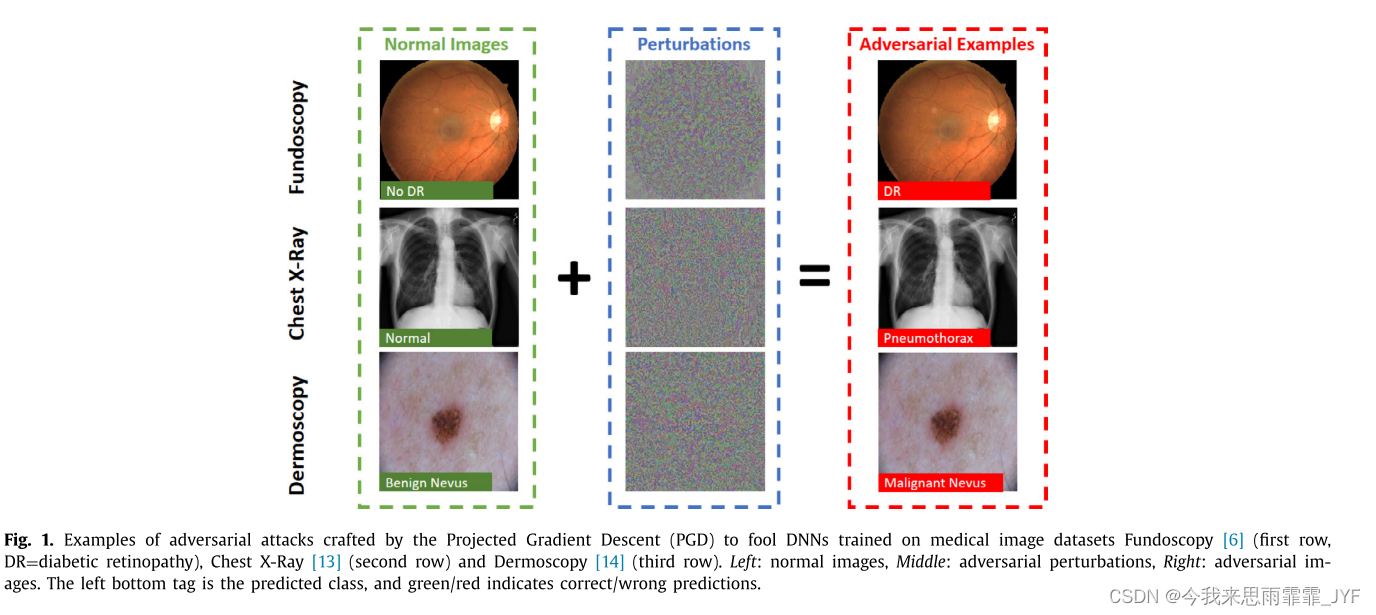
在本文中,我们从生成和检测这些攻击的角度提供了对医学图像对抗攻击的全面理解。最近的两项工作[12,16]研究了对医学图像的对抗性攻击,主要侧重于测试为医学图像分析而设计的深度模型的鲁棒性。特别是,[16]的工作测试了现有的医学深度学习模型是否可以受到对抗性攻击。他们表明,分类准确率从正常医学图像的 87% 以上下降到对抗样本的几乎 0%(即攻击命中率几乎为100%)。[16]的工作利用对抗样本作为衡量标准,来评估医学图像模型在分类或分割任务中的鲁棒性。他们的研究仅限于小扰动,他们观察到在不同的模型中有一个边际的但可变的性能下降。尽管有这些研究,以下问题仍然悬而未决:“对医学图像的对抗性攻击是否可以像对自然图像的攻击一样容易地进行?如果不是,为什么?“此外,据我们所知,之前没有研究过医学图像对抗样本的检测。在本文中,我们通过研究医学图像对抗性攻击的生成和检测来为这些问题提供一些答案。
主要贡献是:
- 我们发现对医学图像的对抗性攻击比对自然图像的对抗性攻击更容易成功。也就是说,成功的攻击只需要较少的扰动。
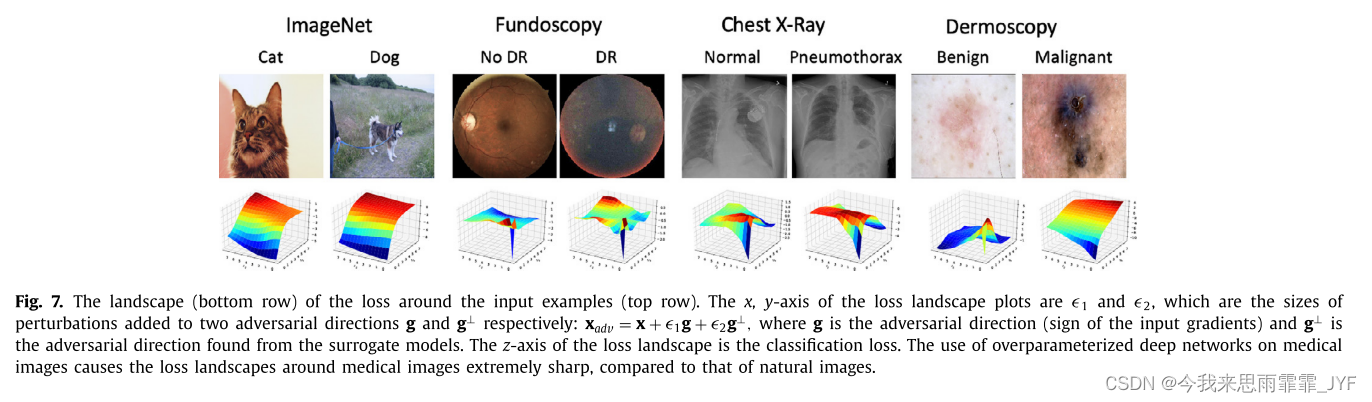
- 我们表明医学图像 DNN 的较高脆弱性似乎是由于以下几个原因造成的:1)一些医学图像具有复杂的生物纹理,导致高梯度区域对小的对抗扰动非常敏感;最重要的是,2)专为大规模自然图像处理而设计的最先进的 DNN 可能会针对医学成像任务进行过度参数化,从而导致急剧的损失情况和极易受到对抗性攻击的脆弱性。
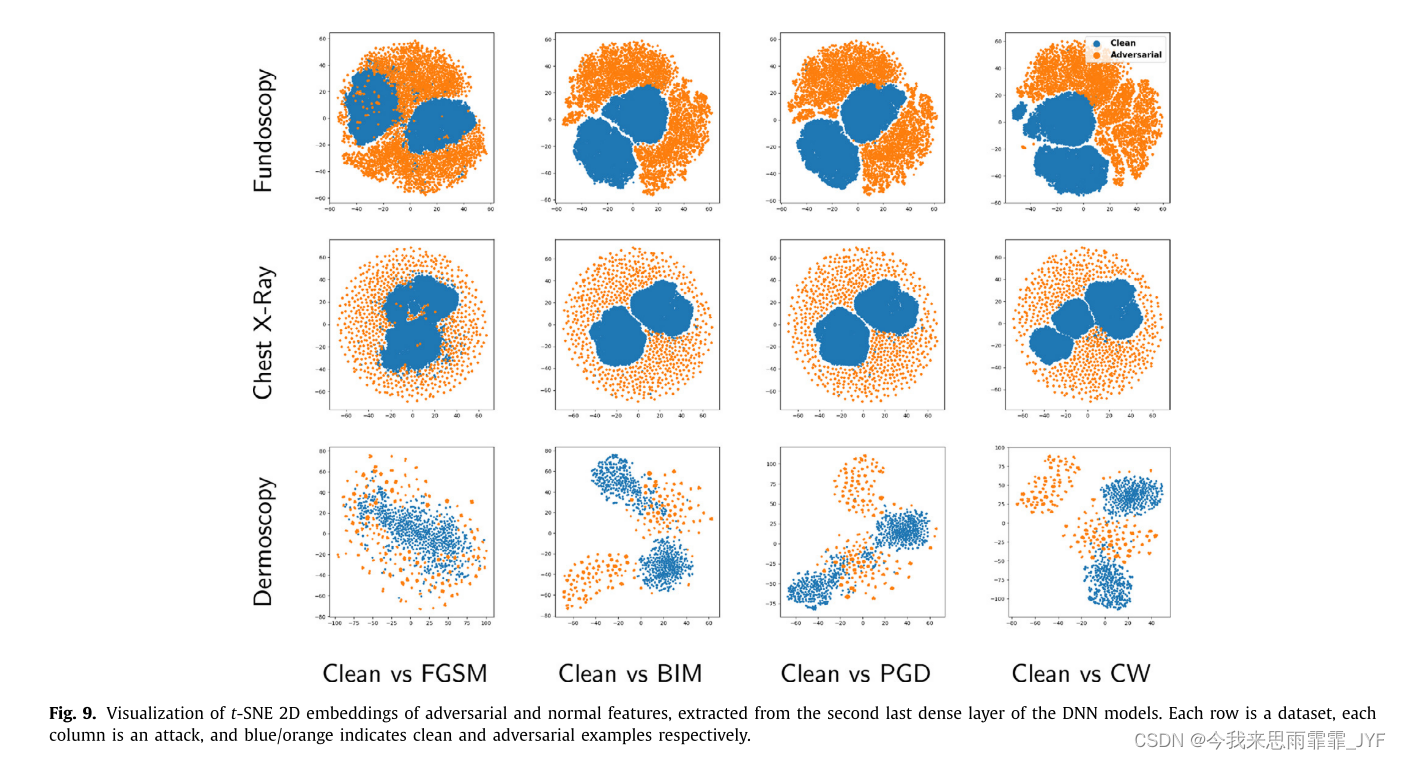
- 令人惊讶的是,我们发现医学图像对抗性攻击也可以很容易地被检测到。仅针对深度特征进行训练的简单检测器就可以针对我们三个数据集上的所有测试攻击实现超过 98% 的检测 AUC。据我们所知,这是第一个关于医学图像领域对抗性攻击检测的工作。
- 我们表明,医学图像对抗性示例的高可检测性似乎是因为对抗性攻击会对病变区域以外的广泛区域造成干扰。这导致对抗性示例的深层特征值明显不同于正常示例。
我们对 DNN 在医学图像与自然图像上不同程度的对抗性漏洞的发现,有助于更全面地了解不同领域深度学习模型的可靠性和鲁棒性。我们对医学对抗样本的分析提供了对学习表征的新的解释,并为深度学习模型在医学图像背景下做出的决策提供了额外的解释。这是构建可解释且鲁棒的医疗诊断深度学习系统的有用起点。
本文的其余部分安排如下。在第 2 节中,我们简要介绍基于深度学习的医学图像分析。在第 3 节中,我们介绍了对抗性攻击和防御技术。我们在第 4 节和第 5 节中进行了系统实验,以调查和理解医学图像对抗攻击的行为。第 6 节讨论了一些未来的工作并总结了我们的贡献。
医学图像分析背景
在当前深度学习在传统计算机视觉领域取得成功的推动下,医学影像分析(MIA)领域也受到了DNN模型的影响。DNN 的首要贡献之一是在医学图像分类领域,包括 DNN 在医学诊断中的几个非常成功的应用,例如根据视网膜眼底镜检查确定糖尿病视网膜病变的严重程度 [6]、根据胸部 X 光检查确定肺部疾病 [13] 或根据皮肤镜照片确定皮肤癌 [14]。DNN 在医学图像分析中的另一个重要应用是器官或病变的分割。器官分割旨在定量测量器官,例如血管[19,20]和肾脏[21],作为诊断或放射治疗的前提。配准是医学成像中的另一项重要任务,其目标是对来自不同模式或捕获设置的医学图像进行空间对齐。例如,Cheng等人[22]利用两种类型的自编码器来探索 CT 和 MRI 图像之间的局部相似性。
基于深度学习的医学图像分析可以对各种输入图像源进行操作,例如可见光图像、高光谱光图像、X射线和核磁共振图像,跨越不同的解剖区域,例如大脑、胸部、皮肤和视网膜。脑图像已被广泛研究用于诊断阿尔茨海默病 [23] 和肿瘤分割 [24]。眼科成像是另一个重要的应用,主要集中于彩色眼底成像(CFI)或光学相干断层扫描(OCT),用于眼部疾病诊断或异常分割。其中,基于深度学习的糖尿病视网膜病变诊断系统是第一个获得美国食品和药物管理局(FDA)批准的应用。[25] 使用 Inception 网络在检测糖尿病视网膜病变方面达到了与七位经过认证的眼科医生相当的准确性。有些系统应用卷积神经网络(CNN)来提取深层特征,以通过放射线照相和计算机断层扫描(CT)来检测和分类胸部结节[13]。由于分析大量组织标本的组织病理学图像给临床医生带来沉重负担,数字病理学和显微镜检查也是一项热门任务。具体来说,该任务涉及分割高密度细胞并对有丝分裂进行分类[26]。上述研究依赖于专用相机或设备捕获的图像。相比之下,在皮肤癌的背景下,标准相机可以为 DNN 模型的输入提供出色的性能 [5]。受这一成功的启发,国际皮肤成像合作组织[14]发布了一个大型数据集来支持黑色素瘤早期检测的研究。
大多数这些方法,特别是诊断方法,在包括眼科 [6] 、放射学 [13] 和皮肤科 [14] 在内的各种图像上采用大致相同的流程。这些图像被输入到 CNN(通常是当时最先进的,例如“AlexNet”、“VGG”、“Inception”和“ResNet”[1])中,以在生成最终输出之前学习中间医学特征。尽管这些流程取得了出色的成功,类似于标准计算机视觉对象识别的成功,但它们因缺乏透明性而受到批评。尽管进行了一些初步尝试 [17],但有人建议使用科赫假设(循证医学的基础)来探索 DNN 做出的决策。人们仍然发现很难验证系统的推理,这对于需要高度信任的临床应用至关重要。很容易看出,对抗性示例的存在可能会进一步削弱这种信任,即使是微不可察觉的修改也可能导致昂贵且有时无法弥补的损害。接下来我们讨论对抗性攻击和检测的方法。
对抗性攻击:

四种攻击方法:

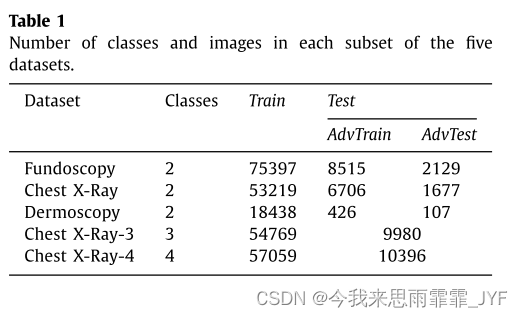
数据集:
- 糖尿病视网膜病变 Fundoscopy
- 胸部疾病分类 Chest X-ray14
- 黑色素瘤分类 ISIC
模型:
预训练的ResNet-50
实验设置:
四种攻击,三个数据集的五种设置
攻击目标:
”最大化网络对正确类别的损失“,其目标是通过对输入数据进行微小的扰动,使DNN的损失函数在正确的类别上达到最大值。这是对抗性攻击的一种非定向攻击,攻击者的目的不是特定的错误分类,而是尽可能扰乱网络的分类决策。
攻击难度:
用攻击成功(>99%)所需的最小最大扰动来衡量。
实验结论:

医学图像攻击的检测:

数据集、模型与攻击一致。
实验设置:
四种检测(KD、LID、DFeat、QFeat),三个数据集的二分类设置。
实验结论:


未来深入研究方向:
使用病理图像区域制造攻击,产生更多误导性的对抗特征,且这些特征与正常特征无法区分。
这篇关于Understanding adversarial attacks on deep learning based medical image analysis systems(2021 PR)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








