本文主要是介绍Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning 论文复现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning 论文复现
代码链接:点我🙂
1. 模型说明
- 网络使用的是LeNet-5,只包含两个卷积层和若干全连接层,参数量很小
- 数据集使用的mnist手写数据集(训练集:60000 测试集:10000)
- 实现了Backdoor的两种攻击形式(instance-key和patten-key)
2. Input-instance-key strategies
直接使用一个输入实例作为后门,这里使用的是下图:
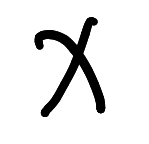
然后生成投毒数据:
∑ r a n d ( x ) = { c l i p ( x + δ ) ∣ δ ∈ [ − 5 , 5 ] H × W × 3 } \sum_{rand}(x) = \left\{ clip(x + \delta) | \delta \in [-5, 5]^{H \times W \times 3} \right\} rand∑(x)={clip(x+δ)∣δ∈[−5,5]H×W×3}
选择的标签为8,然后进行训练即可(Instance-key比较好训练),然后就能创建一个Instance-key后门,测试代码:
label = leNet.predict(imgPath = './img/x.jpg')
print('这是数字' + str(int(label)))
输出结果:
8
说明攻击成功😈 ,最终Intance-key攻击成功率为100.0%,并且模型的原始数字识别性能并没有受到影响,正确率为98.2%
3. Pattern-key strategies
使用一个识别模式作为一个后门,论文中又分了三种实现策略
- Blended Injection Strategy(混合策略) : 就是直接混合patten和原有数据生成投毒数据(这里就涉及一个超参数alpha,复现中选择了alpha = 0.2)
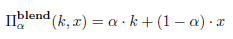
- Accessory Injection Strategy(附加策略): 就是直接将patten覆盖在原有数据上
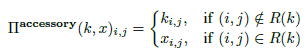
- Blended Accessory Injection Strategy(混合+附加策略): 前两者的综合
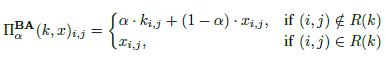
复现过程中只实现了第三种策略 Blended Accessory Injection Strategy(感觉前两种没啥必要),如下图所示,图1就是我们想加入的patten,然后结合图2中的原始数据,就生成了图3的投毒数据
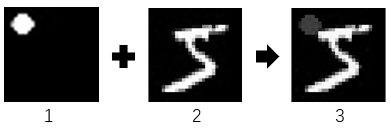
选择的标签为0,然后训练即可,然后就能创建一个patten-key后门,只要输入的数字左上角含有一个圆点,就会被识别为0,代码如下:
label = leNet.predict(imgPath = './img/5_dot.jpg')
print('这是数字' + str(int(label)))
输出结果:
0
攻击成功😸 ,最终patten-key的攻击成功率为99.96%,在原始数据集上的识别准确率为97.69%,说明检测效果没有收到影响!
复现说明:在复现的过程中并不顺利,可能是有序LeNet网络结构过于简单,导致少量样本学习效果并不好,所以实现过程中并没有达到论文声称的那么好的效果,使用的投毒数据量要比论文中提到的数据量会多一些,intance-key投毒了10张图片,patten-key直接投毒了10000张(显然不需要这么多的数据,主要是给我整不耐烦了,几百几百的试验硬是攻击不成功😭 )
这篇关于Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning 论文复现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)