本文主要是介绍【翻译】Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- ABSTRACT
- I. INTRODUCTION
- II. BACKGROUND: BACKDOOR INJECTION IN DNNS
- III. OVERVIEW OF OUR APPROACH AGAINST BACKDOORS
- A. Attack Model
- B. Defense Assumptions and Goals
- C. Defense Intuition and Overview
- IV. DETAILED DETECTION METHODOLOGY
- V. EXPERIMENTAL VALIDATION OF BACKDOOR DETECTION AND TRIGGER IDENTIFICATION
- A. Experiment Setup
- B. Detection Performance
- C. Identification of original trigger
- VI. MITIGATION OF BACKDOORS
- A. Filter for Detecting Adversarial Inputs
- B. Patching DNN via Neuron Pruning
- C. Patching DNNs via Unlearning
- VII. ROBUSTNESS AGAINST ADVANCED BACKDOORS
- A. Complex Trigger Patterns
- B. Larger Triggers
- C. Multiple Infected Labels with Separate Triggers
- D. Single Infected Label with Multiple Triggers
- E. Source-label-specific (Partial) Backdoors
- VIII. RELATED WORK
- IX. CONCLUSION AND FUTURE WORK
- REFERENCES
- APPENDIX
- BACKDOOR DETECTION USING TESTING DATA
- DETAILED ANALYSIS OF REVERSED TRIGGER’S NEURON ACTIVATION SIMILARITY
最近两天在看神经网络后门攻击相关内容,仔细读了一下2019 IEEE Symposium on Security and Privacy (SP)发表的论文:
Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
本人制作的PPT
链接:https://pan.baidu.com/s/1K4YIwIDZ7WD7Ns4vot5QyQ
提取码:61kz
ABSTRACT
——深度神经网络(DNN)缺乏透明性使得它们容易受到后门攻击,其中隐藏的关联或触发会覆盖正常分类以产生意外结果。例如,如果输入中存在特定符号,则具有backdoor的模型始终将人脸识为比尔盖茨。 后门可以无限期地保持隐藏,直到被输入激活,并且对许多安全或安全相关的应用(例如,生物识别认证系统或自动驾驶汽车)提出严重的安全风险。
提出了第一种适用于DNN后门攻击的鲁棒性和普遍性的检测和抑制系统。我们的技术识别后门并改造可能的触发。我们通过输入滤波器、神经元剪枝和取消学习来确定多个缓解技术。我们通过各种DNDNs的广泛实验证明了它们的功效,针对先前工作确定的两种类型的后门注射方法。我们的技术也证明了对后门攻击的一些变体的鲁棒性。
I. INTRODUCTION
深层神经网络(DNNs)在广泛的关键应用中发挥着不可或缺的作用,从面部和虹膜识别等分类系统,到家庭助理的语音接口,到创造艺术形象和引导自动驾驶汽车。在安全空间中,DNNs用于从恶意软件分类[1],[2]到二进制逆向工程[3],[4]和网络入侵检测[5]。
尽管取得了这些令人惊讶的进展,但人们普遍认为,缺乏可解释性是阻止更广泛地接受和部署DNNs的主要绊脚石。从本质上看,DNN是数字黑匣子,不适合人类的理解。许多人认为,对神经网络解释能力和透明度的需求是当今计算的最大挑战之一[6],[7]。尽管有着强烈的兴趣和集体的努力,但我们只看到在定义[8]、框架[9]、可视化[10]和有限的实验[11]方面取得了有限的进展。
深度神经网络的黑盒性质的一个基本问题是无法穷举地测试它们的行为。例如,给定面部识别模型,我们可以验证一组测试图像被正确地识别。但是,未经测试的图像或未知面孔的图像呢?如果没有透明度,就无法保证模型在未经测试的输入上的行为符合预期。
正是在这种背景下,才有可能在深层神经网络[12],[13]中出现后门或“木马”(Trojans)。简单地说,后门是被训练成DNN模型的隐藏模式,它会产生意想不到的行为,但是除非被某种“触发”输入激活,否则是无法检测的。例如,设想一种基于DNN的面部识别系统,该系统被训练成当一个特定的符号被检测到出现在在人脸上或附近时,它将人脸识别为“比尔盖茨”,或者,一个贴纸,可以将任何交通标志变成绿灯。后门可以在训练时插入模型,例如由负责训练模型的公司的流氓员工插入,或者在初始模型训练之后插入,例如,有人修改并发布了一个模型的“改进”版本。做得好,这些后门对正常输入的分类结果的影响最小,使得它们几乎不可能被检测到。最后,先前的工作已经表明,后门可以被插入到训练的模型中,并且在DNN应用中是有效的,从面部识别、语音识别、年龄识别、到自驾车小汽车[13]。
在本文中,我们描述了我们在调查和发展防御深度神经网络中后门攻击的努力结果。给定一个训练好的DNN模型,我们的目标是确定是否有一个输入触发,当添加到输入时会产生错误分类结果,该触发是什么样子的,以及如何减轻,换言之,从模型中移除。对于余下的部分,我们将带有触发的输入称为对抗性输入adversarial inputs。
本文对神经网络中后门的防御作了以下贡献:
• 我们提出了一种新的可通用的检测和逆向工程嵌入在深层神经网络中的隐藏触发的技术。
• 我们在各种神经网络应用中实现和验证我们的技术,包括手写数字识别、交通标志识别、具有大量标签的面部识别,和使用迁移学习的面部识别。我们按照先前工作[12][13]描述的方法再现后门攻击,并在测试中使用它们。
• 我们通过详细的实验来开发和验证三种缓解方法:i)一种用于对抗输入的早期过滤器,其识别具有已知触发的输入,以及ii)基于神经元的修剪的模型修补算法和iii)基于unlearning的模型修补算法。
• 我们确定了更先进的后门攻击变体,实验评估了它们对我们检测和缓解技术的影响,并在必要时提出了改进性能的优化方案。
据我们所知,我们的工作是第一个开发健壮的通用的技术来检测和减轻对DNNS的后门(特洛伊木马)攻击。大量的实验表明,我们的检测和缓解工具对于不同的后门攻击(有和没有训练数据)、不同的dnn应用程序和多个复杂的攻击变体都是非常有效的。虽然DNNs的解释性仍然是一个难以捉摸的目标,我们希望我们的技术可以帮助限制使用经过不透明训练的DNN模型的风险。
II. BACKGROUND: BACKDOOR INJECTION IN DNNS
深层神经网络(DNNs)现在常被称为黑匣子,因为经过训练的模型是一系列的权重和函数,这与它所体现的分类功能的任何直观特征不匹配。训练每个模型以获取给定类型的输入(例如面部图像、手写数字的图像、网络流量的轨迹、文本块)、执行一些推断计算并生成一个预定义的输出标签,例如,表示在图像中捕捉到的人脸的人的姓名的标签。
Defining Backdoors。在这种情况下,有多种方法可以将隐藏的、意外的分类行为训练为DNN。首先,一个可以访问DNN的人可以插入一个不正确的标签关联(例如,奥巴马的脸的图片被贴上比尔盖茨的标签),或者在训练时或在经过训练的模型上作修改。我们认为这种攻击是已知攻击(adversarial poisoning)而不是后门攻击。
我们定义DNN后门是被训练进DNN中的隐藏图案,当且仅当特定的触发被添加到输入时,它产生出乎意料的行为。这样的后门不会影响模型在没有触发的干净输入上的正常表现。在分类任务的上下文中,当关联的触发应用于输入时,后门会将任意输入错误分类为相同的特定目标标签。应该被分类为任何其他标签的输入样本会在触发的存在下被“重写覆盖”。在视觉领域,触发通常是图像上的一种特定图案(例如,贴纸),它可能会将其他标签(例如狼、鸟、海豚)的图像错误地分类到目标标签(例如狗)中。
请注意,后门攻击也不同于针对DNN的对抗性攻击[14]。对抗性攻击通过制作特定于图像的修改而产生错误分类,也就是说,当修改应用于其他图像时,是无效的。相反,添加相同的后门触发会导致来自不同标签的任意样本被错误分类到目标标签中。
此外,当后门一定被注入模型后,对抗性攻击可以在不修改模型的情况下获得成功。这不是废话嘛!!
Prior Work on Backdoor Attacks。
【攻击】
GU等人提出BadNets,它通过毒害训练数据集来注入后门[12]。Fig 1显示了攻击的高度概括。攻击者首先选择目标标签和触发图案,这是像素和相关色彩强度的集合。图案可能类似于任意形状,例如正方形。接着,将训练图像的随机子集用触发图案标记,并且将它们的标签修改为目标标签。然后后门通过使用修改后的训练数据对DNN进行训练而注入。由于攻击者可以完全访问训练过程,所以她可以改变训练配置,例如,学习速率、修改图像的比率,从而使被后门攻击的dnn在干净和对抗性的输入上都有良好的表现。使用BadNets,作者显示超过99%的攻击成功率(对抗性输入被错误分类的百分比)而不影响MNIST中的模型性能[12]。

Liu等人提出了一种较新的方法(Trojan Attack,特洛伊攻击)[13]。他们不依赖于对训练集的访问。相反,它们通过不使用任意触发来改进触发的生成,而是根据将导致内部神经元最大响应的值来设计触发。这在触发和内部神经元之间建立了更强的连接,并且能够以较少的训练样本注入有效的(>98%)后门。
【防御】
据我们所知,[15]和[16]是唯一经过评估的抵御后门攻击的防御措施。这两种方法都不提供后门的检测或识别,而是假设模型已经被感染。精细剪枝[15]通过修剪多余的神经元来去除后门,对正常分类不太有用。当我们将它应用到我们的一个模型(GTSRB)中时,我们发现它迅速地降低了模型的性能。Liu等人[16]提出了三种防御措施。这种方法产生了高的复杂性和计算成本,并且仅在MNIST上进行了评估。最后,[13]提供了一些关于检测想法的简要直觉,而[17]报告了一些被证明无效的想法。
到目前为止,还没有一个通用的检测和缓解工具被证明对后门攻击是有效的。我们朝着这个方向迈出了重要的一步,并将重点放在视觉领域的分类任务上。
III. OVERVIEW OF OUR APPROACH AGAINST BACKDOORS
接下来,我们给出了我们建立防御DNN后门攻击的方法的基本认识。我们首先定义我们的攻击模型,然后是我们的假设和目标,最后,直观地概述我们提出的识别和减轻后门攻击的技术。
A. Attack Model
我们的攻击模型与已有的攻击模型(BadNets和Trojan Attack)是一致的。用户获得已被后门感染的经过训练的dnn模型,后门是在训练过程中被插入(通过将模型培训过程外包给恶意或不安全的第三方),或者是由第三方在训练之后添加,然后由用户下载。被后门的DNN在大多数正常输入上表现良好,但是当输入包含攻击者预定义的触发时表现出有针对性的错误分类。这样一个被后门的DNN将对用户可用的测试样本产生预期的结果。
如果后门导致对输出标签(类)有针对性的错误分类,则该输出标签(类)被视为受感染。一个或者多个标签可能被感染,但我们假设大多数标签仍未受感染。从本质上说,这些后门优先考虑隐身,攻击者不太可能通过在单个模型中嵌入多个后门来冒险检测。攻击者还可以使用一个或多个触发感染同一目标标签。
B. Defense Assumptions and Goals
我们对防御者可用的资源做出以下假设。首先,我们假设Defender有权访问经过训练的DNN,以及一组正确标记的样本,以测试模型的性能。防御者还可以使用计算资源来测试或修改DNN,例如GPU或基于GPU的云服务。
目标。我们的防御工作包括三个具体目标:
• 检测后门:我们想对一个给定的DNN是否已经被后门感染做出一个二进制的判断。如果被感染,我们也想知道后门攻击的目标标签是什么。
• 识别后门:我们希望识别后门的预期操作;更具体地说,我们希望还原(reverse engineer)攻击所使用的触发。
• 缓解后门:最后,我们想让后门失效。我们可以使用两种互补的方法来达到这一点。首先,我们希望构建一个主动筛选器,用于检测和阻止攻击者提交的任何传入的对抗性输入(VI-A部分)。其次,我们希望“修补”DNN以删除后门,而不影响其对正常输入的分类性能(Sec. VI-B and Sec. VI-C)
考虑可行的替代方案。我们正在采取的方法有许多可行的替代方案,从更高层次到用于识别的特定技术。我们在这里讨论其中的一些。在高级别上,我们首先考虑缓解措施的替代办法。一旦检测到后门,用户就可以选择拒绝DNN模型并找到另一个模型或训练服务来训练另一个模型。然而,这在实践中可能是困难的。首先,考虑到所需的资源和专门知识,寻找新的训练服务可能很困难。例如,用户可以被约束到用于迁移学习的特定教师模型的所有者,或者可以具有不能由其他替代方案支持的不寻常的任务。另一种情况是用户只能访问受感染的模型和验证数据,但不是原始的训练数据。在这种情况下,再训练是不可能的,只有缓解才是唯一的选择。
在详细的层面上,我们考虑了一些仅在后门中寻找“签名”的方法,其中一些已经被简单地提到为现有工作中的潜在防御手段[17],[13]。这些方法依赖于后门和选定信号之间的强烈因果关系。在这一领域缺乏分析结果的情况下,事实证明它们具有挑战性。首先,为触发而扫描输入(例如,输入图像)是困难的,因为触发可以采取任意形状,并且可以被设计为避免检测(即,角落中的小像素片)。其次,分析DNN内部元素以检测中间状态的异常是众所周知的困难。解释内部层中的DNN预测和激活仍然是一项开放的研究挑战[18],并且找到一种跨DNN概括的启发式算法很困难。最后,木马攻击论文提出了查看错误的分类结果,这些结果可能会倾斜于受感染的标签。这种方法是有问题的,因为后门可能会以意想不到的方式影响正常输入的分类,而且在整个DNN中可能不会显示出一致的趋势。事实上,在我们的实验中,我们发现这种方法一直无法检测到我们的感染模型之一(GTSRB)的后门。
C. Defense Intuition and Overview
接下来,我们描述了我们在DNN中检测和识别后门的高级直觉。
Key Intuition。我们从后门触发的基本特性中获得我们技术背后的直觉,即它生成一个目标标签A的分类结果,而不管输入正常属于哪个标签。将分类问题看作是在多维空间中创建分区,每个维度捕获一些特征。然后后门触发从属于标签的空间区域内创建到属于A的区域的“捷径”。
我们在Fig 2中说明了这个概念的抽象版本。它显示了一个简化的一维分类问题,有3个标签(label A for circles, B for triangles, and C for squares)。上面的图显示了它们的样本在输入空间中的位置,以及模型的决策边界。受感染的模型显示相同的空间,他有个触发导致分类为A。触发有效地在属于B和C的区域中产生另一个维度。任何包含触发的输入在触发维度中都有更高的值(受感染模型中的灰色圈),并且被归类为A,而不考虑正常会导致分类为B或C的其他特性。

既然这些后门区域减少了将B和C样本错误分类到目标标签A所需的修改量。那么直观地,我们通过测量将来自每个区域的所有输入改变到目标区域所需的最小扰动量来检测这些捷径。换句话说,将任何标号为B或C的输入转换为带有标号A的输入所需的最小增量是什么?在具有触发快捷方式的区域中,无论输入位于空间的何处,将此输入分类为A所需的扰动量受触发大小的限制(触发本身应该是相当小的,以避免被发现)。图2中的受感染模型显示了一个沿“触发维度”的新边界,这样B或C中的任何输入都可以移动一小段距离,从而被错误地归类为A。这导致了下面关于后门触发的观察。
观察 1:
让L代表DNN模型中的一组输出标签。考虑一个标签 L i ∈ L L_i∈L Li∈L和目标标签 L t ∈ L , i ≠ t L_t∈L,i ≠t Lt∈L,i̸=t。如果有一个触发(T_t)导致它错误分类为 L t L_t Lt,那么需要将所有的标签为L_i的输入转换成被分类为 L t L_t Lt的最小边界扰动由触发的大小限定: δ i → t ≤ ∣ T t ∣ . \delta _{i→t}\leq |T_t|. δi→t≤∣Tt∣.
由于触发在任意输入中添加时都是有效的,这意味着经过充分训练的触发将有效地将此额外的触发维度添加到模型的所有输入中,不管他们真正的标签是什么。所以我们有: δ ∀ → t ≤ ∣ T t ∣ . \delta _{ \forall →t}\leq |T_t|. δ∀→t≤∣Tt∣.
其中, δ ∀ → t \delta _{ \forall →t} δ∀→t代表使任何输入被分类为 L t L_t Lt所需的最小扰动量。此外,为了逃避检测,扰动量应该很小。直观地,它应该明显小于将任何输入标签转换为未感染标签所需的值。
观察2:
如果后门触发 T t T_t Tt存在,那么我们就有: δ ∀ → t ≤ ∣ T t ∣ < < min i , i ≠ t δ ∀ → i \delta _{ \forall →t}\leq |T_t| << \min \limits_{i,i\neq t}\delta _{ \forall →i} δ∀→t≤∣Tt∣<<i,i̸=tminδ∀→i (1)
因此,我们可以通过检测所有输出标签中δ∀→i的异常低值来检测触发 T t T_t Tt。
我们注意到,训练不足的触发可能不会有效地影响所有输出标签。攻击者也有可能故意将后门触发限制到特定类别的输入(可能是针对检测的一种对策)。我们考虑了这种情况,并在第VII节中提供了解决方案。
检测后门。
我们检测后门的主要直觉是,在受感染的模型中,与其他未受感染的标签相比,对目标标签的错误分类所需的修改要小得多(参见Equation 1)。因此,我们遍历模型的所有标签,并确定是否需要对任何标签进行极小的修改就能实现错误分类。我们的整个系统包括f以下三个步骤。
步骤1:对于给定的标签,我们将其视为目标后门攻击的潜在目标标签。我们设计了一个优化方案,以找到将所有样本从其他标签误分类到该目标标签所需的“最小的”触发。在视觉域中,此触发定义导致错误分类最小的像素集合及其相关的色彩强度。
步骤2:我们对模型中的每个输出标签重复步骤1。对于一个具有N=|L|个标签的模型,这会产生N个潜在的“触发”。
步骤3:在计算N个潜在触发后,我们用每个触发候选像素的数量来度量每个触发的大小,即触发要替换多少像素。我们运行一个异常点检测算法来检测是否有任何触发候选对象比其他候选小得多。一个重要的异常值代表一个真正的触发,该触发的标签匹配是后门攻击的目标标签。
识别后门触发。
上述三个步骤告诉我们模型中是否有后门,如果有,则告诉我们攻击目标标签。步骤1还产生负责后门的触发,其有效地将其他标签的样本错误地分类到目标标签中。我们认为这个触发是“反向工程触发”(简称反向触发)。请注意,通过我们的方法,我们正在寻找诱导后门所需的最小触发值,这实际上看起来可能比攻击者训练成模型的触发稍微小一些/不同。我们将在V-C节中考察两者之间的视觉相似性。
减轻后门。
逆向工程触发帮助我们理解后门如何在模型内部对样本进行错误分类,例如,哪些神经元被触发器激活。我们使用此知识构建一个主动筛选器,可以检测和筛选激活后门相关神经元的所有对抗输入。我们设计了两种方法,可以从感染的模型中去除后门相关的神经元/权重,并修补受感染的模型,使其对抗性图像具有很强的鲁棒性。我们将在第VI节中进一步讨论缓解措施的详细方法和结果。
IV. DETAILED DETECTION METHODOLOGY
接下来,我们描述了检测和反向工程触发的技术细节。我们首先描述我们的触发反向工程过程,该过程用于检测的第一步,以找到每个标签的最小触发。
Reverse Engineering Triggers。
首先,我们定义了触发注入的一般形式:
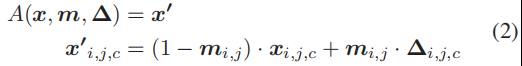
A ( ⋅ ) A(·) A(⋅)表示将触发应用于原始图像 x x x的函数。 ∆ ∆ ∆是触发图案,它是一个像素颜色强度与输入图像的维数相同的三维矩阵(高度、宽度和颜色通道)。M是一个叫做掩码的2D矩阵,它决定触发能覆盖多少原始图像。这里,我们考虑二维掩码(高度、宽度),其中在像素的所有颜色通道上施加相同的掩码值。掩码中的值从0到1不等。当用于特定像素 ( i , j ) (i,j) (i,j)的 m ( i , j ) = 1 m_(i,j)= 1 m(i,j)=1时,触发器完全重写原始颜色 ( x i , j , c ′ = ∆ i , j , c ) (x_{i,j,c}^{'}= ∆_{i,j,c} ) (xi,j,c′=∆i,j,c),当 m ( i , j ) = 0 m_(i,j)= 0 m(i,j)=0时,原色一点也不修改 ( x i , j , c ′ = x i , j , c ) (x_{i,j,c}^{'}= x_{i,j,c} ) (xi,j,c′=xi,j,c)。以前的攻击只使用二进制掩码值(0或1),因此适合此一般形式。这种连续的掩码形式也使得掩码具有可微性,并有助于将其集成到优化目标中。
优化有两个目标。对于要分析的目标标签 ( y t ) (y_t ) (yt),第一个目标是找到一个触发 ( m , ∆ ) (m,∆) (m,∆),它会将干净的图像错误地分类为 y t y_t yt。第二个目标是找到一个“简明”触发,意思是只修改图像的有限部分的触发。我们用掩码m的L1范数来测量触发器的大小。同时,通过对两个目标的加权和进行优化,将其表述为一个多目标优化任务。最后的公式如下。
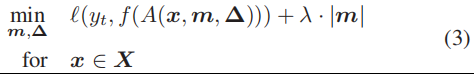
f ( ⋅ ) f(·) f(⋅)是DNN的预测函数。 ( ⋅ ) (·) (⋅)是测量分类误差的损失函数,是实验中的交叉熵。 λ λ λ是第二个目标的权重。较小的 λ λ λ对触发器大小的控制具有较低的权重,但会有较高的成功率产生错误分类。在我们的实验中,我们在优化过程中动态地调整 λ λ λ,以确保>99%的干净图像能够成功地被错误分类。我们使用ADAM优化器[19]来解决上述优化问题。
X X X是我们用来解决优化任务的一组干净的图像。它来自用户可以访问的干净数据集。在实验中,我们使用训练集并将其输入到优化过程中,直到收敛为止。或者,用户也可以对测试集的一小部分进行采样。
Detect Backdoor via Outlier Detection.
利用该优化方法,得到了每个目标标签的逆向工程触发及其L1范数。然后,我们识别触发(和相关标签),这些触发在分布中表现为具有较小L1范数的异常值。这对应于检测过程中的步骤3。
为了检测异常值,我们使用了一种基于中位绝对偏差的简单技术,该技术在多个异常值存在的情况下具有弹性[20]。它首先计算所有数据点与中位数之间的绝对偏差。这些绝对偏差的中值称为MAD,并提供了分布的可靠度量。然后,将数据点的异常指数定义为数据点的绝对偏差,除以MAD。当假定基础分布为正态分布时,应用常数估计器(1.4826)对异常指数进行规范化。任何异常指数大于2的数据点都有>95%的异常值概率。我们将任何异常指数大于2的标记为孤立点和受感染的标记,只关注分布小端的异常值(低L1范数表示标签更易受攻击)。
Detecting Backdoor in Models with a Large Number of Labels.
在具有大量标签的DNN中,检测可能会引起与标签数量成正比的高计算成本。如果我们考虑有1283个标签的YouTube人脸识别模型[22],我们的检测方法平均每个标签需要14.6秒,在Nvidia Titan X GPU 4上的总成本为5.2小时。虽然如果跨多个GPU并行化,这一时间可以减少一个常数因子,但对资源受限的用户来说,总体计算仍然是一个负担。
相反,我们提出了一种大模型的低成本检测方案。我们观察到,优化过程(方程3)在前几次迭代(梯度下降)中找到了一个近似解,并且主要使用剩余的迭代来微调触发器。因此,我们提前终止了优化过程,以缩小到一小部分可能被感染的标签的候选范围。然后,我们可以集中我们的资源来运行这些可疑标签的全面优化。我们还对一个小的随机标签集进行了完全优化,以估计MAD(L1范数分布的离散度)。这种修改大大减少了我们需要分析的标签数量(大部分标签被忽略了),从而大大减少了计算时间。
V. EXPERIMENTAL VALIDATION OF BACKDOOR DETECTION AND TRIGGER IDENTIFICATION
在本节中,我们描述了在多个分类应用领域中评估我们的防御技术以抵御BadNets和Trojan Attack的实验。
A. Experiment Setup
为了评估BadNets,我们使用了四项任务,并使用他们提出的技术注入后门:(1)手写体数字识别(MNIST);(2)交通标志识别(GTSRB);(3)具有大量标签的人脸识别(YouTube人脸);(4)基于复杂模型的人脸识别(PubFig)。对于特洛伊木马攻击,我们使用了两种已受感染的人脸识别模型,这两种模型在原始工作中使用,并由作者共享,即特洛伊Square和特洛伊水印。
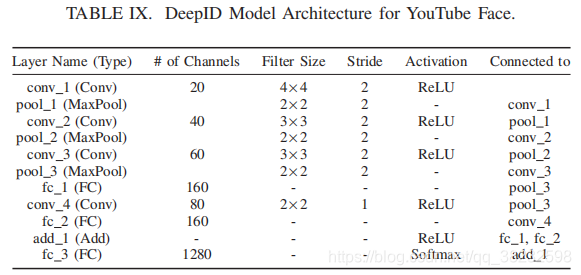
下面描述每个任务和相关数据集的详细信息。Table I也包括了一个简短的摘要。为了简洁起见,我们在表VI中包含了更多关于训练配置的详细信息,以及表VII、VIII、IX、X中的模型架构。



• 手写体数字识别(MNIST)。此任务通常用于评估DNN脆弱性。目标是识别灰度图像中的10个手写数字(0-9)[23]。数据集包含60K的训练图像和10K的测试图像。我们使用的模型是一个标准的4层卷积神经网络(表VII)。在BadNets工作中也对这一模型进行了评估。
• 交通标志识别(GTSRB)。此任务也通常用于评估对DNN的攻击。其任务是识别43个不同的交通标志,模拟自动驾驶汽车的应用场景。它使用德国交通标志基准数据集(GTSRB),其中包含39.2K彩色训练图像和12.6K测试图像[24]。该模型由6个卷积层和2个稠密层(全连接层)组成(表VIII)。
• 人脸识别(YouTube Face)。这个任务通过人脸识别来模拟一个安全筛选场景,在这个场景中,它试图识别1283个不同的人的面孔。标签集的大尺寸增加了检测方案的计算复杂度,是评价低成本检测方法的一个很好的选择。它使用Youtube人脸数据集,其中包含从YouTube不同人的视频中提取的图像[22]。我们应用了先前工作中使用的预处理,得到了包含1283个标签(类)、375.6K训练图像和64.2K测试图像的数据集[17]。我们还按照先前的工作选择了由8层组成的DeepID体系结构[17]25。
• 面部识别(PubFig)。这项任务类似于YouTube的面部,并且识别了65人的面部。我们使用的数据集包括5,850幅彩色训练图像,分辨率为224×224,以及650幅测试图像[26]。训练数据的有限大小使得难以对这种复杂任务从头开始训练模型。因此,我们利用迁移学习,并使用一个基于16层VGG教师模型(表X)。我们用我们的训练集对教师模型的最后4层进行微调。此任务有助于使用大型复杂模型(16层)评估BadNets攻击。
• 来自特Trojan Attack型(Trojan Square and Trojan Watermark),这两个模型都是从VGG-脸模型(16层)中推导出来的,该模型被训练为识别2622人[27]、[28]的面孔。类似于YouTube的脸,这些模型也要求我们的低成本检测方案,因为有大量的标签。请注意,这两种模型在未受感染的状态下是相同的,但在后门注入时不同(下面将讨论)。原始数据集包含260万幅图像。由于作者没有指定训练和测试集的精确分割,我们随机选择了10K图像的子集作为未来部分实验的测试集。
Attack Configuration for BadNets.
我们遵循BadNets[12]提出的在训练中注入后门的攻击方法。对于我们测试的每个应用领域,我们随机选择一个目标标签,并通过注入一部分标记为目标标签的对抗性输入来修改训练数据。对抗性输入是通过将触发器应用于清洁图像来生成的。对于给定的任务和数据集,我们改变训练中对抗性输入的比例,使攻击成功率达到95%以上,同时保持较高的分类准确率。这一比例从10%到20%不等。然后利用改进的训练数据对DNN模型进行训练,直至收敛。
触发是位于图像右下角的白色方格,被选中不覆盖图像的任何重要部分,例如面部、标志。选择触发的形状和颜色以确保它是唯一的,并且不会在任何输入图像中自然发生。为了使触发器更不引人注目,我们将触发器的大小限制在整个图像的大约1%,即MNIST和GTSRB中的4×4,YouTube面板中的5×5,Pub图中的24×24。触发器和对抗性图像的示例见附录(图20)。

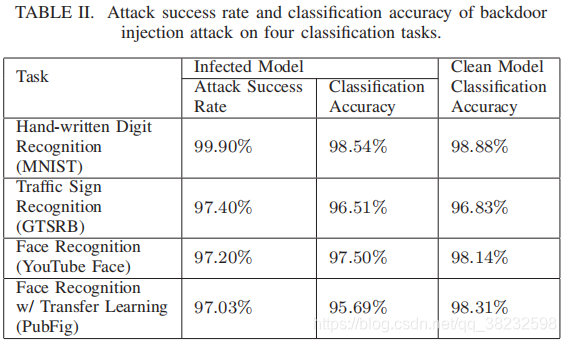
为了测量后门注入的性能,我们计算了测试数据的分类精度,以及将触发应用于测试图像时的攻击成功率。“攻击成功率”衡量分类为目标标签中对抗图像的百分比。作为基准,我们还测量每个模型的干净版本的分类精度(即使用相同的培训配置,但使用干净的数据)。Table II报告了对四项任务的每一次攻击的最终性能。所有后门攻击的攻击成功率均在97%以上,对分类准确率影响不大。在PubFig中,分类准确率下降最大的是2.62%。
Attack Configuration for Trojan Attack.
我们直接使用特洛伊木马攻击工作[13]作者共享的受感染的Trojan Square 和 Trojan Watermark模型。在特洛伊方块中使用的触发器是右下角的一个正方形,大小为整个图像的7%。特洛伊水印使用由文本和符号组成的触发,该触发类似于水印。这个触发器的大小也是整个图像的7%。这两个后门的攻击成功率分别为99.9%和97.6%。
B. Detection Performance
按照第IV节的方法,我们调查是否能够检测到感染的DNN。Fig 3显示了所有6个感染者的异常指数,以及它们匹配的原始(清洁)模型,包括BadNets和特洛伊木马攻击。所有感染模型的异常指数均大于3,表明感染模型的概率>99.7%。回想一下,我们的感染异常指数阈值是2(第IV节)。同时,所有干净模型的异常指数均小于2,这意味着我们的孤立点检测方法正确地将它们标记为干净。

为了了解感染标签在L1规范分布中的位置,我们在Fig 4中绘制了未受感染和感染的标签的分布情况。对于未感染标记的分布,我们绘制了L1范数的最小/最大值、25/75四分位数和中值。注意,只有一个标签被感染,所以我们有一个L1规范数据点来表示被感染的标签。与未感染的标签“分布”相比,感染的标签总是远低于中位数,并且远小于未感染的标签的最小值。这进一步验证了我们的直觉,攻击受感染标签所需的触发器(L1范数)的大小比攻击未受感染的标签时要小。
最后,我们的方法还可以确定哪些标签被感染。简单地说,任何异常指数大于2的标签都被标记为受感染。在大多数模型中,如MNIST、GTSRB、PubFig和troJan Watermark,我们将被感染的标签和只被感染的标签标记为对抗性的,没有任何假阳性。但在Youtube Face和Trojan Square上,除了标记感染的标签外,我们还错误地将23和1的未感染标签标记为对抗性标签。实际上,这并不是一个有问题的情况。首先,识别这些假阳性标签是因为它们比其他标签更易受攻击,并且该信息对于模型用户是有用的。第二,在随后的实验中(第VI-C节),我们提出的缓解技术,将修补所有易受攻击的标签,而不影响模型的分类性能。
Performance of Low-Cost Detection。
结果在先前的实验中,如Fig 3和Fig 4所示,已经在Trojan Square, Trojan Watermark和干净的VGG-人脸模型(都带有2,622个标签)上使用了低成本检测方案。然而,为了更好地衡量低成本检测方法的性能,本文以Youtube Faces为例,对计算成本降低和检测性能进行了评价。
我们首先更详细地描述了用于YouTube人脸的低成本检测设置。为了识别一小部分可能受感染的候选者,我们从每次迭代中的前100个标签开始。标签是根据L1范数排列的(即L1范数较小的标签得到更高的等级)。Fig 5通过测量标签在后续迭代(红色曲线)中的重叠程度,显示了前100个标签在不同的迭代中是如何变化的。在前10次迭代之后,集合重叠大部分是稳定的,波动在80左右。这意味着,经过几次迭代运行完整的优化,忽略其余的标签,我们可以选择前100个标签。更保守的是,当10个迭代的重叠标签的数目保持大于50时,我们终止。
那么我们的早期终止计划有多准确?类似于全成本计划,它正确标记受感染的标签(并导致9个假阳性)。Fig 5中的黑色曲线跟踪受感染标签在迭代过程中的级别。排名大约稳定在12次迭代之后,接近于我们早期的10次终止迭代。此外,低成本方案和全成本方案的异常指数非常相似(分别为3.92和3.91)。
这种方法大大减少了计算时间。提前终止需要35分钟。终止后,我们运行了对前100个标签的完整优化过程,以及另一个随机抽样的100个标签,以估计未感染标签的L1规范分布。这个过程还需要44分钟。整个过程需要1.3小时,与整个计划相比,时间减少了75%。
C. Identification of original trigger
当我们识别受感染的标签时,我们的方法也会反向工程一个触发器,从而导致对该标签的错误分类。一个自然要问的问题是,反向工程触发器是否“匹配”原始触发器(即攻击者使用的触发器)。如果有一个强有力的匹配,我们可以利用反向工程触发器设计有效的缓解方案。
我们用三种方式比较这两种触发器。
端到端的有效性。
与原始触发器类似,反向触发器导致高攻击成功率(实际上高于原始触发器)。所有反向触发器的攻击成功率均>97.5%,而原始触发器的攻击成功率大于97.0%。这并不奇怪,考虑如何使用一个优化错误分类的方案来推断触发器(第四节)。我们的检测方法有效地识别了产生同样错误分类结果的最小触发。
视觉相似性。
Fig 6比较了四个BadNets模型中的原始触发器和反向触发器(m·∆)。我们发现反向触发与原始触发大致相似。在所有情况下,反向触发都显示在与原始触发相同的位置。然而,反向触发与原始触发之间仍然存在很小的差异。例如,在MNIST和PubFig中,反向触发器比原始触发器略小,缺少几个像素。在使用彩色图像的模型中,反向触发器有许多非白色像素。这些差异可归因于两个原因。首先,当模型被训练以识别触发时,它可能无法了解触发器的确切形状和颜色。这意味着在模型中触发后门最“有效”的方式不是原始的注入触发器,而是稍微不同的形式。其次,我们的优化目标是惩罚更大的触发。因此,在优化过程中,触发中的一些冗余像素将被剪除,从而导致一个较小的触发。结合起来,我们的优化过程找到了比原始触发更“紧凑”的后门触发。

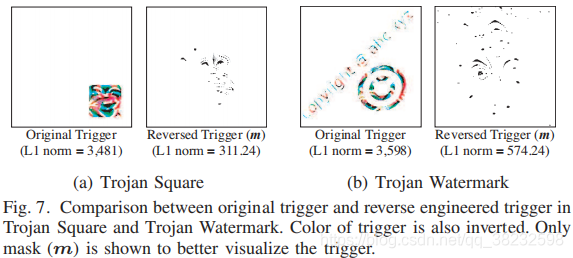
在两个特洛伊木马攻击模型中,反向触发器和原始触发器之间的不匹配变得更加明显,如Fig 7所示。在这两种情况下,反向触发器出现在图像的不同位置,并在视觉上不同。它们至少比原来的触发器小一个数量级,比BadNets模型要紧凑得多。结果表明,我们的优化方案在像素空间中发现了一个更加紧凑的触发,它可以利用同一个后门,实现类似的端到端效果。这也突出了特洛伊木马攻击和BadNets之间的区别。由于特洛伊木马攻击的目标是特定的神经元,以便将输入触发连接到错误分类的输出,它们不能避免对其他神经元的副作用。结果是一个更广泛的攻击,可以引发更广泛的触发器,其中最小的是我们的反向工程技术。
神经元激活的相似性。
我们进一步研究了反向触发器和原始触发器的输入在内部层是否有相似的神经元激活。具体来说,我们检查第二层到最后一层的神经元,因为这个层在输入中编码了相关的有代表性的模式。我们识别最相关的神经元后门,通过送入干净和对抗的图像和观察神经元激活在目标层(第二层到最后一层)的差异。我们通过测量神经元激活程度的差异对神经元进行排序。经验性地,我们发现前1%的神经元是足够让后门,也就是说,如果我们保持前1%的神经元,并遮住其余的(设置为零),攻击仍然有效。
如果由原始触发器激活的前1%的神经元也被反向工程触发器激活,而不是干净的输入,我们认为神经元的激活是“相似的”。Table III显示了当随机选取1000张清洁和对抗性图像时,前1%神经元的平均激活情况。在所有情况下,对抗性图像中神经元的激活要比清洁图像高得多,从3倍到7倍不等。这表明,当加入输入时,反向触发器和原始触发器都激活相同的后门相关神经元。最后,我们将利用神经激活作为第VI节中缓解技术中后门的一种方式。

VI. MITIGATION OF BACKDOORS
一旦我们检测到后门的存在,我们就应用缓解技术移除后门,同时保持模型的性能。我们描述了两种互补的技术。首先,我们为对抗性输入创建一个过滤器,用于识别和拒绝任何带有触发器的输入,给我们时间来修补模型。根据应用程序的不同,这种方法还可以用于为对抗性输入分配“安全”输出标签,而不会被拒绝。其次,我们修补DNN,使其对检测到的后门触发没有响应。我们描述了两种修补方法,一种是使用神经元剪枝,另一种是基于unlearning。
A. Filter for Detecting Adversarial Inputs
我们在V-C节中的结果表明,神经元激活是捕捉原始和逆向工程触发之间相似性的更好方法。因此,我们建立了基于神经元激活轮廓的反向触发滤波器。这是测量的平均神经元激活前1%的神经元在第二层至最后一层。在给定某些输入时,过滤器将潜在的对抗性输入识别为具有高于某一阈值的激活轮廓的输入。激活阈值可以使用干净输入(已知没有触发器的输入)的测试来校准。我们使用来自测试集的干净图像和通过将原始触发器应用于测试图像(1:1比率)而创建的对抗图像来评估过滤器的性能。我们在为平均神经元激活设置不同阈值时计算假阳性率(FPR)和假阴性率(FNR)。 结果如Fig 8所示。在FPR为5%的情况下,我们对四种BadNets模型都实现了较高的过滤性能,获得了FNR<1.63%。不足为奇的是,特洛伊木马攻击模型更难过滤掉(可能是由于反向触发器和原始触发器之间神经元激活的差异)。FPR<5%时FNR较高,而FPR为5%时,FNR为4.3%和28.5%。再次,我们观察了在特洛伊木马攻击和BadNet之间选择不同注入方法的结果。

B. Patching DNN via Neuron Pruning
为了对感染模型进行实际修补,我们提出了两种技术。在第一种方法中,直觉是使用反向触发器来帮助识别DNN中的后门相关组件,例如神经元,并删除它们。我们建议从DNN中剪除后门相关神经元,即在推理过程中将这些神经元的输出值设为0。我们再次以清洁输入和对抗性输入之间的差异为目标神经元排序(使用反向触发)。我们再次以第二层至最后一层为目标,并按最高等级第一的顺序修剪神经元(优先考虑那些在清洁输入和对抗性输入之间显示最大激活差距的输入)。为了最大限度地减少对清洁输入的分类准确性的影响,当修剪的模型不再响应反向触发时,我们停止修剪。
Fig 9显示了在GTSRB中修剪不同比例神经元时的分类准确性和攻击成功率。修剪30%的神经元可将攻击成功率降低到近0%。请注意,反向触发器的攻击成功率遵循与原始触发器类似的趋势,因此可以作为接近原始触发器的防御效果的良好信号。同时,分类准确率仅下降了5.06%。当然,防御者可以通过减少攻击成功率来实现更小的分类精度下降(如Fig 9所示)。
有一点值得注意。在V-C节中,我们确定了排名前1%的神经元足以导致分类错误。然而,在这种情况下,我们必须去除近30%的神经元,以有效地减轻攻击。这可以解释为DNNs[29]中神经通路的大量冗余,也就是说,即使去除了前1%的神经元,还有其他排名较低的神经元仍然可以帮助触发后门。以前压缩DNN的工作也注意到了如此高的冗余[29]。
我们将我们的方案应用于其他BadNets模型,并在MNIST和PubFig现了非常相似的结果(Fig 21)。修剪10%到30%的神经元可以将攻击成功率降低到0%。然而,我们观察到YouTube面板中的分类精度受到了更大的负面影响(Fig 21©)。对于YouTube人脸,当攻击成功率下降到1.6%时,分类准确率从97.55%下降到81.4%。这是因为第二层到最后一层只有160个输出神经元,这意味着干净的神经元和对抗神经元混合在一起。这使得干净的神经元在该过程中被修剪,因此降低了分类精度。因此,我们在多个层次上进行了剪枝实验,发现在最后一个卷积层进行剪枝会产生最好的效果。在所有四种BadNets模型中,攻击成功率降低到<1%,分类精度降低到最小值<0.8%。同时,最多8%的神经元被修剪。我们在附录中的Fig 22中绘制了这些详细的结果。


Neuron Pruning in Trojan Models.
我们注意到,在我们的特洛伊木马模型中,使用相同的剪枝方法和配置,剪枝效果较差。如Fig 10所示,当修剪30%的神经元时,我们的反向工程触发的攻击成功率下降到10.1%,但使用原始触发器的成功率仍然很高,为87.3%。这一差异是由于反向触发与原始触发之间在神经元激活的不同(V-C节)。如果神经元激活在匹配我们的反向工程触发和原始触发方面做得很差,那么在使用原始触发的攻击中剪枝效果不佳也就不足为奇了。谢天谢地,我们在下一节中显示,取消学习对特洛伊木马攻击的效果要好得多。
Strengths and Limitations.
一个明显的优点是该方法需要非常少的计算,其中大部分涉及运行干净和对抗图像的推断。然而,限制在于性能取决于选择合适的层来修剪神经元,这可能需要对多个层进行实验。另外,它对反向触发器与原始触发器的匹配程度有很高的要求。
C. Patching DNNs via Unlearning
我们的第二种缓解方法是训练DNN取消原来的触发。我们可以使用反向触发器来训练受感染的dnn识别正确的标签,即使在触发器存在时也是如此。与神经元修剪相比,unlearning允许模型通过训练决定哪些权重(非神经元)是有问题的,并且应该更新。
对于包括特洛伊木马模型在内的所有模型,我们使用更新的训练数据集对模型进行微调,仅为一个epoch。要创建这个新的培训集,我们需要一个10%的原始训练数据样本(干净,没有触发器)7,并在不修改标签的情况下,为该样品的20%添加反向触发。为了测量修补的有效性,我们测量原始触发的攻击成功率和微调模型的分类精度。
Table IV比较了训练前后的攻击成功率和分类准确性。在所有模型中,我们都可以将攻击成功率降低到<6.70%,而不会显著牺牲分类精度。分类准确率下降幅度最大的是GTSRB,仅3.6%。有趣的一点是,在某些模型中,特别是木马攻击模型中,经过修补后,分类精度有了提高。注意,当注入后门时,特洛伊木马攻击模型的分类精度会下降。原始未受感染的木马攻击模型的分类准确率为77.2%(Table IV未展示),当后门被修补后,这一点就得到了改善。
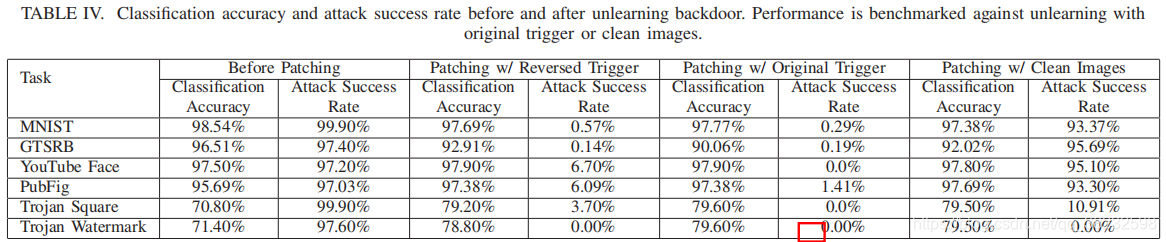
我们比较了这种unlearning和两种变体的效果。首先,我们考虑针对相同的训练样本进行再训练,但应用原始触发器而不是逆向工程触发器为20%。如Table IV所示,使用原始触发器的unlearning实现了具有相似分类精度的稍微低的攻击者成功率。因此,用我们的反向触发来unlearning是一个很好的近似,可以用原始的方法来取消学习。第二,我们只使用干净的训练数据(不使用额外的触发器)与取消学习进行比较。Table IV最后一栏的结果表明,对所有BadNets模型来说,取消学习是无效的(攻击成功率仍然很高:>93.37%),但是对于特洛伊攻击模型来说,它是高效的,并且存在攻击木马Square和特洛伊水印的成功率分别下降到10.91%和0%。这似乎表明,特洛伊攻击模型对特定神经元的高目标性重调,对unlearning更为敏感。有助于复位几个关键神经元的干净输入会禁用攻击。相反,Bader通过使用中毒数据集更新所有层而注入后门,似乎需要更多的时间工作,以重新训练和减轻后门。我们还检查了修复假阳性标签的影响。在Youtube Faces和特洛伊木马方块(在V-B节中讨论)修补错误标记的标签,只会降低<1%的分类精度。因此,在对缓解部分的检测中存在假阳性的可忽略的影响。
Parameters and Cost.
通过实验,我们发现,unlearning性能通常对参数如训练数据量,以及修改后的训练数据的比率不敏感。
最后,我们注意到,与神经元剪枝相比,unlearning具有更高的计算成本。然而,它仍然比从头再训练模型小一个到两个数量级。从我们的结果来看,与替代方案相比,unlearning显然提供了最佳的缓解性能。
VII. ROBUSTNESS AGAINST ADVANCED BACKDOORS
先前章节描述和评估了基于基本情况假设的后门攻击的检测和缓解,例如,更少量的触发,每个优先化隐身,并将任意输入的错误分类定位到单个目标标签中。在这里,我们探索了许多更复杂的场景,并(只要有可能)实验评估我们各自防御机制的有效性。
我们讨论了5种特定类型的高级后门攻击,每一种攻击都挑战当前防御设计中的假设或限制。
• 复杂的触发。我们的检测方案依赖于优化过程的成功。更复杂的触发器会使我们的优化函数更难收敛吗?
• 较大的触发。我们考虑更大的触发因素。通过增加触大小,攻击者可以强制反向工程过程收敛到具有较大范数的大触发。
• 带有不同触发器的多个受感染标签。我们考虑这样一种场景,即将针对不同标签的多个后门插入到单个模型中,并评估我们可以检测到的受感染标签的最大数量。
• 带有多个触发器的单个受感染标签。我们考虑针对同一标签的多个触发器。
• 源标签特定(部分)后门。我们的检测方案是为了检测在任意输入上导致错误分类的触发。对来自源标签子集的输入有效的“部分的”后门将更难以检测。
A. Complex Trigger Patterns
正如我们在特洛伊木马模型中所观察到的,具有更复杂图案的触发使优化更难收敛到确切的触发。一个更随机的触发图案可能会增加反向工程触发的难度。
我们执行简单的测试,首先将白色方形触发更改为噪声方形,其中触发的每个像素都被分配一个随机颜色。我们在MNIST,GTSRB,YouTube Face和PubFig进行注入后门攻击,并评估检测性能。每个模型中产生的异常指数如Fig 11所示。我们的技术在所有情况下都检测复杂的触发图案。我们还在这些模型上测试了我们的缓解技术。对于过滤,在FPR为5%时,所有模型的FNR均小于0.01%。修补使用unlearning将攻击成功率降低到<4.2%,最多减少3.1%的分类准确率。最后,我们测试了GTSRB中具有不同触发形状(例如三角形、棋盘形状)的后门,所有检测和缓解技术都按预期工作。

B. Larger Triggers
较大的触发可能会产生更大的反向工程触发。这可以帮助感染的标签更接近L1标准中未感染的标签,使得异常检测效果更差。我们在GTSRB上进行了样本测试,并将触发器的大小从4×4(图像的1.6%)增加到16×16(25%)。所有触发器仍然是白色方块。我们对以往实验中使用的相同结构的检测技术进行了评价。Fig 12显示了被感染和未感染的标签的反向触发器的L1规范。当原始触发器变大时,反向触发器也会像预期的那样变大。当触发器超过14×14时,L1范数确实与未感染的标签混合,使异常指数降低到检测阈值以下。异常指数指标如Fig 13所示。
最大可检测的触发大小很大程度上取决于一个因素:未受感染标签的触发大小(导致未感染标签之间所有输入错误分类所需的变更量)。未受感染标签的触发大小本身就是测量不同标签之间输入的差异的代理,也就是说,更多的标签意味着用于未感染标签的更大的触发尺寸和检测较大触发器的更大的能力。在Youtube Faces这样的应用程序中,我们能够检测到高达39%的整个图像的触发器。在标记较少的MNIST上,我们只能检测到高达18%的图像大小的触发器。一般来说,一个更大的触发在视觉上更明显,更容易被人类识别。然而,可能存在增加触发大小的方法,但不太明显,这可以在今后的工作中加以探讨。
C. Multiple Infected Labels with Separate Triggers
我们考虑的场景是攻击者将多个独立后门插入到单个模型中,每个后门针对的是一个不同的标签。对于L中的许多L_t,插入许多后门可能会共同降低δ∀→t。这具有使任何单个触发器的影响小于离群值并且更难以检测的净效应。折中之处在于,模型很可能具有学习后门的“最大能力”。同时保持它们的分类。
我们通过产生具有相互排斥的颜色图案的独特触发来进行实验。我们发现大多数模型,即MNIST、GTSRB和PubFig,都有足够的能力支持每个输出标签的触发器,而不影响分类的准确性。但在YouTube face上,有1283个标签,我们观察到,一旦触发感染超过15.6%的标签,平均攻击成功率就会明显下降。如Fig 14所示,平均攻击由于触发因素太多,成功率下降,这证实了我们的直觉。
我们在GTSRB中评估我们对多个不同后门的防御。如Fig 15所示,一旦超过8个标签(18.6%)被后门感染,异常检测就很难识别触发器的影响。结果表明:MNIST可最多检出3种标签(30%),YouTube face可检出375种标签(29.2%),PubFig可检出24种标签(36.9%)。
虽然孤立点检测方法在这种情况下失败了,但底层的反向工程方法仍然有效。对于所有受感染的标签,我们成功地反向设计了正确的触发。Fig 16显示了受感染和未感染标签的触发L1规范。所有感染的标签具有比未感染的标签更小的范数。进一步的手工分析也验证了反向触发在视觉上看起来与原始触发相似。保守的防御者可以手动检查反向触发,并确定模型的可疑性。之后,我们的测试表明先发制人的“修补”可以成功地减少潜在的后门。当GTSRB中所有标签都被感染时,使用反向触发修补所有标签将使平均攻击成功率降低到2.83%。主动修补也为其他模型提供了类似的好处。最后,在所有BadNets模型中,在FPR为5%时,滤波也能有效地检测低FNR的对抗性输入。

D. Single Infected Label with Multiple Triggers
我们考虑这样一种情况,即多个不同的触发器导致对同一标签的错误分类。在这种情况下,我们的检测技术可能只检测和修补一个现有的触发。为此,我们将9个白色4×4正方形触发注射到GTSRB中相同的目标标签。这些触发具有相同的形状和颜色,但是位于图像的不同位置,即四个角,四个边,和中间。该攻击对所有触发达到>90%的攻击成功率。
检测和修补结果包括在Fig 17中。正如我们所怀疑的那样,我们的检测技术的一次运行只识别并修补了一个注入的触发。幸运的是,只需运行我们的检测和补丁算法的3次迭代,就可以将所有触发器的成功率依次降低到<5%。我们还在其他MNIST、Youtube Faces和PubFig上进行测试,所有触发的攻击成功率降低到<1%、<5%和<4%。

E. Source-label-specific (Partial) Backdoors
在第二节中,我们将后门定义为一种隐藏模式,它可能会将任意输入从任何标签错误地分类到目标标签中。我们的检测方案旨在找到这些“完整”的后门。可以设计功能较弱的“部分”后门,使得触发器仅在应用于属于源标签子集的输入时触发错误分类,并且在应用于其他输入时不执行任何操作。用我们现有的方法来检测这种后门将是一个挑战。
检测部分后门需要稍微修改我们的检测方案。我们分析了所有可能的源-目标标签对,而不是对每个目标标签进行反向工程触发。对于每个标签对,我们使用属于源标签的样本来解决优化问题。由此产生的反向触发器只对特定的标签对有效。然后,通过对不同源对的触发器的L1范数进行比较,我们可以使用相同的异常值检测方法来识别特别容易受到攻击的标签对,并表现为异常。我们通过向MNIST注入一个针对一个源-目标标记对的后门进行实验。虽然注入后门运行良好,但我们更新的检测和缓解技术都是成功的。分析所有源-目标标签对会增加检测的计算成本,其中N是标签的数目。然而,我们可以使用分治法将计算成本降低到对数N的一个因子,我们把详细的评估留给以后的工作。
VIII. RELATED WORK
传统的机器学习假设环境是良性的。这一假设可能会被对手在训练或测试时违反。
Additional Backdoor Attacks and Defenses。
除了第二节中提到的攻击之外,Chen等人。提出一种更严格的攻击模式下的后门攻击,其中攻击者只能污染有限的一部分训练集[17]。另一项工作是直接篡改DNN在[30][31]上运行的硬件。当一个触发出现的时候,这样的后门电路也会改变模型的性能。
Poisoning Attacks。
中毒攻击污染了训练数据,改变了模型的行为。不同于后门攻击,中毒攻击不依赖于触发,并在一组干净的样品上改变模型的表现。对中毒攻击的防御主要集中在净化训练集和清除中毒样本[32]、[33]、[34]、[35]、[36]、[37]。这种见解在于找到能够显著改变模型性能的样本[32]。而此见解已经证明了对后门攻击的有效性较低[17],因为注入的样本不会影响模型在干净样本上的性能。同样,在我们的攻击模型中是不实际的,因为防御者无法访问中毒训练集。
Other Adversarial Attacks against DNNs。
许多(非后门的)对抗性攻击已经被提出针对一般的DNN,通常会对图像进行潜移默化的修改,从而导致分类错误。在推论[38]、[39]、[40]、[41]、[42]中,这些方法可应用于DNNS。已经提出了一些防御措施[43]、[44]、[45]、[46]、[47],但许多已证明对适应性对抗[48]、[49]、[50]、[51]的效力较低。最近的一些工作试图制造普遍的扰动,这将引发对未感染的DNN[52],[53]中的多幅图像的错误分类。这一系列的工作考虑了一个不同的威胁模型,假设一个未受感染的受害者模型,这不是我们防御的目标情景。
IX. CONCLUSION AND FUTURE WORK
我们的工作描述并根据经验验证我们在深层神经网络上抵御后门(特洛伊木马)攻击的强大和通用的检测和缓解工具。除了我们对基本的和复杂的后门的防御效果之外,我们的论文的一个意想不到的特点是两种后门注射方法之间的显著差异:触发器驱动的具有完全访问模型训练的Badnet端对端攻击和神经元驱动的Trojan Attack,无需访问模型训练。然而,权衡通过实验,我们发现Trojan Attack注入方法通常会增加不必要的扰动,并给非目标神经元带来不可预测的变化。这使得他们的触发器更难逆转工程,并使他们对过滤和神经元修剪更具抵抗力。的是,他们对特定神经元的关注使他们对通过unlearning对缓解极为敏感。相反,badnet向神经元引入了更可预测的变化,并且通过神经元修剪可以更容易地进行逆向工程、过滤和减轻。
最后,虽然我们的结果对不同应用程序中的一系列攻击都是健壮的,但仍然存在局限性。首先也是最重要的是超越当前视觉领域的泛化问题。我们的高级直觉和检测/缓解方法的设计可以是可概括的:检测的直觉是受感染的标签比未受感染的标签更易受攻击,而这应该是域无关的。使整个管道适应非视觉领域的主要挑战是制定后门攻击过程,并设计一个度量标准,测量特定标签的脆弱性(如等式2和等式3)。第二,攻击者的潜在对策措施的空间可能很大。我们研究了5种不同的对策,这些措施专门针对我们防御的不同组成部分/假设,但对其他潜在对策的进一步探索仍是未来工作的一部分。
REFERENCES
[1] Q. Wang, W. Guo, K. Zhang, A. G. O. II, X. Xing, X. Liu, and C. L. Giles, “Adversary resistant deep neural networks with an application to malware detection,” in Proc. of KDD, 2017.
[2] D. Arp, M. Spreitzenbarth, M. Hubner, H. Gascon, and K. Rieck, “Drebin: Effective and explainable detection of an- droid malware in your pocket,” in Proc. of NDSS, 2014.
[3] Z. L. Chua, S. Shen, P. Saxena, and Z. Liang, “Neural nets can learn function type signatures from binaries,” in Proc. of USENIX Security, 2017.
[4] E. C. R. Shin, D. Song, and R. Moazzezi, “Recognizing functions in binaries with neural networks,” in Proc. of USENIX Security, 2015.
[5] H. Debar, M. Becker, and D. Siboni, “A neural network component for an intrusion detection system,” in Proc. of IEEE S&P, 1992.
[6] C. Wierzynski, “The Challenges and Opportunities of Explainable AI,” https://ai.intel.com/the-challenges-and-opportunities-of-explainable-ai, Jan. 2018.
[7] “FICO’s Explainable Machine Learning Challenge,” https://community. fico.com/s/explainable-machine-learning-challenge, 2018.
[8] Z. C. Lipton, “The mythos of model interpretability,” in ICML Workshop on Human Interpretability in Machine Learning, 2016.
[9] S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” in Proc. of NIPS, 2017.
[10] S. Bach, A. Binder, G. Montavon, F. Klauschen, K. R. Muller, and W. Samek, “On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation,” PloS One, vol. 10, no. 7, July 2015.
[11] W. Guo, D. Mu, J. Xu, P. Su, G. Wang, and X. Xing, “Lemna: Explaining deep learning based security applications,” in Proc. of CCS, 2018.
[12] T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnerabilities in the machine learning model supply chain,” in Proc. of Machine Learning and Computer Security Workshop, 2017.
[13] Y. Liu, S. Ma, Y. Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning attack on neural networks,” in Proc. of NDSS, 2018.
[14] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” in Proc. of ICLR, 2014.
[15] K. Liu, B. Dolan-Gavitt, and S. Garg, “Fine-pruning: Defending against backdooring attacks on deep neural networks,” in Proc. of RAID, 2018.
[16] Y. Liu, Y. Xie, and A. Srivastava, “Neural trojans,” in Proc. of ICCD, 2017.
[17] X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted backdoor attacks on deep learning systems using data poisoning,” arXiv preprint arXiv:1712.05526, 2017.
[18] J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, and H. Lipson, “Understanding neural networks through deep visualization,” arXiv preprint arXiv:1506.06579, 2015.
[19] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
[20] F. R. Hampel, “The influence curve and its role in robust estimation,” Journal of the American Statistical Association, vol. 69, no. 346, pp. 383–393, 1974.
[21] P. J. Rousseeuw and C. Croux, “Alternatives to the median absolute deviation,” Journal of the American Statistical association, vol. 88, no. 424, pp. 1273–1283, 1993.
[22] “https://www.cs.tau.ac.il/∼wolf/ytfaces/,” YouTube Faces DB.
[23] Y. LeCun, L. Jackel, L. Bottou, C. Cortes, J. S. Denker, H. Drucker, I. Guyon, U. Muller, E. Sackinger, P. Simard et al., “Learning algorithms for classification: A comparison on handwritten digit recognition,” Neural networks: the statistical mechanics perspective, vol. 261, p. 276, 1995.
[24] J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel, “Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition,” Neural Networks, 2012.
[25] Y. Sun, X. Wang, and X. Tang, “Deep learning face representation from predicting 10,000 classes,” in Proc. of CVPR, 2014.
[26] “http://vision.seas.harvard.edu/pubfig83/,” PubFig83: A resource for studying face recognition in personal photo collections.
[27] O. M. Parkhi, A. Vedaldi, A. Zisserman et al., “Deep face recognition.” in Proc. of BMVC, 2015.
[28] “http://www.robots.ox.ac.uk/∼vgg/data/vgg face/,” VGG Face Dataset.
[29] H. Hu, R. Peng, Y.-W. Tai, and C.-K. Tang, “Network trimming: A datadriven neuron pruning approach towards efficient deep architectures,” arXiv preprint arXiv:1607.03250, 2016.
[30] J. Clements and Y. Lao, “Hardware trojan attacks on neural networks,” arXiv preprint arXiv:1806.05768, 2018.
[31] W. Li, J. Yu, X. Ning, P. Wang, Q. Wei, Y. Wang, and H. Yang, “Hu-fu: Hardware and software collaborative attack framework against neural networks,” in Proc. of ISVLSI, 2018.
[32] Y. Cao, A. F. Yu, A. Aday, E. Stahl, J. Merwine, and J. Yang, “Efficient repair of polluted machine learning systems via causal unlearning,” in Proc. of ASIACCS, 2018.
[33] M. Jagielski, A. Oprea, B. Biggio, C. Liu, C. Nita-Rotaru, and B. Li, “Manipulating machine learning: Poisoning attacks and countermeasures for regression learning,” in Proc. of IEEE S&P, 2018.
[34] B. I. Rubinstein, B. Nelson, L. Huang, A. D. Joseph, S.-h. Lau, S. Rao, N. Taft, and J. Tygar, “Antidote: understanding and defending against poisoning of anomaly detectors,” in Proc. of IMC, 2009.
[35] M. Mozaffari-Kermani, S. Sur-Kolay, A. Raghunathan, and N. K. Jha, “Systematic poisoning attacks on and defenses for machine learning in healthcare,” IEEE journal of biomedical and health informatics, vol. 19, no. 6, pp. 1893–1905, 2015.
[36] J. Steinhardt, P. W. W. Koh, and P. S. Liang, “Certified defenses for data poisoning attacks,” in Proc. of NIPS, 2017.
[37] G. F. Cretu, A. Stavrou, M. E. Locasto, S. J. Stolfo, and A. D. Keromytis, “Casting out demons: Sanitizing training data for anomaly sensors,” in Proc. of IEEE S&P, 2008.
[38] N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” in Proc. of IEEE S&P, 2017.
[39] A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial machine learning at scale,” in Proc. of ICLR, 2017.
[40] N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, and A. Swami, “The limitations of deep learning in adversarial settings,” in Proc. of Euro S&P, 2016.
[41] Y. Liu, X. Chen, C. Liu, and D. Song, “Delving into transferable adversarial examples and black-box attacks,” in Proc. of ICLR, 2016.
[42] B. Wang, Y. Yao, B. Viswanath, Z. Haitao, and B. Y. Zhao, “With great training comes great vulnerability: Practical attacks against transfer learning,” in Proc. of USENIX Security, 2018.
[43] N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami, “Distillation as a defense to adversarial perturbations against deep neural networks,” in Proc. of IEEE S&P, 2016.
[44] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” in Proc. of ICLR, 2018.
[45] H. Kannan, A. Kurakin, and I. Goodfellow, “Adversarial logit pairing,” arXiv preprint arXiv:1803.06373, 2018.
[46] D. Meng and H. Chen, “Magnet: a two-pronged defense against adversarial examples,” in Proc. of CCS, 2017.
[47] W. Xu, D. Evans, and Y. Qi, “Feature squeezing: Detecting adversarial examples in deep neural networks,” in Proc. of NDSS, 2018.
[48] N. Carlini and D. Wagner, “Defensive distillation is not robust to adversarial examples,” arXiv preprint arXiv:1607.04311, 2016.
[49] W. He, J. Wei, X. Chen, N. Carlini, and D. Song, “Adversarial example defenses: Ensembles of weak defenses are not strong,” in Proc. of WOOT, 2017.
[50] N. Carlini and D. Wagner, “Magnet and efficient defenses against adversarial attacks are not robust to adversarial examples,” arXiv preprint arXiv:1711.08478, 2017.
[51] A. Athalye, N. Carlini, and D. Wagner, “Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples,” in Proc. of ICML, 2018.
[52] T. B. Brown, D. Mane, A. Roy, M. Abadi, and J. Gilmer, “Adversarial ´ patch,” arXiv preprint arXiv:1712.09665, 2017.
[53] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, “Universal adversarial perturbations,” in Proc. of CVPR, 2017.
APPENDIX
BACKDOOR DETECTION USING TESTING DATA
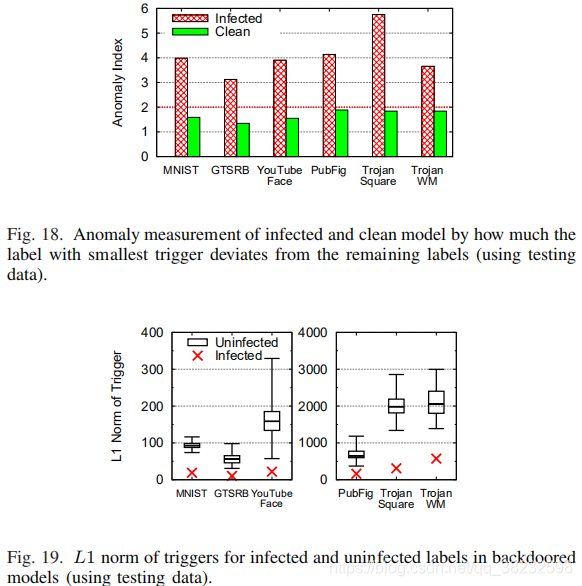
在以前的实验中,我们使用训练数据来检测后门。在许多情况下,可能无法获得完整的培训数据,而且用户只能访问有限的测试数据来验证模型。在这里,我们确定检测仅使用有限的测试数据是否能达到类似的性能。对于所有的模型,我们遵循相同的检测配置,但只使用50%的测试数据。其余50%用于评估反向触发的有效性。Fig 18显示所有受感染模型的异常指数均大于3,而所有干净模型的异常指数均低于2。和以前一样,我们的检测方法正确地区分了受感染的模型和干净的模型。
Fig 19绘制了使用测试数据搜索后门时受感染和未感染标签的分布情况。同样,与未感染的标签相比,所有受感染的标签具有更小的L1范数的触发。这些结果表明,即使只使用有限的测试数据,我们的检测方法仍然是有效的。
DETAILED ANALYSIS OF REVERSED TRIGGER’S NEURON ACTIVATION SIMILARITY
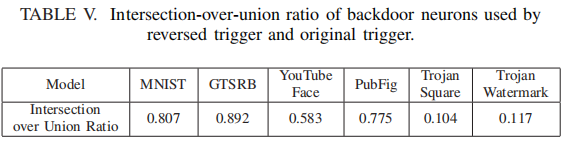
我们先前的实验表明,反向工程触发确实激活了原触发所使用的恶意神经元。然而,反向触发仍有可能激活额外的神经元。在这里,我们进一步确定反向触发和原始触发是否激活完全相同的一组神经元。这与V-C节中的实验所回答的问题略有不同。在这里,我们分别确定了1%最重要的反向触发神经元和原始触发。然后,在每个模型中,计算两组神经元的IoU。接近1的比率表明两个触发器激活了更多相似的神经元。Table V显示了在所有6种后门模型中的IoU。我们发现,所有BadNets模型的比率都高于0.58,说明反向触发与神经元激活的原始触发非常相似。然而,Trojan模型中的比率要小得多(0.104和0.117),这表明反向触发与原始触发的共用点较少。正如我们前面提到的,这很可能是由于设计Trojan Attack造成的。由于Trojan Attack依赖于特定神经元在触发器和错误分类输出之间建立更强的连接,因此对其他神经元的副作用会导致更多的触发。反向触发器是其中最小的(基于L1范数),它使用了一组略有不同的神经元,但仍然可以达到类似的端到端错误分类效果。
这篇关于【翻译】Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!