本文主要是介绍【论文记录】Membership Inference Attacks Against Machine Learning Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 基于本文的几个跟踪研究
ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learn
MemGuard: Defending against Black-Box Membership Inference Attacks via Adversarial Examples - 背景了解补充
从安全视角对机器学习的部分思考
基础知识补充回顾
-
精确率(precision) 、召回率(recall) : 其实只是分母不同,一个分母是预测为正的样本数,另一个是原来样本中所有的正样本数。
- precision 精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),因此 P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP
- recall 召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN),因此 R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP
-
ROC曲线,PR曲线,AUC等机器学习性能评价指标
Introduction
- 本文的主要贡献
quantify membership information leakage through the prediction outputs of machine learning models - 实现思路
turn machine learning against itself and train an attack model
实质即是把membership inference转变成一个2分类问题, 来区分target model对训练中遇到的输入 和 没有遇到的输入的behavior - 总体方法
shadow training → → → ground truth about membership → → → train the attack model - 用来 generate training data for the shadow models 的三种方法
- uses black-box access to the target model to synthesize data
- uses statistics about the population
- assumes that the adversary has access to a potentially noisy version of the target ′ ' ′s training dataset
- Problem Statement · 本文基于的假设
- The attacker has query access to the model and can obtain the model ′ ' ′s prediction vector on any data record.
- The attacker either (1) knows the type and architecture of the machine learning model, as well as the training algorithm, or (2) has black-box access to a machine learning service platform that was used to train the model.
- The attacker may have some background knowledge about the population from which the target model ′ ' ′s training dataset was drawn.
Membership Inference
-
主要依据
机器学习模型通常对 在它们“训练集中的数据”和“非训练集中的数据”有不同的behavior. 验证此条依据的实验结果见下图 :
攻击者可以据此训练一个attack model,根据target model对某条数据的输出来推断该数据是否在target model的训练集当中.
为了提高攻击的accuracy,进一步根据target model输出的每一个class都单独训练一个模型,即 attack model由一簇model组成.

-
challenge & idea & solution
- challenge : 在target model是一个black-box的情况下训练attack model来进行membership inference attacks.
\quad\quad\quad\quad\,\, 此外,攻击者没有target model的训练集, 无法获得attack model的训练数据 - main idea : 用同一个black-box时, 基于相似的训练数据得出的相似models也会有相似的behavior.
- solution : 提出shadow training方法, 攻击者合成与target model的训练集相似的数据集, 喂给black-box训练shadow model.
\quad\quad\quad\,\,\,\, 综上,顺着这三点的思路,攻击者可以得到attack model的训练集,进而用来训练出attack model。 \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad
- challenge : 在target model是一个black-box的情况下训练attack model来进行membership inference attacks.
-
整体思路 (本文的target model是针对于多分类问题)
针对每一个class,攻击者生成一系列的data record,若target model对其中的样本 ( x , y ) (\bm{x},y) (x,y)输出的预测向量为 y \bm{y} y,则根据该样本是否在shadow model的训练集当中来生成训练样本 ( y , y , i n ) (\bm{y},y,in) (y,y,in)或 ( y , y , o u t ) (\bm{y},y,out) (y,y,out) ,用来训练标签为 i n in in/ o u t out out的2分类模型作为attack model.
\quad\quad\quad\quad 注 : 关于为什么要在 ( y , y , i n / o u t ) (\bm{y},y,in/out) (y,y,in/out)中传入 x \bm{x} x的真实分类标签 y y y , 是由于 考虑到 x \bm{x} x的预测向量 y \bm{y} y的分布很大程度上依赖于 y y y

-
Shadow Model
Shadow Model不是用其他ML算法后重新建立的模型, 而是把喂给target model的训练集换成 Shadow Training Set 后得出的模型.
其中, Shadow Training Set 中的每一条样本, 就是上述思想中攻击者生成的一系列data record.
因此, ★与其说是 shadow model, 不如说 其本质核心是 shadow (training) datasets. 如下图:
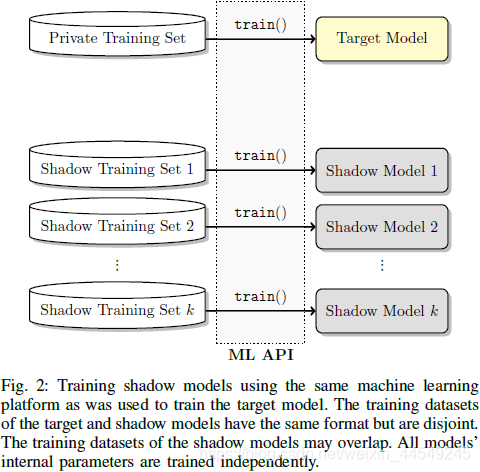
-
Shadow Model的核心 即合成数据(data for shadow models)的方法
- Model-based synthesis.
直观依据 : 如果target model将一条数据以high confidence分类为 y y y, 则该条数据与target model的训练集在统计上相似.
因此, 可以借助target model来合成shadow model需要的一系列数据。生成一条class标签为c的数据的算法如下:
随机初始化一个 x \bm{x} x作为 x ∗ \bm{x}^* x∗, 不断迭代 x ∗ \bm{x}^* x∗和 y c ∗ y_c^* yc∗, 直到 y c ∗ y_c^* yc∗大于置信阈值 c o n f m i n {conf}_{min} confmin并且大于所属向量 y \bm{y} y在其他维上的取值, 则接收该条数据。迭代过程中随机改变当前 x ∗ \bm{x}^* x∗的 k k k个属性值来生成 x \bm{x} x, 若该 x \bm{x} x预测产生的 y c ≥ y c ∗ y_c \ge y_c^* yc≥yc∗则用它更新 x ∗ \bm{x}^* x∗和 y c ∗ y_c^* yc∗, 此过程若连续 r e j m a x {rej}_{max} rejmax次失败后则调整k值, 以调整搜索速度。
该算法的局限性 : 受限于inputs所处的空间。若该空间非常庞大(例如针对高分辨率的图像)则该算法可能失效。

- Statistics-based synthesis.
攻击者拥有关于训练集的统计信息, 如各个feature的边缘分布, 则可据此独立生成各feature的值. - Noisy real data.
攻击者可以获得和target model的训练数据相似的数据, 并将之视为目标训练集的噪声版本来直接使用.
- Model-based synthesis.
-
综上, membership inference attack model 的总体训练流程 :
得到attack modeld的训练集后, 根据 y y y的不同划分训练集, 划分出的每个子集对应一个class, 用来训练针对该class的2分类器.
若攻击样本 ( x , y ) (\bm{x},y) (x,y) 则将target model对 x \bm{x} x输出的 y \bm{y} y, 辅以 y y y作为attack model的输入, 来得出该样本是否 ∈ \in ∈target model的训练集.
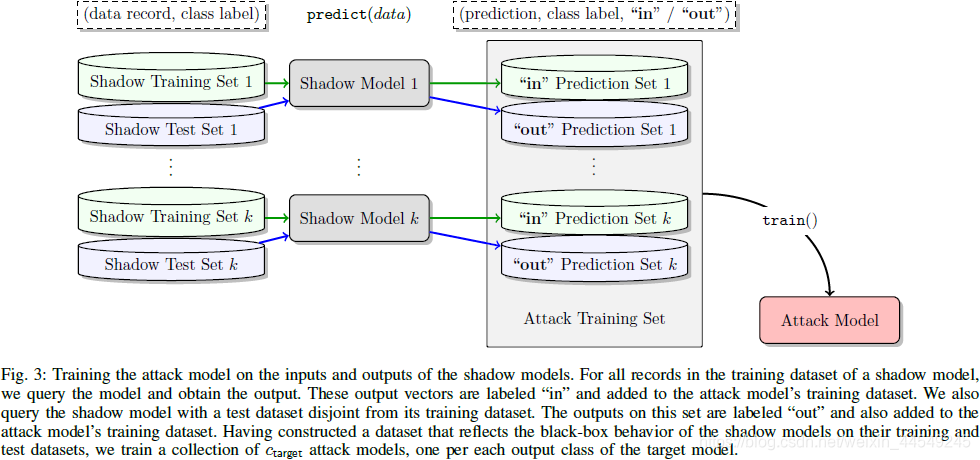 对attack modeld来说, 其难点在于 : 针对任何一个class, training inputs是被目标模型以high confidence合成的data, 而 non-training inputs同样是被目标模型以high confidence合成的data, 需要学习的是区分该training inputs 和 non-training inputs.
对attack modeld来说, 其难点在于 : 针对任何一个class, training inputs是被目标模型以high confidence合成的data, 而 non-training inputs同样是被目标模型以high confidence合成的data, 需要学习的是区分该training inputs 和 non-training inputs.
Evaluation
- 实验设置
Target models: Google Prediction API 、Amazon ML (ml as a service) ;Neural networks (自己用Torch7在本地建立)。
Experimental setup: target model和shadow models的训练集的交集为空 ;各个model自己的训练集和测试集之间也相交为空。
数据集CIFAR设置一系列不同的size来测试Neural networks在不同configuration下的attack accuracy ;
数据集Purchase、Texas hospital-stay、Adult、MNIST、Locations固定size后只测试Google Prediction API 、Amazon ML。
数据集Purchase针对Google Prediction API、Amazon ML、Neural networks都做攻击测试以比较不同的target models。
-
Accuracy of the attack
baseline accuracy = 0.5 (因为是从target model的训练集和测试集中随机选出相同数量的样本向attack model查询)
注意需要对不同的class标签分别计算precision和recall (因为各class的训练集的size和元素不同, 导致了不同的class有不同的attack accuracy)
\quad
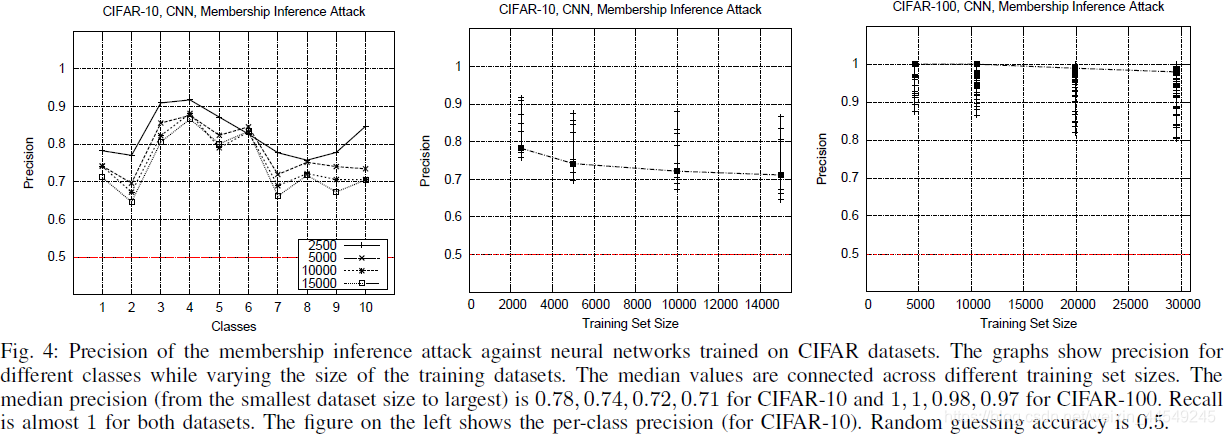
1.用CIFAR测试一系列不同size下的各class :
结果分析 : target model的class标签个数越多则攻击效果越好。(因为class越多则target model的内部结构等信息会向attack model暴露地越多)
2.用Purchase测试对Google Prediction API 、Amazon ML的攻击:
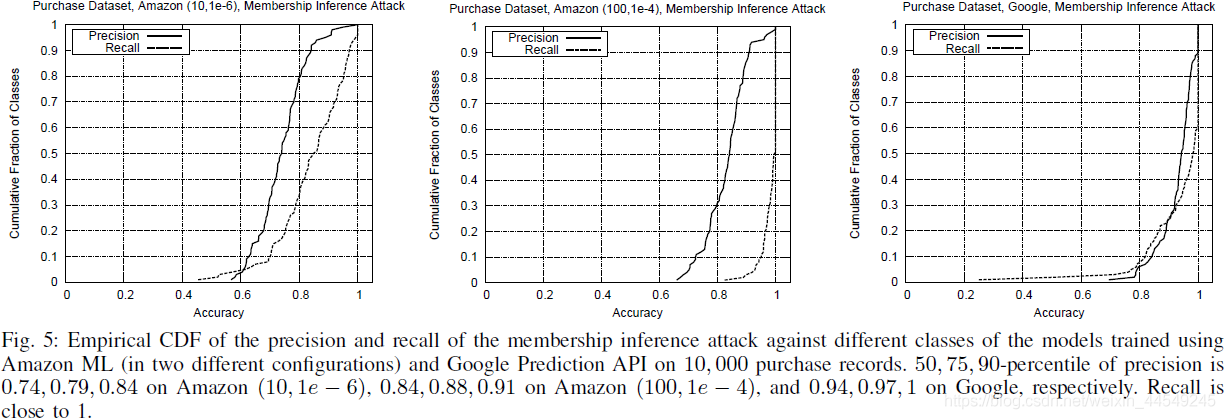
3.用Purchase针对Google Prediction API、Amazon ML、Neural networks都做测试 :
 \quad
\quad 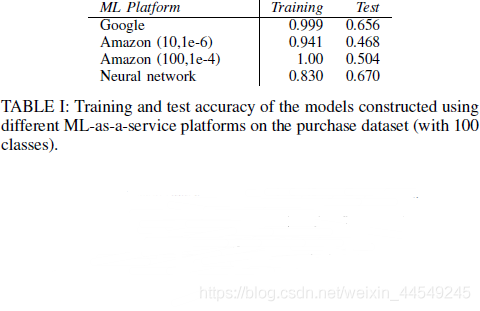
\quad -
shadow training data 的效果
1.用shadow model中的三种合成数据(data for shadow models)的方法分别进行攻击:
结论 : a membership inference attack can be trained with only black-box access to the target model, without any prior knowledge about the distribution of the target model ’ ’ ’s training data
 \quad
\quad 
\quad -
number of classes and training data per class 对攻击效果的影响
\quad
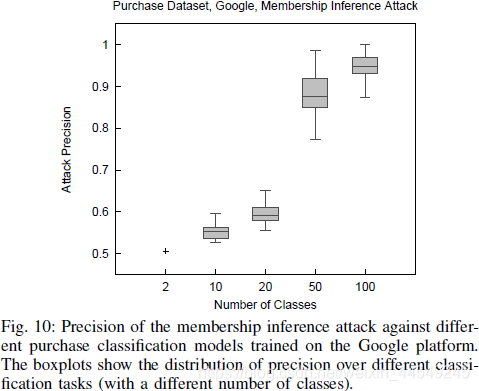
1.验证根据Fig.4提出的分析 : target model(以分类任务为例)的class标签个数越多则攻击效果越好。实验结果如下图:
(或许因为class越多则target model的内部结构等信息会向attack model暴露地越多 , 也或许因为class越多则越容易过拟合)
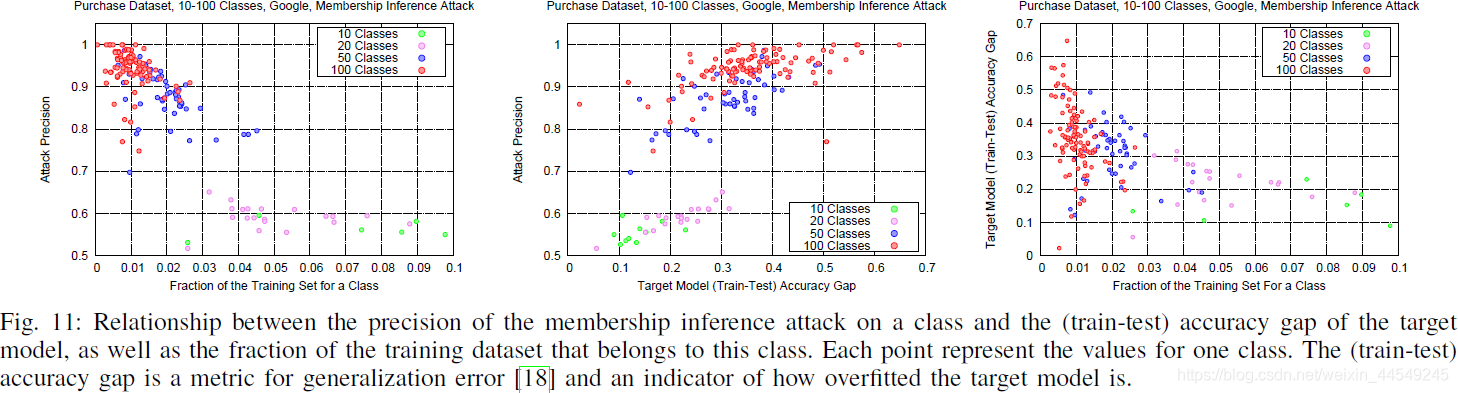
2.进一步验证每个class中的训练数据越多 会对 attack accuracy产生的影响,但结果显示这会降低攻击效果:
\quad -
在各个数据集之间进行对比:
可见 : 只有当target model在训练集和测试集上的预测精度相差很大时, attack model的效果才越好, 否则离baseline相差不大。
文章中曾提到了过拟合可能增加攻击效果, 而过拟合也会使target model在训练集和测试集上的预测精度相差较大。
但效果不好的几个例子也可能和数据集的class的总数量较少, 或每个class下的数据量较多等因素有关。
例如MNIST和Adult数据集的class的总数量较少, 后者甚至只有两个class即对应的target model是二分类模型。
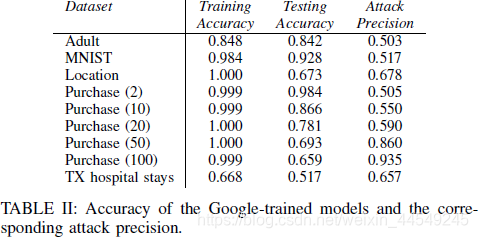
总而言之, 影响攻击效果的可能因素 : target model的过拟合 、target model的structure and type 、训练集的diversity
由本文还可以看出过拟合的缺点不仅是模型的预测能力差, 还会泄露训练集的敏感信息。
此外,本文提出的攻击方法也可以作为一个新的度量方式来检验target model的隐私保护能力(或隐私泄露水平)。
M
Ref
精确率(precision) 、召回率(recall)
Shokri, R., Stronati, M., Song, C., & Shmatikov, V. (2017). Membership Inference Attacks Against Machine Learning Models. ieee symposium on security and privacy.
这篇关于【论文记录】Membership Inference Attacks Against Machine Learning Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





