本文主要是介绍微软开源多模态大模型Phi-3-vision,微调实战来了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型& AIGC 技术趋势、大模型& AIGC 落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
《AIGC 面试宝典》(2024版) 正式发布!
喜欢记得点赞、收藏、关注。更多技术交流&面经学习,可以文末加入我们。
在 Microsoft Build 2024 上,微软持续开源了 Phi-3 系列的新模型们。包括 Phi-3-vision,这是一种将语言和视觉功能结合在一起的多模态模型。
Phi-3家族
Phi-3 系列模型是功能强大、性价比高的小型语言模型 (SLM),在各种语言、推理、编码和数学基准测试中,效果优异。它们使用高质量的训练数据进行训练。
Phi-3 模型系列共有四种模型;每种模型都经过安全保障进行指令调整和开发,以确保可以直接使用,目前均已开源。
-
Phi-3-vision是一个具有语言和视觉功能的 4.2B 参数多模态模型。
-
Phi-3-mini是一个 3.8B 参数语言模型,有两种上下文长度(128K和4K)。
-
Phi-3-small是一个 7B 参数语言模型,有两种上下文长度(128K和8K)。
-
Phi-3-medium是一个 14B 参数语言模型,有两种上下文长度(128K和4K)。
模型种类 | 模型名称 | 模型链接 |
Phi-3-vision | Phi-3-vision-128k-instruct | https://modelscope.cn/models/LLM-Research/Phi-3-vision-128k-instruct |
Phi-3-mini | Phi-3-mini-128k-instruct | https://modelscope.cn/models/LLM-Research/Phi-3-mini-128k-instruct |
Phi-3-mini-4k-instruct | https://modelscope.cn/models/LLM-Research/Phi-3-mini-4k-instruct | |
Phi-3-mini-128k-instruct-onnx | https://modelscope.cn/models/LLM-Research/Phi-3-mini-128k-instruct-onnx | |
Phi-3-mini-4k-instruct-onnx | https://modelscope.cn/models/LLM-Research/Phi-3-mini-4k-instruct-onnx | |
Phi-3-mini-4k-instruct-onnx-web | https://modelscope.cn/models/LLM-Research/Phi-3-mini-4k-instruct-onnx-web | |
Phi-3-small | Phi-3-small-8k-instruct | https://modelscope.cn/models/LLM-Research/Phi-3-small-8k-instruct/summary |
Phi-3-small-8k-instruct-onnx-cuda | https://modelscope.cn/models/LLM-Research/Phi-3-small-8k-instruct-onnx-cuda/summary | |
Phi-3-small-128k-instruct | https://modelscope.cn/models/LLM-Research/Phi-3-small-128k-instruct | |
Phi-3-small-128k-instruct-onnx-cuda | https://modelscope.cn/models/LLM-Research/Phi-3-small-128k-instruct-onnx-cuda | |
Phi-3-medium | Phi-3-medium-128k-instruct | https://modelscope.cn/models/LLM-Research/Phi-3-medium-128k-instruct |
Phi-3-medium-4k-instruct | https://modelscope.cn/models/LLM-Research/Phi-3-medium-4k-instruct | |
Phi-3-medium-4k-onnx-directml | https://modelscope.cn/models/LLM-Research/Phi-3-medium-4k-instruct-onnx-directml | |
Phi-3-medium-4k-onnx-cuda | https://modelscope.cn/models/LLM-Research/Phi-3-medium-4k-instruct-onnx-cuda | |
Phi-3-medium-4k-onnx-cpu | https://modelscope.cn/models/LLM-Research/Phi-3-medium-4k-instruct-onnx-cpu | |
Phi-3-medium-128k-onnx-directml | https://modelscope.cn/models/LLM-Research/Phi-3-medium-128k-instruct-onnx-directml | |
Phi-3-medium-128k-onnx-cuda | https://modelscope.cn/models/LLM-Research/Phi-3-medium-128k-instruct-onnx-cuda | |
Phi-3-medium-128k-onnx-cpu | https://modelscope.cn/models/LLM-Research/Phi-3-medium-128k-instruct-onnx-cpu |
Phi-3 模型已经过优化,可以在各种硬件上运行。ONNX (ONNX Runtime | Phi-3 Small and Medium Models are now optimized with ONNX Runtime and DirectML)格式和 DirectML提供优化过的模型权重,为开发人员提供跨各种设备和平台(包括移动和 Web 部署)的支持。Phi-3 模型还可以作为NVIDIA NIM推理微服务提供,具有标准 API 接口,可以部署在任何地方(Production-Ready APIs That Run Anywhere | NVIDIA),并针对 NVIDIA GPU(https://blogs.nvidia.com/blog/microsoft-build-optimized-ai-developers/)和Intel 加速器(Microsoft Phi-3 GenAI Models with Intel AI Solutions)上的推理进行了优化。
将多模态引入Phi-3
Phi-3-vision 是 Phi-3 系列中的第一个多模态模型,它将文本和图像结合在一起,并具有推理现实世界图像以及从图像中提取和推理文本的能力。它还针对图表和图解理解进行了优化,可用于生成见解和回答问题。Phi-3-vision 以 Phi-3-mini 的语言功能为基础,继续在小型模型中整合强大的语言和图像推理质量。
模型推理
多模态模型推理(Phi-3-vision-128k-instruct)
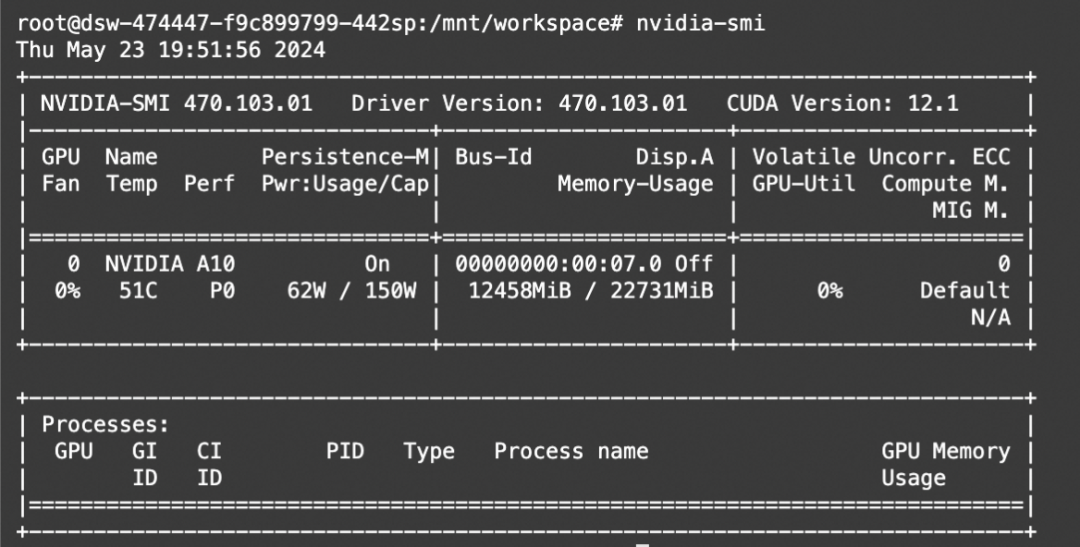
在魔搭社区的免费GPU算力体验Phi-3多模态模型(单卡A10)
推理代码
from PIL import Image
import requests
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM
from transformers import AutoProcessor model_id = snapshot_download("LLM-Research/Phi-3-vision-128k-instruct" )model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda", trust_remote_code=True, torch_dtype="auto")processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True) messages = [ {"role": "user", "content": "<|image_1|>\n图片里面有什么?"}, {"role": "assistant", "content": "该图表显示了同意有关会议准备情况的各种陈述的受访者的百分比。它显示了五个类别:“有明确和预先定义的会议目标”、“知道在哪里可以找到会议所需的信息”、“在受邀时了解我的确切角色和职责”、“拥有管理工具” 诸如记笔记或总结之类的管理任务”,以及“有更多的专注时间来充分准备会议”。每个类别都有一个关联的条形图,指示一致程度,按 0% 到 100% 的范围进行衡量。"}, {"role": "user", "content": "提供富有洞察力的问题来引发讨论。"}
] url = "https://assets-c4akfrf5b4d3f4b7.z01.azurefd.net/assets/2024/04/BMDataViz_661fb89f3845e.png"
image = Image.open(requests.get(url, stream=True).raw) prompt = processor.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)inputs = processor(prompt, [image], return_tensors="pt").to("cuda:0") generation_args = { "max_new_tokens": 500, "temperature": 0.0, "do_sample": False,
} generate_ids = model.generate(**inputs, eos_token_id=processor.tokenizer.eos_token_id, **generation_args) # remove input tokens
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0] print(response)
显存占用:
跨平台推理(Phi-3-medium-4k-instruct-onnx-cpu)
配置:
step1: 下载模型
git clone https://www.modelscope.cn/LLM-Research/Phi-3-medium-4k-instruct-onnx-cpu.git
step2:安装依赖
pip install --pre onnxruntime-genai
step3:运行模型
curl https://raw.githubusercontent.com/microsoft/onnxruntime-genai/main/examples/python/phi3-qa.py -o phi3-qa.py
python phi3-qa.py -m Phi-3-medium-4k-instruct-onnx-cpu/cpu-int4-rtn-block-32-acc-level-4
体验对话效果

模型微调
SWIFT已经支持Phi3系列模型的微调,包括纯文本模型如Phi3-mini-128k-instruct、Phi3-small-128k-instruct、Phi3-middle-128k-instruct等,也包括了Phi3的多模态模型Phi-3-vision-128k-instruct。
下面以多模态模型为例给出微调最佳实践:
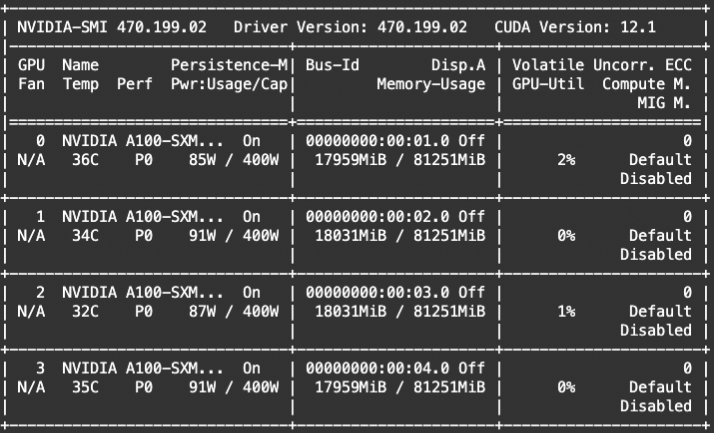
# Experimental environment: 4 * A100
# 4 * 18GB GPU memory
nproc_per_node=4PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
torchrun \--nproc_per_node=$nproc_per_node \--master_port 29500 \llm_sft.py \--model_type phi3-vision-128k-instruct \--model_revision master \--sft_type lora \--tuner_backend peft \--template_type AUTO \--dtype AUTO \--output_dir output \--ddp_backend nccl \--dataset coco-en-2-mini \--train_dataset_sample -1 \--num_train_epochs 1 \--max_length 4096 \--check_dataset_strategy warning \--lora_rank 8 \--lora_alpha 32 \--lora_dropout_p 0.05 \--lora_target_modules ALL \--gradient_checkpointing true \--batch_size 1 \--weight_decay 0.1 \--learning_rate 1e-4 \--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \--max_grad_norm 0.5 \--warmup_ratio 0.03 \--eval_steps 100 \--save_steps 100 \--save_total_limit 2 \--logging_steps 10 \--use_flash_attn true \--ddp_find_unused_parameters true \
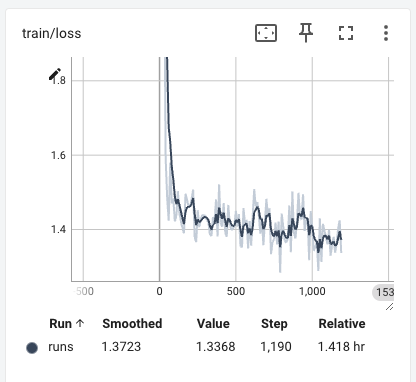
我们使用训练时长约3小时,训练loss收敛情况如下:
显存占用:
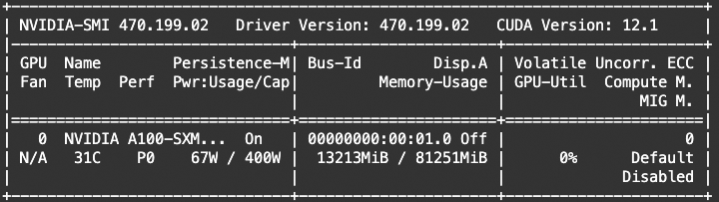
Phi3-vision支持多个图片传入,在训练后我们可以使用ckpt进行多图片推理:

显存占用:
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了算法面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
这篇关于微软开源多模态大模型Phi-3-vision,微调实战来了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








