本文主要是介绍视频拼接融合产品的产品与架构设计(三)内存和显存单元数据迁移,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇文章
视频拼接融合产品的产品与架构设计(二)
这一篇沉下先来,彻底放弃了界面,界面最终的体现是最后要做的,现在要做的是产品的架构,使用链式架构方式迁移数据。同时增加插件口,方便编程序。
插件架构
为了视频拼接和算法等的产品化,在视频解码前(录像),解码后在gpu,解码后转颜色空间(bgr),解码后算法处理,解码后算法处理下放部分数据到cpu(如截图),解码后算法处理后转颜色空间,框架必须能够在各个点上有接口,下放给使用着。其中就包含了内存和显存单元的数据迁移。
目的
先举个简单的例子说明,说明拼接的过程,实际上,拼接就是个算法处理,属于解码后转颜色空间之后的算法部分,其他如AI,去雾,超分算法等等都将在这个口以后进行。
使用两个或者多个gpu拼接两幅图像以后,往下传,到内存合并,然后转码成nv12,编码,rtsp向外传流。虽然数据下放到了cpu,但是在没有nvlink的显卡上,我们的数据无法直接迁移,只能放到cpu上,这一部分是系统中的例外。如果直接有nvlink,可以通过pcie的数据通道直接从一个显卡到另外一个显卡,那就没有问题,我们保持最差系统配置,没有link接口,多块显卡,数据通过cpu迁移到内存进行处理。
下面来看nv12 的数据,如下所示,uv 紧密排列,宽度和y分量保持一致,而高度为y分量的一半。

做法1
一开始使用bgr 往下传,数据量很大,往下传的时候速度也很慢,编码的时候要使用ffmpeg swscale转码bgr到yuv420,最后转成nv12,进行编码,非常慢,因为图像两边都近4k,这个方案pass掉。
做法2
使用unified 内存,cuda中有一个cudaMallocManaged函数来控制内存端和服务端,自动会迁移数据,不用显式拷贝,我们来尝试以下,下面的代码只是申请内存,发现申请unified内存以后,内存和cuda kernel函数同时可以操作,确实省事了不少,随之而来的是更大的问题,操作速度非常慢
#include <cuda_runtime.h>size_t size = width * height * sizeof(float); // 假设为浮点型数据
float* devPtr;cudaError_t err = cudaMallocManaged(&devPtr, size, cudaMemAttachGlobal);
if (err != cudaSuccess) {// 处理错误
}// 现在devPtr可以被CPU和GPU代码直接访问
// 注意:实际使用中还需考虑同步问题,确保数据访问的安全性
经过测试,速度非常慢,比bgr更慢,内存自动迁移对于gpu和cpu来说不适合,还是要手动来做数据迁移
改进1
使用cuda转码bgr到nv12,把nv12往下传,每隔一行拷贝一行,使用异步
void mergeYUV(NV12Image* s1, NV12Image* s2, AVFrame* d) {
//#pragma omp parallel for num_threads(2)cudaStream_t stream;cudaStreamCreate(&stream);for (int i = 0; i < s1->height ; ++i) { // UV高度是Y高度的一半cudaMemcpyAsync(d->data[0] + i * d->linesize[0], s1->Y + i * s1->width, s1->width, cudaMemcpyDeviceToHost, stream);cudaMemcpyAsync(d->data[0] + i * d->linesize[0] + s1->width, s2->Y + i * s2->width, s2->width, cudaMemcpyDeviceToHost, stream);if (i < s1->height / 2){cudaMemcpyAsync(d->data[1] + i * d->linesize[1], s1->UV + i * (s1->width), s1->width, cudaMemcpyDeviceToHost, stream);cudaMemcpyAsync(d->data[1] + i * d->linesize[1] + s1->width, s2->UV + i * (s2->width), s2->width, cudaMemcpyDeviceToHost, stream);}//memcpy(d->data[1] + i * d->linesize[1], s1->UV + i * (s1->width) , s1->width);//memcpy(d->data[1] + i * d->linesize[1] + s1->width , s2->UV + i * (s2->width) , s2->width);}cudaStreamSynchronize(stream);cudaStreamDestroy(stream);
}
这个方法很慢,是因为图像很大,但是比起前面的速度快,整个一帧包含下放和拷贝需要58毫秒,查寻cuda文档后,说明下放次数一定要少,确定以后有信心了,重新组织数据,cuda转空间颜色的函数把nv12放在一块显存中,然后在cudaMemcpy下放迁移。
改进2
以下为实现,算法框架搭建好,开始整理算法,先把两块数据通过迁移直接下放到内存,
int MergeNV12FromGPUMat(cv::cuda::GpuMat& g1, cv::cuda::GpuMat& g2,AVFrame* frame)
{int w1 = g1.cols;int h1 = g1.rows;int w2 = g2.cols;int h2 = g2.rows;int d1YSize = w1 * h1;int d1UVSize = w1 * h1 / 2;int d2YSize = w2 * h2;int d2UVSize = w2 * h2 / 2;void* GPUPtr1 = NULL;void* GPUPtr2 = NULL;double startTime = cv::getTickCount();cudaError_t err1 = cudaMalloc(&GPUPtr1, d1YSize + d1UVSize);if (err1 != cudaSuccess) {return -1;}cudaError_t err2 = cudaMalloc(&GPUPtr2, d2YSize + d2UVSize);if (err2 != cudaSuccess) {cudaFree(&GPUPtr1);return -1;}unsigned char* Y1 = (unsigned char*)GPUPtr1;unsigned char* UV1 = (unsigned char*)GPUPtr1 + w1 * h1;//显卡1bgr24_to_nv12_cuda(reinterpret_cast<uchar3*>(g1.data), Y1,UV1, w1, h1, g1.step, w1, w1);unsigned char* Y2 = (unsigned char*)GPUPtr2;unsigned char* UV2 = (unsigned char*)GPUPtr2 + w2 * h2;
//显卡2 bgr24_to_nv12_cuda(reinterpret_cast<uchar3*>(g2.data), Y2,UV2, w2, h2, g2.step, w2, w2);NV12Image gpum1(Y1, UV1, w1, h1);NV12Image gpum2(Y2, UV2, w2, h2);double endTime = cv::getTickCount();// 计算时间差,单位为毫秒double elapsedTimeMs = (endTime - startTime) / cv::getTickFrequency() * 1000.0;std::cout << "Elapsed time cuda trans in milliseconds: " << elapsedTimeMs << std::endl;// mergeYUV(&gpum1, &gpum2, frame);mergeYUVHost(&gpum1, &gpum2, frame);double endTime1 = cv::getTickCount();elapsedTimeMs = (endTime1 - endTime) / cv::getTickFrequency() * 1000.0;std::cout << "Elapsed time Merge in milliseconds: " << elapsedTimeMs << std::endl;cudaFree(GPUPtr1);cudaFree(GPUPtr2);
}
以下转拷贝计算
//以下使用cpu做
{void* host1YUV = NULL;void* host2YUV = NULL;int n1 = in1->width * in1->height * 1.5;int n2 = in2->width * in2->height * 1.5;cudaMallocHost(&host1YUV, n1);cudaMallocHost(&host2YUV, n2);cudaMemcpy(host1YUV,in1->Y, n1,cudaMemcpyDeviceToHost);cudaMemcpy(host2YUV,in2->Y, n2,cudaMemcpyDeviceToHost);uint8_t* y1 = (uint8_t*)host1YUV;uint8_t* uv1 = (uint8_t*)host1YUV + in1->width * in1->height;uint8_t* y2 = (uint8_t*)host2YUV;uint8_t* uv2 = (uint8_t*)host2YUV + in2->width * in2->height;NV12Image ss1(y1, uv1, in1->width, in1->height);NV12Image ss2(y2, uv2, in2->width, in2->height);NV12Image* s1 = &ss1;NV12Image* s2 = &ss2;for (int i = 0; i < s1->height; ++i) { // UV高度是Y高度的一半memcpy(d->data[0] + i * d->linesize[0], s1->Y + i * s1->width, s1->width);memcpy(d->data[0] + i * d->linesize[0] + s1->width, s2->Y + i * s2->width, s2->width);if (i < s1->height / 2){memcpy(d->data[1] + i * d->linesize[1], s1->UV + i * (s1->width), s1->width);memcpy(d->data[1] + i * d->linesize[1] + s1->width, s2->UV + i * (s2->width), s2->width);}}//end:cudaFree(host1YUV);cudaFree(host2YUV);
}
看时间,两次转颜色空间由于使用了cuda,速度还行,花费3毫秒不到,我的显卡特意选了16系列,1650的显卡,速度不是很快,但也不至于拖后腿。总共下来花费18毫秒多,比起50毫秒有3倍左右提升,这个还是有点多,仔细思考了一下,想从拷贝上下功夫。
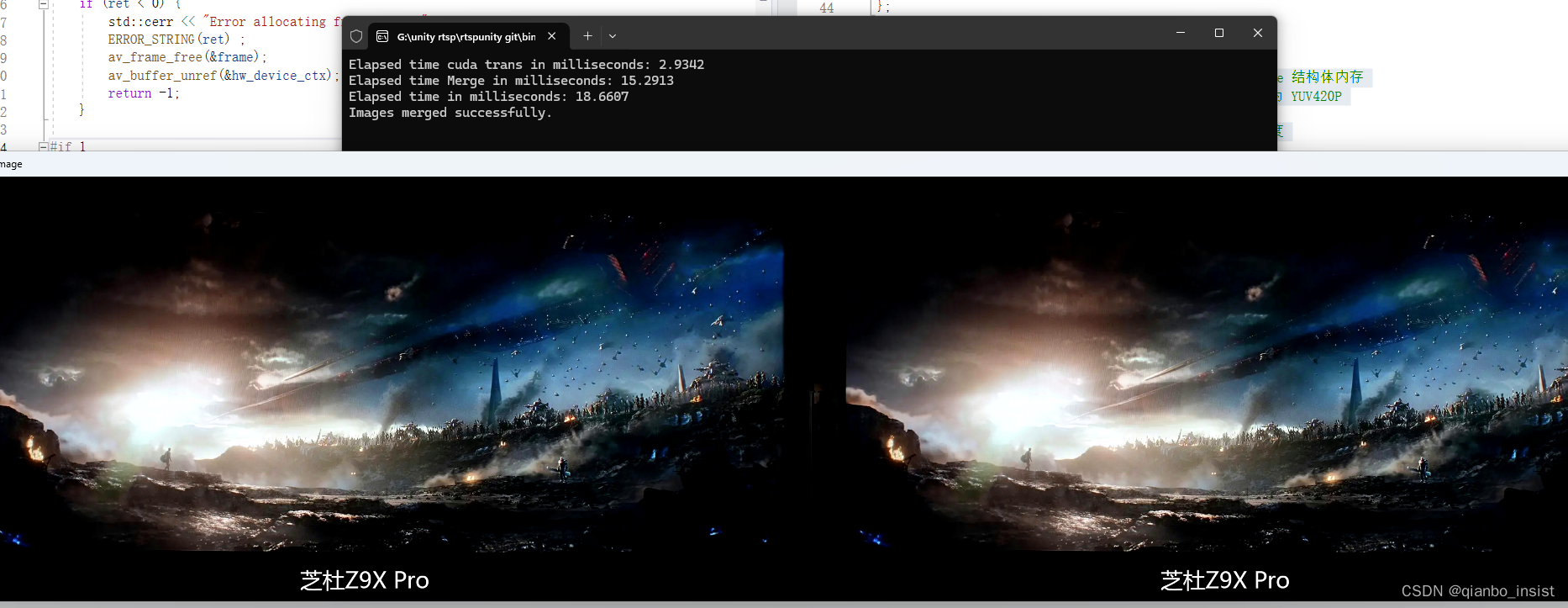
改进3
改成两个线程启动,一个线程拷贝Y分量,一个线程拷贝uv分量
// 合并Y分量的线程函数
void mergeY(NV12Image* s1,NV12Image* s2, AVFrame* d)
{
#pragma omp parallel for //num_threads(10)for (int i = 0; i < s1->height; ++i) {memcpy(d->data[0] + i * d->linesize[0], s1->Y + i * s1->width, s1->width);memcpy(d->data[0] + i * d->linesize[0] + s1->width, s2->Y + i * s2->width, s2->width);}
}// 合并UV分量的线程函数
void mergeUV(NV12Image* s1, NV12Image* s2, AVFrame* d) {
#pragma omp parallel for //num_threads(10)for (int i = 0; i < s1->height / 2; ++i) { // UV高度是Y高度的一半memcpy(d->data[1] + i * d->linesize[1], s1->UV + i * (s1->width) , s1->width);memcpy(d->data[1] + i * d->linesize[1] + s1->width , s2->UV + i * (s2->width) , s2->width);}
}
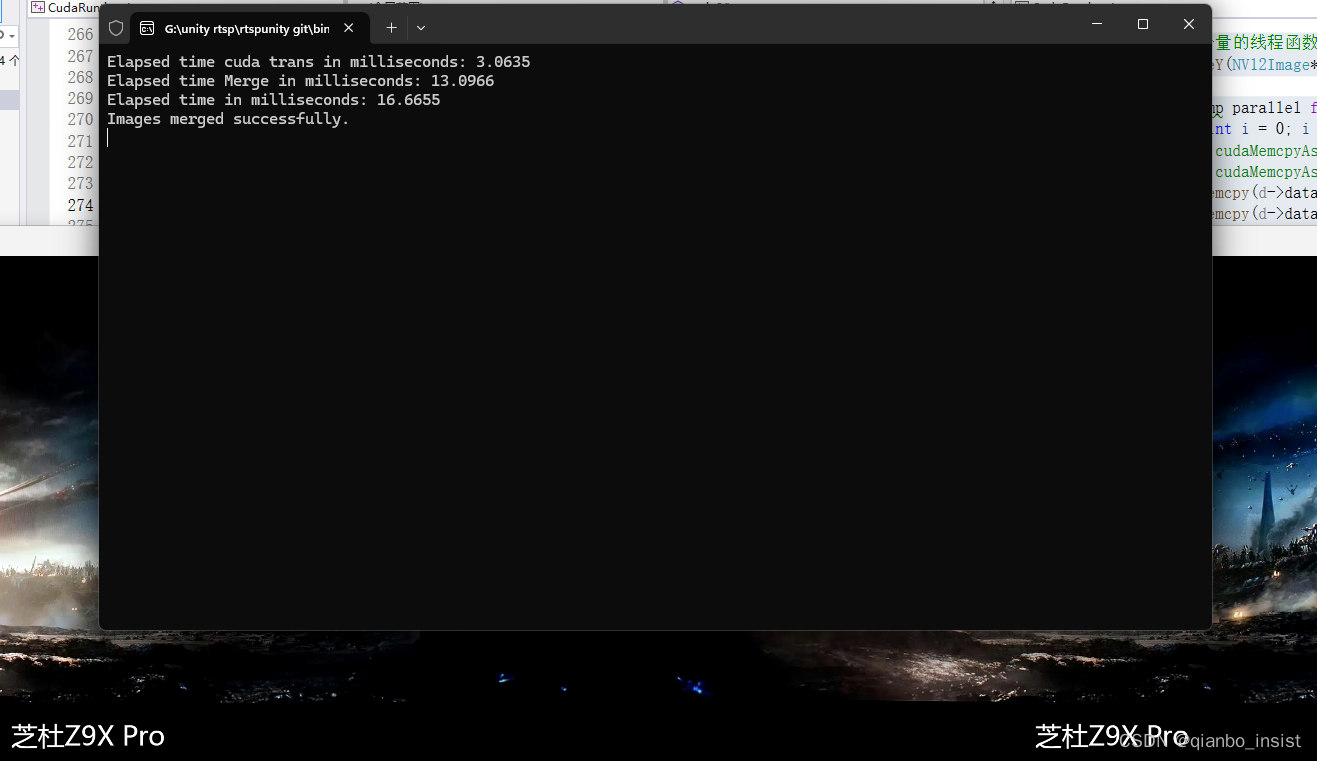
#if 1std::thread yThread(mergeY,s1,s2, d);std::thread uvThread(mergeUV, s1, s2, d); 等待线程完成yThread.join();uvThread.join();#endif
启动线程做,同时启动openmp,大约有2毫秒的提升,线程启动和释放还是需要时间,这个优化必须让线程一直启动,也不要停止
改进4
启用多线程,同时启用更好的avx2 指令集,具体看我的其他文章,最终锁定在10毫秒以内,包括了转颜色空间,数据迁移到内存,合并成ffmpeg可以编码的nv12格式,花费10毫秒,整个过程比完全在显存里面多了一次数据迁移的过程,就是数据既下载又上传,因为在编码的时候,数据又上传到了gpu,最后推流时,又迁移到了内存,rtsp发送数据流,是一定要到内存里面的。
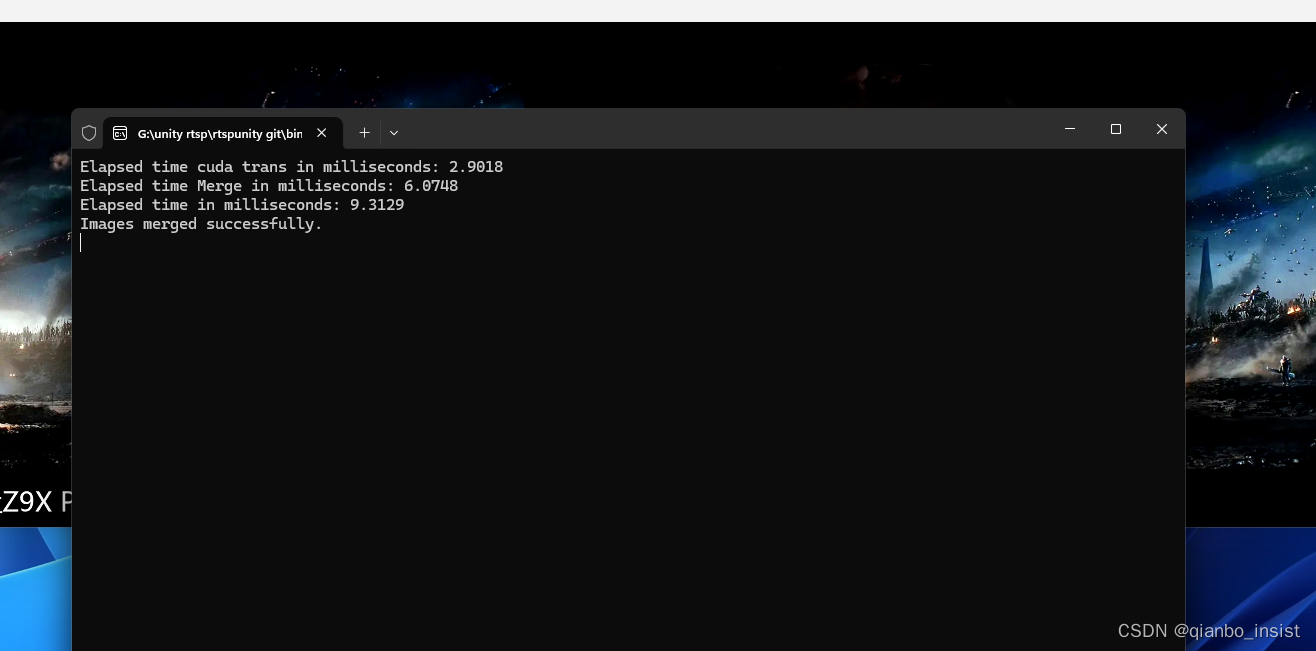
总结
下一篇会往整体架构上写,多画图,少代码
这篇关于视频拼接融合产品的产品与架构设计(三)内存和显存单元数据迁移的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





