显存专题
【AI 绘画】更快?更省显存?支持 FLUX?使用绘世启动器安装 SD WebUI Forge
使用绘世启动器安装 SD WebUI Forge 下载绘世启动器 绘世启动器下载地址1:https://gitee.com/licyk/term-sd/releases/download/archive/hanamizuki.exe 绘世启动器下载地址2:https://www.bilibili.com/video/BV1ne4y1V7QU 新建一个文件夹取名sd-webui-

解决tensorflow模型加载时把GPU显存占满的问题(亲测效果显著)
第一次用tensorflow模型进行推理。 初始状态下,显存的占用情况 模型加载后,电脑显存直接快拉满了,但是模型参数量并不大,这就很奇怪,究竟这是一股什么神秘的力量,竟要试图侵占我可怜的显卡宝贝 原因分析:安装了tensorflow-gpu后,运行程序默认是把GPU的内存全部占满的,但是正常人都不希望这样,都希望能自己掌握自己的资源,而不是任人摆布,可以这样操作。 解决代码:

书生大模型实战营第三期基础岛第二课——8G 显存玩转书生大模型 Demo
8G 显存玩转书生大模型 Demo 基础任务进阶作业一:进阶作业二: 基础任务 使用 Cli Demo 完成 InternLM2-Chat-1.8B 模型的部署,并生成 300 字小故事,记录复现过程并截图。 创建conda环境 # 创建环境conda create -n demo python=3.10 -y# 激活环境conda activate demo#

Qwen2的各模型性能、占用显存和推理速度比较(摘自官方文档)
Qwen2的各模型性能、占用显存和推理速度比较(摘自官方文档) 性能 推理速度(从大到小) 72B 57B-A14B 7B 1.5B 0.5B

Intel8086处理器使用NASM汇编语言实现操作系统02-实模式-显存原理
显卡以高频的刷新速度一直不停的扫描显存中的数据,将显存中的数据显示到屏幕上 显卡有两种模式 1.文本模式:为了方便叙述,本文的代码示例采用文本模式 2.图形模式 对于CPU来说,显存也是内存,显存的地址是B8000-BFFFF,文本模式下,每一个字符由两个字节组成,那么这16个bit排列如下: 屏幕上一个字符=该字符的asicc码(8bit)+背景色(高4bit)+字体颜色(低4b
减少GPU显存的策略
训练时 减少batchsize图片尺寸缩小 推理时 cpu加载模型 pipe.enable_sequential_cpu_offload()减小精度 torch.float32 --> torch.float16其它
用c++查linux与windows上的显存利用率,内存使用率,cpu占有率,gpu占有率
一、显存利用率 Windows https://blog.csdn.net/paopaoc/article/details/9093125 linux https://blog.csdn.net/paopaoc/article/details/9093125 二、GPU占用率 Windows https://blog.csdn.net/paopaoc/article/details/
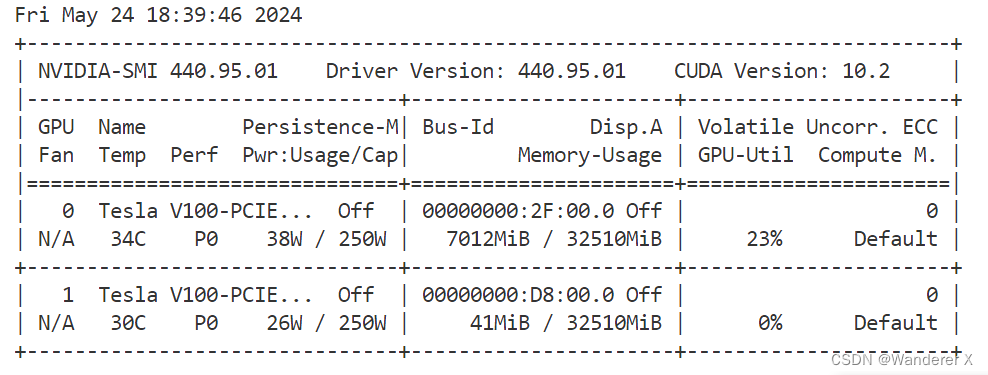
hpc中查看显存占用,等效nvidia-smi
nvidia-smi在hpc中无法使用, 但是可以通过以下方法查看应用程序占用的显存 先执行程序,之后 bjobs 输出 可以看到使用的是gpu01节点 之后 ssh gpu01

视频拼接融合产品的产品与架构设计(三)内存和显存单元数据迁移
上一篇文章 视频拼接融合产品的产品与架构设计(二) 这一篇沉下先来,彻底放弃了界面,界面最终的体现是最后要做的,现在要做的是产品的架构,使用链式架构方式迁移数据。同时增加插件口,方便编程序。 插件架构 为了视频拼接和算法等的产品化,在视频解码前(录像),解码后在gpu,解码后转颜色空间(bgr),解码后算法处理,解码后算法处理下放部分数据到cpu(如截图),解码后算法处理后转颜色空间,框架必
开源框架MXNet | 环境变量配置(显存)
一般情况下,不需要修改有关环境变量的配置。但是一些特殊情况,需要修改的,就涉及到以下这些内容了: 在linux上最简单的修改方式就是export MXNET_GPU_WORKER_NTHREADS=3 一 设置进程数量 MXNET_GPU_WORKER_NTHREADS 这个参数用来在一块卡上并行计算,在每一块GPU上最大的进程数,默认值为2MXNET_GPU_COPY_NTHREADS
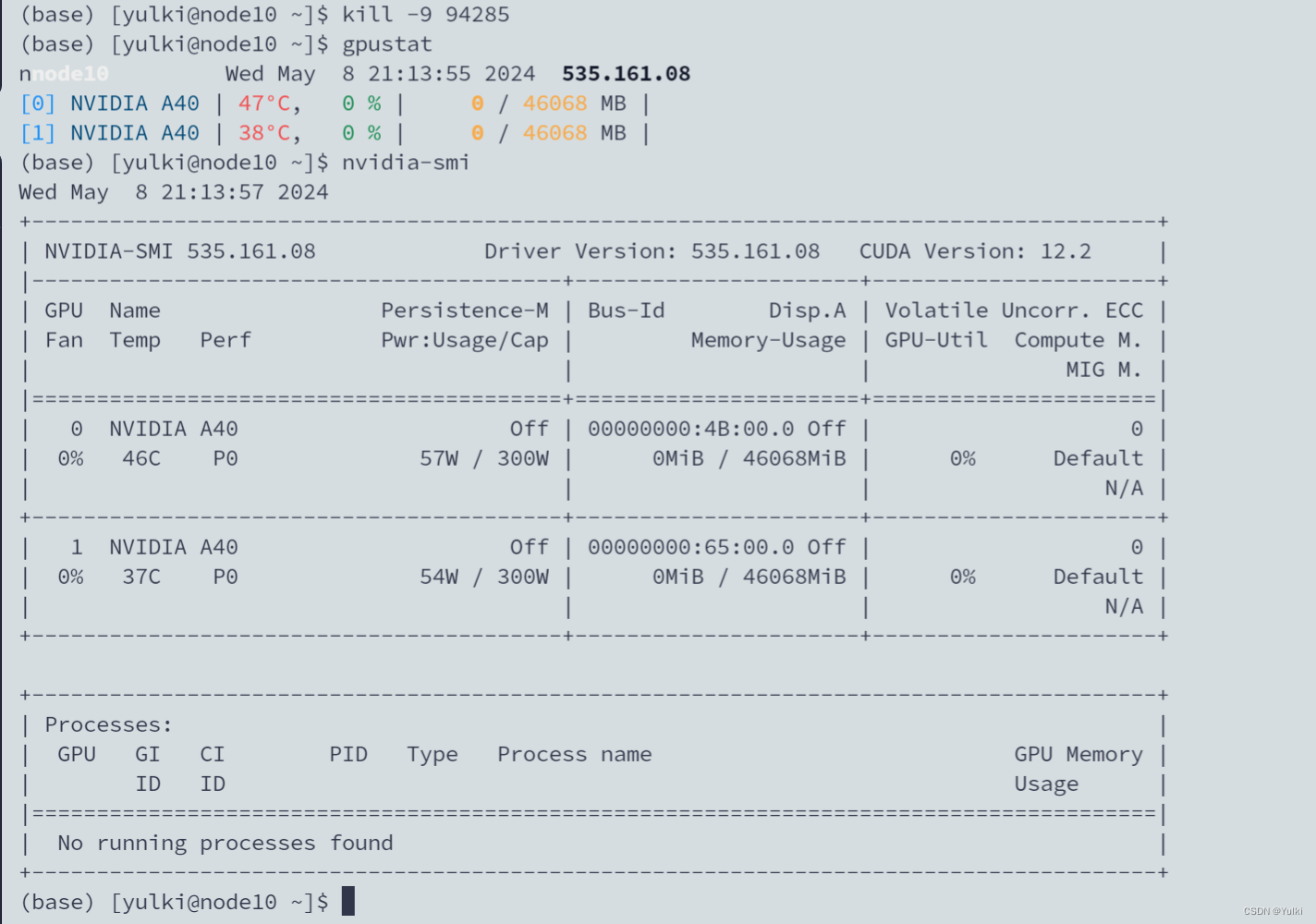
【bug记录】清除僵尸进程,释放GPU显存
目录 1. 为什么会出现这种情况?2. 解决方案方法一:使用 fuser 命令方法二: 3. 小贴士 在进行深度学习或其他需要GPU支持的任务时,我们有时会发现虽然没有可见的进程在执行,但GPU资源却意外地被占用。这种情况往往会阻碍我们的工作进度,因为新的任务无法启动。如果你遇到了这种状况,不要担心,这里有一些方法可以帮助你解决这个问题。 1. 为什么会出现这种情况?

FP16、BF16、INT8、INT4精度模型加载所需显存以及硬件适配的分析
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了FP16、INT8、INT4精度模型加载占用显存大小的分析,希望对学
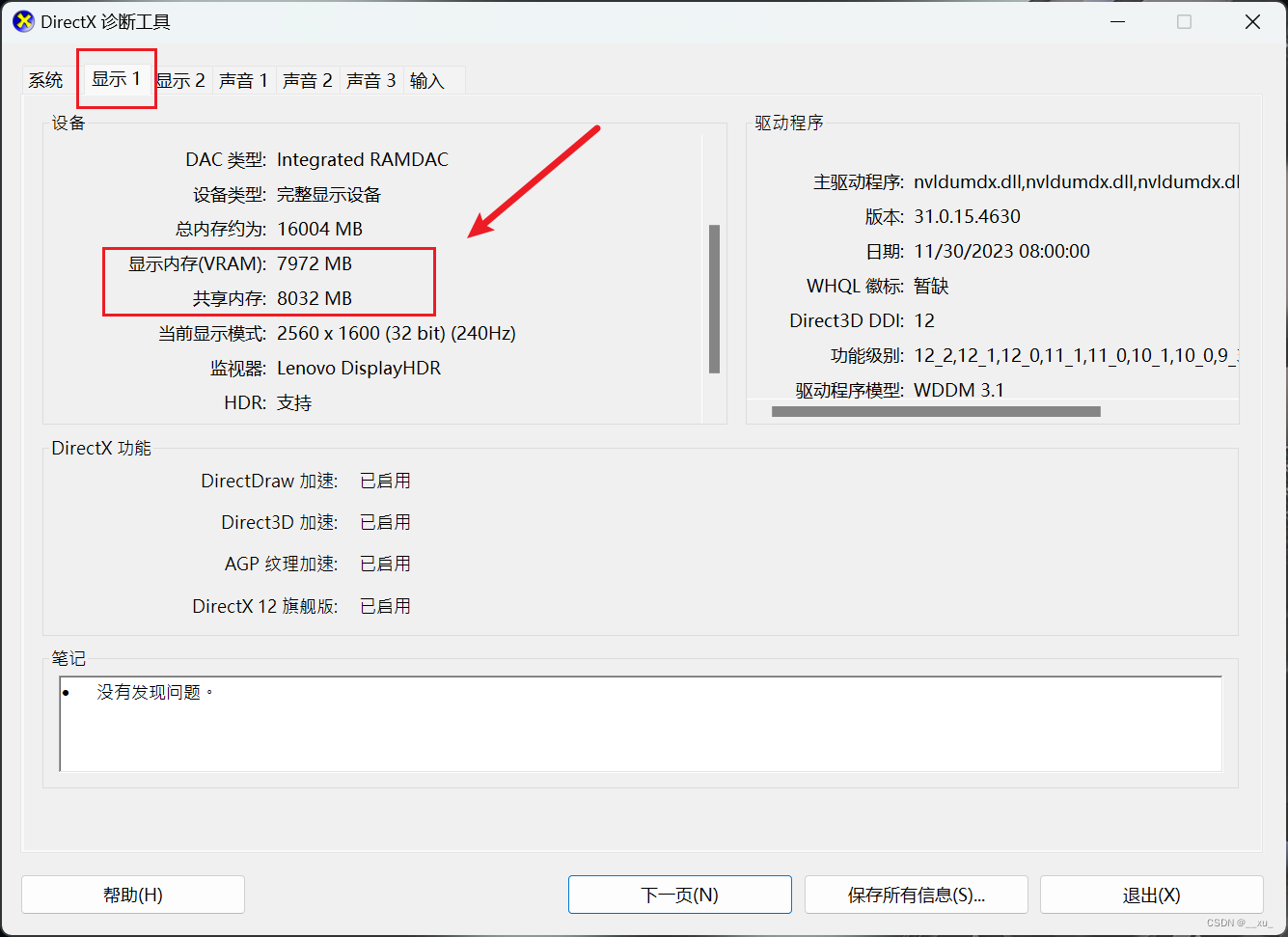
Windows电脑的显存容量查看
要查看Windows电脑的显存容量,可以按照以下步骤进行: 1、通过系统信息查看: 在Windows操作系统中,您可以使用系统信息来查看显存容量。 按下Win键 + R打开“运行”对话框,然后输入“msinfo32”并按回车键。 在打开的系统信息窗口中,导航到“组件” > “显示器”,在右侧窗格中会显示您的显卡信息,包括显存容量。 2、通过显卡驱动程序查看: 您也可以通过显卡驱动程序来查看
ubuntu 操作_文件夹权限_复制文件夹_释放 GPU 显存
注销用户 xorg 界面: 终端输入:htop 找到进程 xorg 的 pid 数,kill pid 数 释放 gpu 显存: nvidis-smi sudo kill -9 PID 复制 source/ 文件夹下的所有文件到 dst 文件夹下: cp -a source/ dst/ 改变某个文件夹下的权限: sudo chmod -R 777 file_dir/

pytorch如何计算显存大小
参考连接 pytorch 减小显存消耗,优化显存使用避免 outofmemory https://blog.csdn.net/qq_28660035/article/details/80688427 如何计算模型以及中间变量的显存占用大小:https://oldpan.me/archives/how-to-calculate-gpu-memory 如何在Pytorch中精细化利用显存:htt
pytorch 显存自适应减少
pytorch在训练时,显存是只会增加不会减少的。如果要动态减少: torch.backends.cudnn.enabled = Truetorch.backends.cudnn.benchmark = True 不过这样做的后果就是训练会很慢,快赶上CPU的速度了

Pytorch 获取当前模型占用的 GPU显存的大小
1. 背景 AI 训练模型时需要知道模型占用显存的大小,以及剩余显存大小 2. 代码 import torch# 检查GPU是否可用if torch.cuda.is_available():# 获取当前设备device = torch.cuda.current_device()# 创建一个虚拟modelmodel = torch.nn.Linear(25600, 20000, 20000)
tensorflow设置显存自适应和显存比例.
转自:http://blog.csdn.net/cq361106306/article/details/52950081 用惯了theano.再用tensoflow发现一运行显存就满载了,吓得我吃了一个苹果。 用天朝搜索引擎毛都搜不到,于是翻墙找了下问题的解决方法,原来有两种 1. 按比例 config = tf.ConfigProto()config.gpu_options.per_p

戴尔灵越3000来说2.5G的双核显存能干啥?
吃鸡已经成为大家耳熟能详的网络游戏。 很多人认为,想要享受吃鸡的乐趣,就必须组装一台高端电脑。 虽然配置越高越好,但现实是很多配置都是以性能为标准的。 有余了,没必要刻意追求高配置、高特效。 说实话,吃鸡不一定需要高特效。 为什么? 因为高效草挡住了伏地魔,我根本看不到。 配置越高越好。 最重要的是适合。 尤其是在这个性能过剩的时代,即使你的2W电脑和1万台电脑相比,跑来跑去几乎没有区别。
性价比深度学习3090RTX显卡 24G显存 主机配置
工作学习需要配置的主机,来跑深度学习模型,2023年底11月配置的。低于市场价的为咸鱼等平台购买,具体如下,供参考 : 配件 单价(*数量)/元 CPU i5 13600kf
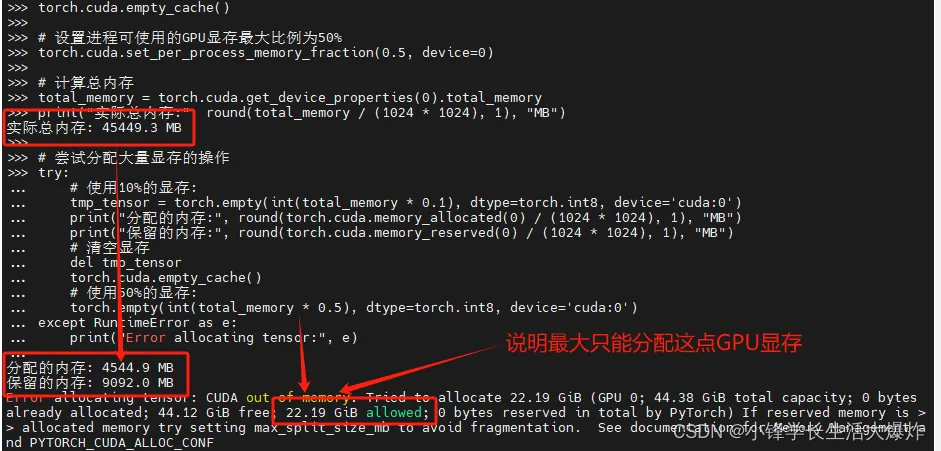
【技巧】PyTorch限制GPU显存的可使用上限
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 从 PyTorch 1.4 版本开始,引入了一个新的功能 torch.cuda.set_per_process_memory_fraction(fraction, device),这个功能允许用户为特定的 GPU 设备设置进程可使用的显存上限比例。 测试代码: torch.cuda.emp

StableDiffusion Web UI开启FP8,极大节约显存
升级了Pytorch后,StableDiffusion最新版本就可以有使用FP8的基础了,因此把秋叶的LINUX包也升级到了最新的版本。 升级Pytorch参考我的升级记录: ComfyUI SDWebUI升级pytorch随记-CSDN博客 然后下一步就是如何开启FP8了。与ComfyUI不同,SDWebUI不是通过启动参数来开启,而是在配置界面找到这个位置: 记得点保存生效。
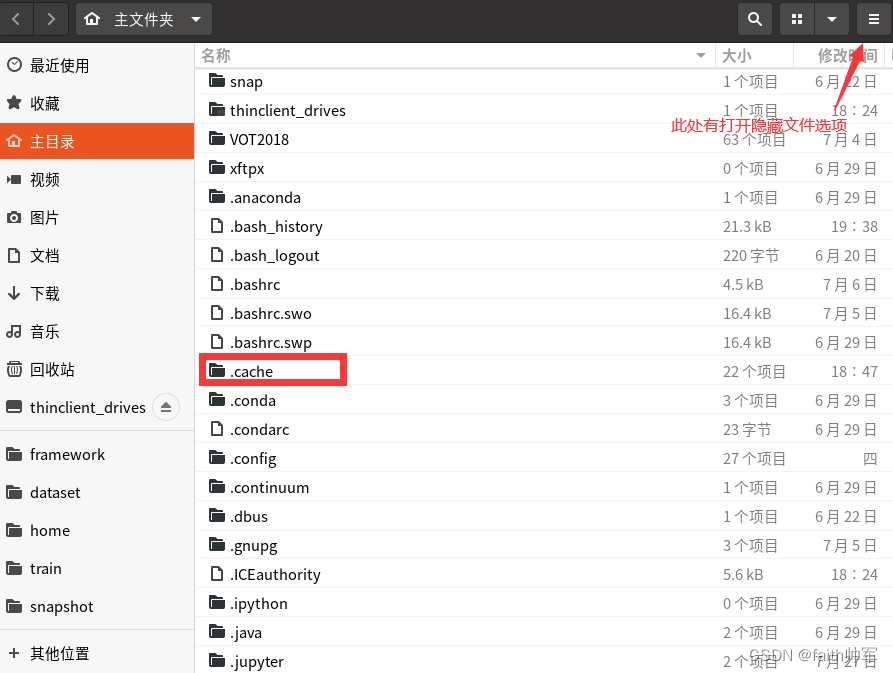
进程在运行时卡住,显存分配了却不开始训练(卡在Using /home/faith/.cache/torch_extensions as PyTorch extensions root...)
使用nvidia-smi 发现显示如下: 无论怎么重新运行程序,或者改变线程或者显卡都一直卡在这里,没有继续训练。 分析: 最后仔细分析了以下,这个代码可能有一些问题,因为我之前是用四张3090在训练,中途停电就中断了一下,当我重新运行的时候使用的是两张卡就出现了这种情况,所以我怀疑可能是 .cache 的原因,导致了进程卡死(两次运行环境和配置不同引起的) 解

【中文视觉语言模型+本地部署 】23.08 阿里Qwen-VL:能对图片理解、定位物体、读取文字的视觉语言模型 (推理最低12G显存+)
项目主页:https://github.com/QwenLM/Qwen-VL 通义前问网页在线使用——(文本问答,图片理解,文档解析):https://tongyi.aliyun.com/qianwen/ 论文v3. : 一个全能的视觉语言模型 23.10 Qwen-VL: A Versatile Vision-Language Model for Understanding, Localizat