本文主要是介绍进程在运行时卡住,显存分配了却不开始训练(卡在Using /home/faith/.cache/torch_extensions as PyTorch extensions root...),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用nvidia-smi 发现显示如下:
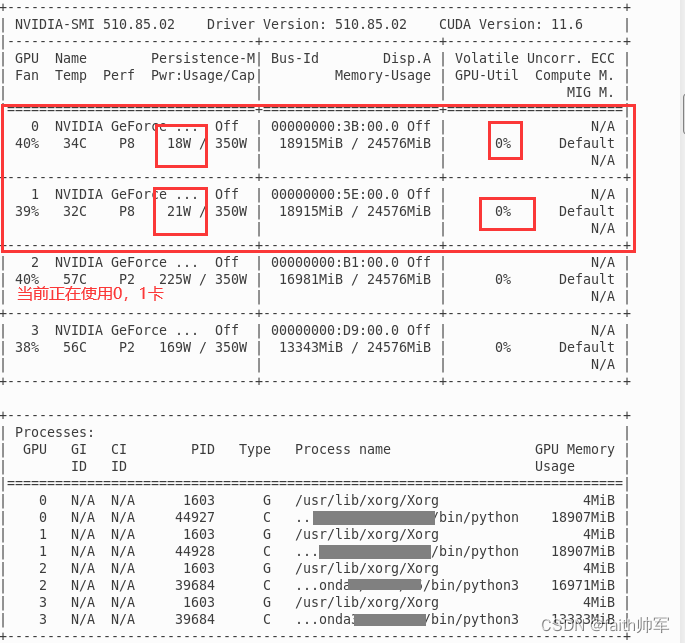
无论怎么重新运行程序,或者改变线程或者显卡都一直卡在这里,没有继续训练。
分析:
最后仔细分析了以下,这个代码可能有一些问题,因为我之前是用四张3090在训练,中途停电就中断了一下,当我重新运行的时候使用的是两张卡就出现了这种情况,所以我怀疑可能是 .cache 的原因,导致了进程卡死(两次运行环境和配置不同引起的)
解决:
一般会在用户主目录下会有一个自动生成的 .cache文件夹(有可能是隐藏状态,需要你打开显示隐藏文件选项),将这个文件夹删除即可,可以重新生成.cache文件夹,然后就不会有冲突啦。(如下图)
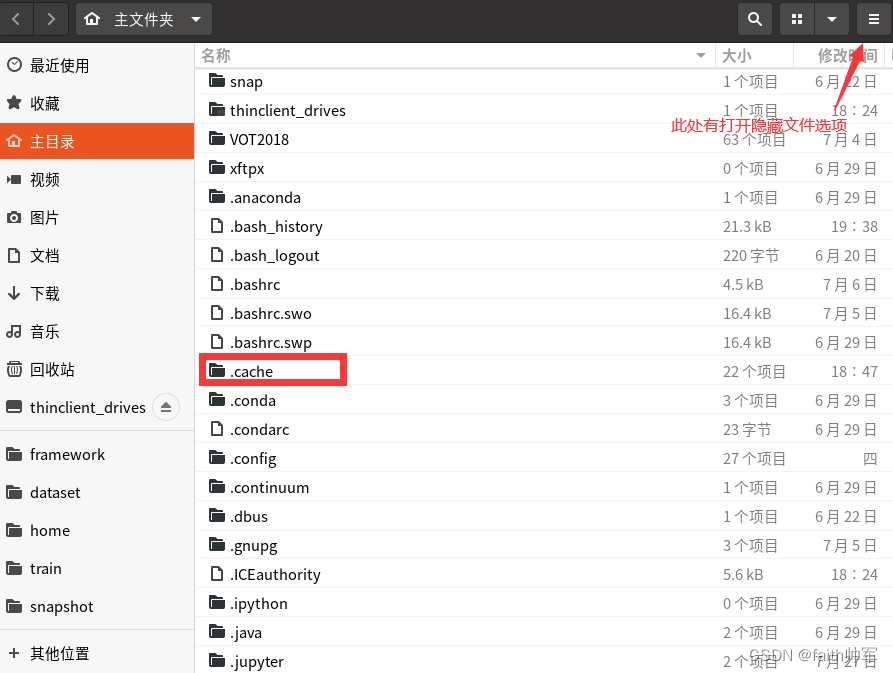
当然不可能只有这一种情况,笔者仅作笔记使用,有问题欢迎指正。
这篇关于进程在运行时卡住,显存分配了却不开始训练(卡在Using /home/faith/.cache/torch_extensions as PyTorch extensions root...)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









