本文主要是介绍今日arXiv最热NLP大模型论文:NAACL24实锤语言学对大模型“负优化”,抽象语义表示+思维链有损表现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
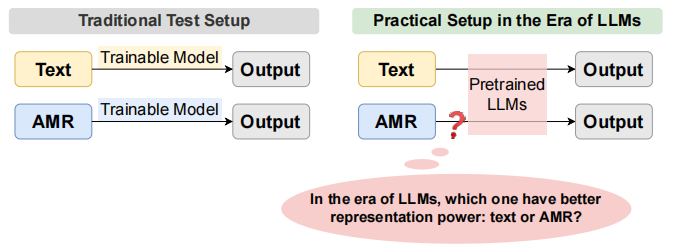
大语言模型正以势不可挡的姿态席卷自然语言处理领域。在这个语言模型大显神威的时代,很多任务都转变为了端到端的文本生成任务。那么,在此之前我们苦心孤诣研究了几十年的语义表示,例如 AMR(抽象意义表示),在这个时代里还能派上用场吗?
这篇文章针对这个问题展开了研究,作者们提出了一种基于 AMR 的思维链(chain-of-thought)提示方法 AMRCOT,在5个自然语言处理任务上对比研究了这种方法和直接提示大模型的效果差异。结果发现,总体而言使用 AMR 并不能带来明显的效果提升,甚至会导致性能下降。
不过,进一步的分析表明,AMR 在一些具体任务上还是能起到积极作用。文章重点指出,要让 AMR 在大语言模型时代真正发挥价值,下一步的重点应该放在提升模型对 AMR 符号表示的理解,以及如何将 AMR 推理与具体任务输出对应起来。
接下来让我们深入剖析这篇文章的研究细节。这个话题对于思考传统语言学知识在AI时代的价值很有启发。语言学家们孜孜不倦几十年的研究成果,面对大语言模型的崛起,究竟该何去何从?这是一个值得认真对待、深入探讨的问题。期待这篇文章能为我们提供一些有价值的思路。
论文标题:
Analyzing the Role of Semantic Representations in the Era of Large Language Models
论文链接:
https://arxiv.org/pdf/2405.01502
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
AMR or not AMR is a question.
近年来,大语言模型被广泛应用于自然语言处理领域。仅需要使用 prompt engineering,一个通用的大模型就可以实现从文本分类、机器翻译到代码生成等各种任务。曾几何时,这些任务需要精心设计特征、标注海量数据,并且需要针对每个任务单独训练专门的模型。但现在,一个大而全的通用语言模型似乎已经可以包揽全部,用一个模型解决所有问题。
在这样的大背景下,我们不禁要问:之前耗费了几十年心血研究的语义表示 AMR,在这个时代还有存在的必要吗?

AMR 通过将句子转化为以概念为节点、以关系为边的有向无环图,力图刻画句子的本质语义内容,剥离表层的语法形式。这种结构化的语义表示方式,曾被认为是实现自然语言理解的关键。但现在大语言模型仅仅基于海量语料的预训练,就已经展现出了惊人的理解和生成能力。那么,我们是不是已经可以彻底抛弃 AMR 这样的语义表示了呢?
事情真的就这么简单吗?本文的作者们并不这么认为。他们认为,在当前大语言模型的语义理解和推理能力还远非完美的情况下,结构化的语义表示或许可以起到重要的辅助和补充作用。为了验证这一想法,他们设计了一系列实验来探究 AMR 在大语言模型时代究竟还能发挥什么独特的价值。
这其实是一个更普遍问题的缩影:传统的语言学知识,如句法、语义等形式化表示在当前神经网络大模型盛行的时代,是否已经完全丧失了价值?还是说,它们可以与大模型优势互补,实现更好的人工智能应用?这篇文章通过聚焦 AMR 这一典型案例。给出了颇具启发性的思考。
当然,文章的探索仍处于初步阶段,还有很多悬而未决的问题,需要后续研究进一步深入。但无论如何,这项工作为传统语言学知识和前沿语言模型的融合,迈出了宝贵的第一步。期待在这一方向上未来有更多学者跟进,为构建更强大、更可解释的语言AI系统贡献自己的力量。
AMRCOT:思维链中融入 AMR 表示
为了研究 AMR 在大语言模型时代的作用,本文作者们提出了一种叫做 AMRCOT 的新方法,其灵感来自于最近很火的思维链(Chain-of-Thought, CoT)提示方法。
什么是思维链提示呢?简单来说,就是在提示语中不仅给出问题本身,还给出了解决问题的思路和步骤。就像老师在教学生解题一样,不仅告诉学生题目是什么,还手把手教学生怎么一步步去解题。研究发现,这种方式可以显著提高当前大语言模型在一些复杂推理任务上的表现。
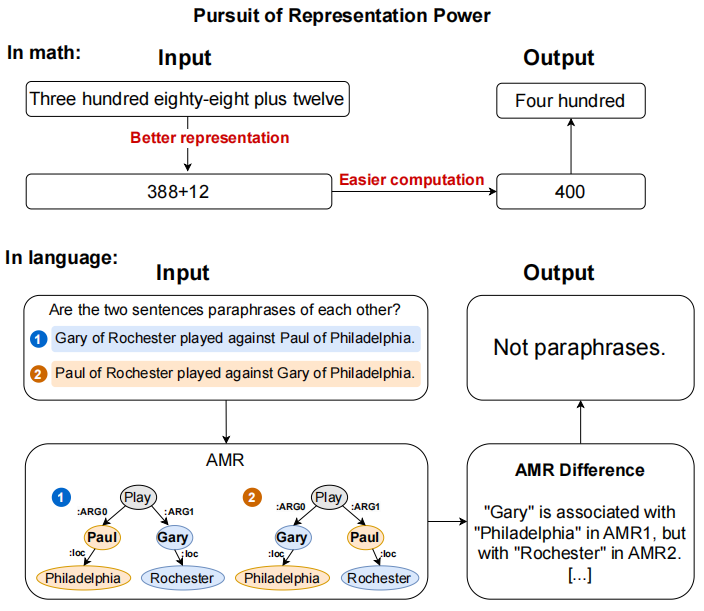
AMRCOT 的核心思路就是在思维链的基础上再加入一环,即将原始文本对应的 AMR 表示喂给大模型。这就像在解题思路里,不仅有自然语言描述的解题步骤,还附上了该题目的结构化表示。通过这种方式,作者希望研究 AMR 是否可以给大模型提供一些额外的有用信息,帮助其更好地理解和解决任务。下图表示了基础 prompt 和 AMRCOT prompt 对比。

举个例子,如果我们想判断两个句子是不是语义相似,传统的思维链提示可能是这样的:
-
找出两个句子的主语、谓语、宾语;
-
判断它们的主语是否指代相同的事物,谓语是否表达相似的行为,宾语是否指代相同的对象;
-
如果以上三点都很相似,那么可以判断这两个句子语义相似。
而在 AMRCOT 中,除了以上思维链,我们还会在提示中加入这两个句子对应的 AMR 图。AMR 图以一种结构化的方式表示了句子的核心语义角色。输入的 AMR 图可以使模型更清晰地"看到"两个句子在语义结构上是否一致,比单纯的文本描述更加直观。
当然这只是一个简单的例子。在实际的实验中,AMRCOT 的具体形式要复杂得多。但核心思想就是在提示中融入 AMR 的结构化信息,来探究它对大模型理解和推理的帮助。这种融合语言学知识与前沿语言模型的尝试,可以说是这项工作最大的亮点和创新之处。
那么 AMRCOT 的实际效果如何呢?它能否如作者所愿,为大语言模型注入新的智慧呢?让我们拭目以待后续的实验结果。
揭秘 AMRCOT:五大 NLP 任务验证,结果出人意料!
为了全面评估 AMRCOT 的效果,作者们将其应用于五个代表性的自然语言处理任务:
-
语义相似性判断(PAWS):判断两个句子是否表达相同的语义。
-
机器翻译(WMT16):将句子从一种语言翻译成另一种语言。
-
逻辑谬误检测(Logic):判断一段话是否包含逻辑谬误。
-
事件抽取(Pubmed45):从文本中抽取事件。
-
文本生成SQL(SPIDER):根据文本描述生成对应的SQL查询语句。
这五个任务涵盖了自然语言理解、生成、推理等多个方面,可以说是对 AMRCOT 的一次全方位测试。同时,为了让实验更贴近实际应用场景,作者选择了直接使用指令微调后的 GPT-3.5 和 GPT-4 等大模型,而非针对特定任务重新训练模型。通过比较使用 AMRCOT 和直接用原始文本提示的效果差异,我们就可以判断出 AMR 在这些任务中的实际贡献有多大。
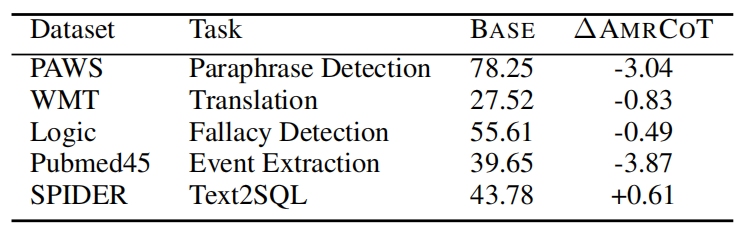
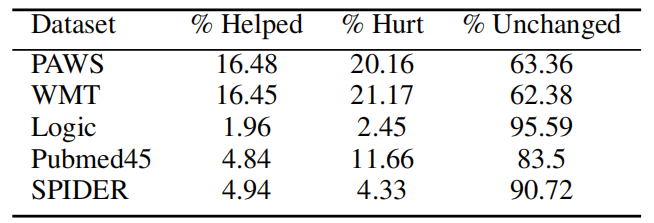
实验的结果出乎很多人的意料。在五项任务中,使用 AMRCOT 的整体效果并不比直接用原始文本提示的基线方法高多少,性能波动范围仅在-3%到1%之间。其中在 PAWS、WMT、Logic 和 Pubmed45 任务上,加入 AMR 表示后,性能反而还略有下降。只有在 SPIDER 任务上,AMRCOT 带来了0.61%的性能提升。
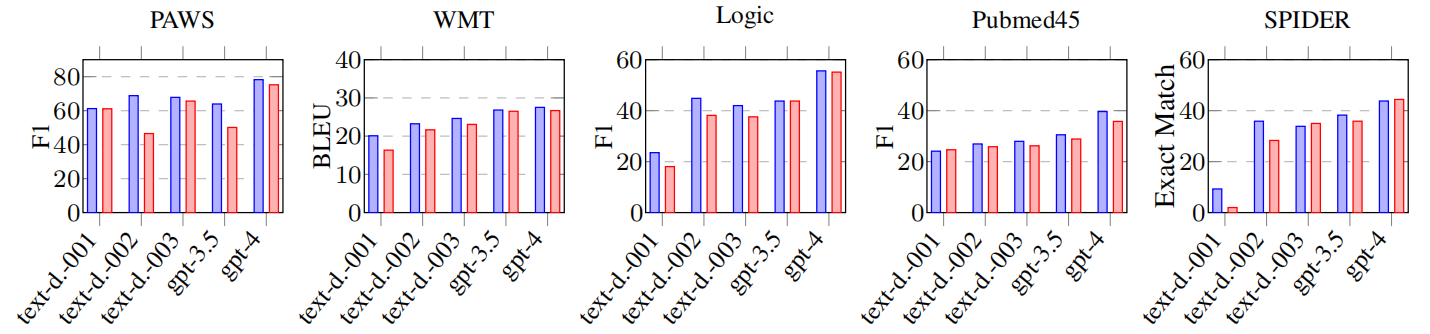
除此之外作者还验证了 AMR 对不同能力模型的影响,从结果上可以看出 AMR 在大多数任务和大多数模型上都会造成模型性能下降。能力比较差的模型使用 AMR 时性能下降更多,作者分析这可能是因为这些模型理解 AMR 及其特殊符号的能力有限。
乍一看这个结果似乎在说,AMR 这样的语义表示,在当前大语言模型已经如此强大的情况下,已经很难再带来显著的性能提升了。是不是意味着,我们可以彻底告别 AMR,让大模型横行天下了呢?
但作者进一步的分析发现,事情并非如此简单。虽然整体性能提升有限,但细粒度的分析表明在某些特定类型的样本上,AMRCOT 还是能发挥独特的作用。这就像是一支部队的整体战斗力可能和另一支旗鼓相当,但在特定地形和特定兵种上,双方的表现可能有很大差异。
那么,究竟是哪些样本让 AMRCOT 大显身手呢?AMR 和大语言模型的组合,未来还有哪些可能的突破口?让我们继续读下去一探究竟。
原来 AMR 在这些地方能发光发热!
尽管使用 AMRCOT 对五项任务的整体性能提升有限,但当研究人员将目光聚焦到更细粒度的样本层面时,却发现了一些有趣的现象。
在语义相似性判断(PAWS)和机器翻译(WMT)任务中,虽然总体指标略有下降,但仍有36%左右的样本在使用 AMRCOT 发生了变化。这引起了研究人员的兴趣:是什么特点让这些样本从结构化语义表示中获益呢?
通过进一步的实验,作者深入探究了 AMR 在什么情况下能够帮助提升模型性能,而在什么情况下会降低模型性能。
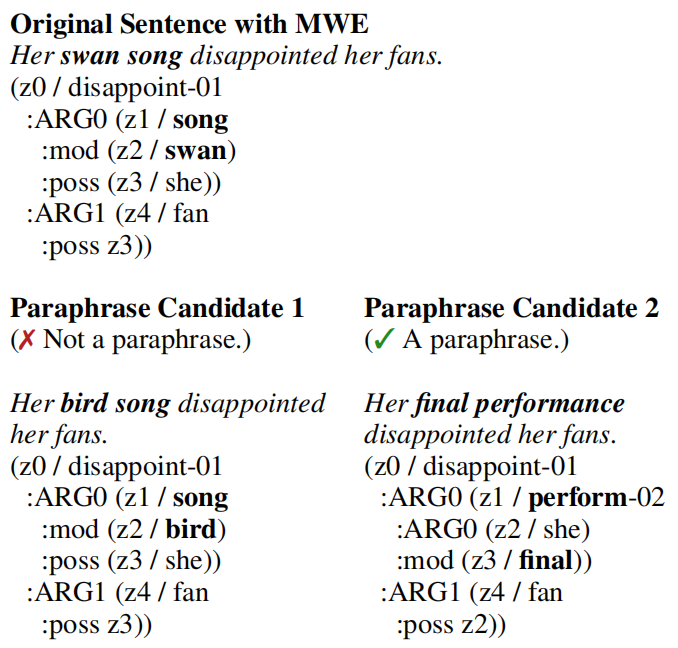
首先,作者通过一个案例研究说明了 AMR 在处理多词表达(Multi-word Expressions, MWE)时的局限性。作者以"swan song"(绝唱)这个 MWE 为例,说明 AMR 无法正确表示其语义,导致在涉及MWE的语义相似性任务中模型性能反而下降。
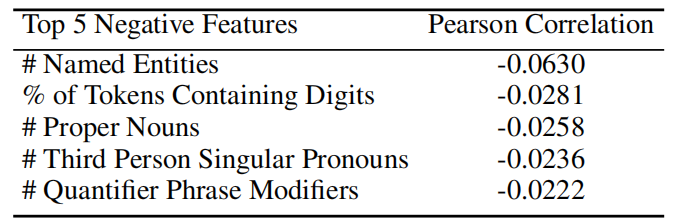
接下来,作者进行了大规模的文本特征分析,试图找出 AMR 表现出优势和劣势的样本特点。通过计算各种语言学特征与 AMR 效果提升的相关性,作者发现 AMR 在处理包含形容词、复杂词汇和状语从句的语句时更有帮助,而在处理包含命名实体、数字和第三人称代词的语句时效果欠佳。

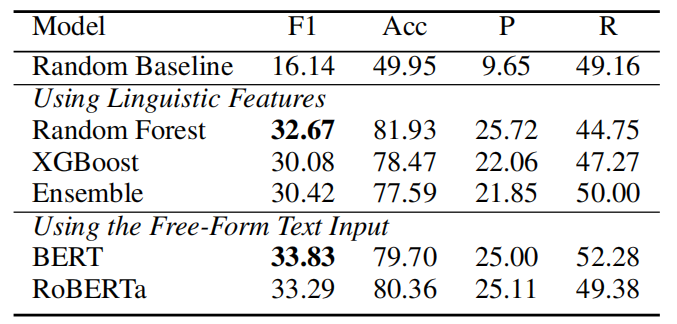
最后,作者将 AMR 效果提升建模为一个二分类任务,使用各种机器学习模型(如随机森林、XGBoost、BERT等),尝试根据输入文本的特征来预测 AMR 是否有帮助。实验结果表明,基于语言学特征的模型能达到32.67%的F1值,而基于 BERT 等神经网络的模型能将F1值提高到33.83%。不过作者也指出,目前的预测性能还不够理想,未来还需要更多的数据和更精妙的建模方法。
为了进一步验证 AMR 的作用,研究人员还设计了一个有趣的实验:如果我们用 gold AMR (即人工标注的准确 AMR)替换自动解析的 AMR,结果会不会更好?毕竟当前的 AMR 解析器准确率还不够高,解析错误可能会误导模型。出乎意料的是,在命名实体识别任务上,使用自动 AMR 和 gold AMR 的效果相差无几!这提示我们,提升 AMR 解析器性能可能不是当务之急,更重要的是探索如何将AMR的结构化信息与大模型的学习能力更好地结合。

总的来说,这些细粒度的分析让我们看到,尽管 AMRCOT 整体效果平平,但在处理某些富有挑战的语言现象上的确展现出了它的独特价值。未来如果我们能够找到更好的方式,将知识和数据驱动的方法融合,不仅是 AMR,其他的语言学知识或许也能在大语言模型时代重放异彩,让人工智能的语言理解和应用更上一层楼。
大语言模型时代,传统语言学还有立足之地吗?
这项研究基于细致入微的实证分析,为传统语义表示 AMR 在当下大语言模型时代探索出了一条崭新的发展路径。尽管 AMR 在提升大模型整体性能上效果有限,但在处理某些富有挑战的语言现象时,其结构化的语义信息却展现出了独特的价值,这无疑为研究者们如何在传统语言学知识和前沿语言模型之间寻找平衡提供了宝贵的启示。
站在更高的层面来看,这项工作也引发了我们对传统语言学和现代人工智能关系的思考。在人工智能飞速发展的今天,传统语言学知识如何与大数据、大模型相结合,找到自己新的定位和价值?这是一个亟需持续关注、深入研究的重要课题。这篇文章虽然聚焦于 AMR 和大语言模型,但其思考模式具有一定的普适性。它启发我们,传统语言学和现代人工智能或许并非你死我活的关系,而是可以互补共生、相得益彰的。
期待在不久的将来,能看到更多继承这一思路的探索性研究,进一步拓展传统语言学赋能智能时代的路径,为人工智能的理论升级和应用创新,注入源源不断的营养。或许,传统语言学和大语言模型终会殊途同归,共同服务于人类对语言奥秘的探索和应用。或许,这个时代正在到来!


这篇关于今日arXiv最热NLP大模型论文:NAACL24实锤语言学对大模型“负优化”,抽象语义表示+思维链有损表现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








