对大专题

RAG噪声的设计及其对大模型问答的作用分析
有趣的大模型中RAG噪声的作用分析 大模型(LLMs)在多个任务上表现出色,但存在依赖过时知识、幻觉等问题。RAG作为一种提高LLM性能的方法,通过在推理过程中引入外部信息来缓解这些限制。 Figure 1 展示了一个来自 NoiserBench 的示例,它阐释了不同类型的 RAG 噪声对大型语言模型(LLM)的影响。这个示例通过一个具体的问题和答案的情境来说明有益噪声和有害噪声对模型性能的不

位映射对大数据排重与排序
利用位映射原理对大数据排重 问题提出:M(如10亿)个int整数,只有其中N个数重复出现过,读取到内存中并将重复的整数删除。 问题分析:我们肯定会先想到在计算机内存中开辟M个int整型数据数组,来one bye one读取M个int类型数组, 然后在一一比对数值,最后将重复数据的去掉。当然这在处理小规模数据是可行的。 我们 考虑大数据的情况:例如在j

初学者如何对大模型进行微调?
粗略地说,大模型训练有四个主要阶段:预训练、有监督微调、奖励建模、强化学习。 预训练消耗的时间占据了整个训练pipeline的99%,其他三个阶段是微调阶段,更多地遵循少量 GPU 和数小时或数天的路线。预训练对于算力和数据的要求非常高,对于普通开发者来说基本上不用考虑了。 对于开发者来说,如果你有几块GPU显卡,那么就可以尝试微调了。不过在微调之前,我们要弄明白为什么要微调,大模型为什么不能

今日arXiv最热NLP大模型论文:NAACL24实锤语言学对大模型“负优化”,抽象语义表示+思维链有损表现
大语言模型正以势不可挡的姿态席卷自然语言处理领域。在这个语言模型大显神威的时代,很多任务都转变为了端到端的文本生成任务。那么,在此之前我们苦心孤诣研究了几十年的语义表示,例如 AMR(抽象意义表示),在这个时代里还能派上用场吗? 这篇文章针对这个问题展开了研究,作者们提出了一种基于 AMR 的思维链(chain-of-thought)提示方法 AMRCOT,在5个自然语言处理任务上对比研究了这种

对大模型和AI的认识与思考
1. 写在前面 自从OpenAI在2022年11月30日发布了引领新一轮AI革命浪潮的产品ChatGPT以来,大模型和生成式AI这把大火在2023年越烧越旺,各种技术和应用层出不穷;而2023年11月,同样是OpenAI CEO山姆·奥特曼(Sam Altman)被开除后有回归,这100小时的宫斗赚足了媒体和世界网名的关注,引出了大家对AI安全的遐想和担忧。 以OpenAI开始,以OpenAI

对大数据量进行排序--位图法
题目:对2G的数据量进行排序,这是基本要求。 数据:1、每个数据不大于8亿;2、数据类型位int;3、每个数据最多重复一次。 内存:最多用200M的内存进行操作。 我听过很多种类似问题的解法,有的是内存多次利用,有的用到了外存,我觉得这两种做法都不是比较好的思想,太慢。由于这个题目看起来没有对效率进行约束,所以这两种方法也是对的,但是我这次提出一个比较好的算法来解答此题,如果有更好的做法请赶
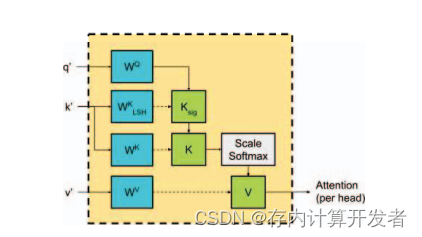
存内计算对大语言模型推理的加速
本篇文章集中讨论了存内计算技术在加速大语言模型推理方面的潜力,从大语言模型的背景知识出发,探讨目前其面临的挑战,进而剖析两篇经典的文献以彰显存内计算有望解决目前大语言模型在推理加速方面存在的问题,最后围绕大语言模型与存内计算的结合展开构想。 大语言模型的背景知识及其面临的挑战 (一)大语言模型的基础概念 通俗来说,大语言模型(Large Language Model,LLM)是基于海量文本

【论文速读】| 对大语言模型解决攻击性安全挑战的实证评估
本次分享论文为:An Empirical Evaluation of LLMs for Solving Offensive Security Challenges 基本信息 原文作者:Minghao Shao, Boyuan Chen, Sofija Jancheska, Brendan Dolan-Gavitt, Siddharth Garg, Ramesh Karri, Muham

利用shell脚本对大文件进行分割
有系统运维的过程中,日志文件往往非常大,这样就要求对日志文件进行分割,在此特用shell脚本对文件进行分割 方法一: #!/bin/bash linenum=`wc -l httperr8007.log| awk '{print $1}'` n1=1 file=1 while [ $n1

ChatGPT时代对大数据应用的展望
前言: 2022年底,科技圈有个爆炸性新闻,ChatGPT的诞生,引发了世界范围内的震惊;人工智能在与人交流上有了划时代的技术突破,可以和人深入的理解交流,让许多公司和领域对这项技术有了更多遐想。对于大数据领域,ChatGPT的出现会对这个行业产生什么影响,这是一个值得讨论和分析的话题。 一、ChatGPT提供的技术能力分析 2022年初,北京冬奥会世界瞩目;三月
小红书搜索团队提出全新框架:验证负样本对大模型蒸馏的价值
大语言模型(LLMs)在各种推理任务上表现优异,但其黑盒属性和庞大参数量阻碍了它在实践中的广泛应用。特别是在处理复杂的数学问题时,LLMs 有时会产生错误的推理链。传统研究方法仅从正样本中迁移知识,而忽略了那些带有错误答案的合成数据。 在 AAAI 2024 上,小红书搜索算法团队提出了一个创新框架,在蒸馏大模型推理能力的过程中充分利用负样本知识。负样本,即那些在推理过程中未能得出正确答案的

【数据库】对大数据量数据集,PostgreSQL分组统计数量,使用 row_number() over
在处理大数据量数据集时,我们经常需要进行分组统计。而在 PostgreSQL 中,我们可以使用 row_number() 函数结合 over (partition by) 子句来实现这个功能。同时,通过设置 row_num <= 100 的条件,我们可以限定每组最多数量为 100。本文将详细介绍如何使用这种方法进行分组统计。 一、row_number() 函数简介 row_number() 函
EmotionPrompt:对大语言模型 “动感情” 就能够提升表现
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 大语言模型(LLMs)已经证明具有高智商,在常见的标准化测试中排名前百分之几。但是它们的情商又如何呢?情商是一种深层的人类特质,细微而又与我们日常解决问题息息相关。LLM 能否理解这种类型的智慧,并像我们一样加以利用呢? 中科院软

如何对大模型进行评估下
如果从实现评估的纬度来分,可以将不同类型的评估分为三类,具体如下所示。更多理论的详细信息可以参见博客《如何对大模型进行评估上》。接下来就从第一种类型出发,看看评估脚本是如何实现的。这里分析的源代码是Qwen的评估脚本。 如何使用选择题类型数据集进行评估 下面的代码是Qwen大模型提供的evaluate_ceval.py评估脚本的部分代码,原始代码所有信息请查看官网。下面对脚本中部分
3D Web轻量引擎HOOPS Communicator如何实现对大模型的渲染支持?
除了读取轻松外,HOOPS Communicator对超大模型的支持效果也非常好,它可以支持30GB的包含70万个零件和3.5亿个三角面的Catia装配模型! 那么它是如何来实现对大模型的支持呢? 我们将从以下几个方面与大家分享:最低帧率控制、增量更新、截流等级、边界预览、内存限制以及破碎模式轻量化。 HOOPS_HOOPS试用_3D软件开发工具_HOOPS中国区指定经销商_慧都科技-HOO
比尔盖茨早有预警:对大疫情爆发我们还没准备好
比尔盖茨早已预警,如今全球最大的危险不是核战争,而是高度传染的病毒,不是导弹,而是微生物。 新型冠状病毒感染肺炎新增病例数仍在增长,钛媒体根据百度数据统计官方发布显示,截止发稿前1月30日9:30,全国累计报告新型冠状病毒感染的肺炎确诊病例7736例,治愈124例。这次疫情不得不让我们重新思考,面对潜在的病毒爆发,人类是否已经做好了足够的准备? 其实,早在2015年非洲埃博拉疫情爆发,一
spark + ansj 对大数据量中文进行分词
本文要解决的问题: 实现将Spark与中文分词源码(Ansj)相结合,进行一系列中文分词操作。 目前的分词器大部分都是单机服务器进行分词,或者使用hadoop mapreduce对存储在hdfs中大量的数据文本进行分词。由于mapreduce的速度较慢,相对spark来说代码书写较繁琐。本文使用 spark + ansj对存储在hdfs中的中文文本数据进行分词。 首先下载ansj源码文
冲击AI芯片第一股的寒武纪:3年亏损16亿,对大客户依赖严重
数据猿 陈天石出生于1985年,16岁考入中科大少年班,25岁成为中科大计算机博士,毕业6年后创办寒武纪。 大数据产业创新服务媒体 ——聚焦数据 · 改变商业 AI芯片独角兽寒武纪的经营业绩终于揭开神秘面纱。 3月26日晚间,上交所官网显示,寒武纪的科创板上市申请获准受理。如果顺利登陆资本市场,寒武纪将成为科创板AI芯片第一股。 疫情之下,AI再次热闹了起来,但从目前的市场判断,