本文主要是介绍3D Web轻量引擎HOOPS Communicator如何实现对大模型的渲染支持?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
除了读取轻松外,HOOPS Communicator对超大模型的支持效果也非常好,它可以支持30GB的包含70万个零件和3.5亿个三角面的Catia装配模型!
那么它是如何来实现对大模型的支持呢?
我们将从以下几个方面与大家分享:最低帧率控制、增量更新、截流等级、边界预览、内存限制以及破碎模式轻量化。
HOOPS_HOOPS试用_3D软件开发工具_HOOPS中国区指定经销商_慧都科技-HOOPS_HOOPS试用_3D软件开发工具_慧都科技慧都科技是HOOPS全套产品中国地区指定授权经销商,提供3D软件开发工具HOOPS售卖、试用、中文试用指导服务、中文技术支持。![]() http://techsoft3d.evget.com/
http://techsoft3d.evget.com/
1 最低帧率
渲染场景时,HOOPS Communicator将按投影屏幕大小对可见对象进行排序,并首先渲染最大的项目。
系统旨在通过中断渲染和将控件返回给用户来保持最小的交互式帧率,以便他们可以继续与查看器进行交互。
您可以使用WebViewer.setMinimumFrame函数设置系统将维护的帧率。
但是,通过设置更高的最小帧率获得更高的性能是有代价的。
与系统交互时,将渲染较少的场景,以保持交互性。下图演示了在模型中飞行时以不同的最小帧率渲染相同视图的效果。
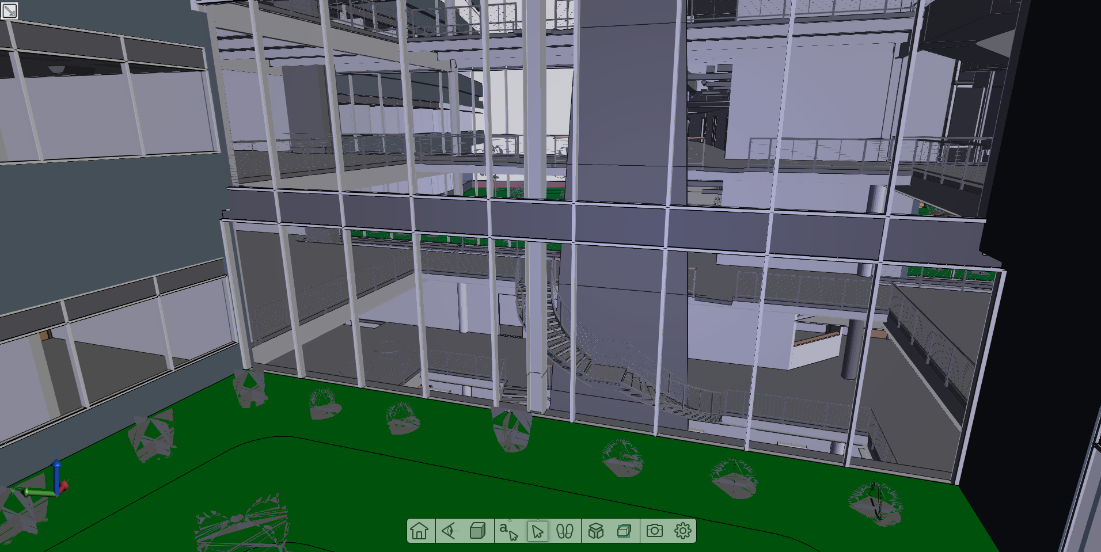
将最小帧速率设置为 15 的室内场景渲染
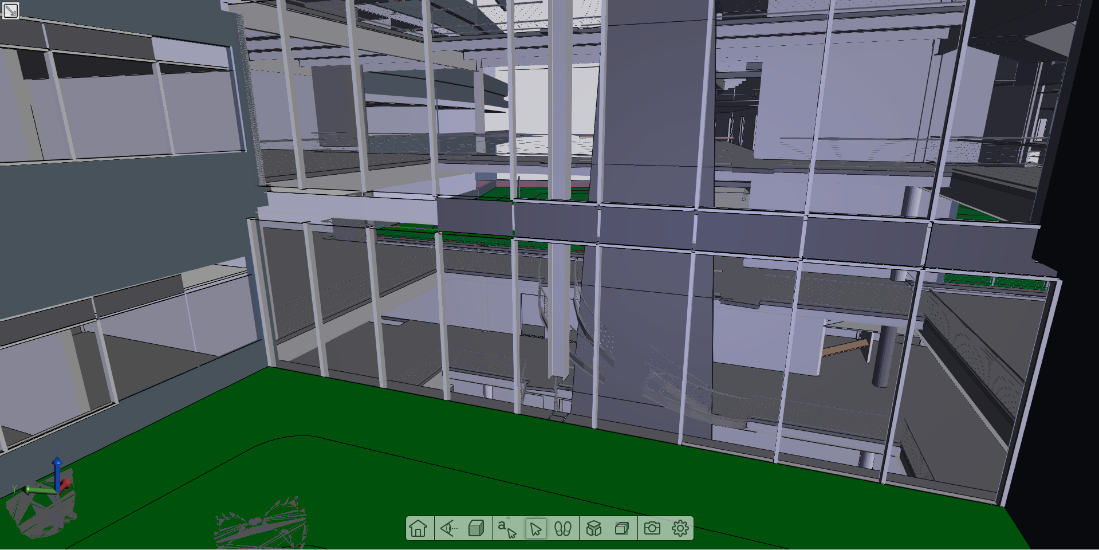
将最小帧速率设置为 30 的室内场景渲染
2 增量更新
场景将增量渲染,以保持与大型场景的交互性。从上面的示例中,当用户停止与模型交互时,场景将增量渲染其余对象,而无需执行完全重绘,直到渲染整个场景。
当交互恢复时,增量更新将中断,并再次保持最小帧率。
您可以使用WebViewer.setDisplayCompletFrames方法启用或禁用增量更新。
默认情况下,增量更新处于启用状态,在呈现包含许多部分的非常大的模型时非常有用。此功能可防止系统在渲染过程中产生明显的暂停,并允许用户在所有的时间移动摄像机。
3 截流等级
HOOPS Communicator的默认行为是剔除视图中显示非常小的项目。目的是避免在对当前场景没有明显影响的几何图形上花费带宽和渲染资源。
使用此技术剔除对象的判断条件是通过将其投影边界直径视为屏幕空间的百分比而做出。如果此百分比小于截流值,则剔除对象,并且不进行绘制调用。
默认流截止值为0.0125。这意味着要渲染对象时,这意味着要渲染的对象,其投影屏幕空间边界直径(占屏幕空间的百分比)必须至少为该值。
您可以通过使用WebViewer.setStreamCutoffScale方法将比例因子应用于此值来调整应用程序中的性能。传递给此方法的值标识了一个介于0.0和2.0之间的比例,该比例将应用于默认值。
将比例因子设置为0将完全禁用流截止选择。
下图显示了在部件的一部分上设置streamCutoffScale的效果:
*注意机器外壳周围细节的变化
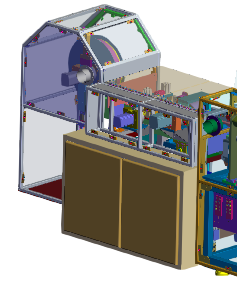
StreamCutoffScale: 0 (disabled)

StreamCutoffScale: 1
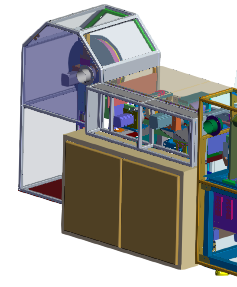
StreamCutoffScale: 1
4 边界预览
加载非常大的模型时,将需要一些时间才能将相关数据从服务器流式传输到客户端。 边界预览提供了可视化的模型中正在等待数据到达的部分。 下图显示了部分加载的飞机模型的边界预览。
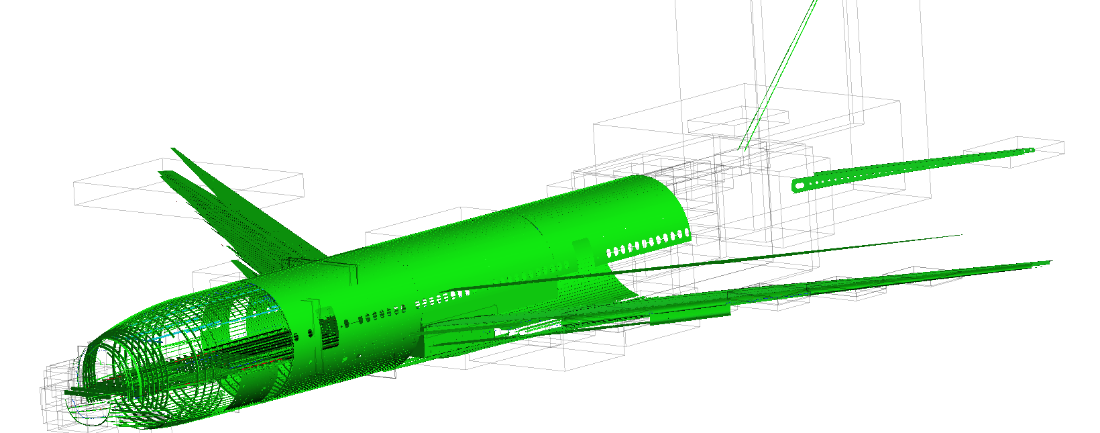
部分加载模型的边界预览
在启动查看器之前,应设置边界预览模式。
边界预览可以与OnDemand加载模式一起使用,以在处理大型模型时提高性能。 它们还可以用于提供有关加载部分如何适合模型的整个上下文。 您可以使用Communicator.StreamingMode设置OnDemand。
5 内存限制
内存限制使您可以对给定时间在客户端上使用的GPU资源量进行某种控制。
当试图在图形资源有限的模型上查看具有大量几何图形的模型时,这很有用。
要启用内存限制,请在创建WebViewer对象时指定memoryLimit选项。
以下代码显示了创建一个Web浏览器的示例,该示例施加了256 MB的限制:

启动查看器后,数据将正常开始流式传输。
如果系统检测到流传输到服务器的其他数据将超出限制,则现有数据将从客户端弹出,为新的、更相关的数据腾出空间。
弹出顺序由当前加载的网格投影边界信息的优先级队列控制。 如果弹出的数据再次变得相关,它将根据需要从服务器重新传输。
6 显示帧率
您可以使用setStatisticsDisplayVisibility方法启用实时渲染统计信息。 统计信息可帮助您深入了解模型的性能。

统计信息显示在 WedViewer 的左上角
下表描述了统计信息显示面板中包含的数据:

>>>点击申请HOOPS试用![]() http://x7pfmmn259623uby.mikecrm.com/l9292M9 如果您当前也有3D模型格式转换、3DWEB轻量化或数据发布的需求,欢迎留言~
http://x7pfmmn259623uby.mikecrm.com/l9292M9 如果您当前也有3D模型格式转换、3DWEB轻量化或数据发布的需求,欢迎留言~
这篇关于3D Web轻量引擎HOOPS Communicator如何实现对大模型的渲染支持?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





