本文主要是介绍如何对大模型进行评估下,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果从实现评估的纬度来分,可以将不同类型的评估分为三类,具体如下所示。更多理论的详细信息可以参见博客《如何对大模型进行评估上》。接下来就从第一种类型出发,看看评估脚本是如何实现的。这里分析的源代码是Qwen的评估脚本。

如何使用选择题类型数据集进行评估
下面的代码是Qwen大模型提供的evaluate_ceval.py评估脚本的部分代码,原始代码所有信息请查看官网。下面对脚本中部分重点代码进行了解释。以get_logits为例,输入的信息通过tokenizer进行编码处理后,输入大模型,得到原始输出outputs后,通过softmax函数,将得到的结果转换为概率分布数据,这样,在提取大模型的答案时,从4个选项中选取概率最大的作为选择题的答案,与真实答案进行对比即刻。
def load_models_tokenizer(args):#调用AutoTokenizer从预训练模型加载tokenizer,这里的checkpoint_path就是大模型名称或者存储的pathtokenizer = AutoTokenizer.from_pretrained(args.checkpoint_path,pad_token='<|extra_0|>',eos_token='<|endoftext|>',padding_side='left',trust_remote_code=True)#加载大模型model = AutoModelForCausalLM.from_pretrained(args.checkpoint_path,pad_token_id=tokenizer.pad_token_id,device_map="auto",trust_remote_code=True).eval()#主要用于设置生成文本的参数model.generation_config = GenerationConfig.from_pretrained(args.checkpoint_path,pad_token_id=tokenizer.pad_token_id,trust_remote_code=True)return model, tokenizer#从下载的csv文件原始数据中读取每一行的question,并进行文本的简要处理
def format_example(line, include_answer=True):example = "问题:" + line["question"]for choice in choices:example += f'\n{choice}. {line[f"{choice}"]}'if include_answer:example += "\n答案:" + line["answer"] + "\n\n"else:example += "\n答案:"return example#从下载的zip文件中,解压出dev,eval,test三个folder,dev中有5条数据作为shot,这里提取这5条数据作为few-shot
def generate_few_shot_prompt(k, subject, dev_df):prompt = ""if k == -1:k = dev_df.shape[0]for i in range(k):prompt += format_example(dev_df.iloc[i, :],include_answer=True,)return prompt#组装好的inputs就是问题+few_shot的prompt,传入后,调用模型,得到原始模型输出logits,然后将得到的答案转换为概率
def get_logits(tokenizer, model, inputs: List[str]):#inputs_ids的长度不等,这里按最大长度进行填充input_ids = tokenizer(inputs, padding='longest')["input_ids"]#将输入的信息转换为pytorch中的张量input_ids = torch.tensor(input_ids, device=model.device)tokens = {"input_ids": input_ids}# 创建 attention_mask,用于指示哪些位置是 padding 位置,以便在模型中进行注意力处理时排除这些位置attention_mask = input_ids.ne(tokenizer.pad_token_id)# 使用模型进行推断,获取模型的输出 logitsoutputs = model(input_ids, attention_mask=attention_mask)["logits"]logits = outputs[:, -1, :]#通过softmax函数,将原始的logits转换为概率分布数据log_probs = torch.nn.functional.softmax(logits, dim=-1)return log_probs, {"tokens": tokens}除了关键的get_logits方法外,还有format_example函数,该函数的作用就是从原始数据集中获取question,然后,对格式进行稍微的调整。调整后的结果如下图所示,这是数据中某一个问题

获取question后,在输入给大模型前,还带了5-shot,结果如下图所示,在输入信息中提供shot,能最大程度的告知大模型如何回答后面的问题,保证能评估到大模型真正的能力。
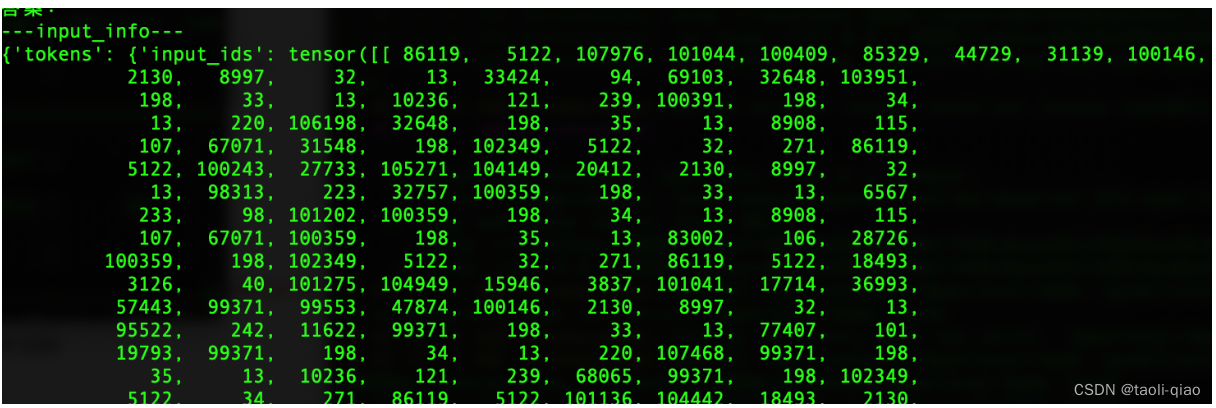
输入的文字信息通过tokenizer进行编码后,再通过pytorch提供的tensor方法,将信息转换为张量,即大模型认识的一种信息表达方式。具体如下所示
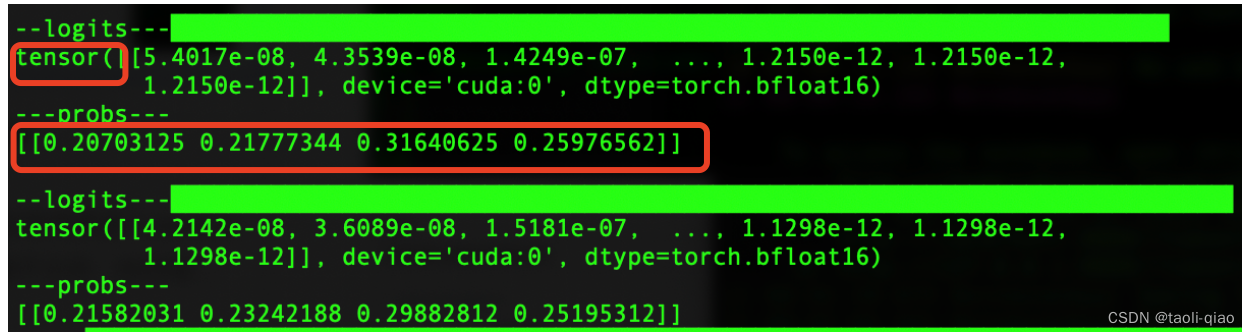
输入信息转换成张量后,传递给大模型,得到原始的logis结果,结果信息如下图所示,也是张量信息。接着调用softmax函数,将结果信息转换成概率分布数据,即下图中的probs信息。
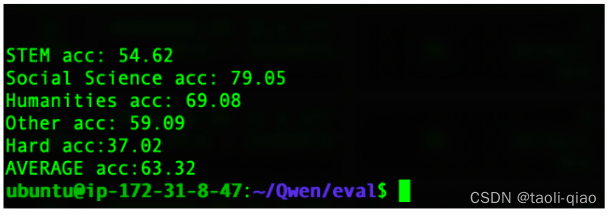
在得到大模型对于每个答案的概率信息后,选取概率最大的答案作为大模型生成的答案,然后与数据集中真实的答案进行对比,计算正确的百分比作为最终的评估值。下图是调用整个评估脚本得到的Qwen-7B大模型的评估分数。可以看到,数据集中有很多subset的子集,不同的子集又被划分到不同类型中。例如某些题目属于Social Science类型,某些属于Humanities类型。这里计算的是不同类型的平均分值。
执行脚本后,除了得到最终的评估值外,还会生成一份详细的评估数据信息,如下图所示。可以看到,该文件中记录了整个中间信息。包括id,提取的question,数据集中的可选答案:A、B、C、B,数据集中的标准答案answer,对四个选项,大模型的预估概率值:prob_A、prod_B、prob_C、prob_D,最有还有correctness值。如果与真实答案相同则值为1,如果不相同值为0.

以上就是对于选择题类型的数据集,在编写脚本调用大模型获取评估值的过程,总结脚本中关键步骤,如下图所示:

如何使用代码生成类型数据集进行评估
对于代码生成类型的数据集,openai已经提供了一套评估脚本。对于大模型本身,如果想估算pass@k的值,只需要生成数据集中每个任务的答案,并组装成jsonl文件即可,然后,调用openai提供的脚本就能得到pass@k的值。即执行下面的命令即可计算出pass@k值。
evaluate_functional_correctness xx.jsonl传递给上述命令的jsonl文件的内容,如下所示:

查看Qwen中evaluate_humanEval脚本,有核心方法generate_sample()方法,该方法中将输入的信息通过调用tokenizer.encode进行编码,然后调用torch.tensor()将输入信息转换为张量,接着调用model生成输出信息,对于输出信息,调用了decode方法进行解码,解码后就是最终的输出信息,即上面jsonl文件中的completion字段内容了。

下面是decode()方法的代码,除了调用tokenizer.decode()进行解码外,还通过split方法对生成的内容进行了提取。
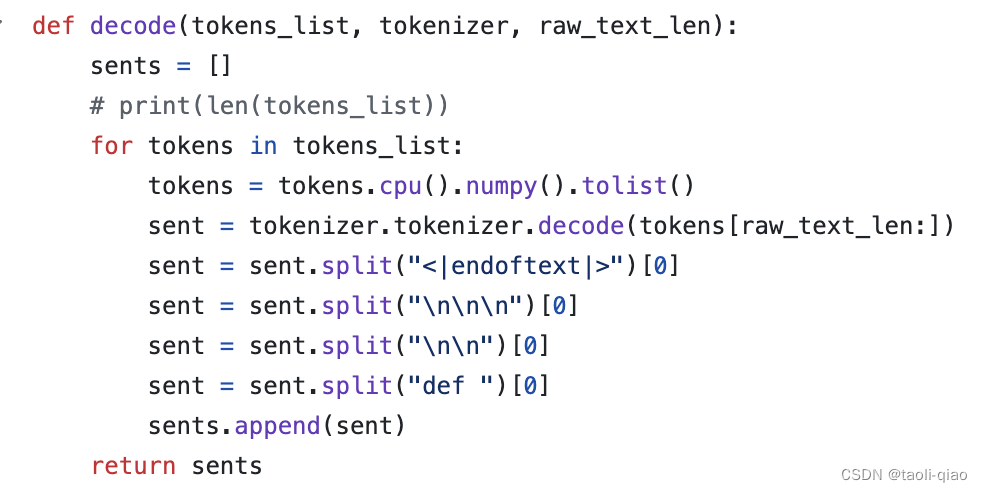
通过split方法对生成的内容进行提取,下图是截取的数据集中某一个题目的生成中间信息,input text是从数据集中提取出来的需要完成的题目prompt,before sent是大模型生成的原始答案,可以看到不止生成了一个解决方案,总共生成了4个答案,后面三个答案的function名称是大模型自定义的。上面的decode方法中提取的就是第一个内容。after sent就是提取出来的内容。

经过decode后,最终组装出来的jsonl文件如下图所示:
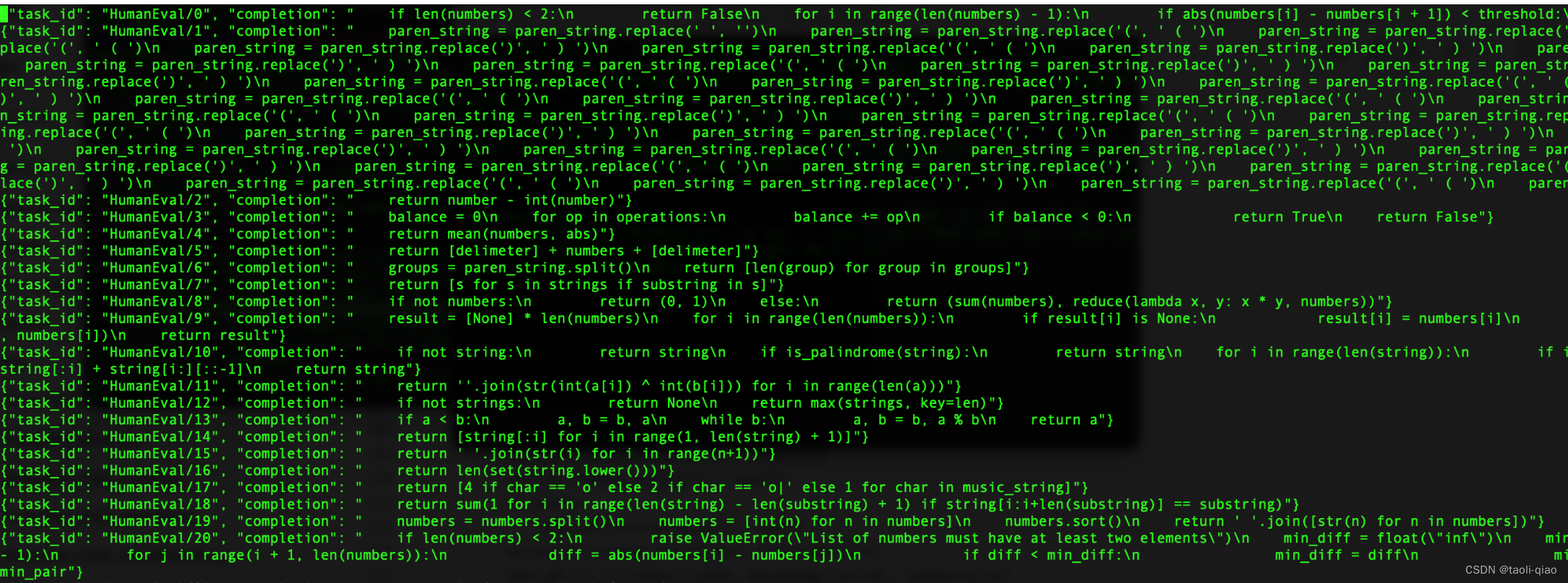
生成了包含大模型结果的jsonl文件中,执行下面的命令,即调用openai官网提供的脚本即可计算出pass@k的值。
"""
git clone https://github.com/openai/human-eval
$ pip install -e human-eval
evaluate_functional_correctness sample-output-file
"""那么openai的脚本是如何check生成的代码是否能通过单元测试呢?这里主要使用了python中的exec方法。
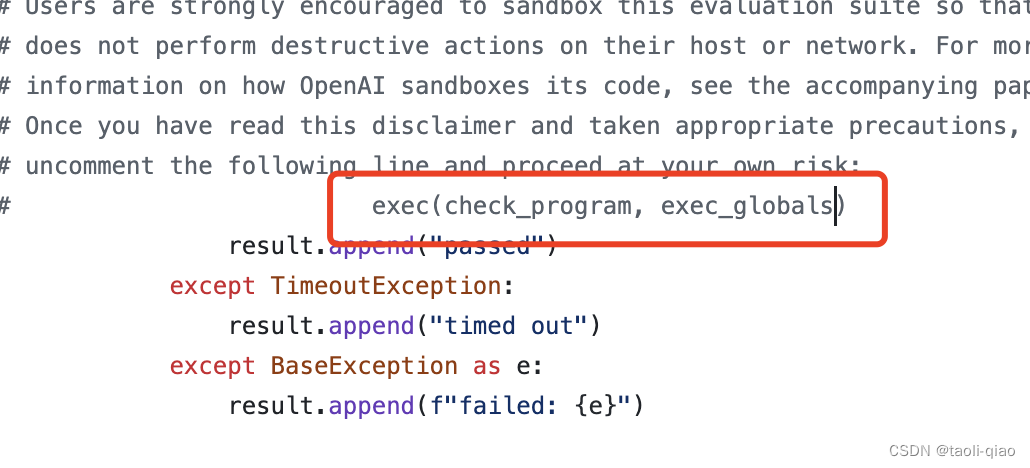
在 Python 中,exec() 是一个内置函数,用于执行存储在字符串中的 Python 代码,即通过调用exec(),可以执行jsonl文件中completion字符串中的代码。在执行的时候,脚本从数据集中提取出单元测试,从jsonl文件中提取出completion,组装在一起,调用exec()执行,执行通过,则说明生成的代码能让单元测试通过。执行过程中报错,则说明生成的代码有问题,无法让所有的单元测试通过。
如何使用数学类题目数据集进行评估
对于数学类题目,如何进行验证呢?查看Qwen目录下的gsm8k的评估脚本。同理,核心方法也是generate_sample(),函数中的代码与上面的HumanEval脚本类似。

对于数学类题目,多加了一个步骤,就是对output_text进行extract_answer的处理,extrace_answer方法的作用是:从生成的答案中提取最后一个数字作为最终的题目答案。然后,与数据集中的正确答案进行对比,如果相等则认为题目回答正确。extract_answer方法的代码如下所示:

总结
通过分析Qwen中大模型评估脚本,大致理解了对于三种不同类型的数据集,如何通过python脚本实现对大模型能力的评估。汇总如下所示:
对于选择题类型的数据集,评估过程如下:
对于代码生成的数据集,评估过程如下:
备注:如果原始数据集与HumanEval数据集的prompt有差异的,需要先对数据集进行预处理,格式follow HumanEval的数据集格式即可。

对于数学运算类数据集,评估过程如下所示:

这篇关于如何对大模型进行评估下的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



