arxiv专题

论文翻译:arxiv-2024 Benchmark Data Contamination of Large Language Models: A Survey
Benchmark Data Contamination of Large Language Models: A Survey https://arxiv.org/abs/2406.04244 大规模语言模型的基准数据污染:一项综述 文章目录 大规模语言模型的基准数据污染:一项综述摘要1 引言 摘要 大规模语言模型(LLMs),如GPT-4、Claude-3和Gemini的快

AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.08.20-2024.08.25
文章目录~ 1.LowCLIP: Adapting the CLIP Model Architecture for Low-Resource Languages in Multimodal Image Retrieval Task2.Evaluating Attribute Comprehension in Large Vision-Language Models3.PropSAM: A P

AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.08.15-2024.08.20
文章目录~ 1.Out-of-Distribution Detection with Attention Head Masking for Multimodal Document Classification2.Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications3.HiRED: Atte
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.08.10-2024.08.15
文章目录~ 1.W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering2.Dynamic Adaptive Optimization for Effective Sentiment Analysis Fine-Tuning on Large Language Models3.Fact

解决arxiv下载速度慢的问题
使用国内中科院arxiv镜像: 修改两处内容:https–>httparxiv.org–>xxx.itp.ac.cn 例如: https://arxiv.org/abs/2009.14410 换成 http://xxx.itp.ac.cn/pdf/2009.14410
CoRR和arXiv
CoRR和arXiv到底是什么?_corr期刊-CSDN博客文章浏览阅读1.4w次,点赞8次,收藏10次。提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档CoRR和arXiv到底是什么文章目录一、arXiv二、CoRR前言 arXiv(X依希腊文的χ发音,读音如英语的archive)是一个收集物理学、数学、计算机科学、生物学与数理经济学的论文预印本的网站,始于1991年8月14日。
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.06.05-2024.06.10
文章目录~ 1.Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation2.Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies3.Low-Rank Quantization-Aware Tra
【arxiv】国内arxiv 镜像
arxiv 镜像: http://xxx.itp.ac.cn, 国内网络能流畅访问 简单直接的方法是: 首页 首页: http://xxx.itp.ac.cn 特定页面 把要访问 arxiv 链接中的域名从 https://arxiv.org 换成 http://xxx.itp.ac.cn , 比如: 从 https://arxiv.org/abs/1901.07249 改为 http:/
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.25-2024.05.31
文章目录~ 1.Empowering Visual Creativity: A Vision-Language Assistant to Image Editing Recommendations2.Bootstrap3D: Improving 3D Content Creation with Synthetic Data3.Video-MME: The First-Ever Compreh

(Arxiv,2023)CLIP激活的蒸馏学习:面向开放词汇的航空目标检测技术
文章目录 相关资料摘要引言方法问题描述开放词汇对象探测器架构概述类不可知框回归头语义分类器头 定位教师指数移动平均一致性训练与熵最小化边界框选择策略 动态伪标签队列生成伪标签维护队列 混合训练未标记数据流队列数据流 实验 相关资料 论文:Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Stud
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.10-2024.05.20
文章目录~ 1.Diff-BGM: A Diffusion Model for Video Background Music Generation2.Rethinking Overlooked Aspects in Vision-Language Models3.Unifying 3D Vision-Language Understanding via Promptable Queries4
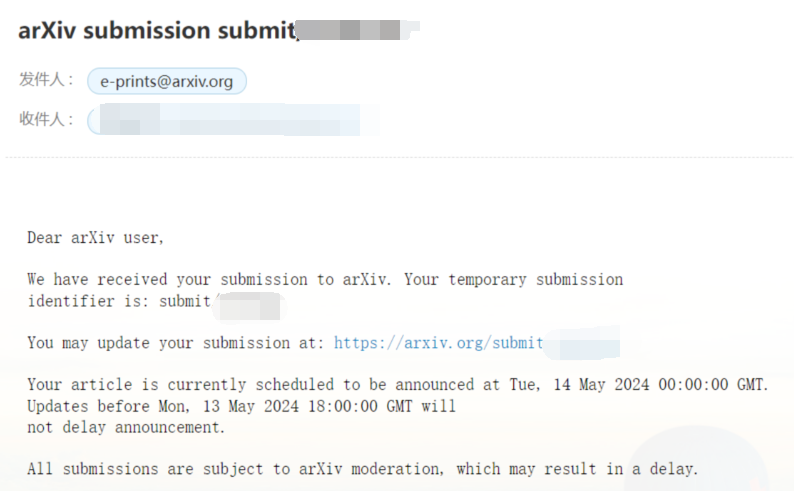
上传论文到arXiv
一、整理提交文件 法一:从Overleaf获取.zip Tips: 注意主文件要放在根目录如果用pdfLatex编译,确保图片全部为.png 或.pdf 右上角Submit,选择 二、提交 登录arXiv官网:https://arxiv.org/,选择START NEW SUBMISSION。 1、Start (1)基础信息 (2)License Statement

今日arXiv最热NLP大模型论文:NAACL24实锤语言学对大模型“负优化”,抽象语义表示+思维链有损表现
大语言模型正以势不可挡的姿态席卷自然语言处理领域。在这个语言模型大显神威的时代,很多任务都转变为了端到端的文本生成任务。那么,在此之前我们苦心孤诣研究了几十年的语义表示,例如 AMR(抽象意义表示),在这个时代里还能派上用场吗? 这篇文章针对这个问题展开了研究,作者们提出了一种基于 AMR 的思维链(chain-of-thought)提示方法 AMRCOT,在5个自然语言处理任务上对比研究了这种
![[深度学习论文笔记][arxiv 1805] Why do deep convolutional networks generalize so poorly to small image transf](https://img-blog.csdn.net/20180825182149494?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNTg2NTk=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[深度学习论文笔记][arxiv 1805] Why do deep convolutional networks generalize so poorly to small image transf
[arxiv 1805] Why do deep convolutional networks generalize so poorly to small image transformations? Aharon Azulay and YairWeiss from Hebrew University of Jerusalem paper link Introduction 深度卷积网络
【5/01-5/02】 Arxiv安全类文章速览
知识星球 首先推荐一下我们的知识星球,以AI与安全结合作为主题,包括AI在安全上的应用和AI本身的安全; 加入星球你将获得: 【Ai4sec】:以数据驱动增强安全水位,涵盖内容包括:恶意软件分析,软件安全,AI安全,数据安全,系统安全,流量分析,防爬,验证码等安全方向。星主目前在某大厂从事安全研究,论文以及专利若干,Csdn博客专家,访问量70w+。分享者均为大厂研究员或博士,如阿里云,蚂蚁
【5/01-5/03】 Arxiv安全类文章速览
知识星球 首先推荐一下我们的知识星球,以AI与安全结合作为主题,包括AI在安全上的应用和AI本身的安全; 加入星球你将获得: 【Ai4sec】:以数据驱动增强安全水位,涵盖内容包括:恶意软件分析,软件安全,AI安全,数据安全,系统安全,流量分析,防爬,验证码等安全方向。星主目前在某大厂从事安全研究,论文以及专利若干,Csdn博客专家,访问量70w+。分享者均为大厂研究员或博士,如阿里云,蚂蚁

今日arXiv最热大模型论文:复旦提出基于diffusion的虚拟试衣模型,模特一键换装
仅需上传模特图像,便可一键换装,极大提高了用户网购衣服的效率。 虚拟试衣(Virtual Try-On)作为图像生成中一个商业价值高、可以直接变现的子任务,研究热度随着图像生成技术的发展水涨船高。 但现有的一些方法生成的效果还差点意思,如下图所示: 基于GAN的方法换装后与模特不贴合,像是简单粗暴P上去的一样。扩散模型的出现使其可以生成逼真的试穿图像,但它们往往在细节上还原度不高,比如衣

今日arXiv最热NLP大模型论文:浙江大学:蒸一蒸,多Agent变成单一模型,效果更好
“团结就是力量”,面对复杂多变的现实环境,multi-agent应运而生。相较于单打独斗的single-agent,multi-agent集结了多个功能各异的LLM,共同攻克难关。然而,这种协同作战的方式也带来了沉重的推理负担,限制了multi-agent在开放世界中的发展潜力。 特别是在多模态环境下,视觉、音频、文本交织在一起,如何动态调整多模态语言模型(MLMs),以适应视觉世界的纷繁复杂,

今日arXiv最热NLP大模型论文:微软发布可视思维链VoT,提高大模型空间想象力
此项研究提出了一种名为思维可视化(VoT)的技术,旨在通过可视化大型语言模型(LLMs)的推理过程来增强其空间推理能力。实验结果显示,VoT在多跳空间推理任务(如自然语言导航、视觉导航和二维网格世界的视觉切分)中显著提高了LLMs的表现,并超越了现有的多模型大型语言模型。其生成“心理影像”以利于空间推理的能力类似于人类的“心眼”过程,表明VoT在多模大型语言模型中具有潜在可行性。 分享几个网站

今日arXiv最热NLP大模型论文:面向不确定性感知的Language Agent
引言:面向不确定性的感知的Language Agent Language Agent利用大型语言模型(如OpenAI发布的GPT系列、Meta的LLaMA2等)来与外部世界互动,例如通过工具和API收集观察结果,并处理这些信息以解决任务。这些Language Agent在改进先前具有挑战性的推理任务方面取得了显著进展,它们能够自主地从世界中获取新知识,并通过记忆或自我完善机制迭代地改进其推理路径
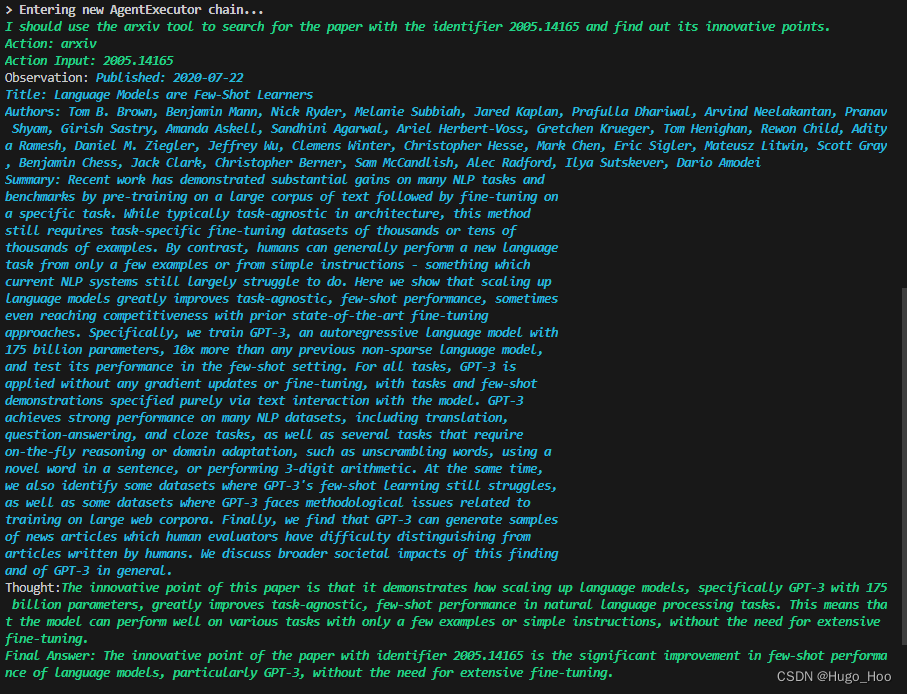
LangChain入门:22.使用 arXiv 工具开发科研助理
有一些工具,比如 SerpAPI,你已经用过了,这里我们再来用一下 arXiv 工具。arXiv 本身就是一个论文研究的利器,里面的论文数量比 AI 顶会还早、还多、还全。那么把它以工具的形式集成到 LangChain 中,能让你在研究学术最新进展时如虎添翼。 arXiv 是一个提供免费访问的预印本库,供研究者在正式出版前上传和分享其研究工作。它成立于 1991 年,最初是作为物理学预印本数据
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.10-2024.04.15
文章目录~ 1.Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models2.Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection3.UNIAA:
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.05-2024.04.10
文章目录~ 1.BRAVE: Broadening the visual encoding of vision-language models2.ORacle: Large Vision-Language Models for Knowledge-Guided Holistic OR Domain Modeling3.MedRG: Medical Report Grounding with
预印本仓库ArXiv——防止论文录用前被别人剽窃
文章目录 一、什么是预印本二、什么是ArXiv2.1 ArXiv的领域2.2 如何使用 一、什么是预印本 预印本(Preprint)是指科研工作者的研究成果还未在正式出版物上发表,而出于和同行交流目的自愿先在学术会议上或通过互联网发布的科研论文、科技报告等文章。 与已经在刊物上发表的文章对比,预印本具有交流速度快、利于学术争鸣、可靠性高的特点。好的期刊录用周期长,等论文发表可
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.04.05-2024.04.10
文章目录~ 1.Learn from Failure: Fine-Tuning LLMs with Trial-and-Error Data for Intuitionistic Propositional Logic Proving2.Continuous Language Model Interpolation for Dynamic and Controllable Text Gene