本文主要是介绍今日arXiv最热NLP大模型论文:微软发布可视思维链VoT,提高大模型空间想象力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
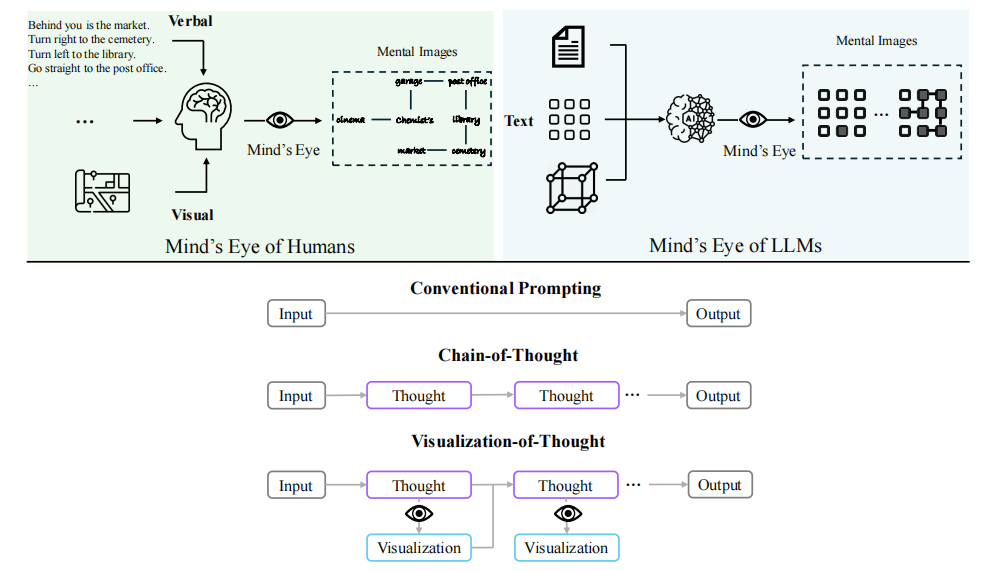
此项研究提出了一种名为思维可视化(VoT)的技术,旨在通过可视化大型语言模型(LLMs)的推理过程来增强其空间推理能力。实验结果显示,VoT在多跳空间推理任务(如自然语言导航、视觉导航和二维网格世界的视觉切分)中显著提高了LLMs的表现,并超越了现有的多模型大型语言模型。其生成“心理影像”以利于空间推理的能力类似于人类的“心眼”过程,表明VoT在多模大型语言模型中具有潜在可行性。
分享几个网站
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
论文标题:
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
论文链接:
https://arxiv.org/pdf/2404.03622.pdf
VoT提示方法
1. VoT方法的提出背景
Visualization-of-Thought(VoT)提示方法的提出是为了激发LLMs的空间推理能力,通过可视化它们的推理过程,从而指导后续的推理步骤。VoT旨在为LLMs提供一种视觉空间草稿本(visuospatial sketchpad),以可视化它们的推理步骤并通知后续步骤。VoT采用零样本提示(zero-shot prompting),而不是依赖少数样本演示或与CLIP的文本到图像可视化。这一选择源于LLMs能够从基于文本的视觉艺术中获取各种心理图像的能力。
2. VoT方法的具体实现
VoT提示方法的实现包括在每个推理步骤后生成推理痕迹和视觉化的交错过程。研究者使用pθ表示具有参数θ的预训练语言模型,x、y、z表示语言序列,v表示文本形式的视觉序列。在一个多跳空间推理任务中,输入x,CoT提示生成一系列中间步骤z1, ···, zn,每个步骤按顺序采样,然后输出。
这种推理范式使LLMs具备了视觉状态跟踪的能力。研究者引入了状态的概念,视觉状态跟踪通过在每个推理步骤zi之后生成视觉化vi作为内部状态si的心理图像(例如,vi可以是标记路径的导航地图网格或填充的矩形)。通过视觉状态跟踪序列的基础,后续状态通过计算得出。这种基于视觉状态跟踪的机制允许推导出反映时空因果关系的后续状态,并在有根据的上下文中增强LLMs的空间推理能力。
实验设计:任务选择与数据集构建
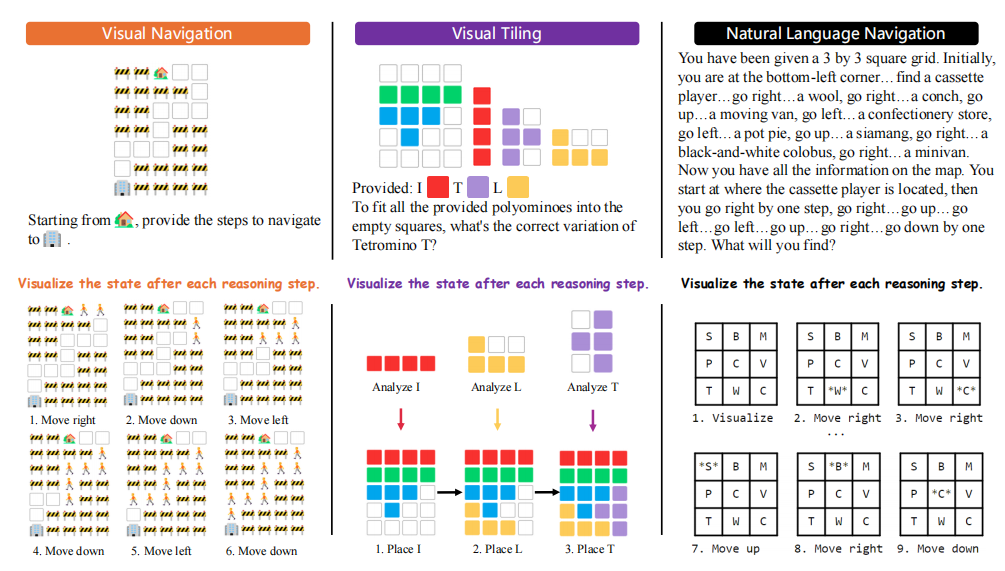
1. 自然语言导航任务
自然语言导航任务涉及通过随机漫步在一个基础空间结构中导航,并识别之前访问过的位置。这个任务要求模型能够理解闭环,这对于空间导航至关重要。在这个任务中,一个方形地图由一系列随机漫步指令和对应的对象定义,模型的任务是在导航指令的指引下识别出正确的对象。
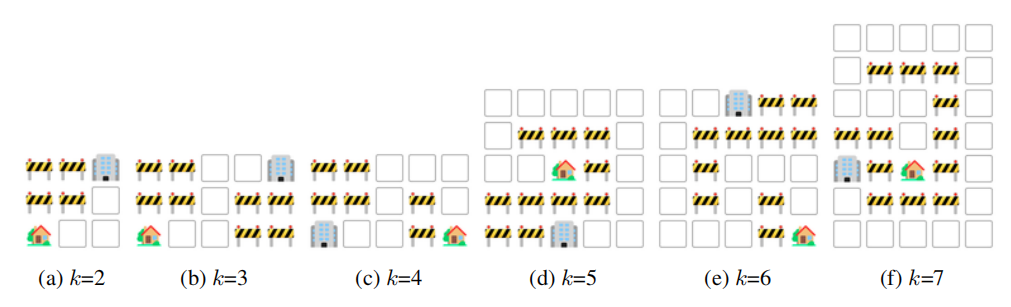
2. 视觉导航任务
视觉导航任务向LLM展示了一个合成的2D网格世界,挑战模型使用视觉线索进行导航。模型必须生成导航指令,以四个方向(左、右、上、下)移动,从起点到达目的地,同时避开障碍物。这涉及到两个子任务:路线规划和下一步预测,都需要多跳空间推理,其中前者更为复杂。
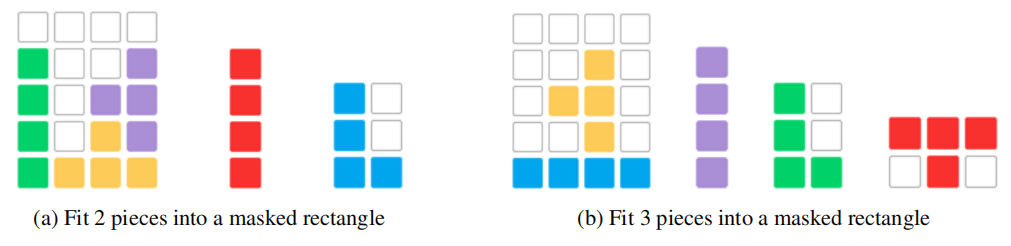
3. 视觉拼图任务
视觉拼图任务是一个经典的空间推理挑战,研究者将其扩展以测试LLM理解、组织和推理形状的能力。任务涉及一个矩形区域,其中有未填充的单元格和各种多米诺骨牌形状的碎片。模型必须选择适当的多米诺骨牌变体,例如为I形多米诺骨牌选择方向,以解决问答谜题。
实验结果:VoT提示的有效性
1. VoT与其他方法的比较
在所有任务中,VoT提示的GPT-4模型在所有指标上显著优于其他设置。特别是在自然语言导航任务中,GPT-4 VoT比GPT-4 w/o Viz(没有可视化提示的GPT-4)提高了27%。在视觉任务中,GPT-4 CoT与GPT-4V CoT(带有对应图像输入的GPT-4 Vision)之间的显著性能差距表明,带有2D网格输入的LLM可能在具有挑战性的空间推理任务中胜过多模态大语言模型(MLLMs)。
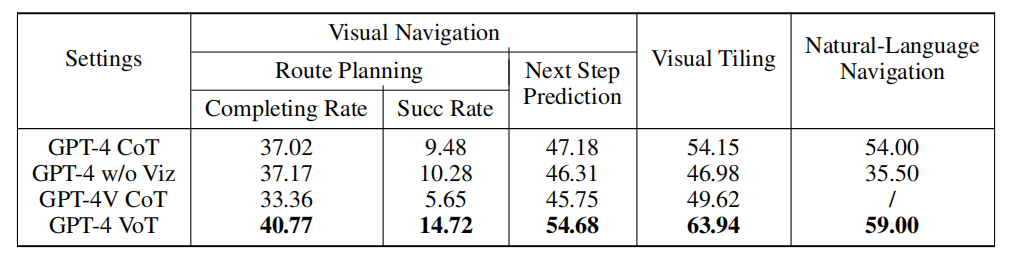
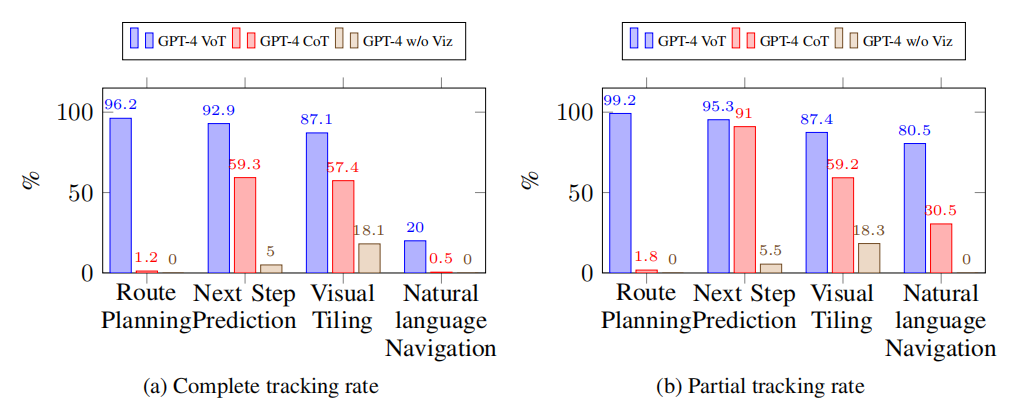
2. VoT在不同任务中的表现
尽管VoT在所有任务中的表现都远未完美,特别是在最具挑战性的路线规划任务中,但它在自然语言导航、视觉导航和视觉拼图任务中的表现证明了其有效性。随着任务复杂性的增加,LLMs的性能显著下降,但即便如此,VoT提示仍然能够显著提高LLMs在这些任务上的表现。
3. 文本到视频生成的竞争性能
通过统一的生成预训练,Video-LaVIT能够灵活地生成视频和图像。在文本到视频生成结果中,该模型在MSR-VTT和UCF-101上的表现显著优于大多数使用类似公共数据集训练的基线,并且与在更大专有数据上训练的模型高度竞争,例如在MSR-VTT上领先FVD。特别是与基于语言模型的文本到视频生成器相比,该方法一致超过CogVideo,同时超过了最近的同期工作VideoPoet,后者使用了更大的数据训练的3D视频分词器。这清楚地验证了分词器设计的优越性。
VoT的观察现象与潜在原因
1. VoT的视觉状态追踪能力
Visualization-of-Thought (VoT) 提出的目的是为了在空间推理任务中模拟人类的“心智之眼”,即通过内部视觉化来增强空间意识和决策。VoT通过提示(prompting)的方式,引导大语言模型(LLMs)在每个推理步骤中生成视觉状态的追踪,从而支持后续的推理步骤。这种方法在自然语言导航、视觉导航和视觉平铺等多跳空间推理任务中表现出了显著的效果,VoT提示的LLMs在这些任务上的表现超过了现有的多模态大语言模型(MLLMs)。
VoT的视觉状态追踪能力体现在其能够生成内部状态的视觉化表示,并利用这些表示来指导后续的推理步骤。例如,在视觉导航任务中,LLMs需要生成导航指令来避开障碍物并到达目的地,VoT使得模型能够在每个推理步骤后生成一个内部状态的视觉化网格图,从而更好地规划路线和预测下一步。
2. VoT的局限性与挑战
尽管VoT在增强LLMs的空间推理能力方面取得了进展,但其也存在局限性和挑战。在实验中观察到,VoT在某些情况下未能展示视觉状态追踪,而在特定任务中,如路线规划任务,GPT-4 CoT(Chain-of-Thought)偶尔会展示出类似的推理模式,但这种情况并不常见。此外,模型输出中常常观察到错误的视觉化表示。
VoT的局限性可能源于LLMs对空间信息的处理能力仍有待提高。例如,在最具挑战性的路线规划任务中,LLMs的表现仍远非完美,尤其是当任务复杂性增加时,LLMs的表现显著下降。此外,LLMs在视觉状态追踪行为上对提示非常敏感,例如,当从VoT提示中移除“推理”一词时,模型在生成错误答案后才进行视觉化采样,这导致追踪率和任务性能下降。
结论与展望
尽管VoT在LLMs中展现出了令人印象深刻的效果,但其在所有任务中的表现仍有提升空间,尤其是在最具挑战性的路线规划任务中。此外,VoT提示可能在那些不需要可视化内部状态即可利用逻辑推理解决的任务中表现不佳。因此,未来的研究将探索如何进一步激发MLLMs中的“心灵之眼”以增强其空间意识,同时寻找从现实世界场景中自动数据增强的有效方法,以学习心理图像的泛化内部表示。
此外,还应探索更多样化和复杂的表示形式,如复杂的几何形状甚至是3D语义,以加强LLMs的“心灵之眼”。这些努力最终将有助于提升LLMs的认知和推理能力,为理解和生成人类级别的空间推理提供新的可能性。

这篇关于今日arXiv最热NLP大模型论文:微软发布可视思维链VoT,提高大模型空间想象力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







