本文主要是介绍Build a Large Language Model (From Scratch) 从头开始构建大型语言模型(第三章)学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
构建大型语言模型(从头开始)
- 3 编码注意力机制(Coding Attention Mechanisms)
- 3.1 长序列建模问题(The problem with modeling long sequences)
3 编码注意力机制(Coding Attention Mechanisms)
本章涵盖
- 探索神经网络中使用注意力机制的原因
- 引入基本的自注意力框架并逐步发展为增强的自注意力机制
- 实现因果注意力模块,允许LLMs一次生成一个token
- 用 dropout 掩盖随机选择的注意力权重以减少过度拟合
- 将多个因果注意力模块堆叠成多头注意力模块
在上一章中,您学习了如何准备用于训练LLM的输入文本。这涉及到将文本分割成单独的单词和子词tokens,这些tokens可以被编码成向量表示,即所谓的嵌入,用于LLM。
在本章中,我们将研究 LLM 架构本身的一个组成部分,即注意力机制,如图 3.1 所示。
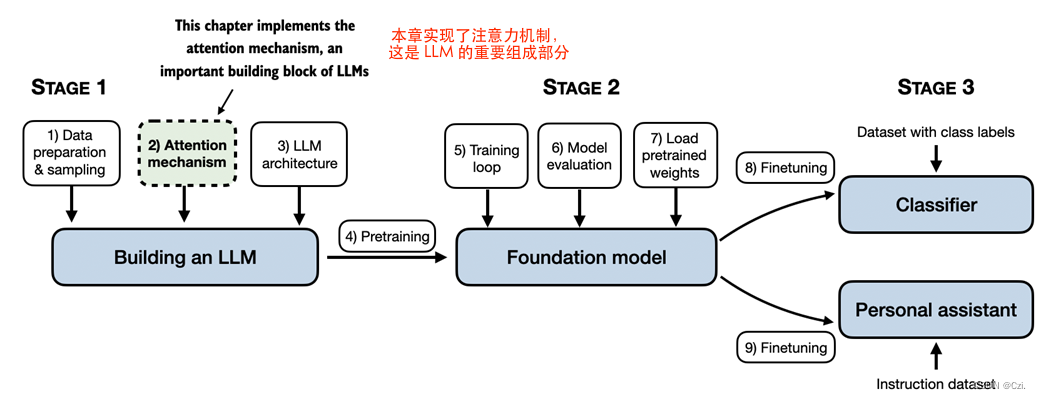
图 3.1 编码 LLM、在一般文本数据集上预训练 LLM 以及在labeled dataset上对其进行微调的三个主要阶段的mental model 。本章重点介绍注意力机制,它是 LLM 架构的一个组成部分。
注意力机制是一个综合性的主题,这就是我们用整整一章来讨论它的原因。我们将主要孤立地看待这些注意力机制,并在机械层面上关注它们。在下一章中,我们将围绕自注意力机制对 LLM 的其余部分进行编码,以查看它的实际效果并创建一个模型来生成文本。
在本章中,我们将实现注意力机制的四种不同变体,如图 3.2 所示。

图3.2中所示的这些不同的注意力变体是相互依赖的,我们的目标是在本章结束时得到一个简洁而有效的多头注意力实现,然后我们可以将其插入到下一章我们将要编写的 LLM 架构中。
3.1 长序列建模问题(The problem with modeling long sequences)
在我们深入探讨本章后面的 LLM 核心的自注意力机制之前,先了解一下 LLM 之前没有注意力机制的架构有什么问题?假设我们想要开发一种语言翻译模型,将文本从一种语言翻译成另一种语言。如图 3.3 所示,由于源语言和目标语言的语法结构,我们不能简单地逐字翻译文本。

图 3.3 将文本从一种语言翻译成另一种语言(例如德语翻译成英语)时,不可能仅仅逐字翻译。相反,翻译过程需要上下文理解和语法对齐。
为了解决我们无法逐字翻译文本的问题,通常使用具有两个子模块的深度神经网络,即所谓的编码器和解码器。编码器的工作是首先读入并处理整个文本,然后解码器生成翻译后的文本。
当我们在第 1 章(第 1.4 节,将 LLM 用于不同任务)中介绍 Transformer 架构时,我们已经简要讨论了编码器-解码器网络。在 Transformer 出现之前,循环神经网络(RNN) 是最流行的语言翻译编码器-解码器架构。
RNN 是一种神经网络,其中先前步骤的输出被作为当前步骤的输入,这使得它们非常适合文本等序列数据。如果您不熟悉 RNN,请不要担心,您不需要了解 RNN 的详细工作原理即可跟随本讨论;我们这里的重点更多是编码器-解码器设置的一般概念。
在编码器-解码器 RNN 中,输入文本被送入编码器,编码器按顺序对其进行处理。编码器在每一步都会更新其隐藏状态( 隐藏层的内部值),试图在最终隐藏状态中捕获输入句子的完整含义,如图 3.4 所示。然后,解码器采用最终的隐藏状态开始生成翻译的句子,一次一个单词。它还在每一步更新其隐藏状态,该隐藏状态应该携带下一个单词预测所需的上下文。
这篇关于Build a Large Language Model (From Scratch) 从头开始构建大型语言模型(第三章)学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







