本文主要是介绍Python数据分析大作业(ARIMA 自回归积分滑动平均模型) 4000+字 图文分析文档 销售价格库存分析+完整python代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
资源地址:Python数据分析大作业 4000+字 图文分析文档 销售分析 +完整python代码
完整代码分析

同时销售量后1000的sku品类占比中(不畅销产品)如上,精品类产品占比第一,达到66.7%,其次是香化类产品,占比11.90%,远远小于精品类产品,酒水类产品占比7.3%,有税商品免税其他商品和电子类产品分别占比6.40%、6.40%、1.3%,
将数据按照毛利进行排序,毛利前1000和后1000的sku品类占比如下,

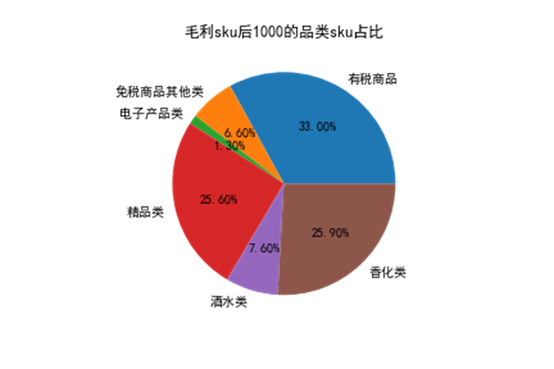
可以发现按照毛利排序,各品类的sku数量占比区别不如按照销量排序的各品类sku数量占比那么大,其中按照毛利排序的sku前1000,品类sku占比最大的是香化类,其次是精品类,它们占比分别达到33.2%和31.5%,其中占比最小的是免税商品其他类,说明该品类的毛利率相对较小,而毛利率较大的为精品类和香化类,这和品牌有一定关系,人民生活正在慢慢变好,精品类商品能满足大部分人民的精致生活,同时香化类产品受众多为女性,商品需求大,毛利也高。对于毛利sku后1000的商品,其中有税商品和精品类和香化类商品仍然占领霸主位置,原因可能由于对于精品类和香化类的部分商品经常打折来吸引顾客,所以这部分商品的毛利较低,sku后1000商品品类占比最大的为有税商品,占比达到33.00%,由于考虑到税额加上顾客的消费能力,这部分的商品毛利相对低一点,同时香化类和精品类占比也达到25.9%和25.6%,占比最小的为电子产品,占比为1.3%。
分析sku销量前1000和销量后1000商品的毛利率,得到毛利率的条形图如下,
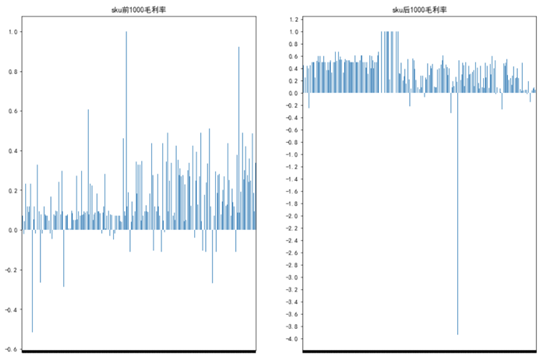
从上图可以发现sku前1000商品的毛利率大概在0.2到0.5左右,而sku后1000的商品的毛利率大部分在0.4到0.5左右,可以认为销量高的商品其毛利率未必会比销量低的商品的毛利率高,这给我们销售商品很有启示,对于商品售卖我们未必要一定去打折扣吸引顾客(当然折扣对部分顾客有一定吸引力),对于畅销品我们就没必要去打折,因为商品本身可能就供不应求,这样通过畅销品的提高整个商场的利润,对于不畅销商品,我们也不一定要去打折,对于不畅销商品,可能其受众较小,而对于那部分受众来说,这对于其他人最不畅销的商品对于他们来说可能是必需品,所以也没必要打折,通过保证毛利,也能提高商场的利润。
价格分析
首先将各品类下的大类进行区间划分,拟定划分6个区间,然后计算每个品类下每个大类的每个价格区间的个数,各品类商品的大类价格区间条形图如下,


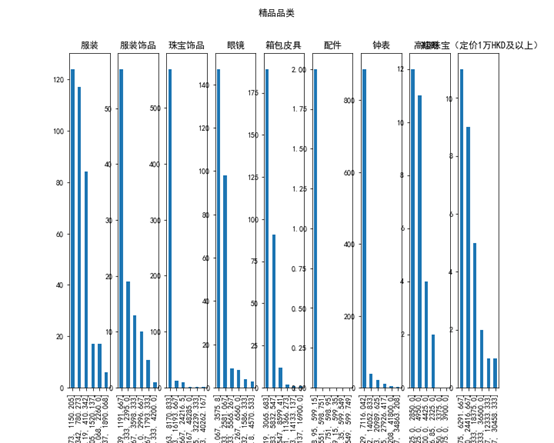

上面4个品类,精品品类、免税其他品类、香化品类、有税品类的价格区间如图,取免税其他品类进行分析说明,首先免税其他品类下面有六个大类,对这六个大类进行区间划分,划分6个价格区间,其中条形图的高度为对应区间的个数,对于所有的大类,其位于低价位的价格区间个数是最多的,说明大多数人的消费能力有限,会偏向于低价位的商品,对于精品品类,其类下的高级珠宝在各个价格区间中价格区间个数相对其他大类会更多一点,说明高级珠宝受价格的影响相对较小,因为高级珠宝的受众基本是固定的,这些顾客不管价格高或者低都是能够消费的起,所以价格对他们影响不大。对于香化类,价格区间个数很大一部分都在最低价格区间内,随着化妆品行业兴起,很多爱美的顾客都选择购买化妆品,但大多数人的消费能力有限,所以低价格的化妆品成为了畅销产品,而且低价格的化妆品价格区间个数远远高于高价格的价格区间个数。对于酒水和电子品类,其对应的大类只有一个,如下所示,对于这两个品类,可以发现酒水品类的低价位远远比其他价位的多,说明便宜酒水的受众很多,而昂贵酒水受众较少,所以对于低价位酒水可以通过促销来促进购买,对于高价位酒水则可以定高价保证利润。对于电子产品,其中等价位及以下的销售区间个数比较多,相当于珠宝酒水来说,人民更愿意在电子产品上花钱,这也是科技给人们带来的便捷之处,但高价位的电子产品的区间个数仍是较少,和人们的消费习惯和消费能力有关。
接着查看各品类下的各大类的畅销产品价格区间的折扣率,这里在每一个品类中选取一个大类的价格区间折扣进行分析,对于有税品类下的个人洗护大类,其价格区间的折扣率和最畅销产品和最不畅销产品如下:
(35.877, 56.5] 0.6818181818181818
(56.5, 77.0] 0.640625
(77.0, 97.5] 1.0
(97.5, 118.0] 0.8571428571428571
(118.0, 138.5] 0.0
(138.5, 159.0] 0.5
最畅销产品价格区间(56.5, 77.0]
最不畅销产品价格区间(118.0, 138.5]
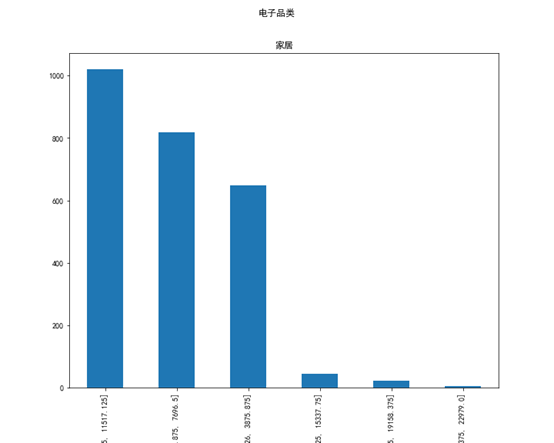
从上面可以发现最畅销产品价格区间位于低价区间,但其折扣率为0.6,算是较高了,而最不畅销的价格区间,其折扣率为0,结合前面的分析,对于低价产品,我们可以减小我们的折扣率来提高利润。对于不畅销的产品我们可以进行适当的折扣来促进购买,对于电子品类下的家居大类,其价格区间的折扣率和最畅销产品和最不畅销产品如下:
(32.326, 3875.875] 0.9583333333333334
(3875.875, 7696.5] 0.978021978021978
(7696.5, 11517.125] 0.9745347698334965
(11517.125, 15337.75] 1.0
(15337.75, 19158.375] 1.0
(19158.375, 22979.0] 1.0
最畅销价格区间(7696.5, 11517.125]
最不畅销价格区间(19158.375, 22979.0]
和有税品类不同的是,最不畅销产品价格区间为最贵的价格区间,而且最不畅销的产品价格区间达到了百分百,而最畅销产品的价格区间位于中等价位价格区间,折扣率也比较高。说明对于电子产品这一类相当难以进行修补的产品来说,人们更倾向于贵一点的,可能这和人们的消费理念和消费能力有关, 一般来说电子产品作为非易换品,人们更倾向于买好一点,用久一点,所以出现最畅销的反而不是价格最低的。对于精品品类下的服装大类,其价格区间的折扣率和最畅销产品和最不畅销产品如下:
(38.19, 410.342] 0.08333333333333333
(410.342, 780.273] 0.09401709401709402
(780.273, 1150.205] 0.016129032258064516
(1150.205, 1520.137] 0.058823529411764705
(1520.137, 1890.068] 0.3333333333333333
(1890.068, 2260.0] 0.11764705882352941
最畅销产品价格区间(780.273, 1150.205]
最不畅销产品价格区间(1520.137, 1890.068]
同上面一样,最畅销产品价格区间位于非位于最低价价格区间,而最不畅销的产品价格区间位于中间价位价格区间,因为对于服装类来说,每一个人都有需求,而对于消费能力不够的消费者来说,他们大多会选择网购而不会选择去商城购物,而大多数人选择去商城购买衣服的都是具有一定的消费能力,但他们消费能力也是有限,所以最畅销的价格区间是中等价位偏下,而中等价位偏上的价格区间对于消费能力不足的消费者来说性价比不高,而对于消费能力足够的消费者来说又不上档次,所以这个价位处于一个比较尴尬的位置。对于这个区间的产品可以稍微的促销提高销量。
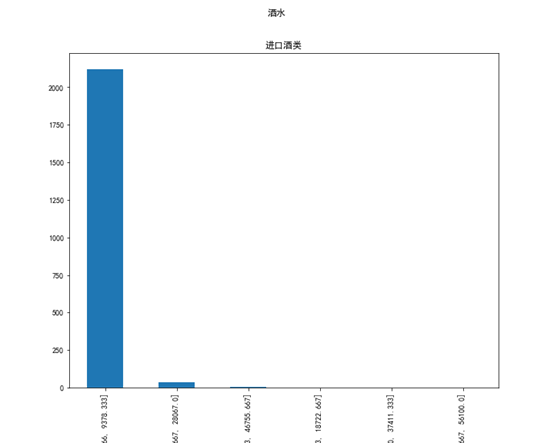
对于酒水品类下的进口酒水大类,其价格区间的折扣率和最畅销产品和最不畅销产品如下:
(6.66, 9378.333] 0.27345591702027344
(9378.333, 18722.667] 1.0
(18722.667, 28067.0] 0.05555555555555555
(28067.0, 37411.333] 0.0
(37411.333, 46755.667] 0.0
(46755.667, 56100.0] 0.0
最畅销价格区间(6.66, 9378.333]
最不畅销价格区间(9378.333, 18722.667]
和上面品类不一样的是,最畅销的产品位于最低价价格区间,由于低价酒类的受众较多,而10000元以下的酒对于普通消费人群来说也不便宜,所以这个价位最畅销,同时折扣也较低,对于最不畅销的商品,是在第二低价价格区间,折扣率为1,而最高价位的酒折扣率为0反而不是最不畅销的价格区间,因为高价酒的受众较少,同时他们也有能力进行消费,所以不需要进行折扣。而最不畅销的价格区间是不受低端客户和高端客户的喜爱,所以不畅销。
对于香化品类下的个人洗护大类,其价格区间的折扣率和最畅销产品和最不畅销产品如下:
(59.07, 215.0] 0.09813084112149532
(215.0, 370.0] 0.0729483282674772
(370.0, 525.0] 0.10810810810810811
(525.0, 680.0] 0.0425531914893617
(680.0, 835.0] 0.25
(835.0, 990.0] 0.10526315789473684
最畅销产品价格区间(215.0, 370.0]
最不畅销产品价格区间(680.0, 835.0]
同上面一个,畅销产品为虽为低价产品,但其并未是最低价产品,该产品折扣率低,同时不畅销产品为高价产品,但也并非是最高价区间产品,折扣率也低。说明价格并不是决定畅销和不畅销的唯一因素,对于洗护类产品,由于关乎自身皮肤健康,所以相当中等价位的产品比较畅销,对于免税其他商品的书写工具大类,其价格区间的折扣率和最畅销产品和最不畅销产品如下:
(5.879, 2215.883] 0.24
(2215.883, 4412.707] 0.36363636363636365
(4412.707, 6609.53] 0.0
(6609.53, 8806.353] 0.3333333333333333
(8806.353, 11003.177] 0.0
(11003.177, 13200.0] 0.0
最畅销价格区间(5.879, 2215.883]
最不畅销价格区间 (8806.353, 11003.177]
对于书写工具,由于需求较大,人民对其没有过多要求,能写就行,所以人民会倾向于较低价的产品,所以其最畅销的价格区间为最低价价格区间,而最不畅销的是倒数第二贵的价格区间,同样这个区间基本只有有强大消费能力的人去购买,而这类人往往会挑选最贵的去买,所以其成为最不畅销的产品价格区间。
库存分析
资源地址:Python数据分析大作业 4000+字 图文分析文档 销售分析 +完整python代码
分析各品类下各大类的sku数,以条形图展现,如下

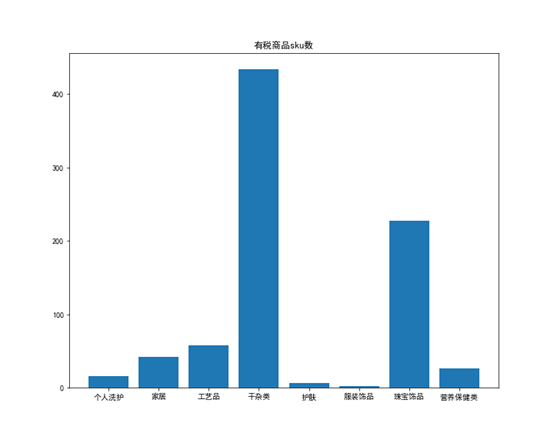
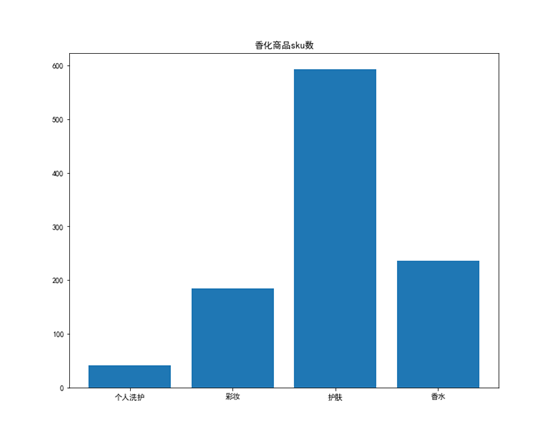
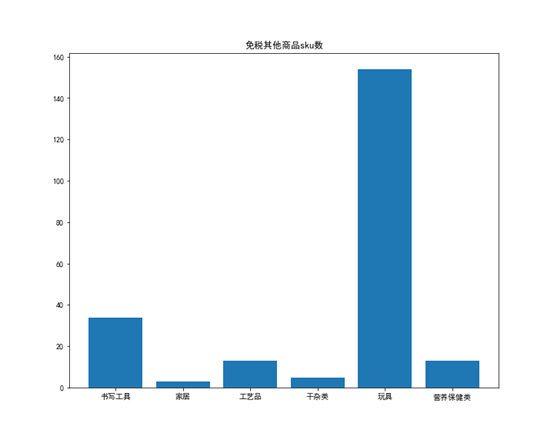

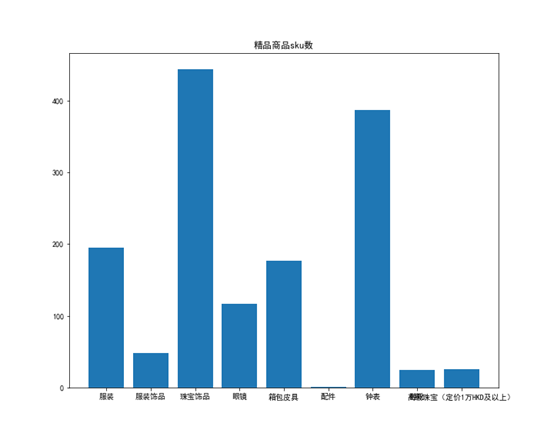
通过分析各大类的sku数可以判断哪些大类商品需要更多的库存,哪些大类商品需要的库存少,对于有税商品中的干杂大类,香化品类中的护肤大类,免税其他品类的玩具大类以及精品品类下的珠宝和钟表大类,他们sku数比较多,可以多放些库存以免缺货。
接着根据28法则,分析各品类下sku金额以及累计金额,结果如下,

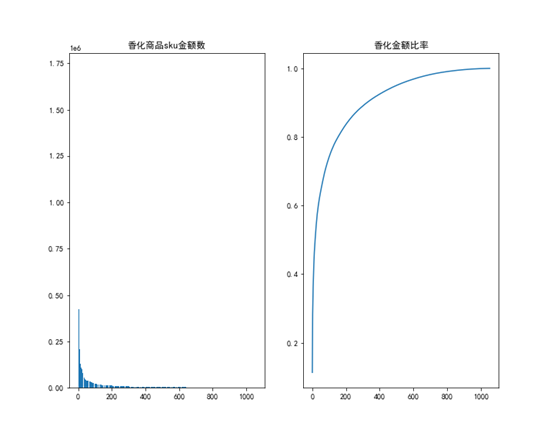
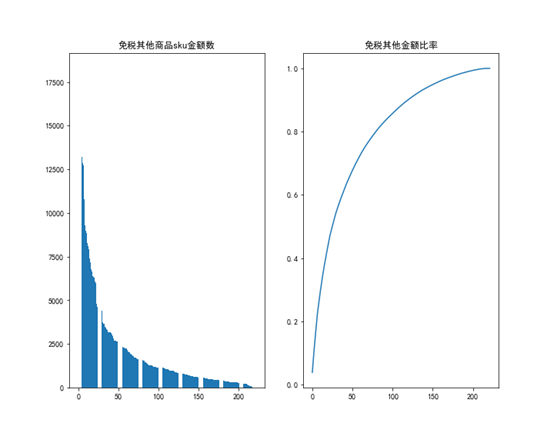


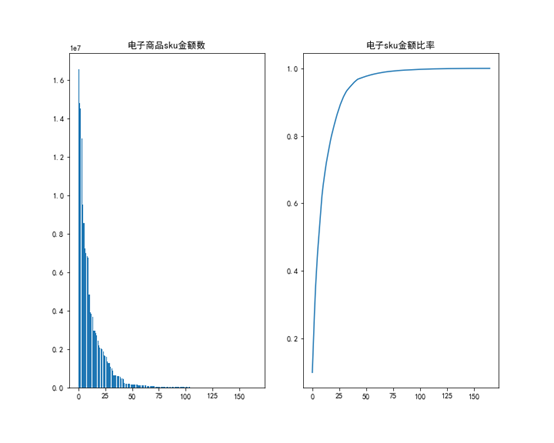
从上面的表中可以发现,免税其他品类和有税品类的前20%的商品金额大概占比总的商品金额的60%,而其他四个品类大概占比了80%,符合28法则。
分析每个品类下的期初期末以及平均库存,结果如下
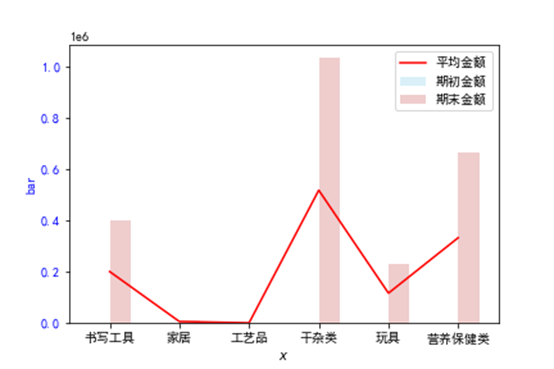
免税其他品类的营养保健类、干杂类库存较多,而期初库存全为0,根据上面的分析,书写工具和玩具的sku数较多,可以加大这两类库存
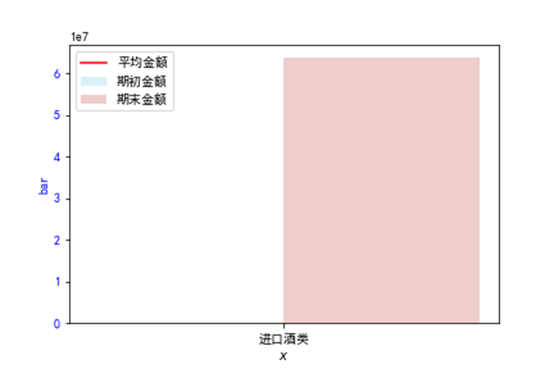
进口酒类期初库存也为0,可以加一些期初库存
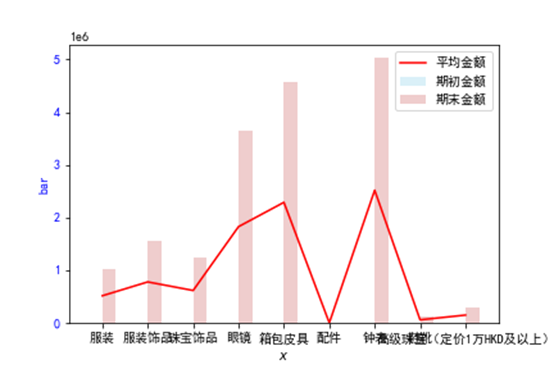
精品品类的珠宝和钟表类的sku数较多,而上方珠宝的库存较少,可以加大该类的品类库存
对于家居品类,可以加一些期初库存。
对于有税商品,干杂类珠宝sku数较多,可以加大珠宝类的库存,根据上图,珠宝类的库存较少,可以加强库存。
对于香化品类,护肤和香水大类的sku数较多,而上图香水库存较少,可以加强该库存。
使用价格区间来分析库存。
通过分析最畅销库存以及最不畅销库存来调配商品。由于品类过多,选取一部分分析,结果如下。
有税品类的个人洗护类:

电子品类:
精品类
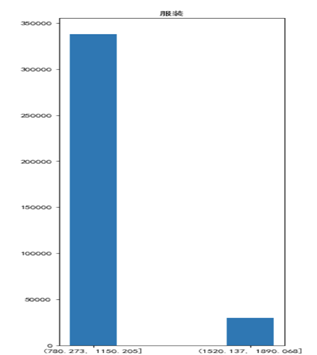
酒水类
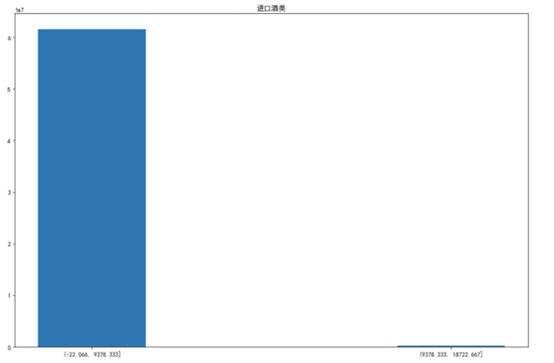
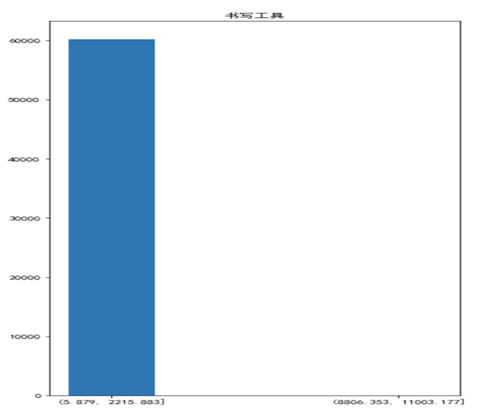
对于这六个品类,除了有税品类下的个人洗护类的不畅销价格区间的库存相对多一点外,其他的最不畅销的价格区间的商品库存都比最畅销的商品库存低许多,说明在不同价格区间的库存来说,库存的配比没有问题,对于精品类,由于其占商品销售很大一部分,所以需要着重的分析,首先需要提高畅销产品的库存,但不一定要减小不畅销产品的库存,因为对于精品类来说,其最不畅销的产品销量可能比其他的类要高,所以可以选择增大畅销产品的库存,同时不动非畅销品的库存。而其他四个看起来正常,他们的库存远远多于最不畅销产品的库存量,在一定程度上认为是合理的。
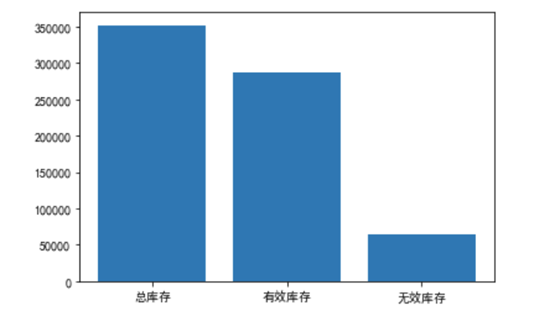
分析有效库存的各品类的库存数
上图为总库存,有效库存,无效库存的条形图,发现有效库存占总库存的绝大多数,接下来分析不同品类下的库存数量,
有税品类的库存如下,有税品类下干杂类sku最多,其库存也最多,库存配比无误
电子类,电子类占销售比例也较大,其库存也算较多,库存配比无误,
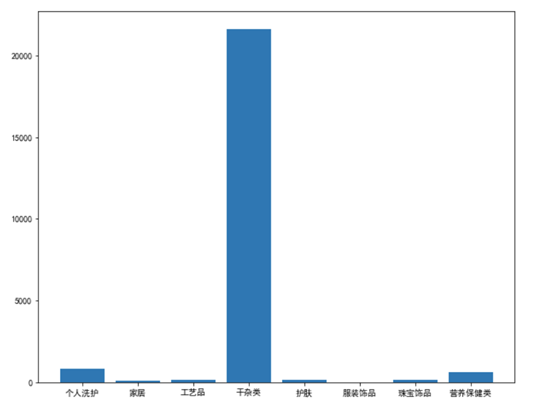
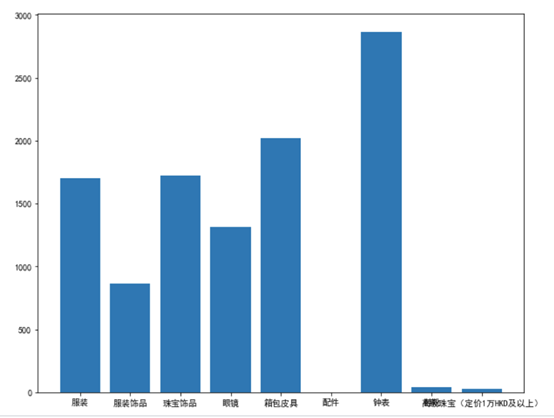
精品类库存图如下,精品类下钟表和珠宝的sku较多,而下面珠宝的库存不多,可以适当提高其库存,相对减少其他库存
资源地址:Python数据分析大作业 4000+字 图文分析文档 销售分析 +完整python代码
这篇关于Python数据分析大作业(ARIMA 自回归积分滑动平均模型) 4000+字 图文分析文档 销售价格库存分析+完整python代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





