本文主要是介绍7.机器学习-十大算法之一拉索回归(Lasso)算法原理讲解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
7.机器学习-十大算法之一拉索回归(Lasso)算法原理讲解
- 一·摘要
- 二·个人简介
- 三·前言
- 四·原理讲解
- 五·算法流程
- 六·代码实现
- 6.1 坐标下降法
- 6.2 最小角回归法
- 七·第三方库实现
- 7.1 scikit-learn实现(坐标下降法):
- 7.2 scikit-learn 实现(最小角回归法):
一·摘要
 拉索回归(Lasso Regression)是一种线性回归的正则化形式,它通过引入L1范数惩罚项来实现模型的稀疏性,从而有助于特征选择。
拉索回归(Lasso Regression)是一种线性回归的正则化形式,它通过引入L1范数惩罚项来实现模型的稀疏性,从而有助于特征选择。
在机器学习和统计学中,当数据集具有许多特征时,可能会遇到特征之间存在多重共线性或者某些特征对预测结果影响不大的情况。标准的线性回归方法可能会导致模型过拟合,并且难以解释。为了解决这个问题,拉索回归被提出。它在最小二乘法的基础上,对系数向量添加了一个L1范数惩罚项,这个惩罚项等于所有回归系数绝对值之和的λ倍(λ为惩罚系数)。这样做的目的是使一些不重要的回归系数收缩至零,从而实现特征的选择。
二·个人简介
🏘️🏘️个人主页:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证,CSDN内容合伙人,阿里云社区专家博主,新星计划导师,在职数据分析师。
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。

| 类型 | 专栏 |
|---|---|
| Python基础 | Python基础入门—详解版 |
| Python进阶 | Python基础入门—模块版 |
| Python高级 | Python网络爬虫从入门到精通🔥🔥🔥 |
| Web全栈开发 | Django基础入门 |
| Web全栈开发 | HTML与CSS基础入门 |
| Web全栈开发 | JavaScript基础入门 |
| Python数据分析 | Python数据分析项目🔥🔥 |
| 机器学习 | 机器学习算法🔥🔥 |
| 人工智能 | 人工智能 |
三·前言
在处理具有大量特征的数据集时,我们常常面临两个主要的挑战:
一是特征之间可能存在多重共线性,这会导致模型参数估计不稳定甚至无法计算;
二是并非所有特征都对预测结果有显著影响,一些无关或冗余的特征可能会干扰模型的预测性能。传统的最小二乘法(Ordinary Least Squares, OLS)回归在这样的高维数据上往往会得到过拟合的模型,即模型在训练集上表现良好但在新数据上泛化能力弱。
为了解决这些问题,统计学家和发展机器学习算法的研究人员提出了一系列的正则化技术,其中拉索回归(Lasso Regression)就是一种被广泛应用的方法。拉索回归通过在回归模型中加入一个调节复杂度的惩罚项来克服上述问题。这个惩罚项是模型系数绝对值之和的λ倍,也就是所谓的L1范数,其中λ是一个非负的调节参数。
引入L1范数作为惩罚项有几个关键的优势:
稀疏性:L1范数有助于模型产生稀疏解,即推动某些系数减小至零。这一性质特别有用,因为它不仅降低了模型的复杂性,还实现了特征选择的目的,即自动地识别出对响应变量有重要影响的变量。
可解释性:通过减少特征的数量,模型变得更加容易解释。这对于高维数据尤其重要,因为在高维情况下,找出重要的特征并理解每个特征如何影响预测结果是非常关键的。
计算效率:尽管Lasso回归是一个复杂的优化问题,存在多种算法可以高效地求解,如坐标下降法、最小角回归法等。
四·原理讲解


五·算法流程
坐标下降法是一种迭代优化算法,用于求解具有可分离结构的凸优化问题。在机器学习中,它常用于训练大规模线性模型,尤其是当特征数量非常大时。
下面是坐标下降法的详细步骤和原理:
-
初始化权重向量 w w w(例如,全部设为零)。
-
迭代更新权重系数。在每次迭代过程中,我们依次更新每一个权重系数 w m w_m wm,而保持其他权重系数不变。对于第 k k k 次迭代和第 m m m 个权重系数,更新规则如下:
w m ( k ) = u n d e r s e t w m a r g m i n Cost ( w 1 ( k ) , w 2 ( k − 1 ) , … , w m − 1 ( k − 1 ) , w m , w m + 1 ( k − 1 ) , … , w n ( k − 1 ) ) w_{m}^{(k)} = underset{w_m}{\mathrm{argmin}} \; \text{Cost}(w_1^{(k)}, w_2^{(k-1)}, \ldots, w_{m-1}^{(k-1)}, w_m, w_{m+1}^{(k-1)}, \ldots, w_n^{(k-1)}) wm(k)=undersetwmargminCost(w1(k),w2(k−1),…,wm−1(k−1),wm,wm+1(k−1),…,wn(k−1))
其中 Cost ( c d o t ) \text{Cost}(cdot) Cost(cdot) 表示损失函数加上正则化项。
- 判断收敛性与迭代终止。如果所有权重系数的变化非常小,或者达到了预设的最大迭代次数,算法停止迭代。
坐标下降法的优势在于其简单性和易于并行化,因为每次更新一个变量时,不需要计算所有变量的信息。它尤其适合于解决高维问题,因为每次迭代只更新一个变量,计算量相对较小。然而,由于其更新规则的贪心性质,可能不保证全局最优解,特别是当损失函数非凸时。尽管如此,在实际应用中,坐标下降法通常能给出满意的结果。
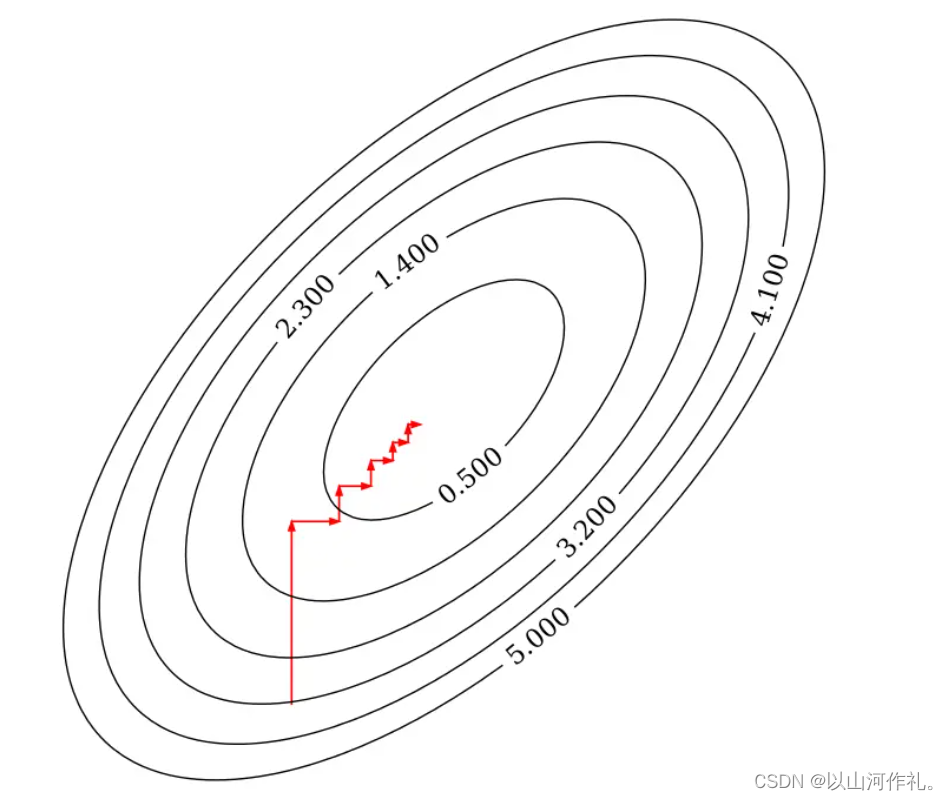
如上图所示,每次迭代固定其他的权重系数,只朝着其中一个坐标轴的方向更新,最后到达最优解。
最小角回归(Least Angle Regression, LARS)是一种用于线性模型的特征选择方法,它通过逐步考虑与当前残差最相关的特征来进行变量选择和系数估计。
下面是最小角回归法的具体步骤和原理:
-
初始化权重系数 w w w(例如全部设为零向量)。
-
计算初始残差向量 r e s i d u a l residual residual,其等于目标标签向量 y y y 减去设计矩阵 X X X 与权重系数 w w w 的乘积。在初始化时, w w w 为零向量,所以残差向量等于目标标签向量 y y y。
-
寻找最相关的特征。选择一个与当前残差向量 r e s i d u a l residual residual 相关性最大的特征向量 x i x_i xi。
-
更新权重系数。沿选定特征向量 x i x_i xi 的方向更新权重系数 w w w,直至出现另一个特征向量 x j x_j xj,使得新的残差向量与 x i x_i xi 和 x j x_j xj 的相关性相等。此时,残差向量位于 x i x_i xi 和 x j x_j xj 的角平分线上。
-
迭代过程。重复上述过程,每次迭代中添加一个新的特征向量,并调整权重系数 w w w,以使残差向量位于新加入的特征和其他所有已选特征的等角线上。
-
终止条件。当残差向量的大小足够小或所有特征都已考虑过后,算法停止。足够小的残差意味着进一步添加特征不会显著改善模型。
最小角回归法的优势在于其能够提供模型选择的整个过程,从一个简单的模型开始,逐步增加特征直到满足某个停止准则。这种方法易于理解,并且计算高效,特别适合于处理高维数据集。
最终,LARS算法会给出一个模型,其中包含了对响应变量有显著影响的特征,以及它们对应的系数估计。这既实现了特征选择的目的,也提供了对应于这些特征的参数估计。
六·代码实现
6.1 坐标下降法
使用 Python 实现Lasso回归算法(坐标下降法):
import numpy as npdef lassoUseCd(X, y, lambdas=0.1, max_iter=1000, tol=1e-4):"""Lasso回归,使用坐标下降法(coordinate descent)args:X - 训练数据集y - 目标标签值lambdas - 惩罚项系数max_iter - 最大迭代次数tol - 变化量容忍值return:w - 权重系数"""# 初始化 w 为零向量w = np.zeros(X.shape[1])for it in range(max_iter):done = True# 遍历所有自变量for i in range(0, len(w)):# 记录上一轮系数weight = w[i]# 求出当前条件下的最佳系数w[i] = down(X, y, w, i, lambdas)# 当其中一个系数变化量未到达其容忍值,继续循环if (np.abs(weight - w[i]) > tol):done = False# 所有系数都变化不大时,结束循环if (done):breakreturn wdef down(X, y, w, index, lambdas=0.1):"""cost(w) = (x1 * w1 + x2 * w2 + ... - y)^2 + ... + λ(|w1| + |w2| + ...)假设 w1 是变量,这时其他的值均为常数,带入上式后,其代价函数是关于 w1 的一元二次函数,可以写成下式:cost(w1) = (a * w1 + b)^2 + ... + λ|w1| + c (a,b,c,λ 均为常数)=> 展开后cost(w1) = aa * w1^2 + 2ab * w1 + λ|w1| + c (aa,ab,c,λ 均为常数)"""# 展开后的二次项的系数之和aa = 0# 展开后的一次项的系数之和ab = 0for i in range(X.shape[0]):# 括号内一次项的系数a = X[i][index]# 括号内常数项的系数b = X[i][:].dot(w) - a * w[index] - y[i]# 可以很容易的得到展开后的二次项的系数为括号内一次项的系数平方的和aa = aa + a * a# 可以很容易的得到展开后的一次项的系数为括号内一次项的系数乘以括号内常数项的和ab = ab + a * b# 由于是一元二次函数,当导数为零时,函数值最小值,只需要关注二次项系数、一次项系数和 λreturn det(aa, ab, lambdas)def det(aa, ab, lambdas=0.1):"""通过代价函数的导数求 w,当 w = 0 时,不可导det(w) = 2aa * w + 2ab + λ = 0 (w > 0)=> w = - (2 * ab + λ) / (2 * aa)det(w) = 2aa * w + 2ab - λ = 0 (w < 0)=> w = - (2 * ab - λ) / (2 * aa)det(w) = NaN (w = 0)=> w = 0"""w = - (2 * ab + lambdas) / (2 * aa)if w < 0:w = - (2 * ab - lambdas) / (2 * aa)if w > 0:w = 0return w
6.2 最小角回归法
使用 Python 实现Lasso回归算法(最小角回归法):
def lassoUseLars(X, y, lambdas=0.1, max_iter=1000):"""Lasso回归,使用最小角回归法(Least Angle Regression)论文:https://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdfargs:X - 训练数据集y - 目标标签值lambdas - 惩罚项系数max_iter - 最大迭代次数return:w - 权重系数"""n, m = X.shape# 已被选择的特征下标active_set = set()# 当前预测向量cur_pred = np.zeros((n,), dtype=np.float32)# 残差向量residual = y - cur_pred# 特征向量与残差向量的点积,即相关性cur_corr = X.T.dot(residual)# 选取相关性最大的下标j = np.argmax(np.abs(cur_corr), 0)# 将下标添加至已被选择的特征下标集合active_set.add(j)# 初始化权重系数w = np.zeros((m,), dtype=np.float32)# 记录上一次的权重系数prev_w = np.zeros((m,), dtype=np.float32)# 记录特征更新方向sign = np.zeros((m,), dtype=np.int32)sign[j] = 1# 平均相关性lambda_hat = None# 记录上一次平均相关性prev_lambda_hat = Nonefor it in range(max_iter):# 计算残差向量residual = y - cur_pred# 特征向量与残差向量的点积cur_corr = X.T.dot(residual)# 当前相关性最大值largest_abs_correlation = np.abs(cur_corr).max()# 计算当前平均相关性lambda_hat = largest_abs_correlation / n# 当平均相关性小于λ时,提前结束迭代# https://github.com/scikit-learn/scikit-learn/blob/2beed55847ee70d363bdbfe14ee4401438fba057/sklearn/linear_model/_least_angle.py#L542if lambda_hat <= lambdas:if (it > 0 and lambda_hat != lambdas):ss = ((prev_lambda_hat - lambdas) / (prev_lambda_hat - lambda_hat))# 重新计算权重系数w[:] = prev_w + ss * (w - prev_w)break# 更新上一次平均相关性prev_lambda_hat = lambda_hat# 当全部特征都被选择,结束迭代if len(active_set) > m:break# 选中的特征向量X_a = X[:, list(active_set)]# 论文中 X_a 的计算公式 - (2.4)X_a *= sign[list(active_set)]# 论文中 G_a 的计算公式 - (2.5)G_a = X_a.T.dot(X_a)G_a_inv = np.linalg.inv(G_a)G_a_inv_red_cols = np.sum(G_a_inv, 1) # 论文中 A_a 的计算公式 - (2.5)A_a = 1 / np.sqrt(np.sum(G_a_inv_red_cols))# 论文中 ω 的计算公式 - (2.6)omega = A_a * G_a_inv_red_cols# 论文中角平分向量的计算公式 - (2.6)equiangular = X_a.dot(omega)# 论文中 a 的计算公式 - (2.11)cos_angle = X.T.dot(equiangular)# 论文中的 γgamma = None# 下一个选择的特征下标next_j = None# 下一个特征的方向next_sign = 0for j in range(m):if j in active_set:continue# 论文中 γ 的计算方法 - (2.13)v0 = (largest_abs_correlation - cur_corr[j]) / (A_a - cos_angle[j]).item()v1 = (largest_abs_correlation + cur_corr[j]) / (A_a + cos_angle[j]).item()if v0 > 0 and (gamma is None or v0 < gamma):gamma = v0next_j = jnext_sign = 1if v1 > 0 and (gamma is None or v1 < gamma):gamma = v1next_j = jnext_sign = -1if gamma is None:# 论文中 γ 的计算方法 - (2.21)gamma = largest_abs_correlation / A_a# 选中的特征向量sa = X_a# 角平分向量sb = equiangular * gamma# 解线性方程(sa * sx = sb)sx = np.linalg.lstsq(sa, sb)# 记录上一次的权重系数prev_w = w.copy()d_hat = np.zeros((m,), dtype=np.int32)for i, j in enumerate(active_set):# 更新当前的权重系数w[j] += sx[0][i] * sign[j]# 论文中 d_hat 的计算方法 - (3.3)d_hat[j] = omega[i] * sign[j]# 论文中 γ_j 的计算方法 - (3.4)gamma_hat = -w / d_hat# 论文中 γ_hat 的计算方法 - (3.5)gamma_hat_min = float("+inf")# 论文中 γ_hat 的下标gamma_hat_min_idx = Nonefor i, j in enumerate(gamma_hat):if j <= 0:continueif gamma_hat_min > j:gamma_hat_min = jgamma_hat_min_idx = iif gamma_hat_min < gamma:# 更新当前预测向量 - (3.6)cur_pred = cur_pred + gamma_hat_min * equiangular# 将下标移除至已被选择的特征下标集合active_set.remove(gamma_hat_min_idx)# 更新特征更新方向集合sign[gamma_hat_min_idx] = 0else:# 更新当前预测向量cur_pred = X.dot(w)# 将下标添加至已被选择的特征下标集合active_set.add(next_j)# 更新特征更新方向集合sign[next_j] = next_signreturn w
七·第三方库实现
7.1 scikit-learn实现(坐标下降法):
from sklearn.linear_model import Lasso# 初始化Lasso回归器,默认使用坐标下降法
reg = Lasso(alpha=0.1, fit_intercept=False)
# 拟合线性模型
reg.fit(X, y)
# 权重系数
w = reg.coef_
7.2 scikit-learn 实现(最小角回归法):
from sklearn.linear_model import LassoLars# 初始化Lasso回归器,使用最小角回归法
reg = LassoLars(alpha=0.1, fit_intercept=False)
# 拟合线性模型
reg.fit(X, y)
# 权重系数
w = reg.coef_
这篇关于7.机器学习-十大算法之一拉索回归(Lasso)算法原理讲解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







