本文主要是介绍新兴存内计算芯片架构、大型语言模型、多位存内计算架构——存内计算架构的性能仿真与对比分析探讨,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CSDN存内社区招募:https://bbs.csdn.net/forums/computinginmemory?
首个存内计算开发者社区,现0门槛新人加入,发文享积分兑超值礼品;
存内计算先锋/大使在社区投稿,可获得双倍积分,以及社区精选流量推送;
精选文章可获得社区奖金激励800,可获得线下训练营的免费名额以及存内主题活动大咖交流机会;
一.大型语言模型(LLM)
近年来,基于注意力机制的大型语言模型(LLM)已经取得了令人瞩目的成功。这些模型的尺寸在不断增长,每两年增长240倍,而相应的计算需求则增长了近750倍。然而,硬件的发展速度已经接近物理极限,进入了技术发展的瓶颈期。传统的超大规模和超大面积的单芯片系统级芯片(SoC)方案面临着诸多问题,包括利用率低、良率低、验证复杂度高、设计成本激增等。
为了应对这些挑战,近年来,研究人员开始将目光投向集成芯粒(Chiplet)技术。集成芯粒技术最早由UCSB大学的谢源教授在2017年国际计算机辅助设计会议(ICCAD)上提出。与传统的单芯片SoC方案不同,集成芯粒方案通过将多个小颗粒芯片独立设计和实现,然后通过先进封装技术重新组装,从而完成系统上的功能集成。
近年来,美国Intel公司、AMD公司、英伟达公司等巨头已经开始广泛采用集成芯粒方案。这些方案将高性能计算核心设计为模块化芯片,通过2.5D/3D封装技术、高速片间互联技术和有源基板技术将计算核心芯片模块集成。这一趋势为硬件设计提供了更为灵活和高效的解决方案,以适应不断增长的大型模型算力需求。
1.1大型模型(LLAMa2-7B)
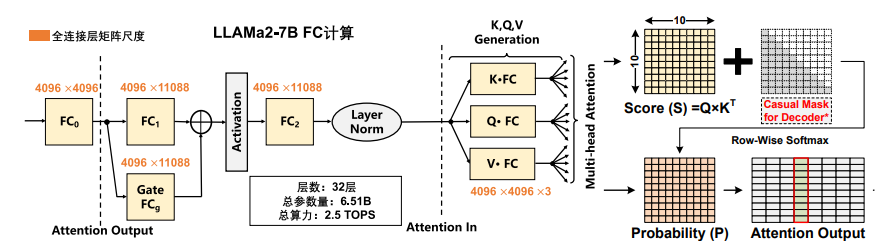
下图展示了一个拥有70亿参数的大型模型(LLAMa2-7B),该模型的每一层多头注意力都包括多个连续前馈(FCL)计算。单层参数量达到2.03亿,而32层的参数总量达到65亿,占用整体系数和计算的85%以上,远超过单一互补金属氧化物半导体(CMOS)芯片的片上存储空间。注意力模块的计算存储要求相对较低,CPU/中等性能网络处理器(NPU)即可完成。
在大型模型推理中,如果要满足每秒1万个令牌的实时要求,即令牌速率为10,000个/秒,对GPU的带宽需求将达到64 Tbit/s,而当前的HBM3带宽仅为0.8 Tbit/s。因此,对于十亿级以上规模的大型模型网络应用场景,现有的GPU/TPU+DRAM分离计算架构难以满足不断增长的模型参数传输带宽需求。
这种情况表明,随着大型模型的不断发展和应用场景的扩大,现有的硬件架构在满足大规模模型计算需求方面面临着巨大的挑战。具体而言,参数量巨大且算力要求高的大模型导致了计算和存储资源高需求的问题,而当前的GPU/TPU+DRAM结构的带宽限制使得数据传输方面的瓶颈日益显现。因此,未来的硬件设计和架构需要不断创新,以适应快速增长的大型模型计算需求,并提供更高效的数据传输和处理解决方案。
二.多位存内计算架构
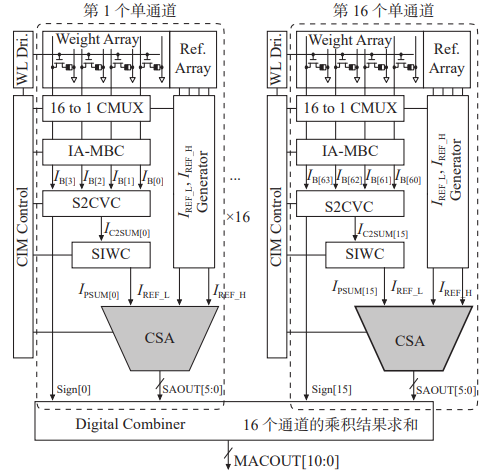
忆阻器阵列在存内计算中扮演着两个主要角色:
1. 存储卷积核的权重信息:
在下图中的"Weight Array"模块中,忆阻器阵列用于存储卷积核的权重信息。每个卷积核的权重被表示为W[3∶0],其中的每一位对应着一个忆阻器。如果某一位的权重为1(W[n]=1),则对应的忆阻器阻值处于低阻态;反之,如果权重为0,则对应的忆阻器阻值处于高阻态。这种设计使得存储卷积核权重的信息可以被编码成忆阻器阵列的阻值状态,从而在计算过程中直接利用忆阻器的阻值状态进行权重计算,而不需要额外的存储单元。
2. 参考阵列:
在下图中的"Ref. Array"模块中,忆阻器阵列充当了产生IREF_L和IREF_H电流的参考阵列(dummy 阵列)。在这个阵列中,所有的忆阻器都被设定为低阻态。这种设计旨在提供用于比较的基准电流,以便在存内计算中进行阈值比较。通过与参考阵列中的忆阻器阻值进行比较,可以确定存储卷积核权重信息的忆阻器阵列中每个忆阻器的阻值状态,从而完成计算过程中的权重计算和阈值比较。
综合来看,忆阻器阵列在存内计算中扮演着存储卷积核权重信息和提供参考电流两个关键角色,这些功能的结合使得存内计算能够更加高效地进行权重计算和阈值比较,从而实现了计算与存储的融合。
2.1 LLM-CSA 原理
LLM-CSA(Large Language Model - Compute Storage Acceleration)是一种用于大型语言模型的计算存储加速器,它结合了计算和存储功能,以提高模型的推理效率和能效。下面是LLM-CSA的基本原理:
-
整合计算和存储:
LLM-CSA将计算和存储功能整合在同一硬件架构中,以便在模型推理过程中同时进行计算和存储操作。传统上,计算和存储通常在不同的硬件单元中进行,而LLM-CSA通过将它们合并到同一硬件单元中,减少了数据传输和延迟,提高了系统整体的效率。 -
忆阻器阵列:
LLM-CSA使用了忆阻器阵列作为存储单元,这种存储单元具有非易失性和可重写性,能够有效地存储大量的模型参数。忆阻器阵列通常由许多忆阻器组成,每个忆阻器都可以存储一个比特的数据。与传统的存储单元相比,忆阻器阵列具有更高的集成度和更低的功耗。 -
计算单元:
LLM-CSA中的计算单元负责执行模型推理过程中的计算操作。计算单元通常由高效的算术逻辑单元(ALU)组成,能够快速地执行矩阵乘法、激活函数等计算操作。与传统的计算单元相比,LLM-CSA中的计算单元通常被设计为与忆阻器阵列紧密集成,以实现快速的数据传输和处理。 -
并行处理:
LLM-CSA通过并行处理来加速模型推理过程。由于计算单元和存储单元在同一硬件单元中集成,它们可以同时进行操作,从而实现更高的并行度。通过有效地利用并行处理的优势,LLM-CSA能够在更短的时间内完成模型推理任务。 -
定制化硬件设计:
LLM-CSA通常采用定制化的硬件设计,以满足大型语言模型推理的特定需求。这种定制化的设计可以根据模型的结构和计算特性进行优化,提高系统的效率和性能。
综上所述,LLM-CSA利用计算存储的融合、忆阻器阵列和定制化硬件设计等技术,实现了对大型语言模型推理过程的高效加速和能效提升。
2.2 基于存内计算架构的性能仿真与对比分析
根据下图的数据显示,存内计算系统的延时从传统CSA的80纳秒降低至LLM-CSA的69.5纳秒,相比传统CSA,延时降低了1.18倍。同时,能量消耗也减少了1.03倍。然而,LLM-CSA单独相对于传统CSA,能耗降低了1.56倍,但是在整个存内计算系统中,LLM-CSA的作用下,系统能耗只降低了1.03倍。这是因为本文的存内计算系统中,每个通道都配备有参考阵列,这些参考阵列的能耗相对较高,导致了LLM-CSA的能耗占比降低,整体能耗下降不太显著。
换句话说,尽管LLM-CSA本身相对于传统CSA能够显著地降低能耗,但由于存内计算系统中其他部分(如参考阵列)的能耗相对较高,LLM-CSA的能耗优势在整体系统中并没有完全体现出来。这一情况表明,在设计存内计算系统时,需要综合考虑各个部分的能耗情况,以实现系统能效的最大化。
基于存内计算架构的性能仿真与对比分析可以通过以下步骤进行:
-
确定性能指标:
首先,确定用于评估性能的指标,例如延迟、能耗、吞吐量等。这些指标可以帮助我们评估不同存内计算架构的性能优劣。 -
建立仿真模型:
建立存内计算架构的仿真模型,包括忆阻器阵列、计算单元、数据传输路径等组成部分。这个仿真模型应该能够模拟存内计算过程中的各种操作,如权重存储、计算操作、数据传输等。 -
选择测试数据集:
选择适当的测试数据集,包括模型参数、输入数据等。这些数据集应该能够充分覆盖不同类型的计算任务和场景,以便进行全面的性能评估。 -
执行仿真实验:
使用建立的仿真模型和测试数据集,执行一系列的仿真实验。这些实验可以涵盖不同的工作负载、数据大小、计算复杂度等方面,以全面评估存内计算架构的性能表现。 -
收集和分析结果:
收集仿真实验的结果数据,并进行分析和对比。对比不同存内计算架构的性能表现,包括延迟、能耗、吞吐量等指标,找出各自的优势和劣势。 -
结论与总结:
根据实验结果,得出对不同存内计算架构性能的评估和对比分析。从中总结出结论,指导后续的存内计算系统设计和优化工作。
在进行性能仿真与对比分析时,需要注意确保仿真模型的准确性和可靠性,以及测试数据集的代表性和多样性,以保证评估结果的客观性和可信度。
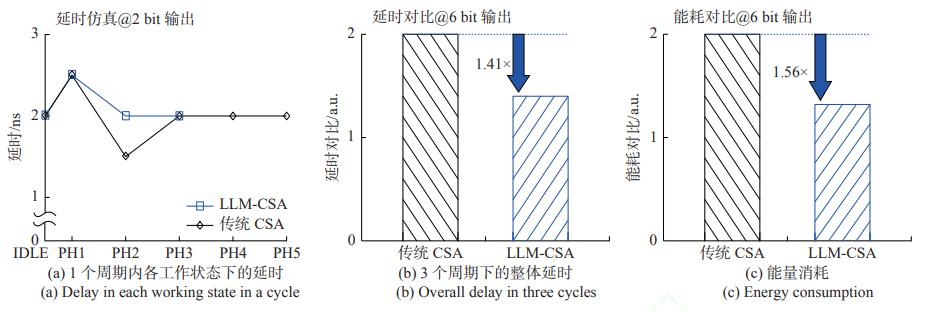
本节介绍了一种低延时低能耗的多位电流型感知放大器(LLM-CSA),并通过基于忆阻器阵列的多位存内计算架构进行了验证。相较于传统的CSA,LLM-CSA电路通过减少每个量化周期的工作状态数量和简化量化时的工作时序,优化了功能。它采用了纯组合电路(低位检测电路)来替代时序逻辑电路(输出解码电路),以多层次地降低输出延时并优化能耗。仿真结果显示,与传统CSA相比,LLM-CSA的延时降低了1.41倍,能量消耗降低了1.56倍。此外,忆阻器阵列多位存内计算电路系统的延时降低了1.18倍,能耗降低了1.03倍。综合分析仿真结果表明,LLM-CSA能够有效提升存内计算的延时性能,并优化能耗。
三.高能效新兴计算的发展现状
高能效新兴计算的发展现状呈现出以下几个主要趋势和特点:
-
存内计算技术的发展:
存内计算技术将计算单元与存储单元集成在一起,减少了数据传输的开销,提高了计算效率。新兴存内计算架构如LLM-CSA等不断涌现,通过优化电路设计和采用新型存储器件,实现了低延时、低能耗的计算,为高能效计算提供了新的解决方案。 -
量子计算的崛起:
量子计算作为一种全新的计算范式,具有在某些特定问题上高效解决的潜力。量子比特的并行计算能力和量子纠缠等特性使得量子计算具有巨大的潜力,能够在未来实现超越经典计算的高效率。 -
神经形态计算的探索:
神经形态计算是一种受生物神经系统启发的新型计算范式,利用神经元模型和突触结构实现大规模并行计算。这种计算方式具有低能耗、高效率的特点,适用于模式识别、图像处理等任务。 -
基于能效硬件的深度学习加速器:
针对深度学习等计算密集型任务,新兴的能效硬件加速器不断涌现。这些加速器结合了专用硬件设计和优化算法,实现了高效的深度学习推理和训练,同时在能耗方面表现出色。 -
能源感知计算:
能源感知计算致力于将计算任务与能源供给进行有效地匹配,以实现能源的节约和优化。通过智能调度、动态功率管理等技术,能源感知计算可以根据系统负载和能源供应情况,调整计算资源的分配和使用,从而提高能效。 -
绿色计算和可再生能源应用:
面对能源危机和环境污染问题,绿色计算成为了当前的热点话题之一。通过利用可再生能源、设计低功耗设备、优化数据中心能源管理等手段,绿色计算致力于降低计算过程中的能源消耗,实现可持续发展。
高能效新兴计算在存内计算技术、量子计算、神经形态计算、能效硬件加速器、能源感知计算、绿色计算等方面都取得了重要进展,为未来计算技术的发展提供了丰富的可能性和前景。
3.1近似计算
近似计算是一种在计算过程中通过牺牲一定的精度来换取计算效率或节省资源的方法。它在很多领域都有广泛的应用,尤其是在大规模数据处理、机器学习和科学计算等方面。以下是近似计算的一些特点和应用:
-
精度折衷:近似计算通过降低计算精度来减少计算量或节省计算资源。在一些应用中,对结果的高精度并不是必需的,因此可以通过近似计算来快速获得满足要求的结果。
-
速度优势:由于牺牲了一定的精度,近似计算往往能够大幅提高计算速度。这对于需要实时计算或大规模数据处理的场景非常有用,例如在推荐系统、数据挖掘和模式识别等应用中。
-
资源节约:在资源受限的环境下,近似计算可以节省计算资源,包括内存、存储和能源等。通过降低计算精度或采用简化的算法,可以在保证一定性能的情况下降低资源消耗。
-
适用性广泛:近似计算适用于许多不同的领域和应用场景,包括数值计算、图形图像处理、信号处理、优化问题求解等。在这些领域中,通常存在一定的容忍度来接受一定的计算误差。
-
深度学习中的应用:在深度学习领域,近似计算可以用于模型压缩、量化和剪枝等技术中,以减少模型的计算复杂度和存储开销,从而实现模型在移动设备上的高效部署和执行。
-
物理模拟和仿真:在物理模拟和仿真领域,近似计算可以用于加速模拟过程,例如通过简化复杂的物理模型或减少模拟的时间步长来降低计算复杂度。
近似计算是一种权衡计算精度和计算效率的方法,通过在实际应用中灵活运用,可以在保证一定性能的情况下提高计算效率和节约资源。

近似计算在大数据、人工智能等计算场景中扮演着重要角色。相关文献统计显示,在诸如数据挖掘、计算机视觉、模式识别、智能通信等典型的大算力需求场景中,约有80%的计算时间可以容忍一定程度的执行时间的可容错性。因此,相较于“完全精确”,“算得快”以及“足够准”成为了大规模计算系统的主要追求目标。
近似计算采用非精确的系统设计和电路结构,以可容忍的计算精度损失来换取硬件性能、能效以及面积效率等指标的大幅提升。它通过合理部署,既能够大幅减少算法运算规模及存储需求,又能够维持足够好的计算精度,以满足实际应用的需求。此外,在大算力所面临的“存储墙”能耗方面,近阈值存储结构提高了能效,使得存取“几乎相同”的数据成为可能,提供了可接受的数据处理精度。在存内计算中嵌入近似电路等逻辑也成为了扩展存内计算场景的重要实现范式,为极低功耗的边缘计算芯片扩展了新的设计思路。
目前,从专用计算到通用计算都可以看到近似计算的应用范例。智能处理器中大量采用精度可调的近似设计,通过采用多位宽可控或模拟计算等方式,使其计算精度损失在可控范围的同时大幅提高能效。在CPU、GPGPU等通用计算架构中,近似计算也已成为提高Cache命中率的重要手段。在通信领域,近似计算技术可使数字信号处理电路得到大幅的能效提升。
为获得较好的电路实现结果,引入近似计算往往需要权衡多个设计层次。从算法设计、架构优化、单元设计、存储结构、器件工艺等层面均有不同的近似计算实现方案。同时,对近似计算系统的设计方法也需要相应的创新优化,以在增加设计维度的同时提高设计效率。
3.2 新兴存内计算芯片架构
新兴存内计算芯片架构是一种集成了计算单元和存储单元的硬件设计,旨在提高计算效率、降低数据传输延迟,并节省能源和资源。这种架构将计算功能直接放置在存储单元内,允许数据在存储时就进行部分处理,而不需要将数据从存储单元传输到计算单元进行处理,从而避免了大量的数据传输延迟和能量消耗。
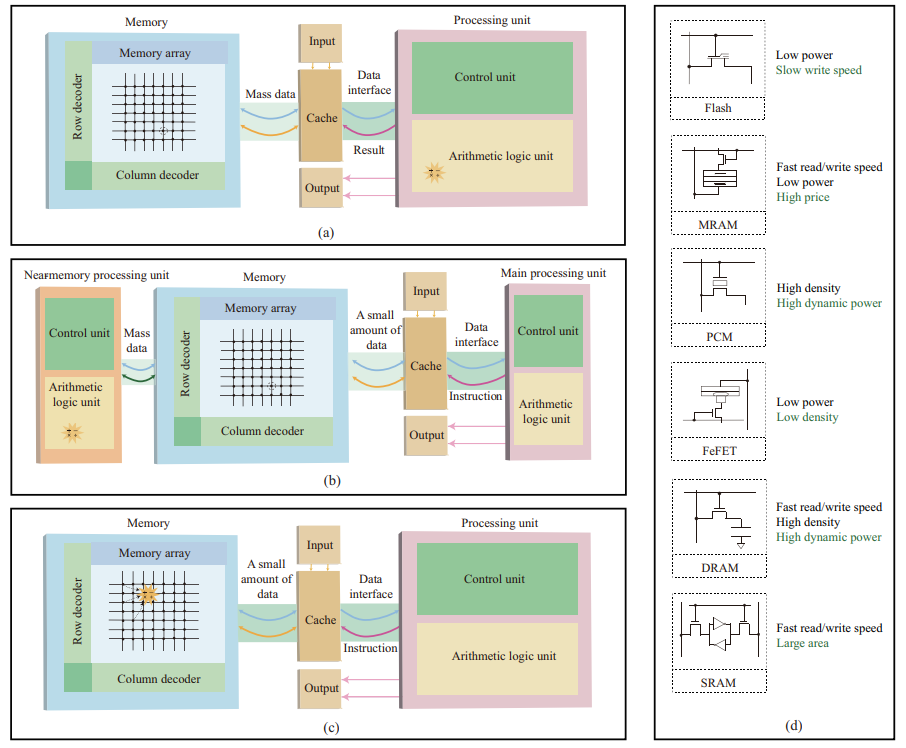
如上图所示,近存计算架构是存内计算领域的一种重要技术路径,旨在将计算与存储更紧密地集成在一起,以缓解“存储墙”问题并提高计算效率。在近存计算架构中,CPU与大容量DRAM存储直接进行一体化封装,通过内部总线互联,实现更快速的访存。以下是近存计算架构的关键特点和技术路径:
-
集成封装:
近存计算将CPU与DRAM存储集成在同一封装中,实现了存储和计算的空间上的紧密结合。这种集成封装可以大大减少数据传输路径,从而降低数据传输延迟和能源消耗。 -
2.5D/3D集成技术:
随着2.5D/3D集成技术的发展,近存计算架构也转向了在垂直方向上进行拓展的思路。典型的案例是将存储切块垂直堆叠在计算单元层之上,通过穿硅通孔技术进行垂直相连,从而实现了更快速的访问速度。 -
PIM-HBM架构:
三星集团提出的PIM-HBM(Processing-in-Memory High Bandwidth Memory)架构是一种典型的近存计算架构。它在2.5D堆叠技术基础上将多层DRAM芯片进行堆叠,并在部分DRAM芯片的存储子阵列级别集成浮点乘加运算单元,利用并行激活提高计算吞吐量。 -
物理隔离的弱化:
近存计算架构并未改变数据存储和处理之间物理隔离的现状,但它在一定程度上弱化了应用导向的“存储墙”和“功耗墙”问题。尽管计算吞吐量得到提高,但由于受到运算单元数据位宽限制,仍然需要面对性能和容量之间的挑战。
近存计算架构作为存内计算技术的一种重要实现方式,为解决“存储墙”问题和提高计算效率提供了新的思路和路径。随着技术的不断发展和成熟,近存计算架构将在数据密集型应用等领域发挥越来越重要的作用。
参考文献
- Vincent B .3D DRAM时代即将到来,泛林集团这样构想3D DRAM的未来架构[J].世界电子元器件,2023,(08):13-18.
- 3D DRAM Is Coming. Here’s a Possible Way to Build It.Benjamin Vincent.Jul 14, 2023
- 邱鲤跳.3D堆叠DRAM Cache的建模以及功耗优化关键技术研究[D].国防科学技术大学,2016.
- 存内计算概述
- 中国科学技术大学
- 唐成峰,胡炜.应用于忆阻器阵列存内计算的低延时低能耗新型感知放大器[J/OL].微电子学与计算机,2024
- 何斯琪,穆琛,and 陈迟晓.基于存算一体集成芯片的大模型专用硬件架构.中兴通讯技术
- 刘伟强, et al.高能效高安全新兴计算芯片:现状、挑战与展望.中国科学:信息科学 54.01(2024):34-47.
这篇关于新兴存内计算芯片架构、大型语言模型、多位存内计算架构——存内计算架构的性能仿真与对比分析探讨的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





