存内专题

【ISSCC】论文详解-34.6 28nm 72.12TFLOPS/W混合存内计算架构
本文介绍ISSCC34.6文章,题目是《A 28nm 72.12TFLOPS/W Hybrid-Domain Outer-Product Based Floating-Point SRAM Computing-in-Memory Macro with Logarithm Bit-Width Residual ADC》(一种28nm 72.12TFLOPS/W混合域外积浮点SRAM存内计算宏单元,具

存内计算与扩散模型:下一代视觉AIGC能力提升的关键
目录 前言 视觉AIGC的ChatGPT4.0时代 扩散模型的算力“饥渴症” 存内计算解救算力“饥渴症” 结语 前言 在这个AI技术日新月异的时代,我们正见证着前所未有的创新与变革。尤其是在视觉内容生成领域(AIGC,Artificial Intelligence Generated Content),技术的每一次飞跃都意味着更加逼真、创意无限的数字艺术作品的诞生。自动生成
【论文合集1】- 存内计算加速机器学习
本章节论文合集,存内计算已经成为继冯.诺伊曼传统架构后,对机器学习推理加速的有效解决方案,四篇论文从存内计算用于机器学习,模拟存内计算,对CNN/Transformer架构加速角度阐述存内计算。 【1】WWW: What, When, Where to Compute-in-Memory 简介:本文探讨了在机器学习推理加速中整合Compute-in-memory(CiM)

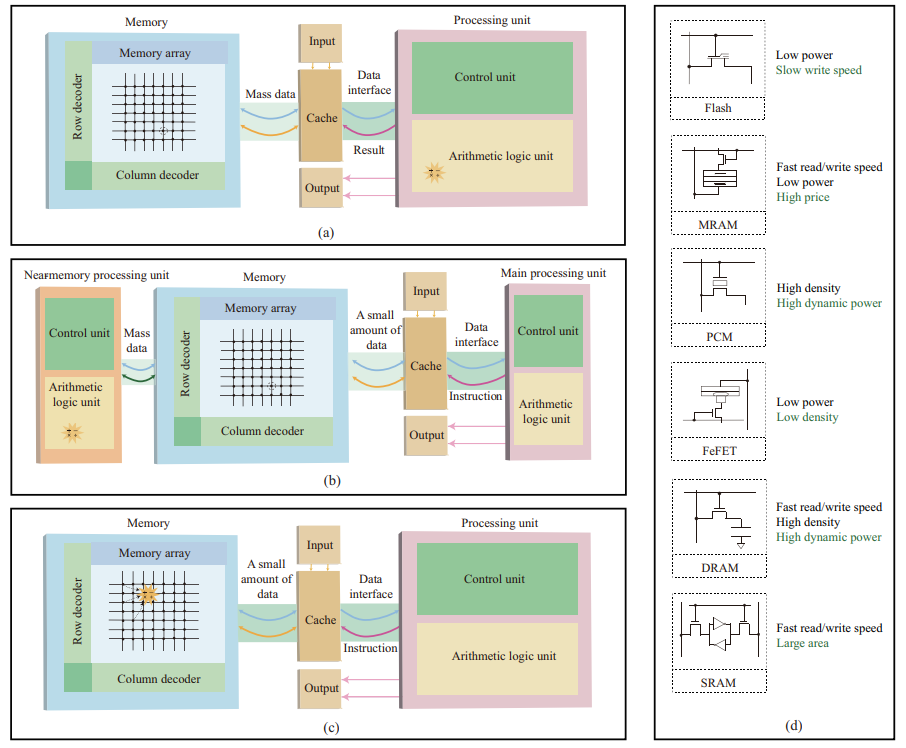
【论文合集 2】- 基于忆阻器的存内计算
基于忆阻器的存内计算(In-Memory Computing, IMC)是一种新兴的计算范式,它利用忆阻器(Memristor)的物理特性来执行计算任务,并将计算过程集成在存储器中。这种架构旨在解决传统冯·诺依曼架构中存在的数据传输瓶颈问题,通过减少数据在处理器和存储器之间传输的需求,从而提高计算效率和降低能耗。本节例举了基于MRAM,RRAM存储器的存内计算范式。 【1】A Survey
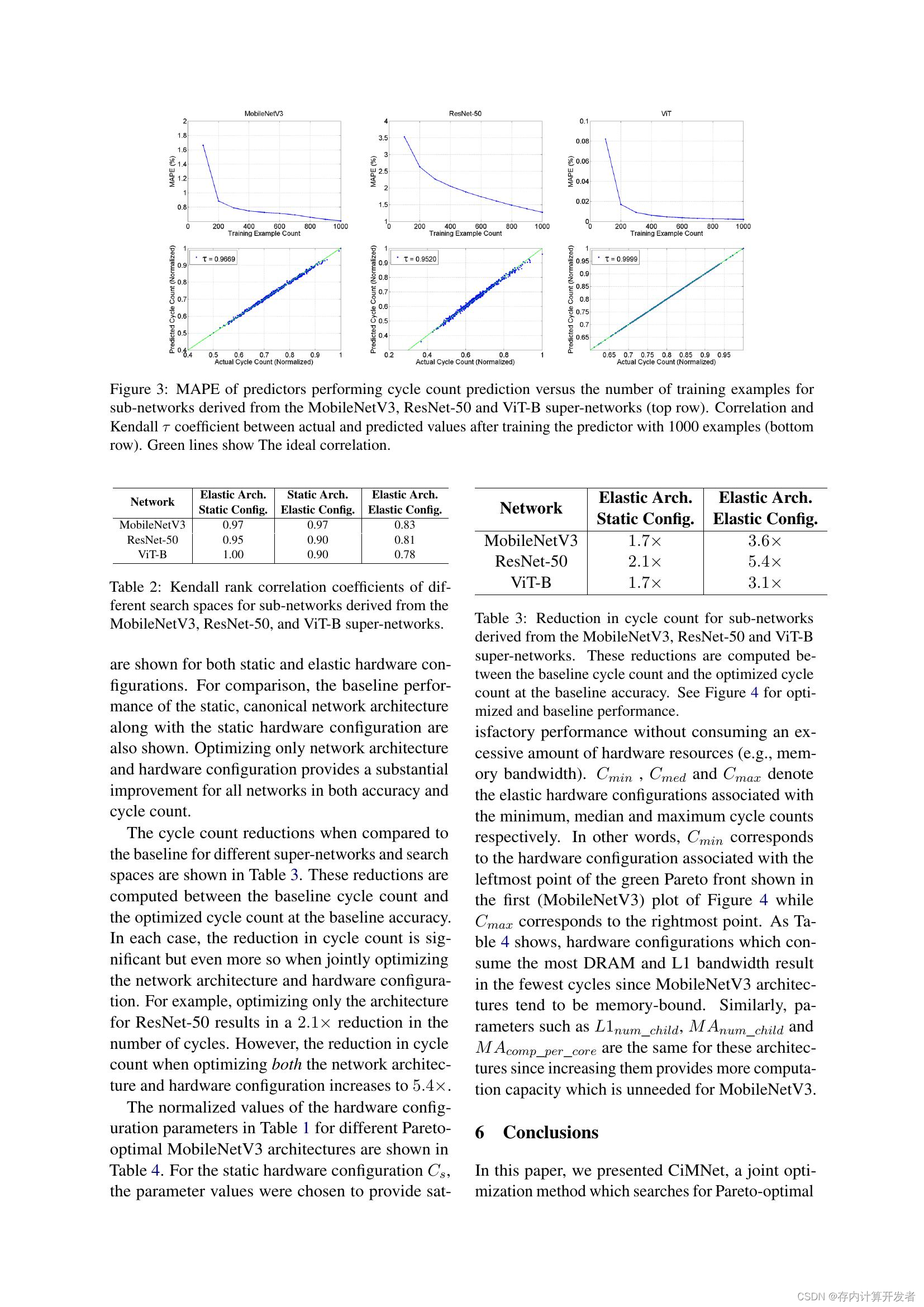
新兴存内计算芯片架构、大型语言模型、多位存内计算架构——存内计算架构的性能仿真与对比分析探讨
CSDN存内社区招募:https://bbs.csdn.net/forums/computinginmemory? 首个存内计算开发者社区,现0门槛新人加入,发文享积分兑超值礼品; 存内计算先锋/大使在社区投稿,可获得双倍积分,以及社区精选流量推送; 精选文章可获得社区奖金激励800,可获得线下训练营的免费名额以及存内主题活动大咖交流机会; 一.大型语言模型(LLM) 近年来,基于注
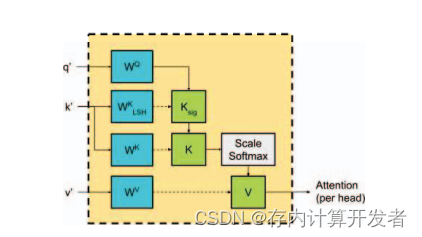
存内计算对大语言模型推理的加速
本篇文章集中讨论了存内计算技术在加速大语言模型推理方面的潜力,从大语言模型的背景知识出发,探讨目前其面临的挑战,进而剖析两篇经典的文献以彰显存内计算有望解决目前大语言模型在推理加速方面存在的问题,最后围绕大语言模型与存内计算的结合展开构想。 大语言模型的背景知识及其面临的挑战 (一)大语言模型的基础概念 通俗来说,大语言模型(Large Language Model,LLM)是基于海量文本

存内计算:释放潜能的黑科技
什么是存内计算? 存内计算技术是一种新型的计算架构,它将存储器和计算单元融合在一起,以实现高效的数据处理。存内计算技术的优势在于能够消除数据搬运的延迟和功耗,从而提高计算效率和能效比。目前,存内计算技术正处于从学术到工业产品落地的关键时期,随着技术的不断进步和应用场景的不断催生,预计存内计算技术将成为AI计算领域的主要架构。 陈巍博士是存算一体芯片技术的专家之一,他指出存算一体技术比冯诺依

存内计算技术大幅提升机器学习算法的性能—挑战与解决方案探讨
一.存内计算技术大幅机器学习算法的性能 1.1背景 人工智能技术的迅速发展使人工智能芯片成为备受关注的关键组成部分。在人工智能的构建中,算力是三个支柱之一,包括数据、算法和算力。目前,人工智能芯片的发展主要集中在两个方向:一方面是采用传统计算架构的AI加速器/计算卡,以GPU、FPGA和ASIC为代表;另一方面则是采用颠覆性的冯诺依曼架构,以存算一体芯片为代表。 随着摩尔定律接近极限,传统的

存内计算引领新一代技术革新,开启算力新时代
文章目录 存内计算与传统计算的区别 存内计算与传统计算的区别 存内计算芯片的优势 存内计算在各个领域的应用 存内计算技术对未来发展的影响 CSDN存内计算开发者社区:引领新一代技术革新的最前沿 社区内容专业度 社区具备的资源 社区的开放性 社区招募令:寻找存内计算先锋与大使 存内计算先锋招募 存内计算大使招募 总结 在计算机领域中,经常出现新的技术和设计

存内计算架构在通用视觉模型上的潜力应用
近年来,人工智能领域的通用视觉模型在自动驾驶、医疗图像分析、机器人视觉系统等场景中发挥了越来越重要的作用,它们通过模拟人类的视觉处理机制,有效地识别、理解和分析图像和视频数据。同时,新兴的存内计算架构显著优化了现有通用视觉模型的性能。它通过减少处理器和存储器间的数据传输需求,提升了数据处理速度,并显著降低了能源消耗。因此,存内计算架构对于提高通用视觉模型的处理速率和整体效能至关重要,使其能够更加迅
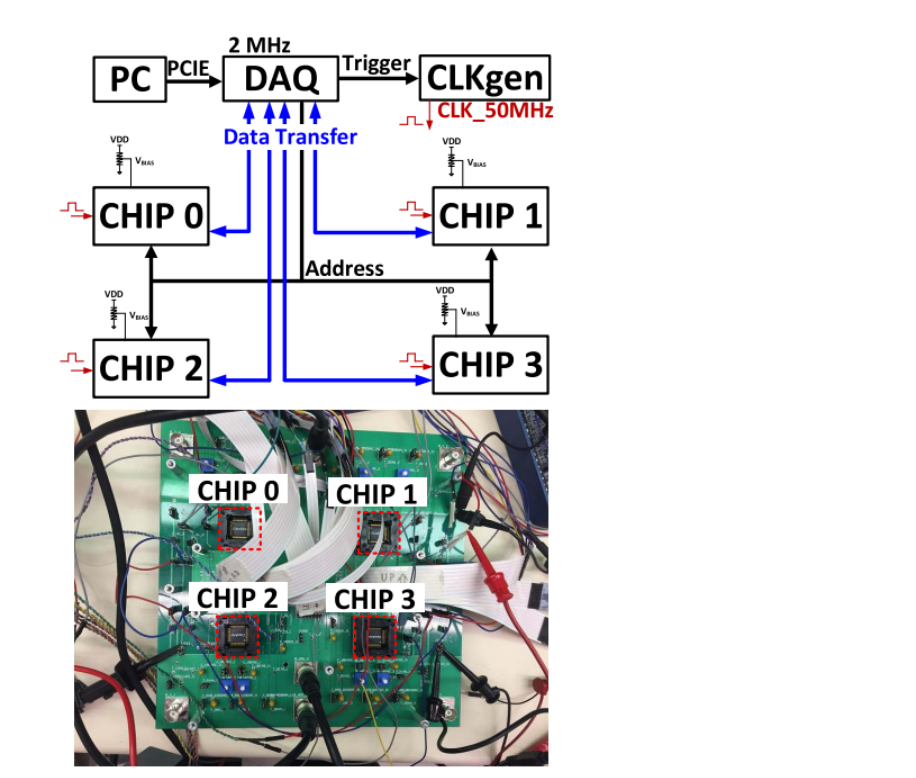
深度神经网络中的BNN和DNN:基于存内计算的原理、实现与能量效率
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z ChatGPT体验地址 文章目录 前言引言内存计算体系结构深度神经网络(DNN)随机梯度的优化算法 二值化神经网络(BNN)BNN架构基于 sram 的内存计算系统中各列偏移的硬件补偿,归一化 系统演示总结 引言 深度神
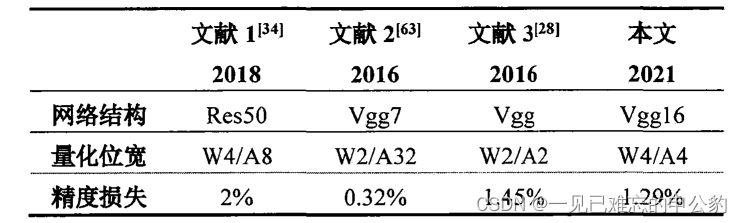
存内计算芯片研究进展及应用—以基于NorFlash的卷积神经网络量化及部署研究突出存内计算特性
文章目录 存内计算的背景存算一体技术发展历程 存内计算芯片研究现状SRAM存内计算DRAM存内计算ReRAM/PCM存内计算MRAM存内计算NOR Flash存内计算 基于 NOR Flash 的卷积神经网络量化卷积神经网络基本结构卷积神经网络量化方法研究实验及结果分析心得 参考文献 如果我能看得更远一点的话,那是因为我站在巨人的肩膀上。 —牛顿 存内计算的背景 存内计算

数字存内计算与云边端具有广泛的应用场景深度剖析【根据中国移动研究院文献分析总结】
文章目录 背景数字存内计算技术研究端侧应用场景边侧应用场景云侧应用场景 总结参考文献: 背景 存内计算产品基于其不同的器件特性和计算方式,能够为云、边缘和端设备提供推理、训练等多种人工智能(AI)能力,从而提升运算效率、降低系统功耗以及设备成本。这些产品在不同的应用场景中发挥着关键作用。 推理能力提升: 存内计算产品在推理任务中展现出优越的性能。通过在存储器内部执行计算
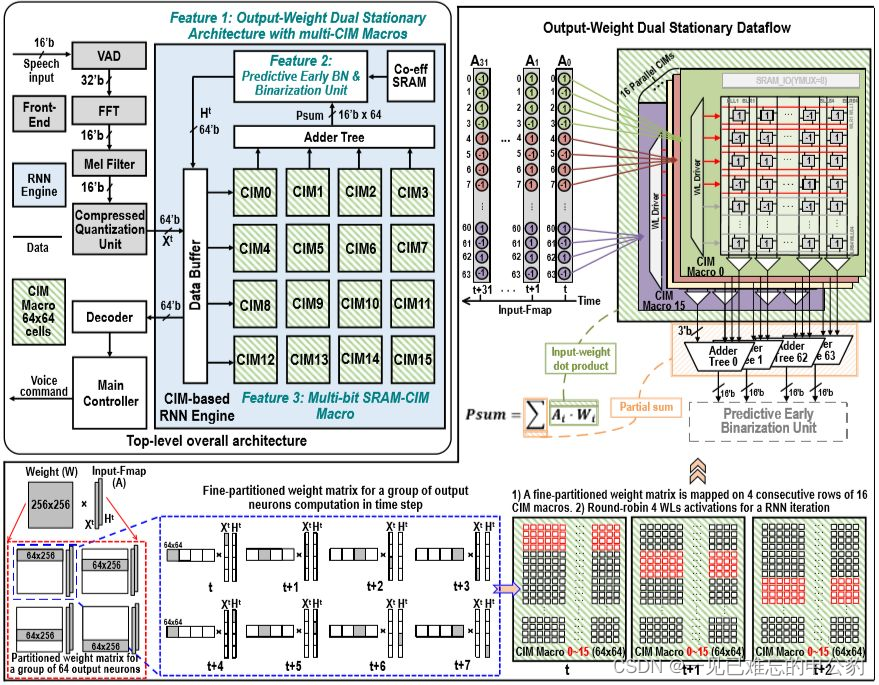
存内计算技术—解决冯·诺依曼瓶颈的AI算力引擎
文章目录 存内计算技术背景CSDN首个存内计算开发者社区硅基光电子技术存内计算提升AI算力知存科技存算一体芯片技术基于存内计算的语音芯片的实现挑战 参考文献 存内计算技术背景 存内计算技术是一种革新性的计算架构,旨在克服传统冯·诺依曼架构的瓶颈,并实现更高效的数据处理。随着大数据时代的到来,传统的冯·诺依曼架构已经难以满足不断增长的计算需求,因为它将处理单元和存储器分开,导致数据

快速入门存内计算—助力人工智能加速深度学习模型的训练和推理
存内计算:提高计算性能和能效的新技术 传统的计算机架构是将数据存储在存储器中,然后将数据传输到计算单元进行处理。这种架构存在一个性能瓶颈,即数据传输延迟。存内计算通过将计算单元集成到存储器中,消除了数据传输延迟,从而提高了系统性能。 什么是存内计算 存内计算(Processing-In-Memory)是指在存储器内部直接进行数据处理的技术。存内计算的实现方式主要有两种: 模拟存内计算:
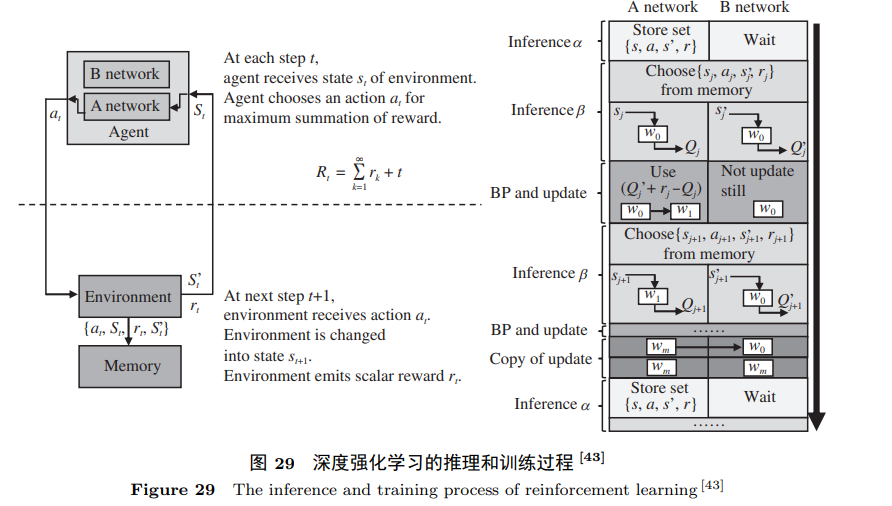
窥探向量乘矩阵的存内计算原理—基于向量乘矩阵的存内计算
在当今计算领域中,存内计算技术凭借其出色的向量乘矩阵操作效能引起了广泛关注。本文将深入研究基于向量乘矩阵的存内计算原理,并探讨几个引人注目的代表性工作,如DPE、ISAAC、PRIME等,它们在神经网络和图计算应用中表现出色,为我们带来了前所未有的计算体验。 窥探向量乘矩阵的存内计算原理 生动地展示了基于向量乘矩阵的存内计算最基本单元。这一单元通过基尔霍夫定律,在仅一个读操作延迟内
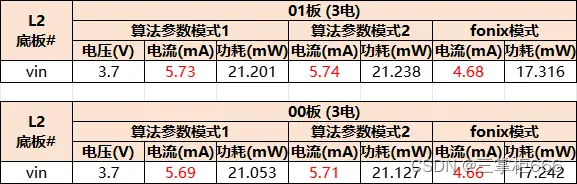
存内计算技术打破常规算力局限性
目录 前言 关于存内计算 1、常规算力局限性 2、存内计算诞生记 3、存内计算核心 存内计算芯片研发历程及商业化 1、存内计算芯片研发历程 2、存内计算先驱出道 3、存内计算商业化落地 基于知存科技存内计算开发板ZT1的降噪验证 (一)任务目标以及具体步骤 1、主模块 2、子模块(烧录时候需要用到) 3、主模块设置 4、连接效果 (二)模拟及验证结果 1、啸叫环境

“超越摩尔定律”,存内计算走在爆发的边缘
过去几十年来,在摩尔定律的推动下,处理器的性能有了显著提高。然而,传统的计算架构将数据的处理和存储分离开来,随着以数据为中心的计算(如机器学习)的发展,在这两个物理分离的单元之间传输数据的成本越来越高,在整体延迟和能耗方面占据了主导地位。 专用处理器的能效 同时,尽管传统逻辑门具有通用性和鲁棒性,但其计算效率低下,在进行乘法、加法和非线性函数等算术计算时需要消耗大量

1024 CSDN 程序员节-知存科技-基于存内计算芯片开发板验证语音识别
前言 在今年的 CSDN 程序员节上,我参与了这次知存科技举办的一个 AI Workshop 小活动——“基于存内计算芯片开发板验证语音识别”,并且有幸成为完成任务的学习者之一XD。上一次参与类似的活动是算能公司举办的“千校万里行”AIGC 大模型编译部署活动,感觉虽然只是简单的烧录现成代码,经历这几次活动后 AI 小白也能有一个小小的成就感。趁着这股新鲜感还没冷却,我打算写一篇博文来记录下这次