本文主要是介绍存内计算架构在通用视觉模型上的潜力应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近年来,人工智能领域的通用视觉模型在自动驾驶、医疗图像分析、机器人视觉系统等场景中发挥了越来越重要的作用,它们通过模拟人类的视觉处理机制,有效地识别、理解和分析图像和视频数据。同时,新兴的存内计算架构显著优化了现有通用视觉模型的性能。它通过减少处理器和存储器间的数据传输需求,提升了数据处理速度,并显著降低了能源消耗。因此,存内计算架构对于提高通用视觉模型的处理速率和整体效能至关重要,使其能够更加迅速和高效地处理复杂的图像和视频数据,从而在实时应用中发挥更大的作用。
本篇文章将从通用视觉模型和存内计算架构的定义出发,分析存内计算加速器架构如何有效提升通用视觉模型的性能,讲述现有存内计算加速器架构的特点及优势,最后展望存内计算加速器架构在通用视觉模型领域的未来趋势和潜在发展。
一.通用视觉模型及存内计算的基础概念
(一)通用视觉模型
通用视觉模型是一种具有广泛应用场景的视觉处理技术,旨在模拟和实现人类视觉系统的功能,其可以处理各种复杂的图像识别任务,如人脸识别、物体识别、场景识别等,在智能家居、商品识别、设备检视等领域中有所应用。这些模型通常基于深度学习算法,从图像或视频中提取边缘、颜色、纹理等关键特征,进而识别对象、场景、动作等。
目前主流的通用视觉模型主要基于两种框架:卷积神经网络(Convolutional Neural Network,CNN)和Transformer。CNN通过模拟人类视觉系统的工作原理,利用多层卷积层来自动和有效地提取图像中的特征,随后通过池化层降低特征的维度以减少计算量,最终借助全连接层基于这些特征进行分类或其他任务的决策;Transformer通过自注意力机制有效地处理序列数据,利用注意力层计算输入元素间的关联度,然后通过这些加权关联强化输入特征。此外,一些模型通过混合这两种架构,提高了模型的性能和效率,例如ConvNeXt、Swin Transformer等。
(二)存内计算
存内计算(Compute-In-Memory,CIM)加速器架构,即将数据处理功能直接集成到内存芯片中,允许在数据存储位置执行计算操作。这种设计减少了数据在处理器和内存之间的传输,从而降低了延迟并提高了能效。由于计算操作可以在多个内存位置同时进行,对于大规模数据集,CIM能够实现高度的并行处理。
在传统计算模式中,如图1(a),数据处理和存储相分离,数据在存储器和处理器之间的频繁搬移造成了传输延迟和能源消耗,限制了处理速度和整体性能。而在存内计算模式中,如图1(b),不再区分存储单元和计算单元,能够提供更快的处理速度和更好的性能,尤其是在处理大数据量时。
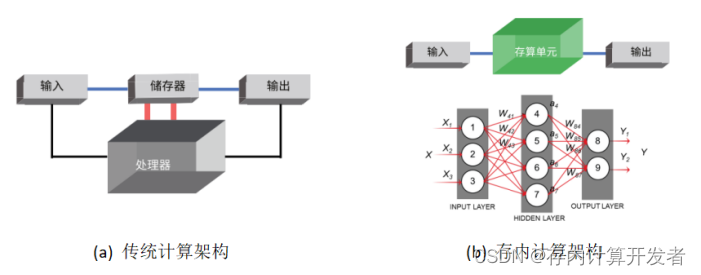
图1 传统计算架构vs存内计算架构[2]
近年来,随着通用视觉模型的算力、算法和数据呈指数级增长,摩尔定律逐渐逼近极限,“功耗墙”和“存储墙”等问题日益显著,作为创新型架构的存内计算或许能够为通用视觉模型带来性能上的提升,同时解决传统计算模式中的一些瓶颈问题。
二.存内计算架构在通用视觉模型上的性能分析
(一)Gibbon - 神经网络模型和存内处理架构的高效协同探索框架
在深度学习领域,基于忆阻器的存内处理(PIM)架构正引起革命性的变革。这种架构通过将数据存储与处理紧密结合,显著提高了计算和能源效率,特别适用于数据密集型的深度神经网络。然而,要最大化这一架构的潜力,需要同时对神经网络模型和PIM架构进行协同优化。为此提出了Gibbon框架(图2),它不仅精心设计了适应NN模型与PIM架构的协同探索空间,还引入了自适应参数优先级的进化搜索算法(ESAPP)和多级联合模拟器以提高搜索效率来减少评估时间。实验结果显示,Gibbon框架能在短短6个GPU小时内找到优化方案("6个GPU小时"是指使用6台图形处理单元(GPU)的计算资源,用于运行计算和优化任务的时间),相比现有研究提供了高达9.8×–48.2×的加速比,同时增加了15.3%的准确性并将能量延迟积(EDP)降低了5.96倍。特别是在视觉模型领域,Gibbon框架的应用能够显著提高处理速度,为图像和视频分析等应用提供了高效且节能的解决方案。
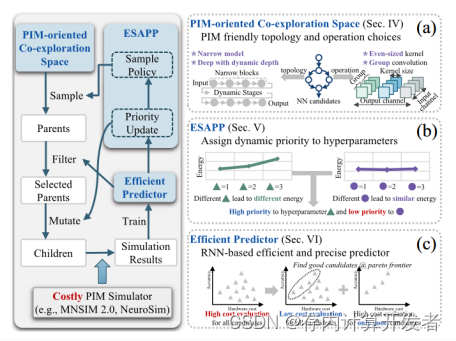
图2 共同探索框架概述(左部分)。 Gibbon 包含三个关键组件:(a) 面向 PIM 的协同探索空间、(b) ESAPP 和 (c) 基于 RNN 的准确性和硬件性能预测器。
(二)MulTCIM - 高效多模态Transformer计算加速器架构
多模态Transformer模型在人工智能领域备受关注,但其高计算成本和能耗一直是挑战。MulTCIM是一种新型基于数字存内计算(CIM)的加速器架构(图3),专为多模态Transformer优化。它具备三个关键功能:长重用消除、令牌修剪和模态自适应,以充分利用注意力令牌位混合稀疏性。MulTCIM的应用在基于ViLBERT的模型中表现出色,仅消耗2.24 μJ/Token的能量,比传统加速器和数字CIM节能2.50×–5.91×。这一架构不仅提高了计算效率,还为视觉模型等领域带来更高的性能和能效。
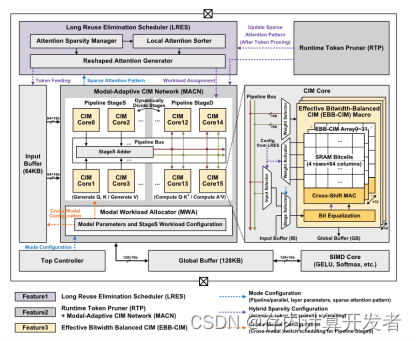
图3 MulTCIM加速器的整体架构
(三)TT@CIM - 高效能量节省的深度神经网络加速器
存内计算(CIM)是一种低功耗深度神经网络(DNN)处理方法,适合用于低功耗边缘设备。但典型DNN模型通常超出了CIM静态随机存取存储器(SRAM)的容量,导致内存问题。为解决这一挑战,提出了一种CIM处理器TT@CIM(图4),通过张量训练分解(TTD)来压缩DNN以适应CIM-SRAM。虽然TTD减少了存储需求,但引入了串行小规模矩阵乘法,导致低效的乘法累加(MAC)和量化运算(QuantOps)。为提高效率,TT@CIM提出三种优化技术:匹配数据流、稀疏编码、可变精度量化。TT@CIM在28 nm CMOS制造,测试表明在4/8位分解DNN上,工作电压下能效实现5.99 - 691.13 TOPS/W。
TT@CIM架构在视觉模型中表现显著。通过TTD压缩模型,减小内存占用,使得视觉模型在低功耗边缘设备上运行更高效。同时,优化技术降低计算能耗,延长续航时间,为实时图像处理和视觉识别任务提供更强性能。这一架构有助于推动低功耗AI视觉应用,提供潜力应用于智能摄像头、无人机和移动设备。
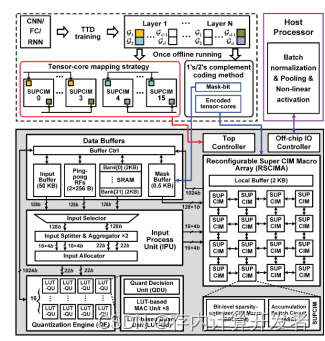
图4 TT@CIM 整体架构
- 存内计算架构在通用视觉模型上的应用

图5 知存科技WTM8芯片示意图
卷积方案以其能够降低大量参数为优势,适应于小场景,边缘端侧应用,此外,卷积方案的高效性也为在边缘端实施复杂的数据处理和分析任务,如图像和语音识别,提供了可能。随着技术的成熟和优化,市场上已经涌现出多种基于卷积方案的商用产品如,它们在提高性能和可靠性的同时,也推动了边缘计算技术的广泛应用和行业发展。
国内知存科技推出WTM-8系列产品芯片(图5),这是针对视频增强处理的一款高性能低功耗的移动设备计算AI视觉芯片,采用第二代3D存内计算架构,为全球首款存内计算视觉芯片,它采用了支持Linux系统的处理器,并且集成了AI加速功能、高动态范围(HDR)图像处理以及高速信号处理等多项技术。WTM-8的核心优势包括:(1)拥有超过24 Tops的计算能力,能够高效地处理复杂的AI运算和图像处理任务。(2)具备64M的超大存储空间,为数据密集型的应用提供了充足的存储资源。(3)支持12-bit的高精度数据处理,这对于高质量图像和信号处理至关重要。WTM-8的这些特性使其在高性能计算、图像和视频处理、智能分析等多个领域表现卓越,为各种高端应用提供了强有力的硬件支持。
存内计算架构提供了一种对传统计算架构的重要补充,为下一代计算需求提供了支持。随着技术的进步和产品的创新,预计存内计算架构将在高性能计算领域扮演越来越重要的角色。
- 存内计算架构在通用视觉模型领域的未来发展
存内计算架构能够在数据所在的内存中直接处理数据,避免了数据在内存和CPU之间的传输,从而显著减少了延迟,还有效利用了带宽资源,提高了数据的并行处理能力。因此在数据密集型和带宽密集型的应用中存内计算架构具有优势。
Transformer模型在自然语言处理(NLP)等领域取得了巨大成功。这种模型依赖于大量的矩阵乘法运算(如自注意力机制),这些运算非常耗费计算资源。存算一体技术可以加速这些矩阵乘法运算,因为它允许这些运算在数据存储的地方直接进行,减少了数据传输造成的延迟和能源消耗。
最近,研究者们开始探索将CNN和Transformer结合起来,以便利用二者的优势。CNN在处理固定网格数据(如图像)时非常有效,而Transformer在处理序列数据时效果显著。在这种组合模型中,CNN可以用于提取特征,而Transformer则可以用于处理这些特征之间复杂的关系。存算一体技术在这种组合中发挥作用,它可以在存储器中执行CNN的卷积运算和Transformer的矩阵运算,从而提高整体的计算效率和能源效率。
在通用视觉模型领域,尽管存内计算架构展现出巨大潜力,但仍面临一系列挑战。首先,CIM架构的计算能力虽然强大,但在处理高复杂性视觉任务时可能存在限制。其次,数据安全和隐私是CIM在视觉模型应用中的另一个关键问题。再者,CIM架构在能效方面虽有优势,但随着视觉模型计算需求的增加,如何进一步提高能效比和降低功耗,仍是研究和开发的重点。最后,CIM架构的硬件和软件兼容性也是一个重要考虑因素。现有的视觉处理软件和算法可能需要重构,以充分利用CIM架构的优势。
综上所述,虽然存内计算架构在通用视觉模型领域显示出显著的潜力和优势,但仍需在计算能力、数据安全、能效优化以及硬件软件兼容性等方面进行进一步的研究和开发,以解决这些挑战,推动技术的发展与应用。
资料来源
- 通用视觉大模型 — 华为云(https://marketplace.huaweicloud.com/article/1-3354b48bcff398471fecdcee9fa85c8d)
- 知存科技官网(witintech.com)
- 郭昕婕,王光燿,王绍迪.存内计算芯片研究进展及应用[J].电子与信息学报,2023,45(05):1888-1898.
- H. Sun et al., "Gibbon: An Efficient Co-Exploration Framework of NN Model and Processing-In-Memory Architecture," in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 11, pp. 4075-4089, Nov. 2023, doi: 10.1109/TCAD.2023.3262201.
- F. Tu et al., "MulTCIM: Digital Computing-in-Memory-Based Multimodal Transformer Accelerator With Attention-Token-Bit Hybrid Sparsity," in IEEE Journal of Solid-State Circuits, vol. 59, no. 1, pp. 90-101, Jan. 2024, doi: 10.1109/JSSC.2023.3305663.
- R. Guo et al., "TT@CIM: A Tensor-Train In-Memory-Computing Processor Using Bit-Level-Sparsity Optimization and Variable Precision Quantization," in IEEE Journal of Solid-State Circuits, vol. 58, no. 3, pp. 852-866, March 2023, doi: 10.1109/JSSC.2022.3198413.
这篇关于存内计算架构在通用视觉模型上的潜力应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






