本文主要是介绍窥探向量乘矩阵的存内计算原理—基于向量乘矩阵的存内计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在当今计算领域中,存内计算技术凭借其出色的向量乘矩阵操作效能引起了广泛关注。本文将深入研究基于向量乘矩阵的存内计算原理,并探讨几个引人注目的代表性工作,如DPE、ISAAC、PRIME等,它们在神经网络和图计算应用中表现出色,为我们带来了前所未有的计算体验。

窥探向量乘矩阵的存内计算原理
生动地展示了基于向量乘矩阵的存内计算最基本单元。这一单元通过基尔霍夫定律,在仅一个读操作延迟内完整执行一次向量乘矩阵操作。演示了一个2×1的向量(V1, V2)与一个1×2的向量(G1, G2)T相乘的过程,其中ReRAM阻值以(G1, G2)T表示,电压则以(V1, V2)表示。基于基尔霍夫定律,比特线上的输出电流便是向量乘矩阵操作的结果。将这一操作扩展,将矩阵存储在ReRAM阵列中,通过比特线输出相应的结果向量。
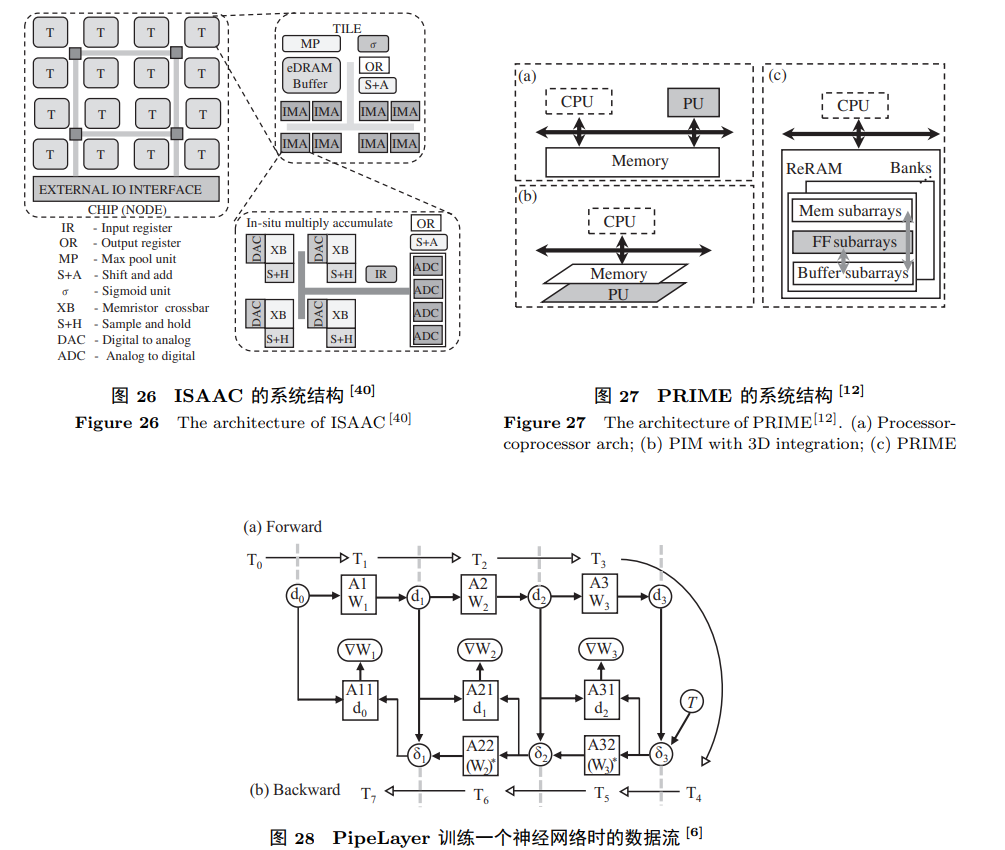
探寻代表性工作的独特之处
1. DPE (Hewlett Packard Laboratories)
DPE是专为向量乘矩阵操作设计的存内计算加速器。其独特之处在于提供了一种转化算法,将实际的全精度矩阵巧妙地存储到精度有限的ReRAM存内计算阵列中。实验证明,仅用4位的DAC/ADC就能保证计算结果没有精度损失,而性能提升更是达到了令人瞠目的1000到10000倍。
2. ISAAC (University of Utah)
ISAAC是专为神经网络推理设计的存内计算架构,其多个存内计算阵列通过C-mesh片上网络连接。每个阵列包含用于不同计算层的多种单元,如最大池化单元、Sigmoid单元、eDRAM缓存等。ISAAC通过ReRAM阵列实现向量乘矩阵操作,采用流水线方式提高推理效率,为神经网络的推理提供了独特而高效的解决方案。
3. PRIME (University of Santa Barbara)
PRIME同样专注于神经网络推理,其独特之处在于直接使用ReRAM单元进行计算。ReRAM bank包括Mem subarrays(存储)、FF subarrays(计算)和Buffer subarray(缓存)。相较于其他结构,PRIME实现了显著的性能提升和能耗节约,为神经网络推理领域带来了全新的可能性。
逐鹿存内计算的新时代
随着计算领域不断演进,存内计算技术如一匹矫健的鹿儿,勇敢地迎接着新时代的挑战。DPE、ISAAC、PRIME等工作不仅为存内计算打开了崭新的篇章,也为我们提供了探索计算世界更深层次的机会。
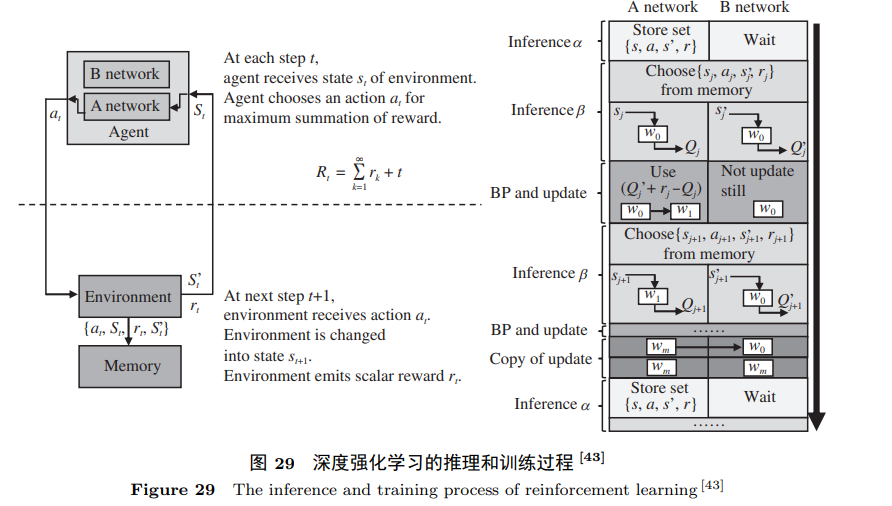
4. PipeLayer (Duke University)
在神经网络训练领域,PipeLayer是一匹勇敢的鹿。其存内计算系统架构旨在通过复制多份权重数据实现少气泡的pipeline结构。PipeLayer巧妙地使得反向传播阶段的误差传递和权值计算并行进行,从而提高了存内计算训练神经网络的计算效率。实验结果显示,与传统的GPU系统相比,PipeLayer实现了42倍的性能提升和7倍的能耗节约。
5.TIME (Tsinghua University)
在神经网络训练领域,TIME则为存内计算技术打开了新的可能性。为了降低训练时权重矩阵更新的延迟和能耗,TIME采取了权重矩阵复用的方法,与其他方法不同,它不是复制多份权重矩阵,而是通过特殊的数据映射操作来消除拷贝操作的写入开销。实验证明,TIME在有监督的神经网络和强化学习网络方面分别实现了5.3倍和126倍的能耗节约。
踏入未知的LerGAN之境 (Tsinghua University)
LerGAN作为对抗生成网络(GAN)的存内计算系统架构,为存内计算的发展开辟了新的天地。通过去除零相关的操作,重新构建卷积核,LerGAN巧妙地应对了GAN的挑战。它提出了一个三层堆叠的存内计算阵列结构,使得GAN训练的数据传输路径变短,路由减少。实验结果表明,相较于传统的CNN,LerGAN在性能和能耗方面分别取得了7.46倍和7.68倍的提升。
PCM+CMOS:IBM的前瞻之举
IBM的PCM+CMOS存内计算方法,将存储单元与计算结合,实现了全连接神经网络的前向传播、反向传播和权值计算。其独特的结构中使用PCM单元存储权值的高位,而电容器单元存储权值的低位,巧妙地平衡了计算的稳定性和存储的寿命。该方法为存内计算提供了一种前瞻性的解决方案。
结语:携手向前迈进
这一系列存内计算的代表性工作,如同一群勇敢的鹿群,勇敢地探索着计算领域的未知领域。DPE、ISAAC、PRIME、PipeLayer、TIME、LerGAN、PCM+CMOS等工作,各自带有独特的特点,共同构筑起存内计算技术的辉煌画卷。
未来,存内计算技术将继续与创新者携手前行,挑战更大的计算难题。这不仅是对技术的不懈探索,更是对计算领域的一次颠覆性的变革。在这个充满激情和创造力的时代,我们期待存内计算技术与计算领域共同书写新的传奇。携手向前,踏上计算的无限征程。
基于向量乘矩阵的存内计算技术正积极推动着神经网络和图计算领域的发展。DPE、ISAAC、PRIME等代表性工作展示了这一领域的多样性和创新。我们可以期待,存内计算技术将在提高计算效率、减少能耗等方面发挥更为关键的作用,为计算领域带来更多的创新与突破。在这个充满活力的领域中,我们正迈向一个更加智能和高效的未来。
参考文献;
《中国科学》杂志社:内存计算研究进展
这篇关于窥探向量乘矩阵的存内计算原理—基于向量乘矩阵的存内计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





