本文主要是介绍数字存内计算与云边端具有广泛的应用场景深度剖析【根据中国移动研究院文献分析总结】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 背景
- 数字存内计算技术研究
- 端侧应用场景
- 边侧应用场景
- 云侧应用场景
- 总结
- 参考文献:
背景

存内计算产品基于其不同的器件特性和计算方式,能够为云、边缘和端设备提供推理、训练等多种人工智能(AI)能力,从而提升运算效率、降低系统功耗以及设备成本。这些产品在不同的应用场景中发挥着关键作用。
-
推理能力提升: 存内计算产品在推理任务中展现出优越的性能。通过在存储器内部执行计算,避免了频繁的数据传输,从而大幅提升了推理任务的效率。这对于云端、边缘设备以及终端设备上运行的AI应用都具有重要的意义。
-
训练加速: 存内计算产品的设计有助于加速AI模型的训练过程。存储器内部的计算单元能够直接处理大规模的数据,减少了对外部计算资源的依赖,提高了训练效率。这对于需要在本地进行模型更新和训练的场景非常有益。
-
运算效率提升: 存内计算直接在存储器中完成计算,减少了数据在存储和计算单元之间的移动,从而提高了运算效率。这对于处理大规模数据集和复杂计算任务的场景尤为重要。
-
降低系统功耗: 存内计算的设计能够降低整个系统的功耗,因为它减少了数据传输的需求,避免了在存储和计算单元之间频繁读写数据的开销。这使得在边缘和端设备上运行的AI应用更为节能。
-
降低设备成本: 存内计算的技术可以使设备更为紧凑,同时减少了对外部计算资源的需求,从而有望降低整个设备的成本。这对于推动AI技术在广泛的设备中的采用具有积极的影响。
数字存内计算技术研究
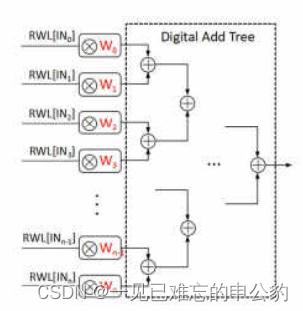
数字存内计算通过在存储阵列内部加入逻辑计算电路,例如与门和加法器等,使得数字存内计算阵列具备存储和计算能力[5]。以下以静态随机存储器(Static Random-Access Memory,SRAM)为例,介绍数字存内计算的基本原理。
在数字存内计算中,输入数据是一个向量 [IN, IN, …, IN],这些数据依次存入存储单元。模型参数 [W, W, …] 存储在相应的存储单元中。通过控制存储器的读字线(Read WordLine, RWL),实现输入数据与存储单元内的模型参数进行乘法操作。然后,通过数字加法树(Digital Add Tree)实现累加,从而完成向量乘加运算。对于多个向量,可以重复以上过程,从而实现矩阵乘加计算。
需要注意的是,数字存内计算的存储单元只能存储单比特数据,并且由于需要增加部分传统逻辑电路,这在一定程度上限制了其面积和能效的优势。因此,当前业界多采用可兼容先进工艺的SRAM来实现数字存内计算。这样的设计可以更好地平衡存储和计算的需求,同时保持较高的集成度和能效。
端侧应用场景

根据IDC的预测,到2025年,全球物联网设备数量将超过400亿台,产生的数据量接近80ZB。在智慧城市、智能家居、自动驾驶等多个场景中,超过一半的数据需要依赖于终端本地处理。单个设备的算力需求预计将在0.1~64TOPS之间。此外,各种终端设备对运行时间、功耗、便携性等方面有较高要求,例如智能眼镜/耳机需要保证满负荷待机时间超过16小时,而手机的最高运行功耗不应超过8W。终端设备的未来发展将更加注重时延、功耗、成本和隐私性等需求特征。
与传统方案相比,存内计算在功耗和计算效率等方面具有显著优势。在相同制程工艺下,存内计算芯片能够在单位面积上提供更高的算力,更低的功耗,从而延长设备的工作时间。这使得存内计算在端侧具有广阔的应用前景,将广泛应用于家庭网关、工业网关、摄像头、可穿戴设备等场景。
目前,存内计算产品已经成功在端侧初步商用,为语音、视频等AI处理能力提供支持,并取得了十倍以上的能效提升。这有效地降低了端侧设备的成本,使得存内计算在应对未来大规模物联网设备挑战的同时,为各种终端应用提供了更为高效和可持续的解决方案。
边侧应用场景
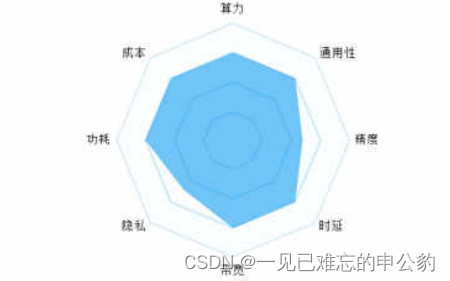
随着云游戏、车联网等边缘计算应用的迅速发展,海量数据将在边缘进行处理,流量模型逐渐从云扩展到边缘。在边缘计算场景下,对单个设备的算力需求预计将在64256TOPS之间,同时对时延的要求非常高,例如智慧港口要求端到端时延在1020ms之间,而车联网场景要求端到端时延在3~100ms之间。此外,由于边缘设备通常部署在靠近数据生产或使用的场所,对散热性能的要求也相对较高。总体而言,边缘设备的未来发展将更加注重时延、功耗、成本和通用性等需求特征,如图3-2所示。
与传统方案相比,存算一体在深度学习等领域具有独特的优势,能够提供比传统设备高几十倍的算效比。此外,存内计算芯片通过架构创新,可以提供综合性能全面兼顾的芯片和板卡。预计存算一体将在边缘推理场景中得到广泛应用,为各种边缘AI业务提供服务。这种技术的应用有望在提高处理效率的同时,更好地满足边缘计算应用对时延、功耗、成本和通用性等多方面的要求。
云侧应用场景
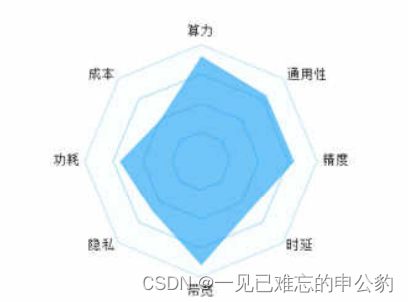
以图像、语音、视频为主的非结构化数据正呈现高速增长趋势。根据IDC的预测,到2030年,这种趋势将推动智能算力需求增长500倍。以AI算力为核心的智算中心将成为算力基础设施的主流。然而,随着大规模AI芯片集约化建设的推进,高功耗成为一个严峻的挑战。每机架平均功耗预计将由35kW逐渐升至710kW。未来智算中心呼唤新型AI芯片,以满足云侧大算力、高带宽、低功耗等特性,如图3-3所示。
存内计算作为一种新型的AI芯片技术,通过多核协同集成大算力芯片,结合可重构设计构建通用计算架构。存内计算在智算中心的发展中扮演着重要的角色,作为下一代关键AI芯片技术,正持续演进以满足大算力、通用性、高计算精度等方面的需求。它有望为智算中心提供绿色、节能的大规模AI算力,有效缓解了传统建设方式所面临的功耗和散热问题,为未来的智能计算基础设施提供更为可持续和高效的解决方案。
总结

本文介绍了存内计算技术在推理、训练等人工智能任务中的优越性能,以及其在云、边缘和端设备上的应用场景。具体来说,存内计算在提升推理能力、加速训练过程、提高运算效率、降低系统功耗和设备成本方面取得显著成果。数字存内计算技术通过在存储阵列内部集成逻辑计算电路,如与门和加法器,使得存内计算阵列能够同时进行存储和计算操作。以静态随机存储器(SRAM)为例,文章详细解释了数字存内计算的基本原理。
在应用场景方面,存内计算在端侧、边侧和云侧都展现出广泛的潜力。在端侧,存内计算产品已经在语音、视频等AI处理能力方面取得商业成功,为各种终端设备提供高效且节能的解决方案。在边侧,存算一体在边缘推理场景中得到广泛应用,为边缘AI业务提供服务。在云侧,存内计算作为新型AI芯片技术,在智算中心的发展中发挥着关键作用,为大规模AI算力需求提供绿色、节能的解决方案。总体而言,存内计算技术为AI应用在不同场景中提供了高效、可持续和节能的计算支持。
参考文献:
本文根据中国移动研究院文献分析总结而来。
1.知存科技
2.中国移动研究院
这篇关于数字存内计算与云边端具有广泛的应用场景深度剖析【根据中国移动研究院文献分析总结】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





