本文主要是介绍多模态大模型训练数据以及微调数据格式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多模态数据,尤其是中文多模态数据,找一些中文多模态的数据
中文多模态数据集汇总_数据集-阿里云天池本文整理汇总了业界常用的多模态中文数据集,提供了每个数据集的简介、官网、下载地址、Github代码等信息,方便算法研究人员学习研究。![]() https://tianchi.aliyun.com/dataset/145784
https://tianchi.aliyun.com/dataset/145784
LMM 视觉描述(Captioning)和定位(Grounding)数据集本文介绍了 Visual Captioning 和 Visual Grounding 的相关概念、细分领域,然后具体介绍了相关的常见评估集,比如 COCO Caption、NoCaps、Flickr30KRefCOCO等。![]() https://mp.weixin.qq.com/s?__biz=Mzk0ODU3MjcxNA==&mid=2247484571&idx=1&sn=0105194bd7493c33fd8d53be97f688b7&chksm=c364c3def4134ac8512d1d64c7e789e1edabe48e347652c73dc32492cec5627fbdb88cd2eaff&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=Mzk0ODU3MjcxNA==&mid=2247484571&idx=1&sn=0105194bd7493c33fd8d53be97f688b7&chksm=c364c3def4134ac8512d1d64c7e789e1edabe48e347652c73dc32492cec5627fbdb88cd2eaff&scene=21#wechat_redirect
LMM 视觉问答(VQA)数据集解读本文整理了常用的 VQA 评估集,分为两类,一类是通用型 VQA(General VQA),也就是直接基于图像来问题;另一类是文本导向的 VQA(Text-Oriented VQA),以便了解各个评估集的具体内容和相应的应用场景。![]() https://mp.weixin.qq.com/s?__biz=Mzk0ODU3MjcxNA==&mid=2247484515&idx=1&sn=94b77ab783e903632c83a952a85a4c3c&chksm=c364c326f4134a30c59e9fe1a5a93e030cebb5a893108677d3209e1c17a06c7b7bf4e16d8c51&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=Mzk0ODU3MjcxNA==&mid=2247484515&idx=1&sn=94b77ab783e903632c83a952a85a4c3c&chksm=c364c326f4134a30c59e9fe1a5a93e030cebb5a893108677d3209e1c17a06c7b7bf4e16d8c51&scene=21#wechat_redirect
GitHub - BradyFU/Awesome-Multimodal-Large-Language-Models: :sparkles::sparkles:Latest Papers and Datasets on Multimodal Large Language Models, and Their Evaluation.:sparkles::sparkles:Latest Papers and Datasets on Multimodal Large Language Models, and Their Evaluation. - BradyFU/Awesome-Multimodal-Large-Language-Models![]() https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models?tab=readme-ov-file#awesome-datasets
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models?tab=readme-ov-file#awesome-datasets

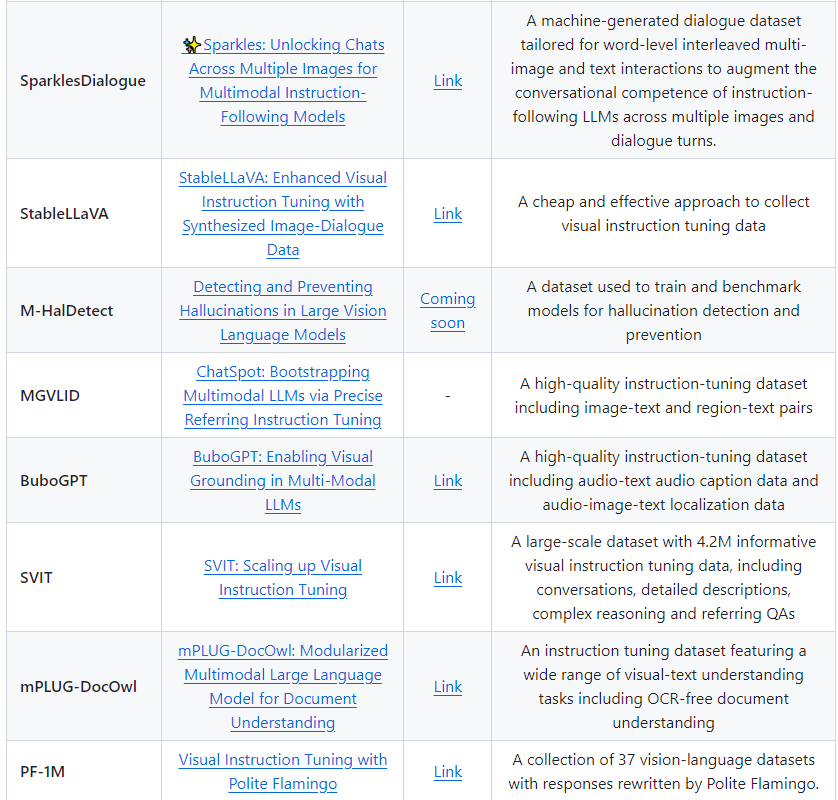
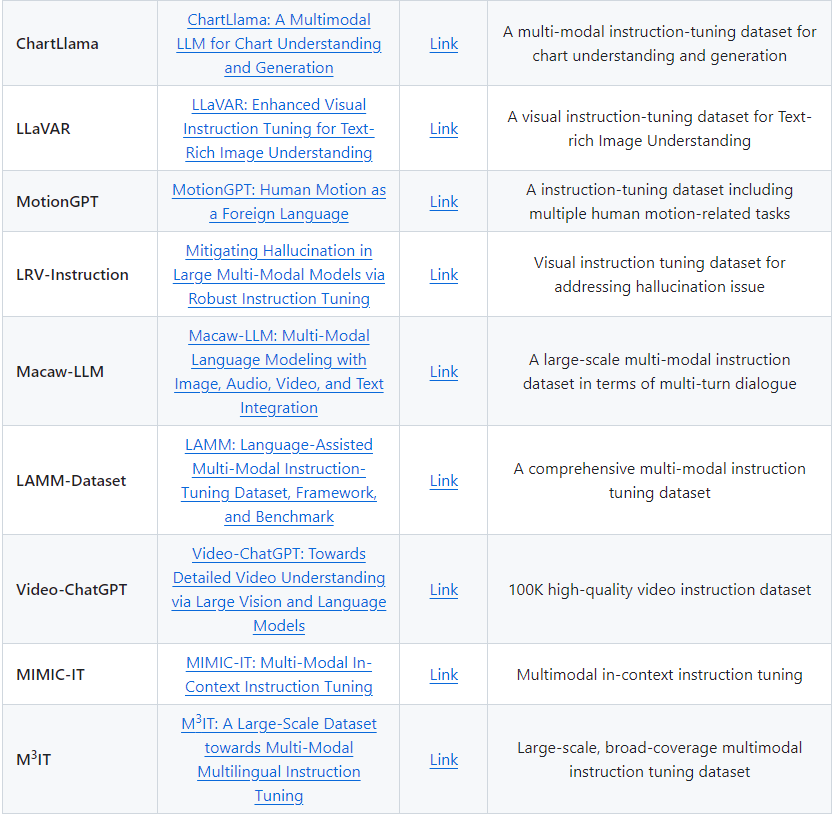
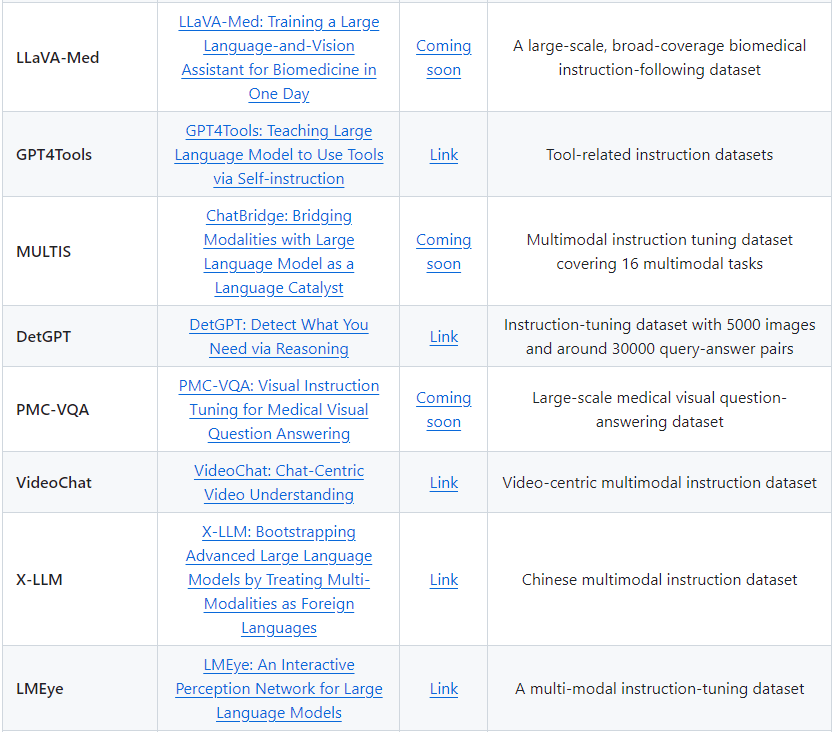
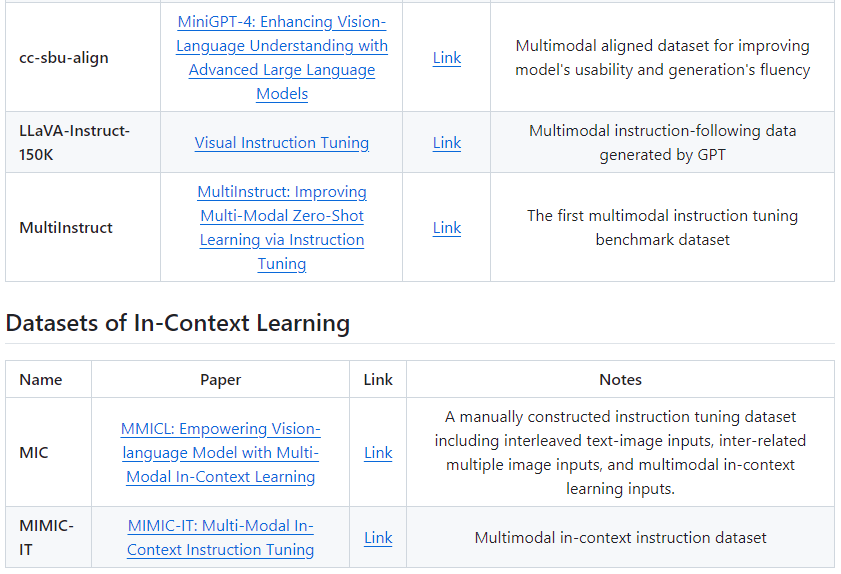

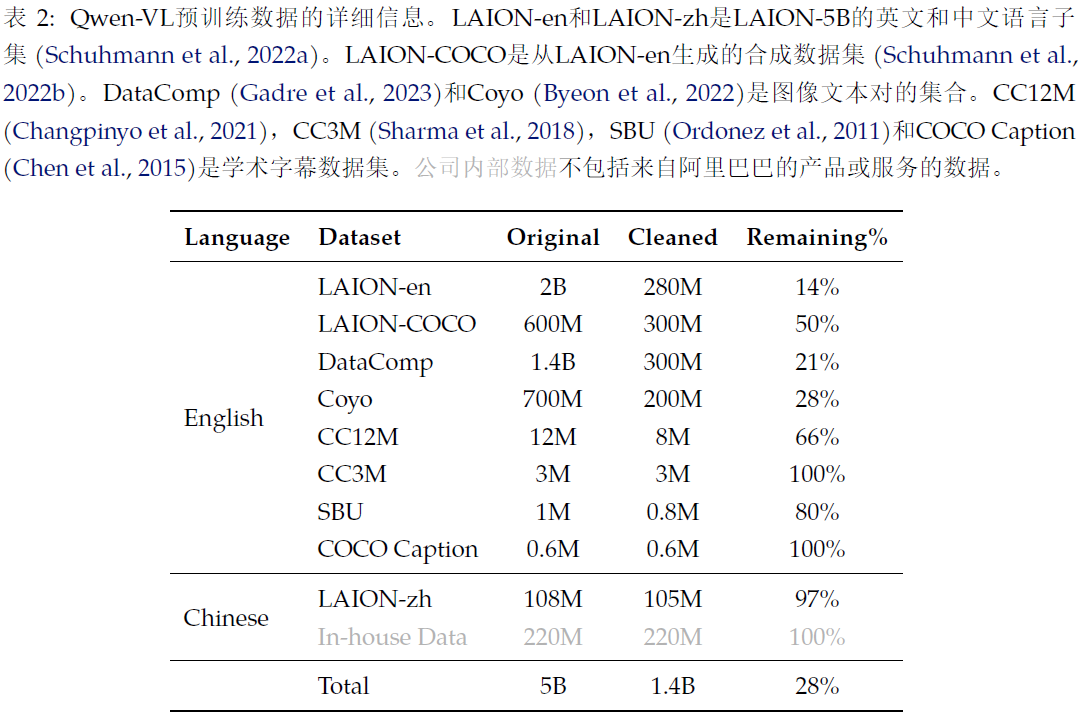

1.XrayGLM
https://github.com/WangRongsheng/XrayGLM![]() https://github.com/WangRongsheng/XrayGLM6423张Xray图片,
https://github.com/WangRongsheng/XrayGLM6423张Xray图片,
2.sharegpt4v
用的gpt4v标注的多模态数据,1.2M
InternLM-XComposer/projects/ShareGPT4V/docs/Data.md at main · InternLM/InternLM-XComposer · GitHubInternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) excelling in free-form text-image composition and comprehension. - InternLM-XComposer/projects/ShareGPT4V/docs/Data.md at main · InternLM/InternLM-XComposer![]() https://github.com/InternLM/InternLM-XComposer/blob/main/projects/ShareGPT4V/docs/Data.md3.wukong
https://github.com/InternLM/InternLM-XComposer/blob/main/projects/ShareGPT4V/docs/Data.md3.wukong
4.zero-chinese
5.laion-2b-chinese
数据格式:
这里llava格式是应用最为广泛的,除了qwen-vl系列,几乎所有的系列都是llava格式。
1.InternLM-VL
InternLM-XComposer/finetune/README_zh-CN.md at main · InternLM/InternLM-XComposer · GitHubInternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) excelling in free-form text-image composition and comprehension. - InternLM-XComposer/finetune/README_zh-CN.md at main · InternLM/InternLM-XComposer![]() https://github.com/InternLM/InternLM-XComposer/blob/main/finetune/README_zh-CN.md2.QWEN-VL
https://github.com/InternLM/InternLM-XComposer/blob/main/finetune/README_zh-CN.md2.QWEN-VL
Qwen-VL/README_CN.md at master · QwenLM/Qwen-VL · GitHubThe official repo of Qwen-VL (通义千问-VL) chat & pretrained large vision language model proposed by Alibaba Cloud. - Qwen-VL/README_CN.md at master · QwenLM/Qwen-VL![]() https://github.com/QwenLM/Qwen-VL/blob/master/README_CN.md
https://github.com/QwenLM/Qwen-VL/blob/master/README_CN.md
[{"id": "identity_0","conversations": [{"from": "user","value": "你好"},{"from": "assistant","value": "我是Qwen-VL,一个支持视觉输入的大模型。"}]},{"id": "identity_1","conversations": [{"from": "user","value": "Picture 1: <img>https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg</img>\n图中的狗是什么品种?"},{"from": "assistant","value": "图中是一只拉布拉多犬。"},{"from": "user","value": "框出图中的格子衬衫"},{"from": "assistant","value": "<ref>格子衬衫</ref><box>(588,499),(725,789)</box>"}]},{ "id": "identity_2","conversations": [{"from": "user","value": "Picture 1: <img>assets/mm_tutorial/Chongqing.jpeg</img>\nPicture 2: <img>assets/mm_tutorial/Beijing.jpeg</img>\n图中都是哪"},{"from": "assistant","value": "第一张图片是重庆的城市天际线,第二张图片是北京的天际线。"}]}
]3. swift中的数据格式
qwen:
[{"conversations": [{"from": "user", "value": "Picture 1:<img>img_path</img>\n11111"},{"from": "assistant", "value": "22222"}]},{"conversations": [{"from": "user", "value": "Picture 1:<img>img_path</img>\nPicture 2:<img>img_path2</img>\nPicture 3:<img>img_path3</img>\naaaaa"},{"from": "assistant", "value": "bbbbb"},{"from": "user", "value": "Picture 1:<img>img_path</img>\nccccc"},{"from": "assistant", "value": "ddddd"}]},{"conversations": [{"from": "user", "value": "AAAAA"},{"from": "assistant", "value": "BBBBB"},{"from": "user", "value": "CCCCC"},{"from": "assistant", "value": "DDDDD"}]}
]4.bunny
{
'id': '0',
'image': 'coco_2017/000000337760.jpg',
'conversations': [{'from': 'human', 'value': '<image>\n这是一辆现代消防车吗?\n请用单个短语回答问题。'}, {'from': 'gpt', 'value': '不'}, {'from': 'human', 'value': '这张照片是黑白的还是彩色的?'}, {'from': 'gpt', 'value': '黑白的'}, {'from': 'human', 'value': '图中显示了哪些车辆?'}, {'from': 'gpt', 'value': '消防车'}
]
}5.visualglm
[{"img": "fewshot-data/2p.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是蒙蒙细雨。"},{"img": "fewshot-data/pig.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是是虚化的。"},{"img": "fewshot-data/meme.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是蓝色的木质地板。"},{"img": "fewshot-data/passport.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是棕黄色木质桌子。"},{"img": "fewshot-data/tower.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是黄昏的天空、云彩和繁华的城市高楼。"},{"img": "fewshot-data/rub.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是太阳、大树、蓝天白云。"},{"img": "fewshot-data/push.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是蓝天和沙漠。"},{"img": "fewshot-data/traf.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是城市街道。"},{"img": "fewshot-data/music.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是一个音乐混音器。"},{"img": "fewshot-data/pattern.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是小区的楼房和街道。"},{"img": "fewshot-data/rou.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是大理石桌子和一个盘子。"},{"img": "fewshot-data/katong.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是绿色的草地。"},{"img": "fewshot-data/man.jpg", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是城市的街道和高楼。"},{"img": "fewshot-data/kobe.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是虚化的观众席。"},{"img": "fewshot-data/panda.jpg", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是纯白的。"},{"img": "fewshot-data/titan.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是一座雕像。"},{"img": "fewshot-data/woman.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是纯蓝的。"},{"img": "fewshot-data/ghost.jpg", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是一个房间。"},{"img": "fewshot-data/justice.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是天空和阳光。"},{"img": "fewshot-data/tianye.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是金黄的田野。"}
]这篇关于多模态大模型训练数据以及微调数据格式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!