本文主要是介绍Flattened Butterfly 扁平蝶形拓扑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- Flattened Butterfly 扁平蝶形拓扑
- 1. 传统蝶形网络 Butterfly Topology
- 2. 扁平蝶形拓扑 Flattened Butterfly
- 3.On-Chip Flattened Butterfly 扁平蝶形拓扑应用于片上网络
Flattened Butterfly 扁平蝶形拓扑
扁平蝶形拓扑是一种经济高效的拓扑,适用于高基数路由器。扁平蝶形是通过组合(或扁平化)传统蝶形拓扑每行中的路由器而得到的一种拓扑,同时保留路由器间的连接。
1. Butterfly Topology 传统蝶形网络
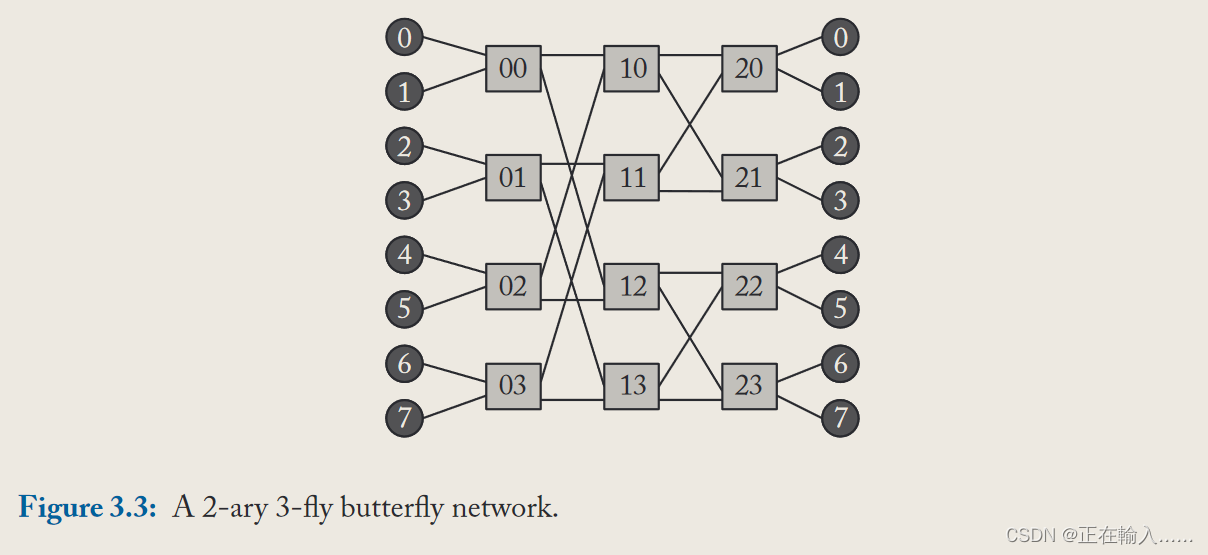
传统蝶形网络可以描述为k-ary n-fly。该网络拥有kn**个终端节点,有**n级**交换节点,每级含**k(n-1)个kxk的交换节点。即k为交换节点的出入度或者度的一半。如上图所示,展示了一个2-ary 3-fly的蝶形网络。
蝶形网络中源节点到目标节点的跳数不会变化,始终是n-1(在系统实现中,终端节点和相邻的交换节点往往集成在一起,故跳数只计算交换网络中的跳数)。在流量均匀分布的情况下蝶形网络的最大通道负载是1,所以网络的最大注入带宽也为1flit/node/cycle。其他不均匀的如从网络一端发送到另一端的流量会增大负载,从而减小最大注入带宽。
蝶形网络的最大缺点就是缺失了路径多样性并缺少对网络局部性的利用。缺失路径多样性使得蝶形网络在非平衡流量模式下性能很差,而缺少局部性的利用在于未利用源节点到目标节点相邻或距离较近的情况下,拓扑进行了绕远。
2. Flattened Butterfly 扁平蝶形拓扑
**扁平蝶形拓扑(Flattened Butterfly)**将同一行中的中间交换节点合并成一个交换节点,从而将非直连拓扑转换为直连拓扑。
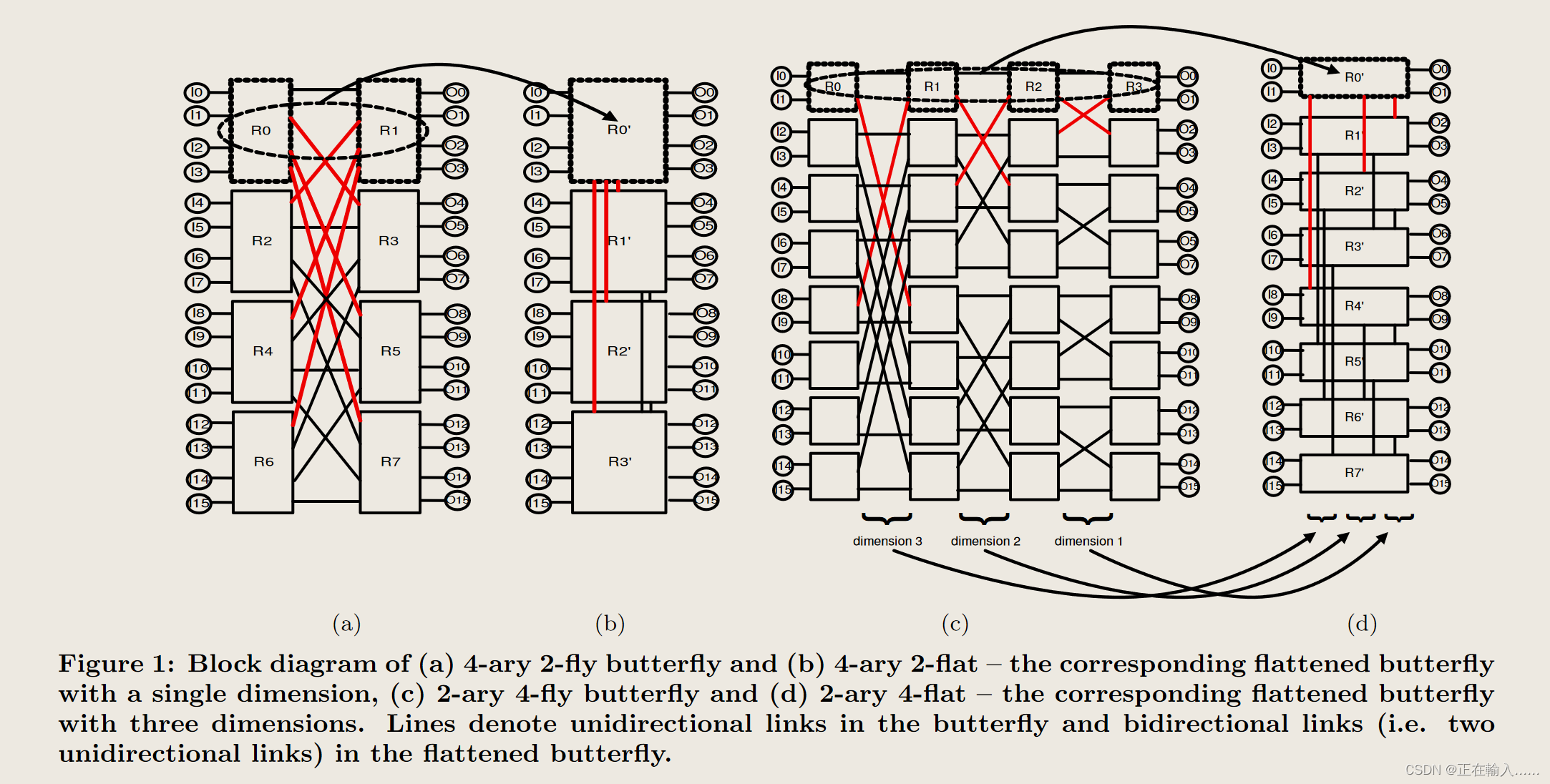
如上图所示,由 4-ary 2-fly 的蝶形网络转换为 4-ary 2-fly 的扁平蝶形网络 以及 由 2-ary 4-fly 的蝶形网络转换为 4-ary 2-fly 的扁平蝶形网络。
图1(a)第一行的路由器R0和R1组合成图1(b)扁平化蝶形拓扑中的单个路由R0’。类似地,图1©的路由器R0、R1、R2和R3被组合成图1(d)的R0’。当一行路由器组合在一起时,完全位于该行本地的通道(例如图 1(a) 中的通道 (R0,R1))将被消除(因为组合而成的路由器的内部可以进行同一行的通信),而其他的所有通道都被保留在扁平蝶形中。例如,图1(a)中的通道(R0,R3)变为图1(b)中的通道(R0’,R1’)。由于扁平蝶形结构中的通道是对称的,因此图 1(b,d) 中的每条线代表一个双向通道(即两个单向通道),而图 1(a,c) 中的每条线代表一个单向通道。
k-ary n-flat是从 k-ary n-fly 蝶形网络衍生而来的扁平蝶形,由N/k(N^(k-1))个(中间路由器的个数),基数为k’=n(k-1)+1(一侧的终端个数再加上中间路由器与其他路由器的连接)的路由器组成,N为网络的大小(一侧的终端节点个数)。
传统蝶形网络中n-1为不同的列,代表不同的dimension,而在扁平蝶形网络中,路由器同样通过n’ = n-1维度的通道连接,对应于蝶形网络中的n-1列路由。每个维度d中,从1到n’,路由器i连接到路由器j:
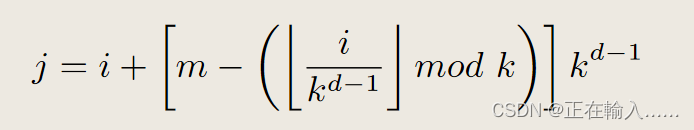
例如,在图 1(d) 中,R4’ 在维度 1 中连接到 R5’,在维度 2 中连接到 R6’,在维度 3 中连接到 R0’。图 2 中,扁平蝶形结构中的节点数量 (N ) 被绘制为维数 n’ 和交换机基数 k’ 的函数。该图显示该拓扑仅适用于高基数路由器。可以使用低基数路由器 (k′ < 16) 构建规模非常有限的网络,即使 k′ = 32,也需要许多维度才能扩展到大型网络规模。然而,当 k′ = 61 时,只有三个维度的网络可以扩展到 64K 个节点。
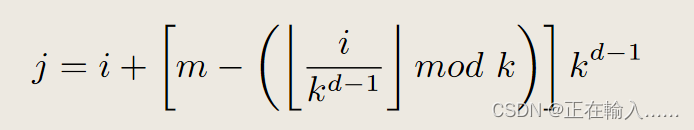
3. On-Chip Flattened Butterfly 扁平蝶形拓扑应用于片上网络
John Kim, James Balfour, and William J. Dally将扁平蝶形拓扑应用于片上网络。
通过集中在路由器中,扁平蝶形结构显着降低了拓扑的布线复杂性,使其能够更有效地扩展。为了将 64 节点片上网络映射到扁平化蝴蝶拓扑上,折叠了4-ary 3-fly的蝶形网络以生成如图 3(a) 所示的扁平化蝴蝶网络。由此产生的扁平蝴蝶有 2 个维度并使用 radix-10 路由器。每个路由器连接四个处理器节点,因此路由器的集中系数为 4。其余 6 个路由器端口用于路由器间连接:3 个端口用于维度 1 连接,3 个端口用于维度 2 连接连接。路由器的放置如图 3(b) 所示,将拓扑嵌入到平面 VLSI 布局中,每个路由器放置在 4 个处理节点的中间。维度1连接的路由器水平对齐,维度2连接的路由器垂直对齐;因此,行内的路由器是完全连接的,列内的路由器也是完全连接的。
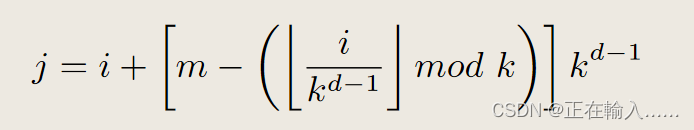
与数据包源和目的地之间的曼哈顿距离相关的线路延迟是了片上网络传输所需的延迟的下限。当使用最小路由时,这个扁平化蝴蝶网络中的处理器仅相隔 2 跳,这比 2-D 网格的跳数有显着改进。扁平蝶形尝试通过减少中间路由器的数量来接近线路延迟界限,这不仅可以降低延迟,还可以降低能耗。然而,扁平化蝶形网络中连接远程路由器的电线必然比网状网络中的电线更长。通过最佳地插入中继器和流水线寄存器来保留通道带宽,同时容忍可能是几个周期的通道遍历时间,可以很容易地减少长导线对性能的不利影响。较长的通道还需要更深的缓冲区大小来覆盖信用往返延迟,以维持完整的吞吐量。
References:
[1] J. Kim, J. Balfour, and W. Dally, “Flattened Butterfly Topology for On-Chip Networks,” in 40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2007), Chicago, IL, USA: IEEE, 2007, pp. 172–182. doi: 10.1109/MICRO.2007.29.
[2] J. Kim, W. J. Dally, and D. Abts, “Flattened Butterfly : A Cost-Efficient Topology for High-Radix Networks,” 2007.
这篇关于Flattened Butterfly 扁平蝶形拓扑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!