本文主要是介绍四、事务拓扑(Transactional Topolgoy),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、问题的提出
怎样做到每个出错的tuple只被处理一次?这样才能统计所有发射出的tuple的数量。
2、简介
Storm 0.7.0引入了Transactional Topology, 它可以保证每个tuple”被且仅被处理一次”, 这样你就可以实现一种非常准确,非常可扩展,并且高度容错方式来实现计数类应用。跟DRPC类似, transactional topology其实不能算是storm的一个特性,它其实是用storm的底层原语spout, bolt, topology, stream等等抽象出来的一个特性。
3、三个设计<1>强顺序流:顺序id的tuple+数据库
比如你想统一个stream里面tuple的总数。那么为了保证统计数字的准确性,你在数据库里面不但要保存tuple的个数, 还要保存这个数字所对应的最新的transaction id。 当你的代码要到数据库里面去更新这个数字的时候,你要判断只有当新的transaction id跟数据库里面保存的transaction id不一样的时候才去更新。考虑两种情况:
- 数据库里面的transaction id跟当前的transaction id不一样: 由于我们transaction的强顺序性,我们知道当前的tuple肯定没有统计在数据库里面。所以我们可以安全地递增这个数字,并且更新这个transaction id.
- 数据库里面的transaction id一样: 那么我们知道当前tuple已经统计在数据库里面了,那么可以忽略这个更新。这个tuple肯定之前在更新了数据库之后,反馈给storm的时候失败了(ack超时之类的)。
给整个batch一个transaction id,batch与batch之间的处理是强顺序性的, 而batch内部是可以并行的
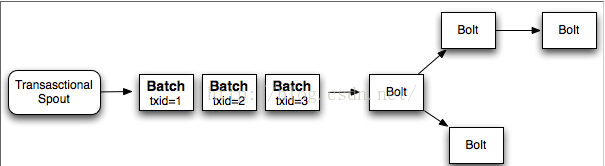
优点: 减少数据库调用;利用了storm的并行计算能力(每个batch内部可以并行)
缺点:考虑下面这个topology

在bolt 1完成它的处理之后, 它需要等待剩下的bolt去处理当前batch, 直到发射下一个batch
<3>storm的设计
- processing阶段: 这个阶段很多batch可以并行计算。
- commit阶段: 这个阶段各个batch之间需要有强顺序性的保证。所以第二个batch必须要在第一个batch成功提交之后才能提交。
4、例子
源代码如下:
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.coordination.BatchOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.testing.MemoryTransactionalSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBatchBolt;
import backtype.storm.topology.base.BaseTransactionalBolt;
import backtype.storm.transactional.ICommitter;
import backtype.storm.transactional.TransactionAttempt;
import backtype.storm.transactional.TransactionalTopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;public class TransactionalGlobalCount {public static final int PARTITION_TAKE_PER_BATCH=3;public static final Map<Integer,List<List<Object>>> DATA=new HashMap<Integer, List<List<Object>>>(){{put(0,new ArrayList<List<Object>>(){{add(new Values("cat"));add(new Values("dog"));add(new Values("chicken"));add(new Values("cat"));add(new Values("dog"));add(new Values("apple"));}});put(1,new ArrayList<List<Object>>(){{add(new Values("cat"));add(new Values("dog"));add(new Values("apple"));add(new Values("banana"));}});put(2,new ArrayList<List<Object>>(){{add(new Values("cat"));add(new Values("cat"));add(new Values("cat"));add(new Values("cat"));add(new Values("cat"));add(new Values("dog"));add(new Values("dog"));add(new Values("dog"));add(new Values("dog"));}});}};public static class Value{int count=0;BigInteger txid;}public static Map<String, Value> DATABASE=new HashMap<String, Value>();public static final String GLOBAL_COUNT_KEY="GLOBAL-COUNT";public static class BatchCount extends BaseBatchBolt{Object _id;BatchOutputCollector _collector;int _count=0;@Overridepublic void prepare(Map conf, TopologyContext context,BatchOutputCollector collector, Object id) {// TODO Auto-generated method stub_collector=collector;_id=id;}@Overridepublic void execute(Tuple tuple) {// TODO Auto-generated method stub_count++;}@Overridepublic void finishBatch() {// TODO Auto-generated method stub_collector.emit(new Values(_id,_count));}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {// TODO Auto-generated method stubdeclarer.declare(new Fields("id","count"));}}public static class UpdateGlobalCount extends BaseTransactionalBolt implements ICommitter {TransactionAttempt _attempt;BatchOutputCollector _collector;int _sum = 0;@Overridepublic void prepare(Map conf,TopologyContext context,BatchOutputCollector collector,TransactionAttempt attempt) {_collector = collector;_attempt = attempt;}@Overridepublic void execute(Tuple tuple) {_sum+=tuple.getInteger(1);}@Overridepublic void finishBatch() {Value val = DATABASE.get(GLOBAL_COUNT_KEY);Value newval;if(val == null ||!val.txid.equals(_attempt.getTransactionId())) {newval = new Value();newval.txid = _attempt.getTransactionId();if(val==null) {newval.count = _sum;} else {newval.count = _sum + val.count;}DATABASE.put(GLOBAL_COUNT_KEY, newval);} else {newval = val;}_collector.emit(new Values(_attempt, newval.count));System.out.println(_attempt);System.out.println(newval.count);}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("id", "sum"));}}public static void main(String[] args) throws InterruptedException {// TODO Auto-generated method stubMemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA, new Fields("word"), PARTITION_TAKE_PER_BATCH);TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("global-count", "spout", spout, 3);builder.setBolt("partial-count", new BatchCount(), 5).shuffleGrouping("spout");builder.setBolt("sum", new UpdateGlobalCount()).globalGrouping("partial-count");LocalCluster cluster=new LocalCluster();Config config=new Config();config.setDebug(true);config.setMaxSpoutPending(3);cluster.submitTopology("global-count-topology", config, builder.buildTopology());Thread.sleep(3000);cluster.shutdown();}
}详解如下:
<1>构建Topology
MemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA, new Fields("word"), PARTITION_TAKE_PER_BATCH);TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("global-count", "spout", spout, 3);builder.setBolt("partial-count", new BatchCount(), 5).shuffleGrouping("spout");builder.setBolt("sum", new UpdateGlobalCount()).globalGrouping("partial-count");</span> TransactionalTopologyBuilder接受如下的参数
- 这个transaction topology的id
- spout在整个topology里面的id。
- 一个transactional spout。
- 一个可选的这个transactional spout的并行度。
一个transaction topology里面有一个唯一的TransactionalSpout, 这个spout是通过TransactionalTopologyBuilder的构造函数来制定的。在这个例子里面,MemoryTransactionalSpout被用来从一个内存变量里面读取数据(DATA)。第二个参数制定数据的fields, 第三个参数指定每个batch的最大tuple数量。
<2>第一个bolt:BatchBolt:随机地把输入tuple分给各个task,然后各个task各自统计局部数量
public static class BatchCount extends BaseBatchBolt{Object _id;BatchOutputCollector _collector;int _count=0;@Overridepublic void prepare(Map conf, TopologyContext context,BatchOutputCollector collector, Object id) {// TODO Auto-generated method stub_id=id;}@Overridepublic void execute(Tuple tuple) {// TODO Auto-generated method stub_count++;}@Overridepublic void finishBatch() {// TODO Auto-generated method stub_collector.emit(new Values(_id,_count));}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {// TODO Auto-generated method stubdeclarer.declare(new Fields("id","count"));}} storm会为每个batch创建这个一个BatchCount对象。而这些BatchCount是运行在BatchBoltExecutor里面的。
这个对象的prepare方法接收如下参数:
- 包含storm config信息的map。
- TopologyContext
- OutputCollector
- 这个batch的id。而在Transactional Topologies里面, 这个id则是一个TransactionAttempt对象。
在transaction topology里面发射的所有的tuple都必须以TransactionAttempt作为第一个field,然后storm可以根据这个field来判断哪些tuple属于一个batch。所以你在发射tuple的时候需要满足这个条件。TransactionAttempt包含两个值: 一个transaction id,一个attempt id。transaction id的作用就是我们上面介绍的对于每个batch是唯一的,而且不管这个batch replay多少次都是一样的。 我们可以把attempt id理解成replay-times, storm利用这个id来区别一个batch发射的tuple的不同版本。transaction id对于每个batch加一, 所以第一个batch的transaction id是”1″, 第二个batch是”2″,以此类推。execute方法会为batch里面的每个tuple执行一次。最后, 当这个bolt接收到某个batch的所有的tuple之后, finishBatch方法会被调用。这个例子里面的BatchCount类会在这个时候发射它的局部数量到它的输出流里面去。
<3>第二个bolt:UpdateBlobalCount, 用全局grouping来从汇总这个batch的总的数量。然后再把总的数量更新到数据库里面去。
public static class UpdateGlobalCount extends BaseTransactionalBolt implements ICommitter {TransactionAttempt _attempt;BatchOutputCollector _collector;int _sum = 0;@Overridepublic void prepare(Map conf,TopologyContext context,BatchOutputCollector collector,TransactionAttempt attempt) {_collector = collector;_attempt = attempt;}@Overridepublic void execute(Tuple tuple) {_sum+=tuple.getInteger(1);}@Overridepublic void finishBatch() {Value val = DATABASE.get(GLOBAL_COUNT_KEY);Value newval;if(val == null ||!val.txid.equals(_attempt.getTransactionId())) {newval = new Value();newval.txid = _attempt.getTransactionId();if(val==null) {newval.count = _sum;} else {newval.count = _sum + val.count;}DATABASE.put(GLOBAL_COUNT_KEY, newval);} else {newval = val;}_collector.emit(new Values(_attempt, newval.count));} UpdateGlobalCount是Transactional Topologies相关的类, 所以它继承自BaseTransactionalBolt。在execute方法里面, UpdateGlobalCount累积这个batch的计数, 比较有趣的是finishBatch方法。首先, 注意这个bolt实现了ICommitter接口。这告诉storm要在这个事务的commit阶段调用finishBatch方法。所以对于finishBatch的调用会保证强顺序性(顺序就是transaction id的升序), 而相对来说execute方法在任何时候都可以执行,processing或者commit阶段都可以。UpdateGlobalCount里面finishBatch方法的逻辑是首先从数据库中获取当前的值,并且把数据库里面的transaction id与当前这个batch的transaction id进行比较。如果他们一样, 那么忽略这个batch。否则把这个batch的结果加到总结果里面去,并且更新数据库。
这篇关于四、事务拓扑(Transactional Topolgoy)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





