本文主要是介绍如何应对MySQL单表数据量过大:垂直分表与水平分表策略解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
话接上回,单表最大数据建议两千万,那如果开发一个项目,预计注册量达到一个亿怎么办。
单表内放这么多数据,MYSQL底层B+树的层级结构就可能会变得很高,磁盘io次数变多,性能会大幅度降低。所以考虑数据库分表。
这里的分表分为垂直分表和水平分表两种。
垂直分表:
原理比较简单,一般就是把某几列拆成一个新表,这样原来的表就小了,拆几列出去,那数据表里的每行数据就会变少,单个16K数据页就能放入越多的行数,这样发生查询时需要的数据页就会越少,那磁盘IO也会越少,所以性能就会越快。
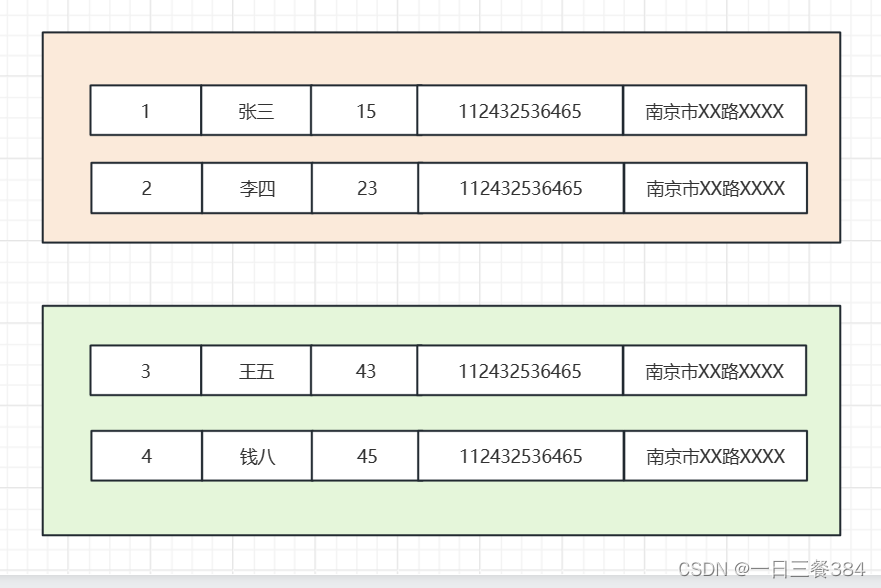
水平分表:
水平分表有好几种做法,但不管是哪种,本质上都是将原来的user表变成USER0到user_n这样的N张小,每一张小表里只保存了一部分数据,一般是500万到2000万。
第一种:根据ID取模分表
假设我们一共分了两张表,分别是user_0和user_1,此时模等于2,我们将输入的ID与模进行求余数操,如ID=2,4,6的时候,会被写到user_0这张表。ID=1,3,5和2取模得到1,于是就能知道应该写到user_1这张表里。
优点:
比较简单
读写数据都可以很均匀的分摊到每个分表上
缺点:如果想要扩展表的个数,比如从两张表变成3张表,那同样还是ID=3的数据,以前3和2取模得到1,所以ID=3的数据会放在USER1表里,现在3和3取模得到0,那就要放在USER0这张表里,跟原来的USER1就对不上了,这就需要考虑数据迁移。
第二种:根据ID范围分表
假设我们每张分表都能存放500万条数据,那user_0就存放ID为1~500万的数,user_1就存放ID在500万到1000万之间的数据。假设现在有条数据,ID=3000万要读写条数据,就需要将3000万除以500万得到6,那就可以知道这条数据属于user_6一表,于是就去读写user_6表就行了。
优点:根据ID范围去分表就能很好的解决ID取模时数据表的扩展问题。
缺点:假设新注册玩家的ID是不断加一的,那么在某段时间内,ID会集中在某个分片范围内,比如在4000万到6000万的范围,数据会不断写入这个特定的分表中,并没有起到分摊数据读写压力的效果,这就是所谓的读写热点问题。解决读写热点问题最简单的方案就是让ID变得随机,这样ID就能随机分散到所有表上,分摊读写压力。
推荐一位优秀的up主:小白debug的个人空间-小白debug个人主页-哔哩哔哩视频 (bilibili.com)
这篇关于如何应对MySQL单表数据量过大:垂直分表与水平分表策略解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





