量过大专题

zm-tree-org 数据量过大时,全部展开后,根节点点击收缩,树形消失
zm-tree-org 数据量过大时,全部展开后,根节点点击收缩,树形消失 <zm-tree-orgref="tree"@on-expand="onExpand"</zm-tree-org>export default {methods: {onExpand(e, data) {<!-- 当为根节点,且根节点为闭合时 -->if (data.root === true && data.expa

mysql批量插入数据量过大报错两种解决办法
Packet for query is too large (6071393 > 4194304). You can change this value on the server by setting the max_allowed_packet’ variable. 方式一: 批量插入数据量过大,解决办法 修改 my.ini 加上 max_allowed_packet =67108864 6

程序员面试之MySQL索引失效,索引失效的原因可能有多种,表数据量过大,当表中的数据量过大时,即使有合适的索引,MySQL仍可能选择全表扫描的方式进行查询,从而导致索引失效,实际情况还可能有其他因素
AI:please wait… MySQL索引失效的原因可能有多种,以下是一些常见的原因: 索引选择性不好:索引的选择性是指索引中不同值的个数与表中记录数的比值。如果索引选择性较差,即不同值较少,那么使用该索引进行查询可能会导致大量的数据读取,进而导致索引失效。索引列类型不匹配:如果索引列的数据类型与查询条件中的数据类型不匹配,那么MySQL可能无法使用该索引进行查询,从而导致索引失效。表数据量
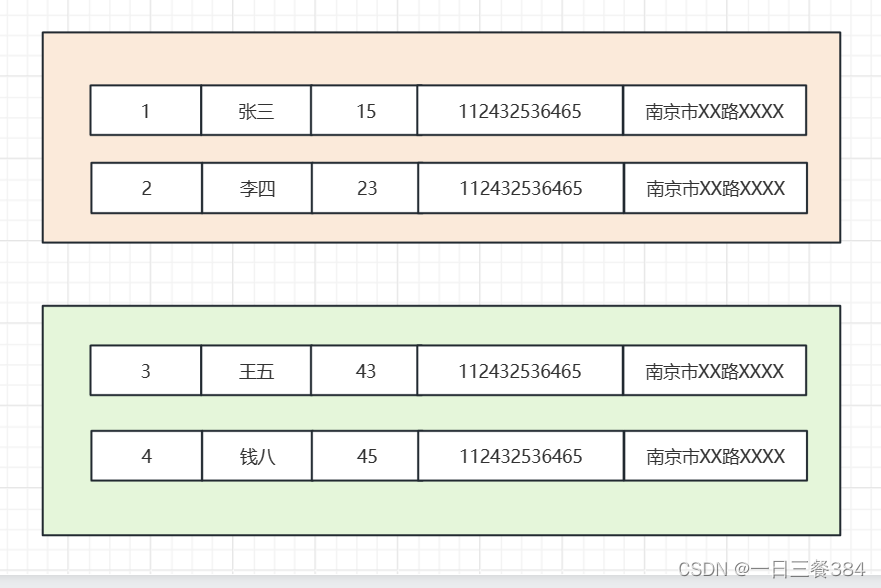
如何应对MySQL单表数据量过大:垂直分表与水平分表策略解析
话接上回,单表最大数据建议两千万,那如果开发一个项目,预计注册量达到一个亿怎么办。 单表内放这么多数据,MYSQL底层B+树的层级结构就可能会变得很高,磁盘io次数变多,性能会大幅度降低。所以考虑数据库分表。 这里的分表分为垂直分表和水平分表两种。 垂直分表: 原理比较简单,一般就是把某几列拆成一个新表,这样原来的表就小了,拆几列出去,那数据表里的每行数据就会变少,单个16K数据页就能
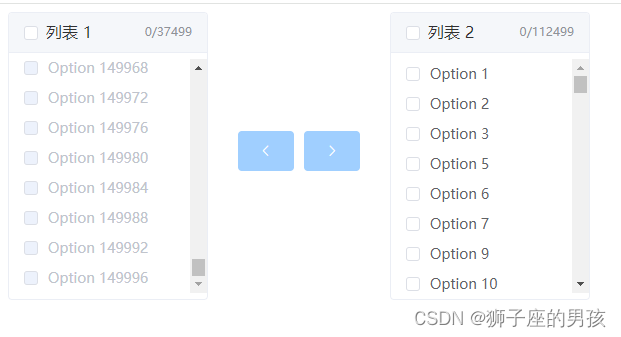
(Transfer)解决:Element-ui 中 Transfer 穿梭框因数据量过大而渲染卡顿问题的三种方法
解决 Transfer 穿梭框卡顿问题: Ⅰ、Element-ui 提供的 Transfer 组件信息:1、Transfer 组件代码:2、运行页面截图: Ⅱ、存在的问题:1、页面卡顿的描述: Ⅲ、解决卡顿的方案一:1、采用定时器的方法:2、代码为:3、页面展示为: Ⅳ、解决卡顿的方案二(懒加载):1、需要将 element-ui 的 transfer 的组件拉出来进行二次封装:2、代码为:

Echarts 添加横轴伸缩功能,并解决数据量过大情况下伸缩看起来错位问题,以及横坐标设置不同颜色,滑动时候文字颜色样式错位问题
原有基础横轴伸缩功能 关键代码 dataZoom: [{type: 'inside',start: 0,end: 10},{start: 0,end: 10}], 完整代码,可以放到官方DEMO测试 myData = {nameData: [ // 橫坐標顯示的值'TEST-數據名字01','TEST-數據名字02','TEST-數據名字03','TEST-數據名字04','TEST

el-transfer 数据量过大加载慢卡顿解决办法:el-transfer虚拟滚动懒加载的实现
参考链接 1)https://github.com/GreenHandLittleWhite/blog/issues/152)https://github.com/GreenHandLittleWhite/blog/tree/master/el-virtual-transfer3)https://github.com/raintoway/element/tree/sum 其他可参考项 1)
Elasticsearch单个索引数据量过大的优化
当Elasticsearch(ES)中的单个索引(index)的数据量变得过大时,可能会遇到性能下降、查询缓慢、管理困难等问题。为了优化和应对大索引的挑战,可以考虑以下策略: 1. 使用分片和副本 分片(Sharding):ES自动将索引分成多个分片,分布式地存储和处理数据。对于大型索引,可以在创建时指定更多的主分片数量,以平衡数据和查询的负载。不过,一旦索引创建,其主分片的数量就不能更改,因此

大数据日志数据量过大如何处理
如果是web端的埋点数据,我们可以对这些数据进行分流。 我们可以采用事件分流,步骤如下 定义事件类型: 根据埋点数据的内容,定义不同的事件类型。例如,可以有页面访问事件、按钮点击事件、表单提交事件等。 提取关键信息: 从埋点数据中提取关键的信息,用于确定事件类型以及其他可能用于分流的属性。这可能涉及到解析日志、提取特定字段或属性等操作。 制定分流规则: 基于提取的信息,制定分流规则。例如
sql导出excel数据量过大的处理(需解决)
提示: Microsoft OLE DB Provider for SQL Server 错误 '80040e14' 链接服务器"(null)"的 OLE DB 访问接口 "Microsoft.ACE.OLEDB.12.0" 返回了消息 "电子 数据表满。" 有时间需要查找解决方法。
easyexcel 数据量过大问题
java总的生成excel工具 poi太费事了,于是就是用来 阿里提供的 easyexcel 很简单, 具体使用方式参考: https://zhuanlan.zhihu.com/p/88720415?utm_source=wechat_timeline https://blog.csdn.net/weixin_30533109/article/details/112082439 https

el-tree数据量过大,造成浏览器卡死、崩溃
el-tree数据量过大,造成浏览器卡死、崩溃 场景:树形结构展示,数据超级多,超过万条,每次打开都会崩溃 我这里采用的是引入新的插件虚拟树,它是参照element-plus 中TreeV2改造vue2.x版本虚拟化树形控件,不论你的数据量多大,虚拟树都能毫无压力地处理。 虚拟树传送门:https://sangtian152.github.io/virtual-tree/zh/demo/