本文主要是介绍快手团队长文解读:基于FPGA加速的自动语音识别在大规模直播和短视频场景的应用...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:机器之心
本文约6000字,建议阅读10分钟
本文介绍了基于FPGA加速的自动语音识别在大规模直播和短视频场景的应用。典型的实时流式自动语音识别业务如语音搜索、语音输入等和用户操作相关,直接影响用户体验,最重要的性能指标是延迟,其次是并发路数。TDNN+LSTM 作为一种主流的实时流式声学模型,可以实现低延迟、高并发。本文介绍了快手异构计算与 MMU 音频中心合作的针对 TDNN+LSTM 声学模型的全定点推理硬件加速方案。该方案基于 FPGA,在流式 ASR 服务场景下, 高峰期平均延时减小 37.67 %,并发路数提升 7.5 倍,是 FPGA 在国内大规模数据中心语音场景落地的成功案例之一。
ASR(Automatic Speech Recognition)是自动语音识别技术。ASR 在快手有许多的应用场景,是快手 APP,直播,风控,游戏等众多业务的核心功能,不同服务场景的 ASR 技术指标需求有很大的差别。快手语音识别基本可分为如下:
低延迟、实时流式 ASR:如快手 APP 语音搜索、直播间语音输入法、小快机器人、语音魔法表情、一甜相机实时字幕等;
高精度、高并发、离线 ASR:如直播语音转写、聊天室语音转写、直播连麦 PK、短视频语音转写等。
实时流式业务和用户操作相关,直接影响用户体验,最重要的性能指标是延迟,其次是并发路数。实时流式ASR业务性能优化是本文介绍的目标。
背景
人工智能AI是快手短视频和直播平台的重要使能技术,同时也代表着公司的核心竞争力。当前快手AI基础设施高度依赖INTEL CPU 和NVIDIA GPU这两种通用计算硬件。受业务快速增长的驱动,快手近几年投入了大量人力和资金来扩展AI软硬件基础设施, 也积极地寻找更好的异构计算加速方案,以实现更好的用户体验,同时达到优化增量和存量的目标。
实时流式 ASR 是快手自动语音识别中的核心技术之一。许多创新的实时流式 ASR 应用在快手 APP 直播间,比如直播间的小快机器人 (语音助手) 获得 2019 年 Synced Machine Intelligence Award。现在更普及到多项服务如快手 APP 语音搜索、直播间语音输入法、语音魔法表情、一甜相机实时字幕等,如图一所示。

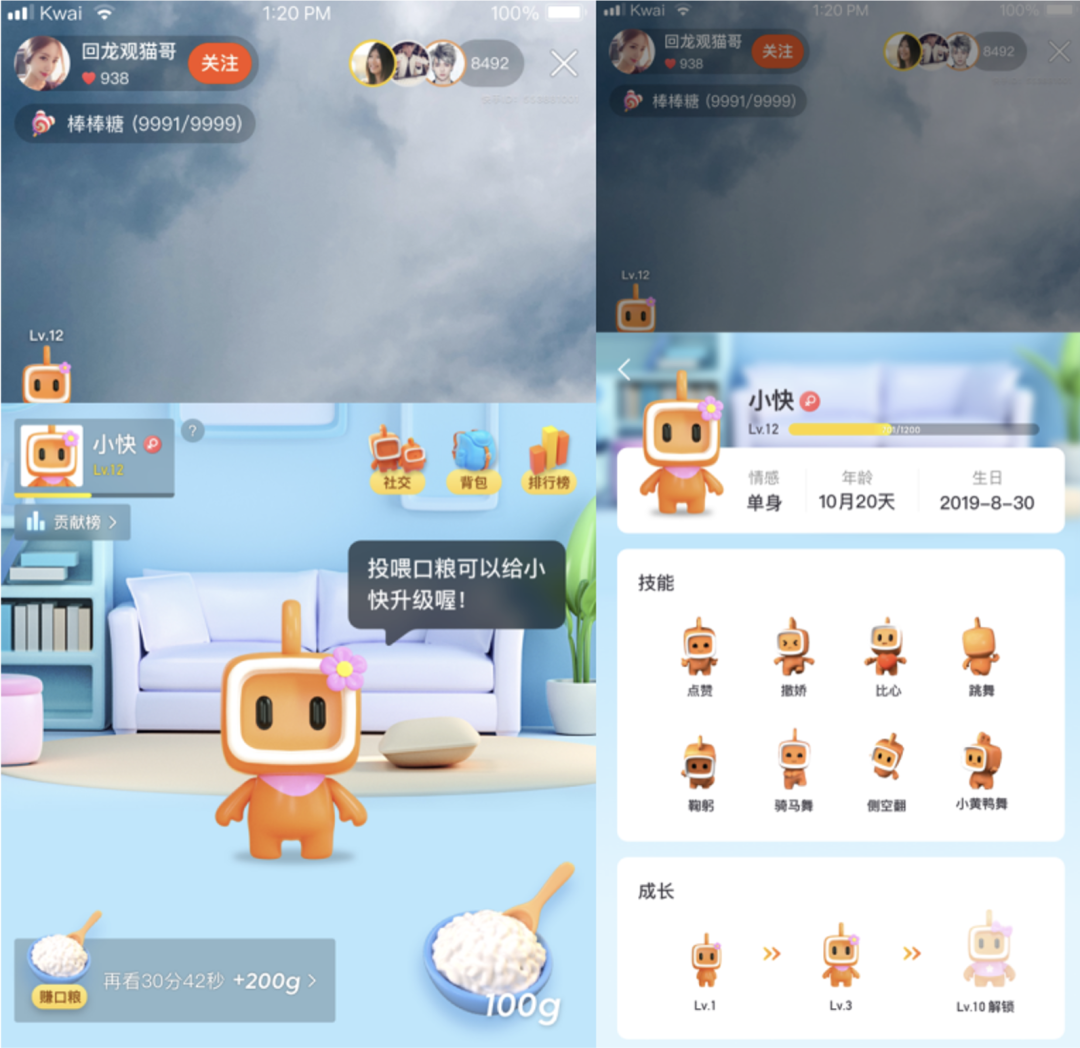
图一:快手实时流式 ASR 应用包含快手 APP 语音搜索、直播间语音输入法、小快机器人、语音魔法表情、一甜相机实时字幕表情等多项服务。
目前快手的流式 ASR 服务整体框架如图二所示,主要包含特征提取、声学模型(Acoustic model, AM)、包含语言模型 (Language model, LM) 的解码器,且都是在 CPU 上运行。
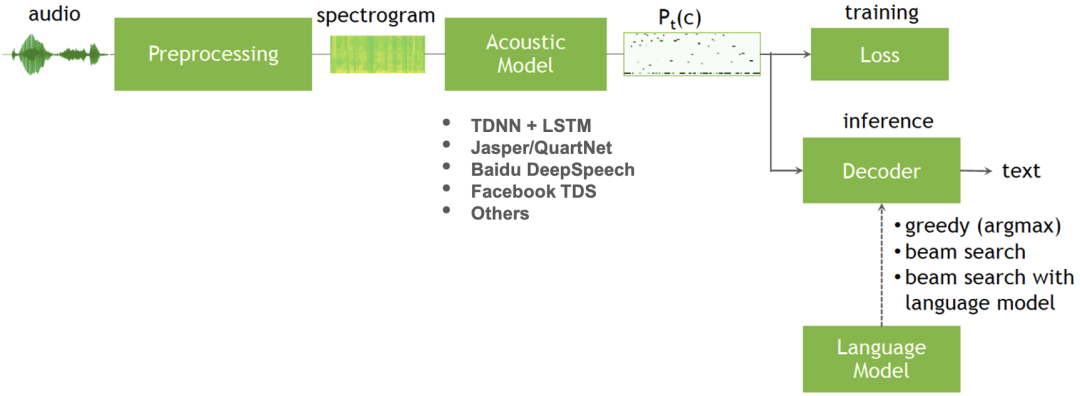
图二:快手流式 ASR 服务整体框架
原本的 CPU 方案耗时瓶颈明显,在该框架的处理流程中,特征提取等前处理模块的运行时间占比约为 5%~10%,声学模型为 TDNN+LSTM 模型,运行时间占比约为 60%~80%,而包含语言模型的解码器部分运行时间占比约为 15%~30%。优化后的方案是将主要的耗时关键模块移至更合适的异构底层器件。其中语言模型的大小和精度相关,现有的语言模型大小超过了当前异构器件(GPU/FPGA/ASIC)的板上内存。如果想要放到异构器件的板上内存,需要缩小语言模型规模,可能会影响识别精度。为了更好的用户体验,经过评估后,语言模型的大小维持不变,解码器的部分仍然在 CPU 上处理,而声学模型的推理部分,用更合适的异构器件来替换 CPU。以 TDNN+LSTM 为主结构的流式声学模型优化的关键痛点是减少延迟(Latency)、改善实时率(RTF,Real Time Factor)和提高并发数(Concurrency)。
除 CPU 外,异构底层器件可供选择的有 GPU、第三方 ASIC 芯片和 FPGA。FPGA 的特点在于延时低且可精确控制,单位算力功耗低,片上内存大。与 GPU 和 ASIC 的具体对比如表ㄧ。总结而言,FPGA 较适合于延时要求高,batch 比较小的应用场景;在 AI 领域,尤其适用于类 LSTM,Transformer Decoder, GPT2 这种模型复杂或参数需要重复调用的场景。

表ㄧ:异构器件特性比较表
快手流式声学模型是在 Kaldi 的框架上训练的。流式声学模型 TDNN+LSTM 有以下几个特点:
LSTM 的输入 batch size 为 1
LSTM 的运算是串行的
LSTM 中的各个分支中的矩阵乘大小不一, 造成多个碎片化的矩阵乘
LSTM 对运算精度的要求相当高
以上模型特点本身对当前主流的 GPU/ASIC 大算力的 Tensor Core 硬件架构并不友善,使得硬件使用率 (Utilization) 低落。比如现有的流式模型在 T4 GPU 上实测 RTF 不能满足需求。
主流的 ASIC 推理卡除了以上介绍的硬件使用率 (Utilization) 问题外,还存在不支持 Kaldi 框架,定点实际只有 12bit 等问题,大概率不能满足精度需求。
综上,异构组将业务的需求抽象为在模型精度不妥协的情况下降低延迟[用户体验]、降低算力成本[TCO],同时方案要尽可能易用易部署,支持业务的框架模型。在人工智能训练和推理部署上,最前沿的做法是训练采用浮点或定点,而推理采用定点 INT8/INT16 计算,使得推理的算力需求大幅度地降低。快手的应用场景的 AI 算法和模型,对精度要求很高,第三方异构平台厂商的人工智能编译器的定点化实现较难满足需求,或是不支持我们的算法模型 。理想的异构器件平台应当是一个全定制的定点平台,通过软硬件协同设计确保精度符合业务标准。这次针对 ASR 的优化,异构组评估后决定选型 FPGA,采用自研的快手定点通用推理框架和定点 C 模型,以达到最佳的量化、图融合及图优化的效果来为业务助力赋能。
方案设计与创新
快手异构组选择了全定点推理的 FPGA 定制化方案,考虑业务场景、成本约束和算力限制,为达到最佳效果,在各个环节、各个层面针对性的解决问题和提出创新,如表二。
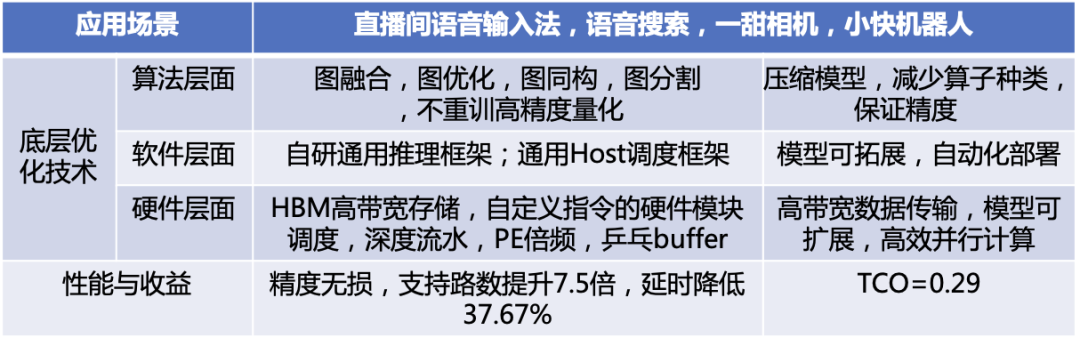
表二:硬件加速方案技术创新
算法层面
算法层面: 图融合
完整的原始 TDNN+LSTM 声学模型结构和图融合后的声学模型如图三所示。图融合和图优化是神经网络部署下比较常见的优化步骤,可以将数层 layer 融合为 1 个,降低对算力需求同时不会影响精度。透过快手通用推理框架图融合和图优化,原始模型的层数从 125 层减少到 98 层,减少了约 20%。
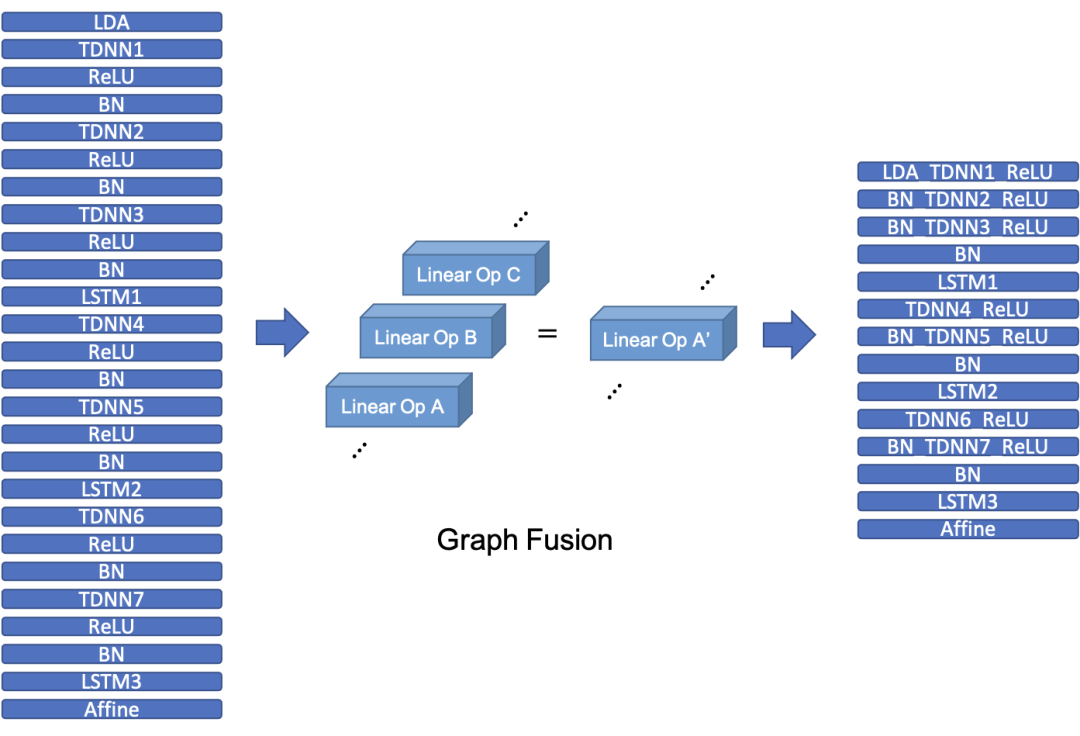
图三:图融合和图优化后的声学模型减少了约 20% 的层数
算法层面: 不重训的高精度模型压缩
在各个异构底层器件 (CPU/GPU/FPGA/ASIC) 中,乘加器是主要的基本运算单元之一,在相同的位宽下,实现浮点乘加器所需的计算资源大约是定点乘加器所需的 7~8 倍。从减少运算开销,功耗和增加计算密度而言,定点运算相比浮点运算有显着的优势。将原本 FP32 的模型推理改为 Int16, 如图四,保证精度可用,这意味着要为业务模型定制 TDNN+LSTM 中各个算子的定点实现算法。
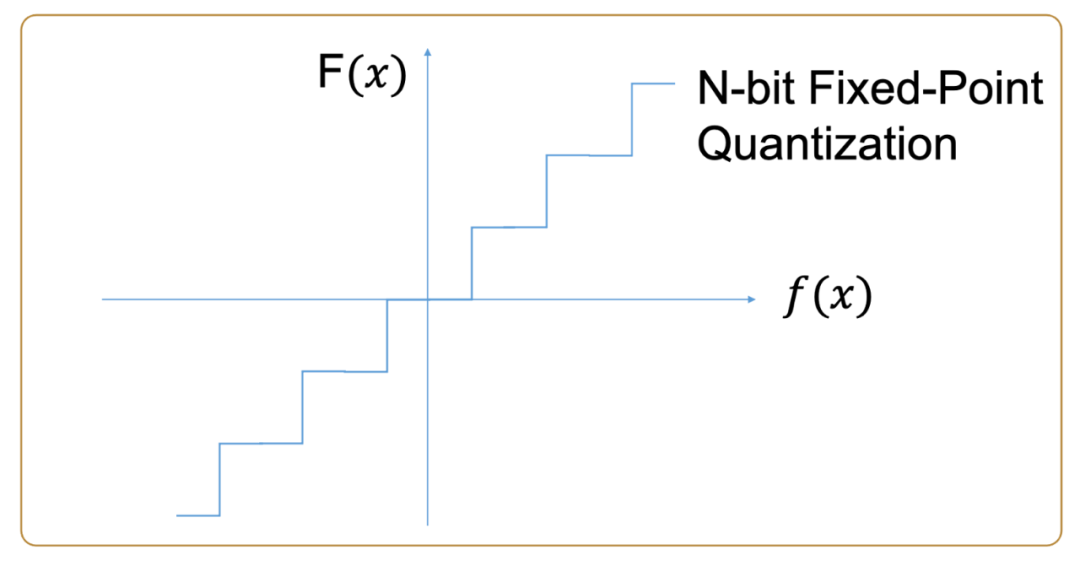
图四:浮点和定点量化转换
算法层面: 时序校准 LSTM
LSTM 的定点化是一个难点。一般定点化模型,先准备校准集 (calibration dataset),在校准集上做 inference,观察模型中意图量化的层的数据分布直方图作为量化的范围依据。LSTM 是有 feedback loop 的模型,参与下一时刻计算的是上一时刻数据的子集,即 c_t=F(c_t-1[0:x],其他参数 1,其他参数 2······)。在 TDNN+LSTM 声学模型的定点化过程中,异构组自研推理框架创造性的使用了时序校准(Temporal Profiling) 的方法,将 c_t 和 c_t-1 两时间点视为不同的 node 以校准 (profiling) 如图五所示。
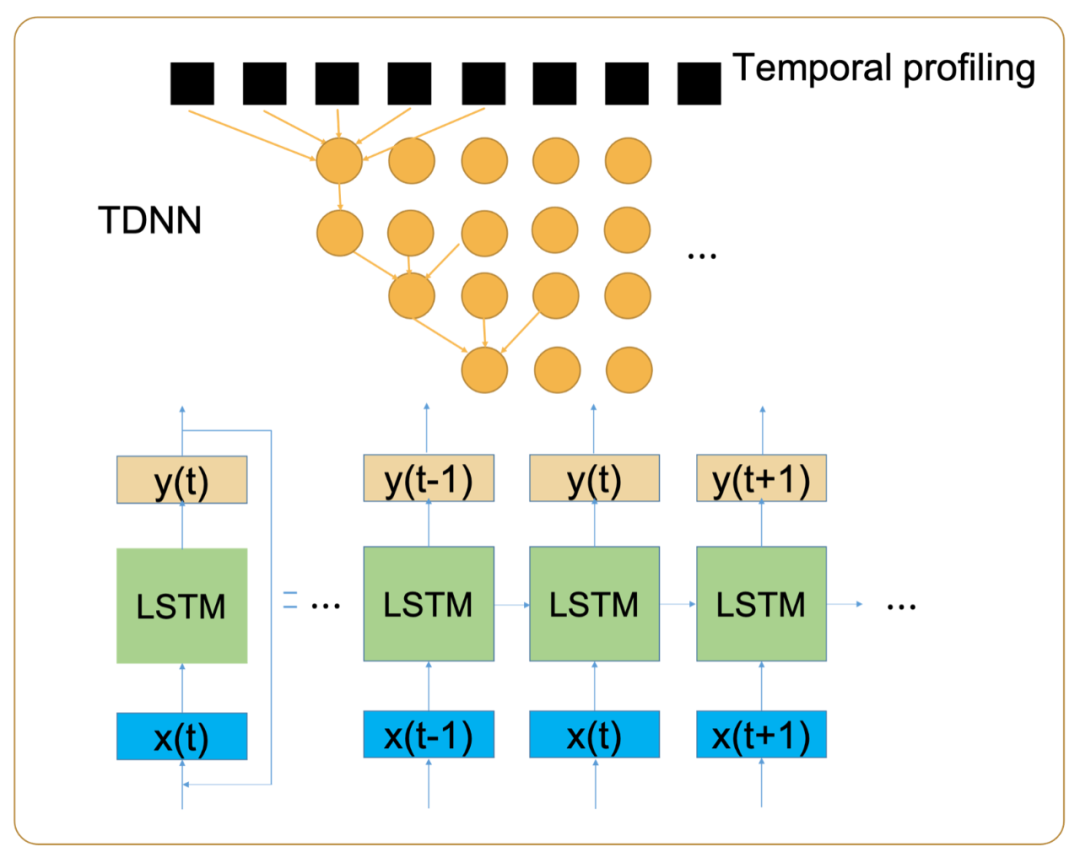
图五:时序校准
算法层面: 图同构加速 FPGA
现今主流的 NPU 架构,如图六 NVDLA 所示,针对不同的算子,拥有专用的处理引擎。好处是众多的专用处理引擎可以支持更深的流水线,易拥有良好的性能。代价是需要更多逻辑资源,造成芯片的面积和功耗更大,总体的硬件使用率 (Utilization) 相对低落,性能功耗比 (Performance Per Watt) 较差。
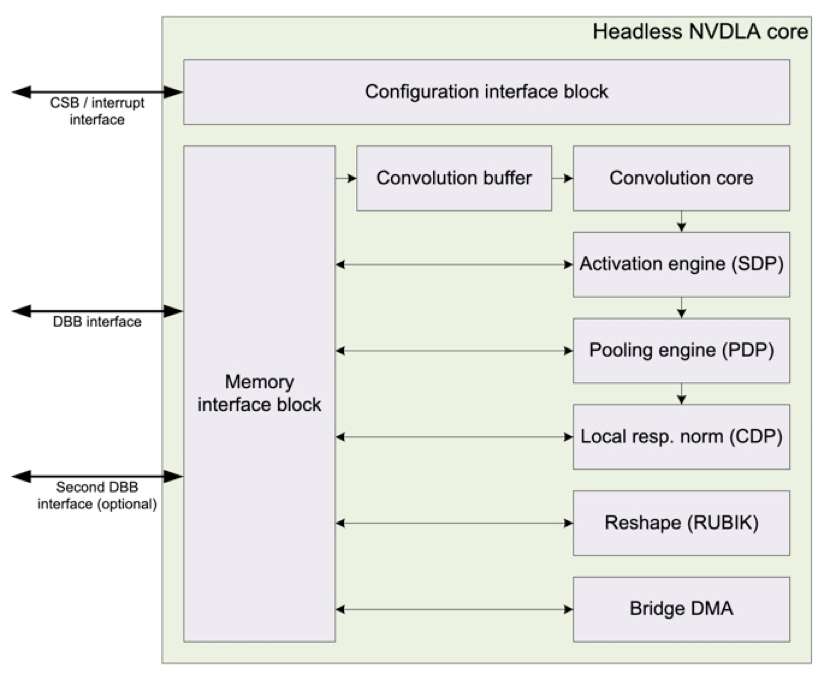
图六:NVIDIA NVDLA Core Block Diagram(http://nvdla.org/hw/v1/hwarch.html)
以上介绍的主流 NPU 架构并不适用于 FPGA,因为 FPGA 上的计算资源是固定的。在计算资源是固定的情况下,拥有多项专用算子的处理引擎架构,会分散计算资源,每个处理引擎得到的运算资源有限。更理想的设计是透过图同构,将多种不同的算子映射到同样的计算方式,因此,只需要设计一种专用算子的处理引擎,能将计算资源利用最大化。
除此之外,在 FPGA 性能设计上,FPGA 一般来说拥有 1~N 核 (Kernel)。每个 Kernel 上可以规划多个运算引擎(PE),每个 PE 对应一个并发数。要达到低延迟,从计算角度,每个运算引擎(PE) 的计算资源越多,计算可以越快完成。而要达到高并发,FPGA 上的 PE 数是越多越好。如何平衡低延迟和高并发,是 FPGA 加速器设计的另一大挑战。
算法层面: 图分割加速 FPGA
结合 FPGA 的 pipeline 的硬件特性,考虑尽可能的用好 FPGA 算力,异构组在对 TDNN+LSTM 模型分析的基础上做了图分割(graph partitioning)。如图七所示,图分割可针对性的将模型计算量「均匀化」,在 FPGA inference 阶段的每一环的计算资源利用率更高,从而带来更好的 latency 收益。
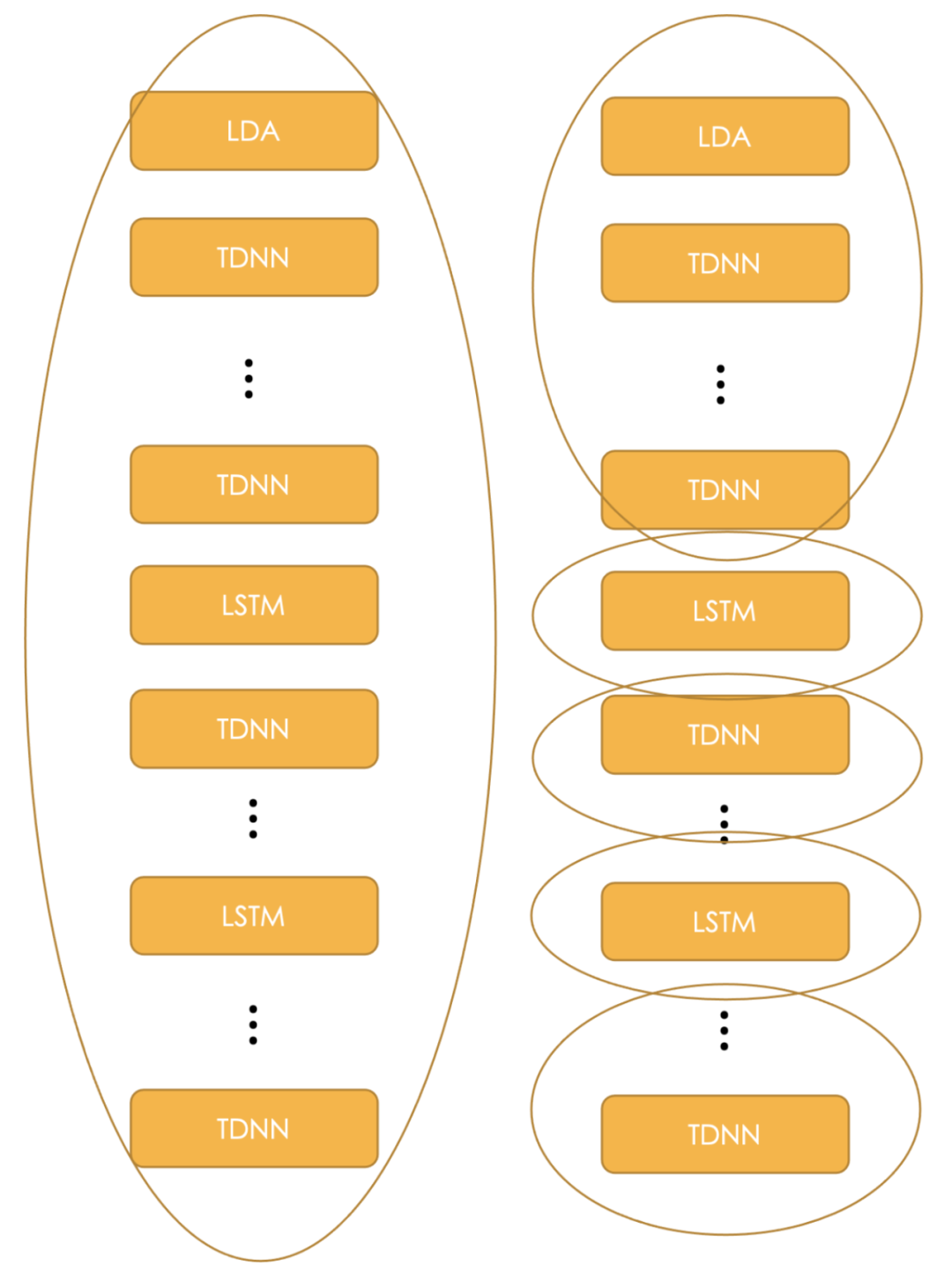
图七: 针对 TDNN+LSTM 模型的图分割(Graph partitioning)示意
系统层面
可扩展性及易用性设计
针对可扩展性及易用性需求,FPGA 的设计考虑到以下几点:
软件接口易用。FPGA 加速引擎以 pub 库的形式提供给业务方。接口简单,只需要 Init 和 Inference 两个函数接口即可完成 FPGA 引擎的调用。Init 接口还可支持多个不同模型的加载。
零代码升级模型。通过配置文件修改模型的 layer,channel,dim 等信息,软件会自动更新模型。非常易于模型升级与部署。
支持多模型任意切换。可以同时运行多个模型,也可实时任意切换模型。
计算资源可配置。同一模型的 kernel 个数可配置。
系统整体架构
系统整体架构如图八所示:
Host(调度加速引擎的代码框架)接收输入的语音数据,经过前处理,神经网络推理,和后处理过程生成识别后的文本。
神经网络推理过程(黄色部分)卸载到 FPGA 加速卡上完成。
Host 将输入数据通过 PCIe 接口搬移到 FPGA 加速卡的设备内存中。
启动 FPGA 上的 ASR Accel Engine(即 Kernel,负责执行模型计算)进行神经网络推理。
将推理结果从设备内存搬移到主机内存。
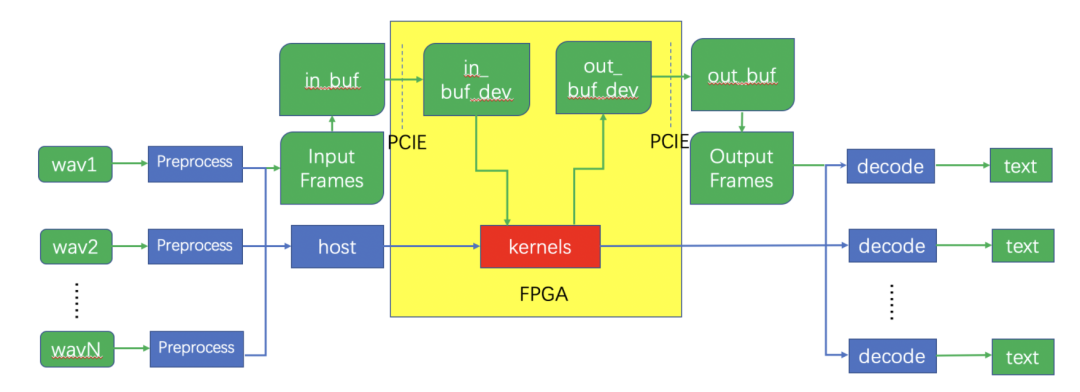
图八: 系统整体架构
硬件架构设计
硬件架构设计如图九所示:
ASR 硬件加速引擎是一个基于超长指令字 (VLIW) 的专用领域处理器,在 FPGA 加速卡上可以放多个这样的加速引擎。
Insruction Fetch & Decoder 单元负责指令加载与解析。
Scheduler 负责所有计算单元之间的调度工作。
Matrix Multiply Array(MMA)支持 64x32 个 16bit 定点乘累加。
Vector Process Unit(VPU)为向量处理单元,一个加速引擎中包括 32 个 VPU。
Load/Store 负责数据的加载与结果的返回。
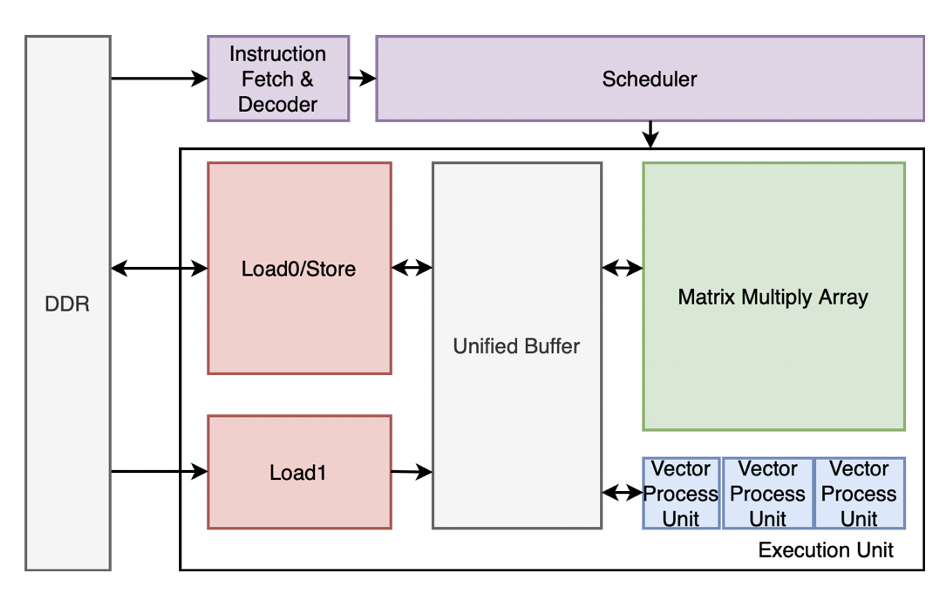
图九: 硬件架构设计
软件层面
Batch 机制
FPGA 引擎中单个 Kernel(加速引擎,执行模型计算)有 32 个计算单元,可同时支持 32 个用户的数据计算。为了保证 Kernel 计算资源的利用率,需要同时计算尽可能多的用户数据。设计 batch 机制,积累用户请求,先到先算。这种调度方式可以最大限度提升 kernel 的利用率,同时减少 kernel 调度本身的开销。
负载均衡
FPGA 引擎支持同时运行多个模型,不同模型的大小不同,计算量不同,如果模型与 kernel 之间的映射固化,会导致 kernel 之间负载不均衡,不能充分发挥计算资源的性能。一、Kernel 的调度采取实时分配的策略,当前的计算任务优先分配给空闲的 kernel。二、Host 根据当前模型实时切换数据空间和指令空间;Kernel 内部计算采用兼容性设计。以上两点设计可以实现负载均衡,计算资源利用率最高。
基于 OpenCL 的任务调度
OpenCL(全称 Open Computing Language,开放运算语言)是一个面向异构系统通用目的的并行编程开放式标准,广泛适用于 CPU、GPU 及 FPGA 等高性能计算开发。FPGA 引擎基于 OpenCL 设计了任务队列调度系统,基于事件的任务同步机制,任务自动 Pipeline 机制,使得数据传输、kernel 计算等任务高效的并行执行。
硬件层面
Kernel 指令调度
自动语音识别的加速任务的关键之一在于设计面向 TDNN 和 LSTM 网络的高性能硬件加速器。考虑到设计的灵活性,快手采用了当前流行的 DSA(Domain Specific Architecture)的设计方法,并定义一组专用的指令集。
项目中的指令集架构采用了 VLIW( 超长指令字),指令的生成和调度,指令的并行,不同指令之间的数据依赖关系均通过编译器解决,大大降低了硬件设计的复杂程度。虽然 VLIW 的设计在灵活性上有所欠缺,但针对神经网络推理领域,这是一个很好的解决方案,并能达到很高的效率。
底层设计优化
建立在上文所描述的指令集架构上,可以进行硬件微架构的设计和开发。在开发过程中,首先选择了 High Level Synthesis(HLS,高层次综合)技术,快速且高效的完成了硬件微架构的设计。和直接采用硬件描述语言(譬如 Verilog HDL)相比,HLS 技术在更高的抽象层次上使用 C/C++ 的语法描述硬件行为,快速实现各种优化技术。
Matrix Multiply Array 中采用了 Loop Unroll 技术,将循环展开,设计了 32*64 个并行执行的乘法单元。
Vector Process Unit 中采用了 Loop Pipeline 技术,流水完成多种不同的计算。
MMA 和 VPU 之间采用了 PingPang Buffer 的设计,使得访存不被阻塞。
Load 模块采用 AXI 接口,对内存进行高效的读写。
通过一系列手段,采用 HLS 开发方法达到了和 Verilog 接近的效果;开发时间从 3 个月缩短到 6 周。
在此基础上,后期采用 Verilog 进行了进一步性能优化,利用计算单元倍频,逻辑资源分时共享,布局布线策略优化等技术,达到了极致性能。
方案结果与总结
方案结果
以直播间语音输入法服务为例,相比原 CPU 服务(对照组),FPGA 服务(实验组)的精度基本无损,符合业务预期。
压测结果:CPU 单实例 24 路,FPGA 单实例 180 路,提升 7.5 倍。
上线结果:相比原 CPU 服务,高峰期平均延时减小 37.67%,P99 延时减小 20.7%,可用性更稳定,提升了用户体验。服务总 QPS=6000 高峰时的指标对比如表 4:

表四: 实际上线性能指标对比
总结
在开发实现上,每一种异构平台的开发方式和成本都是不同的, 与通用芯片平台 GPU 和 CPU 相比,FPGA 开发代价和周期是比较高的。在本项目中,我们以算法优化为起点,在确保精度无损的前提下,透过多种算法优化和压缩流式 ASR 模型,大幅减少所需算力和内存使用。项目中最大的挑战和风险在于如何确保性能优化后能达到识别精度无损。
为降低甚至避免识别精度下降的风险,在开发上,快手异构组采取了先进的软硬件协同设计。以本项目为例,透过软硬件协同设计,Kaldi 流式 FP32 ASR 声学模型透过快手自研的模型压缩推理框架,完成模型压缩和推理精度测试。确保精度符合业务要求才开始 FPGA 设计。FPGA 上的最终结果和自研的模型压缩推理框架结果是 bit-exactness - 每一条语音的输出位元,FPGA 和推理框架都是一致的。这从根本上解决和回答了到底经过压缩后的模型在 FPGA 上是否能满足业务精度要求。在 FPGA 的设计中,透过定量分析,增加 pipleline 的深度,提高数据复用次数,减少数据写回 DDR,降低数据传输所造成的性能损失。 配合 FPGA 上的高带宽内存 (HBM) 功能,近乎达到存算一体的性能。通过图融合及图同构, 减少在 FPGA 上图计算量 30% 和简化 FPGA 内核设计,增加内核中的运算引擎 (PE)数量,支援更高的并发数。
如何提升快手 AI 基础设施效能的关键之一是先进的软硬件架构设计。在未来的 AI 算力领域,通用 / 专用 AI 硬件 + 通用异构计算加速技术将是未来 AI 算力基础设施的首选。针对不同的业务场景充分挖掘不同 AI 器件平台的计算能力,提升存量利用效率并降低采购增量,实现降本增效和业务赋能有很重要的意义。如何通过软硬件协同优化,在通用 / 专用异构 AI 硬件上实现面向具体 AI 应用场景的 Domain Specific Acceleration 是关键的技术挑战。
团队介绍
本文来自于快手异构计算中心,快手异构计算中心的使命是为业务部门提供强大、高效的计算系统,包括 CPU、GPU、FPGA、ASIC 等异构加速平台和混合解决方案。让每一种不同类型的计算单元都可以执行自己最擅长的任务,从而达到提高性能、节省成本和节约能耗的目的。解决算力需求增长远高于计算资源算力增长的矛盾,通过定制化开发将算力限制导致的不可能变为可能,从而赋能业务。快手异构计算中心的发展目标是围绕快手核心业务打造技术护城河,引导互联网硬件行业发展。快手异构计算中心秉持 「上线、创新、深入、开放」 的价值观和快手各业务部门展开深入合作,实现降本增效、业务赋能的共同目标。
快手 MMU 音频中心语音识别组的目标是结合快手业务场景,打造业内一流的语音识别解决方案,助力快手业务发展。通过精准高效地理解平台上的语音内容,为海外、电商、风控、搜案、推荐、商业化等业务方提供基础服务。典型应用场景包括: 短视频 / 直播 ASR、自动字幕、电话客服 ASR 等。此外,通过提供更高效的交互方式,提升用户在平台的消费体验,为平台新增流量入口,应用形式包括语音搜索、直播间语音输入法、直播间小快机器人等。
编辑:王菁

这篇关于快手团队长文解读:基于FPGA加速的自动语音识别在大规模直播和短视频场景的应用...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





