本文主要是介绍PairAug:增强图像-文本对对放射学有什么用?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接
代码链接GitHub - YtongXie/PairAug: [CVPR2024] PairAug: What Can Augmented Image-Text Pairs Do for Radiology?
发表于CVPR2024
机构
1) 澳大利亚机器学习研究所(AIML),澳大利亚阿德莱德大学
2) 西北工业大学计算机科学与工程学院
3) 西北工业大学宁波学院
4) 南澳大利亚医学成像,澳大利亚
摘要
当前的视觉语言预训练(VLP)方法主要依赖于成对的图像-文本数据集,由于隐私考虑和标签复杂性,在放射学中很难获得这种资源。数据增强为克服数据稀缺问题提供了一种实用的解决方案,然而,大多数增强方法的关注点有限,只优先考虑图像或文本增强。认识到这一限制,我们的目标是设计一个能够同时增强医学图像和文本数据的框架。我们设计了一种成对增强(PairAug)方法,该方法包含一个患者间增强(InterAug)分支和一个患者内增强(IntraAug)分支。具体来说,我们方法的InterAug分支使用源自大型语言模型(LLM)的合成但可信的报告生成放射学图像。生成的对可以被d认为是新患者病例的集合,因为它们是人为创建的,可能不存在于原始数据集中。相反,IntraAug分支使用新生成的报告来操作图像。这个过程使我们能够为每个不同医疗条件的人创建新的配对数据。我们在包括医学图像分类零采样和微调分析在内的各种下游任务上进行的大量实验表明,我们的PairAug同时扩展图像和文本数据,大大优于仅图像/文本扩展基线和高级医学VLP基线。
背景
VLP在医学领域的应用面临着复杂的挑战,很大程度上归因于对大量数据的固有需求。例如,对比语言-图像预训练(CLIP)模型[26]需要在一个包含4亿对来自互联网的图像-文本对的数据集上进行训练,但是医学数据难以获得。
VLP的有效增强需要图像和文本的同步增强,确保一致性并最大限度地从配对的医学图像文本数据中获得信息增益。因此,我们认为医学图像和文本数据的同时扩展是至关重要的。通过采用这种并行增强策略,我们不仅在数量上扩大了数据集,而且在语义层面增加了数据多样性,从而进一步提高了模型的泛化能力和准确性。
在本文中,我们提出了一种医学VLP的成对增强(PairAug)方法。PairAug由两个不同的分支组成:患者间增强(InterAug)和患者内增强(IntraAug)分支,每个分支都具有独特的功能。这些分支旨在跨患者间和患者内域扩展配对数据,保持谨慎的平衡,以避免在增强的配对中冗余或重叠。
相关工作
Medical VLP 医学语言文本预训练
医学VLP, VLP在医疗保健领域的延伸,旨在解释复杂的医学图像和相关文本。许多方法使用视觉语言对比学习[15,38,41,44,47],利用自然发生的医学图像-放射学报告对,在图像分类[15,38,47]和图像-文本检索[15,38,41]等各种任务中产生了令人印象深刻的结果。最近的进展是将 (mask Auto-Encoder, MAE)模型[12]从自然图像领域引入医学VLP,证明是有益的[4,48]。然而,尽管有很好的结果,性能往往受到现实世界医学图像-文本对的稀缺性和多样性的限制。
Medical Data Expansion 医学数据增强
医疗数据扩展是一个活跃的研究领域,解决了医疗保健中数据稀缺的关键问题[19]。
先进增强技术的出现,尤其是生成对抗技术
网络(gan)开创了合成但看起来逼真的图像生成的新时代。gan及其变体已经在各种医学成像环境中取得了相当大的成功[23,25,43],为模型训练提供了更丰富、更多样化的数据集。
最近的一些研究已经探索了语言到图像模型在医学图像扩展中的潜力[3,27,30,42]。他们使用基于医学教科书/报告的提示作为生成图像的输入,并提高在有限的真实数据集上训练的模型的诊断准确性。
传统的文本扩展方法在不同的粒度级别上工作[6]:字符、单词、句子和文档。llm的最新进展,如PaLM[5]、LLaMA[35]和ChatGPT,促进了更复杂的文本扩展方法的发展。尽管在医疗数据扩展方面取得了实质性进展,但大多数现有策略都局限于图像或文本合成。这种单一的焦点并没有充分解决有限的现实世界医学图像-文本对数据的持久问题。
方法
Problem Statement
考虑到开放式词汇学习,我们的目标是在原始/现有的数据集Ωo中增加图像文本对,其中(xi, yi) ∈
Ωo。
其中,xi表示与相应文本yi配对的图像(例如,放射学报告),no表示样本数量。数据集扩展的目标是生成一组新的合成样本Ωs,其中(x~i,y~i)∈Ωs,以放大原始数据集,使在扩展数据集Ωo∪Ωs上训练的可学习模型显著优于仅在Ωo上训练的模型。
How to Augment for Effective Expansion
为了生成新的图像-文本对,我们利用了大型语言模型P和图像合成模型G的功能,它们分别以令人印象深刻的文本和图像生成功能而闻名。然而,不同样本类型的有效性尚不清楚。我们的主要见解是,与原始对(x, y)∈Ωo相比,新合成的对(≈x,≈y)∈Ωs应该引入新的信息,同时保持每个创建对的高质量。为了实现这些目标,我们考虑了两个关键标准:(1)非重叠成对增强和(2)优先考虑高质量对。
Overall Pipeline

如图1所示,考虑到前面提到的几点,我们提出了一个名为Pairwise的框架
用于扩展数据集的增强(PairAug)。该框架在指定标准的指导下,通过两个不同的分支扩展数据集:
患者间扩增(InterAug)和患者内扩增(IntraAug),从而防止扩增对中的冗余或重叠。此外,我们为每个分支纳入了特定的数据修剪方法,以保持增广对的质量。PairAug的管道可以表示为:
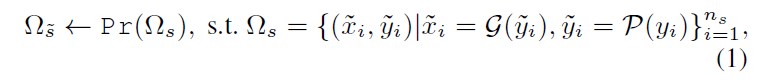
其中Ω ~ s是Ωs和ns的子集,ns表示Ωs中合成对的个数。
Pr()是一个修剪操作。
为简单起见,我们省略了大型语言模型P的输入提示符。
在实践中,最终的合成数据集Ω ~ s由两个子集Ω ~ a和Ωe’组成,分别来自我们的InterAug和IntraAug分支。
3.1. InterAug: Inter-patient Augmentation
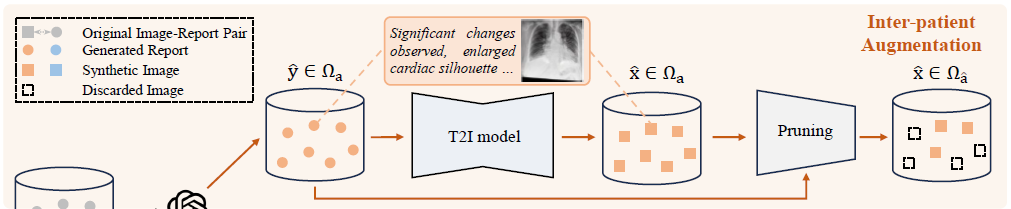
New Report Generated by Large Language Model (LLM)
首先,我们关注文本域,使用ChatGPT与 Azure OpenAI服务处理x射线报告。LLM根据手动指令生成结果报告
e.g prompt: 以下是胸部x光片的原始报告。生成一个可能的扩充,限制在50个单词以内,并且传达与原始报告部分相反的意思
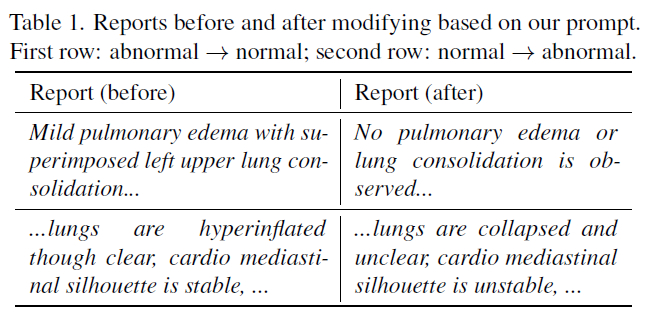
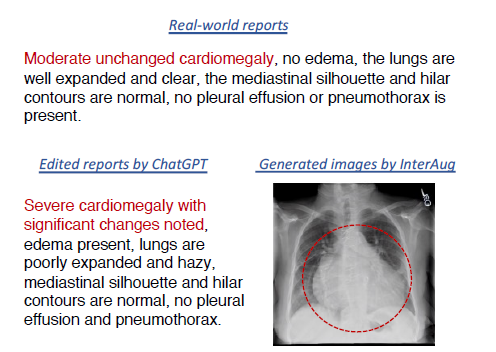
如表1所示,我们以提供输入报告“轻度肺水肿合并左上肺实变”为例,我们使用ChatGPT根据我们的书面提示生成经过适当修改的输出报告“未观察到肺水肿或肺实变”。这样,我们可以获得大量新的和多样化的放射学报告。由于篇幅限制,我们在补充部分提供了更多的例子。
Inter-patient Image Generation
在这一部分中,我们试图在没有任何其他约束的情况下基于文本生成图像。这样,这些对可以看作是一组新患者,因为它们是合成生成的,在原始数据集中可能不存在(见图2(a)生成的图像)。
具体来说,我们的模型基于Stable Diffusion,这是一种大规模文本到图像(tt2i)潜在扩散模型[29],并在放射学数据集上使用后预训练版本,即RoentGen[3]。正式地,生成新的图像-文本对的过程可以定义为
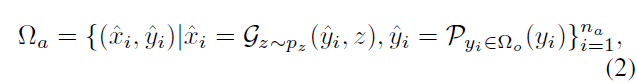
式中,P为LLM, G为生成模型。Pz是输入噪声变量z的先验分布。na表示新的图像-文本对的数量。
Data Pruning by Semantically-aligned Informativeness
为了保证生成对的质量,我们引入了一种基于语义对齐分数Sa的数据修剪方法Pra(),该方法利用了CLIP的语义对齐能力[26]。与[28]类似,我们使用CLIP对从生成模型中提取的样本进行重新排序。值得注意的是,当我们专注于胸部x光片的放射学图像生成时,我们使用MedCLIP[39]在胸部x射线数据集上进行预训练而非original CLIP。具体来说,对于来自InterAug的配对数据,MedCLIP根据图像与报告的匹配程度进行评分。然后,我们过滤并仅保留那些达到分数超过阈值τ的图像报告对。这样,我们不仅保证了扩展数据集的语义一致性,而且提高了我们的数据生成方法对生成模型失效的鲁棒性。数学上,剪枝处理后保留的数据集Ω´a可定义为
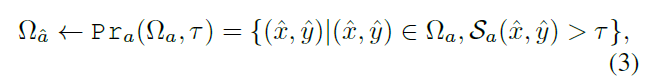
式中Sa(x^, y^)分别为MedCLIP图像编码器和文本编码器提取的图像特征与文本特征的余弦相似度。
3.2. IntraAug: Intra-patient Augmentation
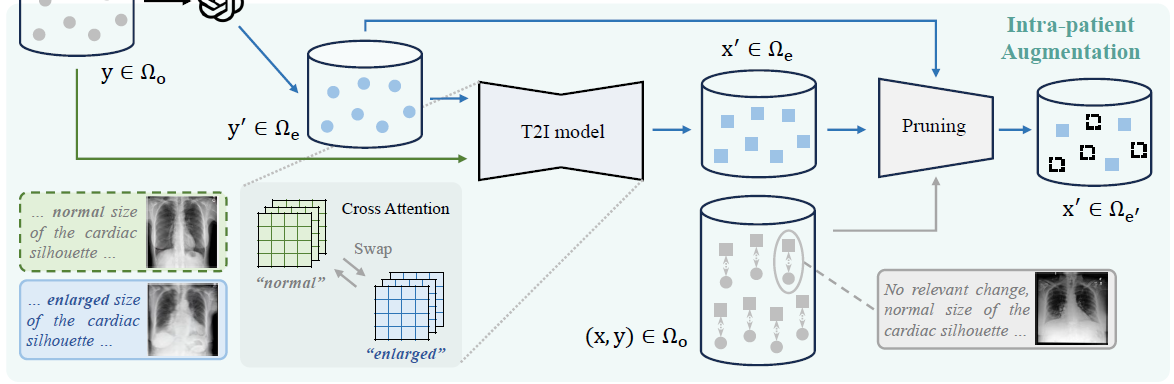
除了通过Inter- Aug扩展患者水平的数据外,我们还寻求获得捕获每个个体不同医疗条件的样本。与InterAug生成的数据相比,这进一步增强了数据集的多样性,而不会引入重叠或冗余。然而,由于缺乏对图像一致性的保证,捕捉每个患者病情的变化,即使是微小的变化,都是具有挑战性的。
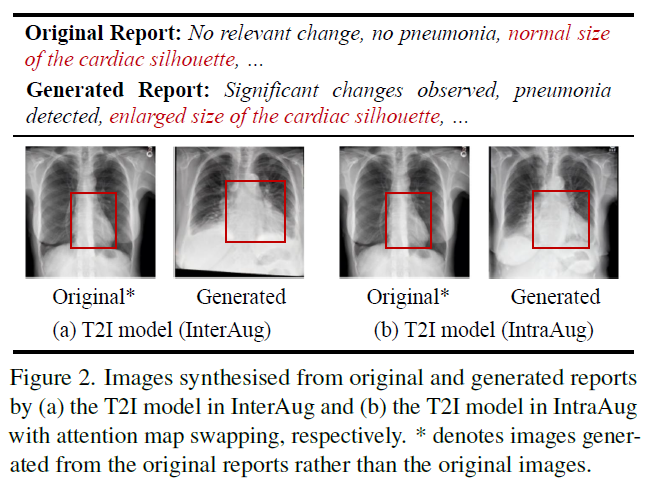
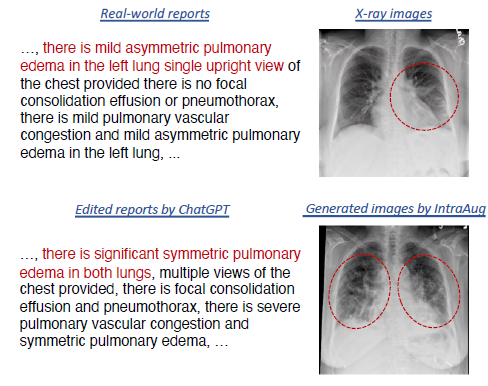
p2中放射图像来自不同的病人,即使他们都在语义上与他们的报告一致(见红色框和描述)。
这与我们的目标相矛盾,因为我们希望生成显示同一患者不同医疗状况的放射学图像(图2(b)),而不是在另一个患者上生成条件。为此,我们设计了一个IntraAug,在考虑原始报告作为条件的同时,使用新生成的报告生成新的患者内部图像。
为了使整个模型对记忆友好,我们没有重新开发图像编辑模型(在有限的训练数据下,编辑质量可能无法保证),而是重用相同的生成模型G(来自上一节)来合成图像,但交换了原始报告中的cross-attention map。
Image Generation by Controlling Cross-Attention Maps
受[13]中观察的启发,我们试图通过修改生成模型G的中间cross-attention map M来控制生成过程。
形式上,我们将生成过程定义为
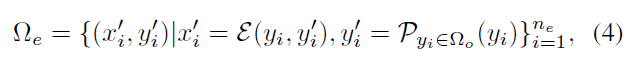
式中,P为大语言模型,ne为生成数据总数。其中E为生成过程,包含扩散模型G和注意图交换操作Swap(t)(Mt,M ' t),该操作将扩散过程第t步的原始交叉注意图Mt(来自原始报告y)与修改后的M ' t(来自修改后的报告y ')交换,如图1中从“正常”到“放大”。
在数学上,给定y ',扩散处理步骤t的输出噪声图像z ' t - 1可如下计算↓
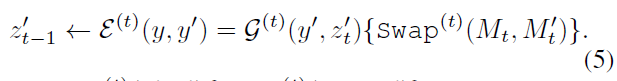
这里,让G(t)(y ', z '){Swap(t)(Mt,M ' t)}表示扩散步骤,我们将注意力映射Mt与修改后的映射M ' t交换,其中Mt←G(t)(y, zt)和M ' t←G(t)(y ', z ')。前一步分别从y和y '生成噪声图像zt和z '。对于G,在第一步T处输入随机噪声z′T ~ pz,最后在最后一步0处生成图像x′= z′0。
此外,继[13,21]之后,我们使用了一种更柔和的注意图交换方法来很好地控制修改程度,即:
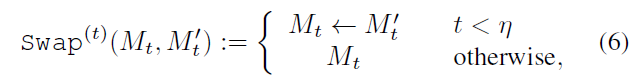
其中η = 0.5是时间戳(timestamp)超参数,指定使用哪一步交换操作。
Data Pruning by Hybrid Consistency
在这一部分中,我们通过设计混合一致性评分来评估来自IntraAug的数据,该评分由三个一致性标准组成:
(i)输入报告与相应图像之间的语义对齐S1;
(ii)原始图像与生成图像的相似度S2;
(iii)两幅图像之间的变化S3与对应的两份报告之间的变化的一致性。
对于(i)和(ii),我们直接使用MedCLIP捕获报告和图像的特征,然后分别计算图像-报告对和图像-图像对的相似度。对于(iii),受[10]的启发,我们使用CLIP空间中的方向相似度(directional similarity)。这将计算Δx和Δy之间的余弦相似度,其中Δx表示图像特征之间的差异,Δy表示报告特征之间的差异。
由于S1, S2和S3的大小不同,我们试图单独计算它们,然后将它们的平均值作为过滤阈值。在形式上,数据集Ω1、Ω2和Ω3可以如下过滤↓
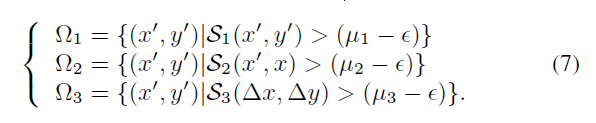
其中Δx为x与x′之间的特征相减,Δy为y与y′之间的特征相减,其中(x′,y′)∈Ωe, (x, y)∈Ωo。Ωo为原始数据集。μ1、μ2、μ3分别为S1、S2、S3评分的平均值。
此外,我们引入了一个超参数,使阈值更灵活,不那么严格。最后,通过↓得到我们增强后的数据
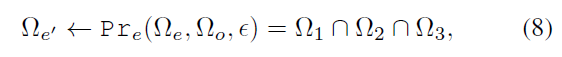
其中Pre()是具有以上三个标准的修剪方法
3.3. Medical VLP with Generated Pairs
我们为我们的医疗VLP合并了真实世界和生成的医学图像文本对。我们的模型建立在CheXzero框架上[34],这是一种先进的方法,可以熟练地利用医学图像和放射学报告之间的语义对应关系来进行全面的医学数据表示学习。我们使用Vision Transformer [9], viti - b /32作为图像编码器,并使用具有12层,宽度为512的Transformer[37]作为文本编码器,具有8个注意头。我们使用来自OpenAI的CLIP模型[26]的预训练权值初始化自监督模型。之后,我们将预训练的权值参数应用到各种下游分类任务中,在zero shot和微调设置下。对于zero shot 设置,我们遵循CheXzero,并对每种疾病采用阳性-阴性softmax评估程序进行多标签分类任务。特别是,我们计算带有积极提示(例如肺炎)和消极提示(即没有肺炎)的对数。然后,我们计算正负对数之间的softmax。最后,我们保留正对数的softmax概率作为胸片中疾病的概率。我们采用广泛使用的linear probing方法进行微调评估,其中预先训练好的图像编码器被冻结,只训练一个随机初始化的线性分类头。
实验
实现细节
我就暂时略了

Generation Setup
Pre-training Setup
Downstream Setup
实验结果
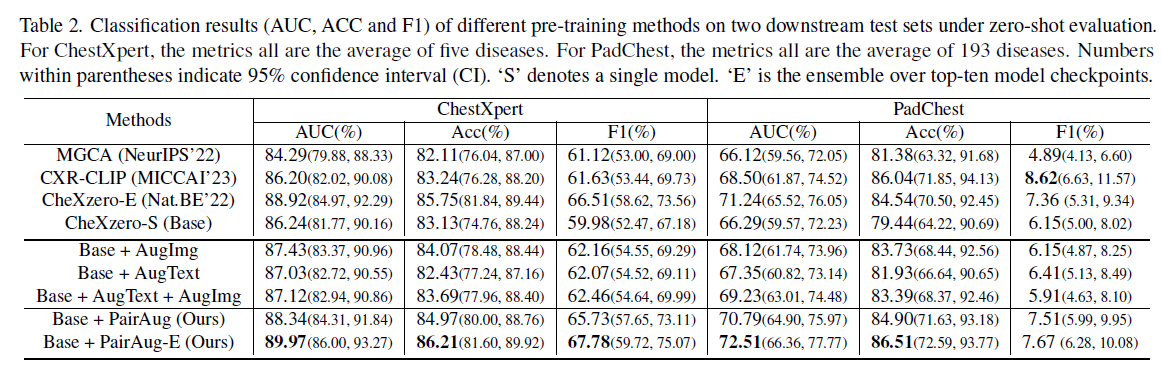
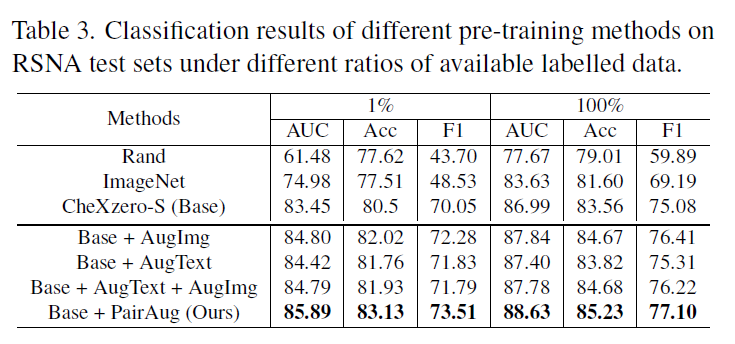
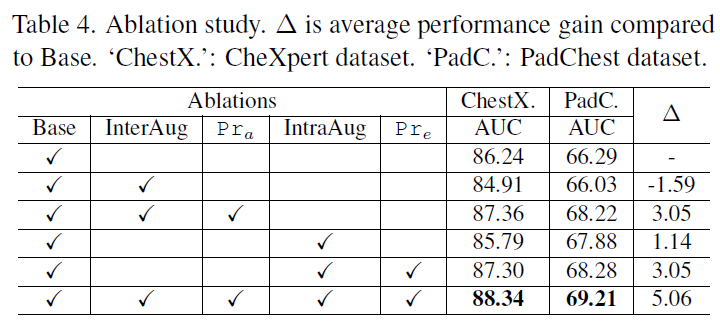
定性结果
1)图像/报告嵌入的T-SNE可视化,将IntraAug和InterAug方法的合成数据与MIMIC CXR数据集的真实数据进行比较。
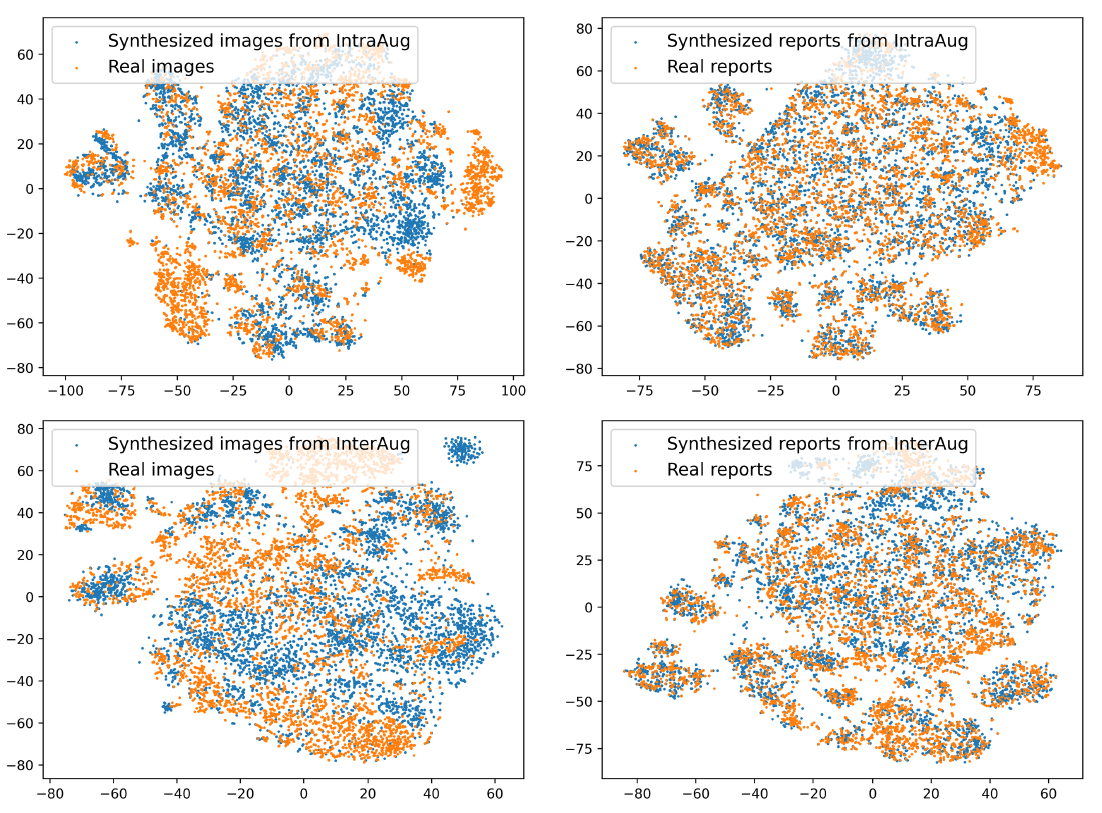
2)ChatGPT编辑前后的放射学报告和InterAug生成的相应图像。我们用红色边框突出放射图像中的特定区域,并在报告中用相同颜色突出相应的描述
3)利用IntraAug合成的放射影像-报告对
总结
在本文中,我们提出了一种名为PairAug的方法来解决在放射学中获取配对图像-文本数据集的挑战。paiaug包含两个分支:InterAug和IntraAug。InterAug生成与可信报告配对的合成放射学图像,创建新的患者病例,而IntraAug专注于为每个人生成不同的配对数据。我们采用数据修剪技术来确保高质量的数据。各种任务的实验结果表明,PairAug优于仅关注图像或文本扩展的基线方法。
整篇读下来感觉工作量超级大,比起模型其实更加方法论,可复制性不太强kora
这篇关于PairAug:增强图像-文本对对放射学有什么用?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







