本文主要是介绍【语音识别】基于matlab语音分帧+端点检测+pitch提取+DTW算法歌曲识别【含Matlab源码 1057期】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✅博主简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,Matlab项目合作可私信。
🍎个人主页:海神之光
🏆代码获取方式:
海神之光Matlab王者学习之路—代码获取方式
⛳️座右铭:行百里者,半于九十。
更多Matlab仿真内容点击👇
Matlab图像处理(进阶版)
路径规划(Matlab)
神经网络预测与分类(Matlab)
优化求解(Matlab)
语音处理(Matlab)
信号处理(Matlab)
车间调度(Matlab)
⛄一、DTW简介
Dynamic Time Warping(DTW)诞生有一定的历史了(日本学者Itakura提出),它出现的目的也比较单纯,是一种衡量两个长度不同的时间序列的相似度的方法。应用也比较广,主要是在模板匹配中,比如说用在孤立词语音识别(识别两段语音是否表示同一个单词),手势识别,数据挖掘和信息检索等中。
1 概述
在大部分的学科中,时间序列是数据的一种常见表示形式。对于时间序列处理来说,一个普遍的任务就是比较两个序列的相似性。
在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,在语音识别领域表现为不同人的语速不同。因为语音信号具有相当大的随机性,即使同一个人在不同时刻发同一个音,也不可能具有完全的时间长度。而且同一个单词内的不同音素的发音速度也不同,比如有的人会把“A”这个音拖得很长,或者把“i”发的很短。在这些复杂情况下,使用传统的欧几里得距离无法有效地求的两个时间序列之间的距离(或者相似性)。
2 DTW方法原理
在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,在语音识别领域表现为不同人的语速不同。而且同一个单词内的不同音素的发音速度也不同,比如有的人会把“A”这个音拖得很长,或者把“i”发的很短。另外,不同时间序列可能仅仅存在时间轴上的位移,亦即在还原位移的情况下,两个时间序列是一致的。在这些复杂情况下,使用传统的欧几里得距离无法有效地求的两个时间序列之间的距离(或者相似性)。
DTW通过把时间序列进行延伸和缩短,来计算两个时间序列性之间的相似性:
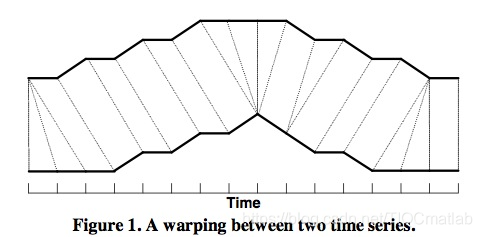
如上图所示,上下两条实线代表两个时间序列,时间序列之间的虚线代表两个时间序列之间的相似的点。DTW使用所有这些相似点之间的距离的和,称之为归整路径距离(Warp Path Distance)来衡量两个时间序列之间的相似性。
3 DTW计算方法
令要计算相似度的两个时间序列为X和Y,长度分别为|X|和|Y|。
归整路径(Warp Path)
归整路径的形式为W=w1,w2,…,wK,其中Max(|X|,|Y|)<=K<=|X|+|Y|。
wk的形式为(i,j),其中i表示的是X中的i坐标,j表示的是Y中的j坐标。
归整路径W必须从w1=(1,1)开始,到wK=(|X|,|Y|)结尾,以保证X和Y中的每个坐标都在W中出现。
另外,W中w(i,j)的i和j必须是单调增加的,以保证图1中的虚线不会相交,所谓单调增加是指:


上图为代价矩阵(Cost Matrix) D,D(i,j)表示长度为i和j的两个时间序列之间的归整路径距离。
⛄二、部分源代码
clc;
clear;
close all;
waveFile = sprintf(‘同桌的你.wav’);% 同桌的你 女儿情 回梦游仙 滴答 彩虹
% 读取波形—端点检测—切音框
waveFile=‘同桌的你.wav’;
pivFile = sprintf(‘同桌的你.piv’);
pivFile=[‘mfcc’ pivFile];
[y,fs]=audioread(waveFile); %读取原文件
figure
subplot(221)
plot(y);
title(‘原图形’);
frame = PointDetect(waveFile); %端点检测
subplot(222)
plot(frame);
title('端点检测');subplot(223)
pitch=wave2pitch(frame,fs); %计算音高
plot(pitch);
title('音高');
function [pitch, pdf, frameEstimated, excitation]=frame2pitch(frame, opt, showPlot)
% frame2acf: PDF (periodicity detection function) of a given frame (primarily for pitch tracking)
%
% Usage:
% out=frame2pdf(frame, opt, showPlot);
% frame: Given frame
% opt: Options for PDF computation
% opt.pdf: PDF function to be used
% ‘acf’ for ACF
% ‘amdf’ for AMDF
% ‘nsdf’ for NSDF
% ‘acfOverAmdf’ for ACF divided by AMDF
% ‘hps’ for harmonics product sum
% ‘ceps’ for cepstrum
% opt.maxShift: no. of shift operations, which is equal to the length of the output vector
% opt.method: 1 for using the whole frame for shifting
% 2 for using the whole frame for shifting, but normalize the sum by it’s overlap area
% 3 for using frame(1:frameSize-maxShift) for shifting
% opt.siftOrder: order of SIFT (0 for not using SIFT)
% showPlot: 0 for no plot, 1 for plotting the frame and ACF output
% out: the returned PDF vector
%
% Example:
% waveFile=‘soo.wav’;
% au=myAudioRead(waveFile);
% frameSize=256;
% frameMat=enframe(au.signal, frameSize);
% frame=frameMat(:, 292);
% opt=ptOptSet(au.fs, au.nbits, 1);
% opt.alpha=0;
% pitch=frame2pitch(frame, opt, 1);
%
% See also frame2acf, frame2amdf, frame2nsdf.
% Roger Jang 20020404, 20041013, 20060313
if nargin<1, selfdemo; return; end
if nargin<2||isempty(opt), opt=ptOptSet(8000, 16, 1); end
if nargin<3, showPlot=0; end
%% ====== Preprocessing
%save frame frame
frame=frameZeroMean(frame, opt.zeroMeanPolyOrder);
%frame=frameZeroMean(frame, 0);
frameEstimated=[];
excitation=[];
if opt.siftOrder>0
[frameEstimated, excitation, coef]=sift(frame, opt.siftOrder); % Simple inverse filtering tracking
frame=excitation;
end
frameSize=length(frame);
maxShift=min(frameSize, opt.maxShift);
switch lower(opt.pdf)
case ‘acf’
% pdf=frame2acf(frame, maxShift, opt.method);
pdf=frame2acfMex(frame, maxShift, opt.method);
% if opt.method1
% pdfWeight=1+linspace(0, opt.alpha, length(pdf))';
% pdf=pdf.*pdfWeight; % To avoid double pitch error (esp for violin). 20110416
% end
% if opt.method2
% pdfWeight=1-linspace(0, opt.alpha, length(pdf))‘; % alpha is less than 1.
% pdf=pdf.pdfWeight; % To avoid double pitch error (esp for violin). 20110416
% end
pdfLen=length(pdf);
pdfWeight=opt.alpha+pdfLen(1-opt.alpha)./(pdfLen-(0:pdfLen-1)’);
pdf=pdf.pdfWeight; % alpha=0==>normalized ACF, alpha=1==>tapering ACF
case ‘amdf’
% amdf=frame2amdf(frame, maxShift, opt.method);
amdf=frame2amdfMex(frame, maxShift, opt.method);
pdf=max(amdf)(1-linspace(0,1,length(amdf))')-amdf;
case ‘nsdf’
% pdf=frame2nsdf(frame, maxShift, opt.method);
pdf=frame2nsdfMex(frame, maxShift, opt.method);
case ‘acfoveramdf’
opt.pdf=‘acf’;
[acfPitch, acf] =feval(mfilename, frame, opt);
opt.pdf=‘amdf’;
[amdfPitch, amdf]=feval(mfilename, frame, opt);
pdf=0*acf;
pdf(2:end)=acf(2:end)./amdf(2:end);
case ‘hps’
[pdf, freq]=frame2hps(frame, opt.fs, opt.zeroPaddedFactor);
case ‘ceps’
pdf=frame2ceps(frame, opt.fs, opt.zeroPaddedFactor);
otherwise
error(‘Unknown PDF=%s!’, opt.pdf);
end
switch lower(opt.pdf)
case {‘acf’, ‘amdf’, ‘nsdf’, ‘amdf4pt’, ‘acfoveramdf’, ‘ceps’}
n1=floor(opt.fs/opt.freqRange(2)); % pdf(1:n1) will not be used
n2= ceil(opt.fs/opt.freqRange(1)); % pdf(n2:end) will not be used
if n2>length(pdf), n2=length(pdf); end
% Update n1 such that pdf(n1)<=pdf(n1+1)
while n1<n2 & pdf(n1)>pdf(n1+1), n1=n1+1; end
% Update n2 such that pdf(n2)<=pdf(n2-1)
while n2>n1 & pdf(n2)>pdf(n2-1), n2=n2-1; end
pdf2=pdf;
pdf2(1:n1)=-inf;
pdf2(n2:end)=-inf;
[maxValue, maxIndex]=max(pdf2);
if isinf(maxValue) || maxIndexn1+1 || maxIndexn2-1
pitch=0; maxIndex=nan; maxValue=nan;
elseif opt.useParabolicFit
deviation=optimViaParabolicFit(pdf(maxIndex-1:maxIndex+1));
maxIndex=maxIndex+deviation;
pitch=freq2pitch(opt.fs/(maxIndex-1));
else
pitch=freq2pitch(opt.fs/(maxIndex-1));
end
case {‘hps’}
pdf2=pdf;
pdf2(freq<opt.freqRange(1)|freq>opt.freqRange(2))=-inf;
[maxValue, maxIndex]=max(pdf2);
% if opt.useParabolicFit
% deviation=optimViaParabolicFit(pdf(maxIndex-1:maxIndex+1));
% maxIndex=maxIndex+deviation;
% end
pitch=freq2pitch(freq(maxIndex));
otherwise
error(‘Unknown PDF=%s!’, opt.pdf);
end
if showPlot
subplot(2,1,1);
plot(frame, ‘.-’);
set(gca, ‘xlim’, [-inf inf]);
title(‘Input frame’);
subplot(2,1,2);
plot(1:length(pdf), pdf, ‘.-’, 1:length(pdf2), pdf2, ‘.r’);
line(maxIndex, maxValue, ‘marker’, ‘^’, ‘color’, ‘k’);
set(gca, ‘xlim’, [-inf inf]);
title(sprintf(‘%s vector (opt.method = %d)’, opt.pdf, opt.method));
end
% ====== Self demo
function selfdemo
mObj=mFileParse(which(mfilename));
strEval(mObj.example);
⛄三、运行结果

⛄四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
🍅 仿真咨询
1 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化
2 机器学习和深度学习方面
卷积神经网络(CNN)、LSTM、支持向量机(SVM)、最小二乘支持向量机(LSSVM)、极限学习机(ELM)、核极限学习机(KELM)、BP、RBF、宽度学习、DBN、RF、RBF、DELM、XGBOOST、TCN实现风电预测、光伏预测、电池寿命预测、辐射源识别、交通流预测、负荷预测、股价预测、PM2.5浓度预测、电池健康状态预测、水体光学参数反演、NLOS信号识别、地铁停车精准预测、变压器故障诊断
3 图像处理方面
图像识别、图像分割、图像检测、图像隐藏、图像配准、图像拼接、图像融合、图像增强、图像压缩感知
4 路径规划方面
旅行商问题(TSP)、车辆路径问题(VRP、MVRP、CVRP、VRPTW等)、无人机三维路径规划、无人机协同、无人机编队、机器人路径规划、栅格地图路径规划、多式联运运输问题、车辆协同无人机路径规划、天线线性阵列分布优化、车间布局优化
5 无人机应用方面
无人机路径规划、无人机控制、无人机编队、无人机协同、无人机任务分配
6 无线传感器定位及布局方面
传感器部署优化、通信协议优化、路由优化、目标定位优化、Dv-Hop定位优化、Leach协议优化、WSN覆盖优化、组播优化、RSSI定位优化
7 信号处理方面
信号识别、信号加密、信号去噪、信号增强、雷达信号处理、信号水印嵌入提取、肌电信号、脑电信号、信号配时优化
8 电力系统方面
微电网优化、无功优化、配电网重构、储能配置
9 元胞自动机方面
交通流 人群疏散 病毒扩散 晶体生长
10 雷达方面
卡尔曼滤波跟踪、航迹关联、航迹融合
这篇关于【语音识别】基于matlab语音分帧+端点检测+pitch提取+DTW算法歌曲识别【含Matlab源码 1057期】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








