本文主要是介绍书生·浦语大模型实战营之茴香豆:搭建你的 RAG 智能助理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
书生·浦语大模型实战营之茴香豆:搭建你的 RAG 智能助理

RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。
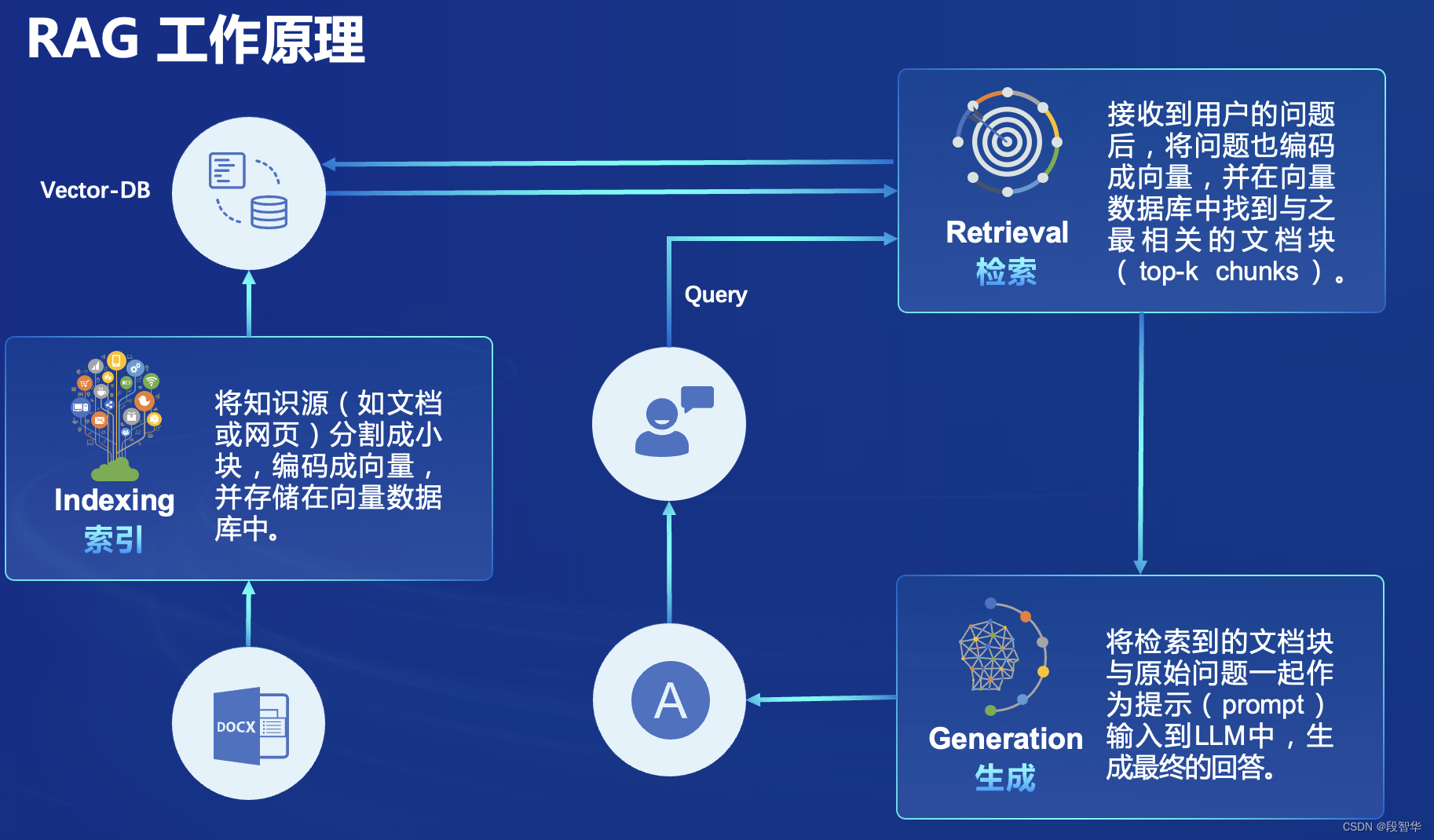
RAG 能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。本次课程选用的茴香豆应用,就应用了 RAG 技术,可以快速、高效的搭建自己的知识领域助手。
https://github.com/InternLM/HuixiangDou
论文
https://arxiv.org/pdf/2401.08772.pdf

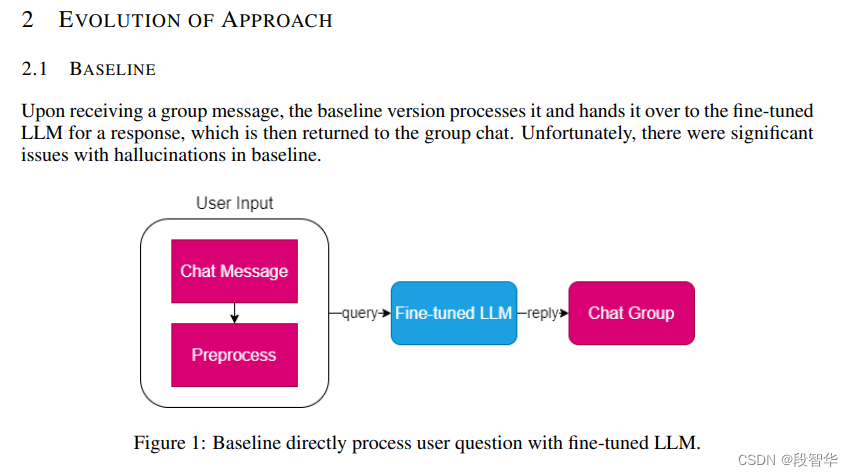
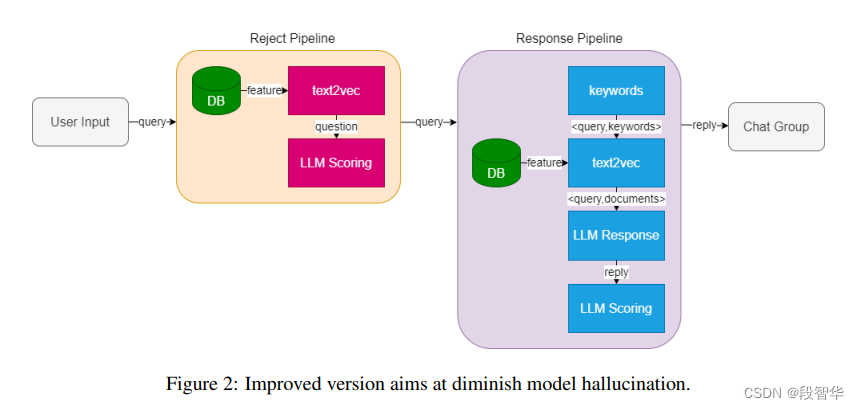
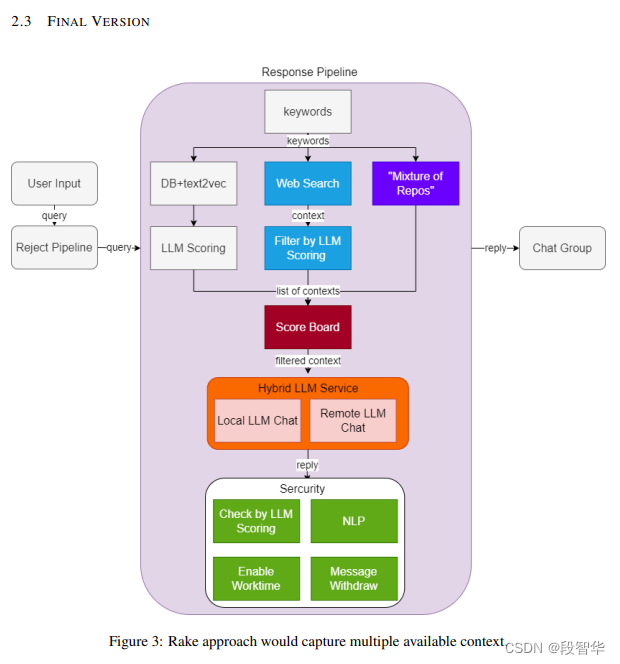
RAG 效果比对
如图所示,由于茴香豆是一款比较新的应用, InternLM2-Chat-7B 训练数据库中并没有收录到它的相关信息。图中关于 huixiangdou 的 3 轮问答均未给出准确的答案。

未对 InternLM2-Chat-7B 进行任何增训的情况下,通过 RAG 技术实现的新增知识问答。

配置基础环境
在 Intern Studio 服务器上部署茴香豆
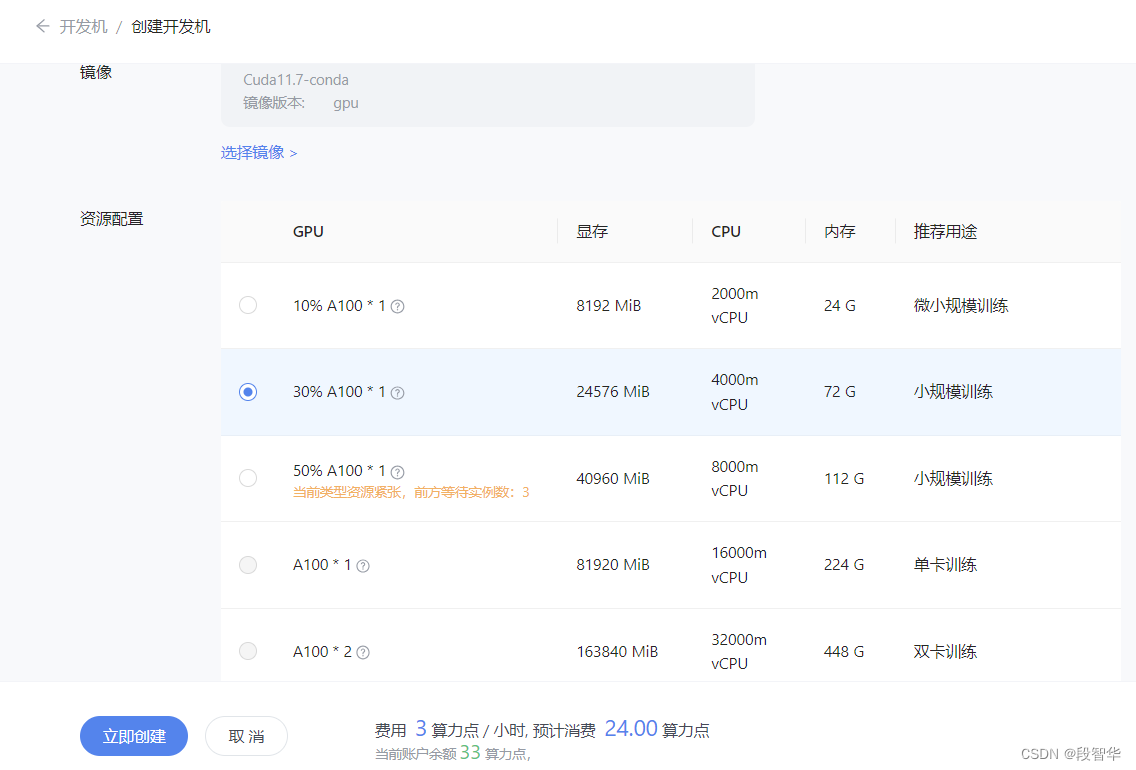
进入开发机后,从官方环境复制运行 InternLM 的基础环境,命名为 InternLM2_Huixiangdou,在命令行模式下运行
studio-conda -o internlm-base -t InternLM2_Huixiangdou运行 conda 命令,激活 InternLM2_Huixiangdou python 虚拟环境
conda activate InternLM2_Huixiangdou
下载基础文件
复制茴香豆所需模型文件,为了减少下载和避免 HuggingFace 登录问题,所有作业和教程涉及的模型都已经存放在 Intern Studio 开发机共享文件中。本教程选用 InternLM2-Chat-7B 作为基础模型。
# 创建模型文件夹
cd /root && mkdir models# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maidalun1020/bce-reranker-base_v1 /root/models/bce-reranker-base_v1# 复制大模型参数(下面的模型,根据作业进度和任务进行**选择一个**就行)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b
下载安装茴香豆
cd /root
# 下载 repo
git clone https://github.com/internlm/huixiangdou && cd huixiangdou
git checkout 447c6f7e68a1657fce1c4f7c740ea1700bde0440
安装茴香豆运行所需依赖。

使用茴香豆搭建 RAG 助手
2.1 修改配置文件
用已下载模型的路径替换 /root/huixiangdou/config.ini 文件中的默认模型,需要修改 3 处模型地址,分别是:
sed -i '6s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini用于检索的重排序模型
sed -i '7s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
和本次选用的大模型
sed -i '29s#.*#local_llm_path = "/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b"#' /root/huixiangdou/config.ini
命令行输入下面的命令,修改用于向量数据库和词嵌入的模型
sed -i '6s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini
sed -i '7s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
sed -i '29s#.*#local_llm_path = "/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b"#' /root/huixiangdou/config.ini

2.2 创建知识库
本示例中,使用 InternLM 的 Huixiangdou 文档作为新增知识数据检索来源,在不重新训练的情况下,打造一个 Huixiangdou 技术问答助手。
首先,下载 Huixiangdou 语料
cd /root/huixiangdou && mkdir repodirgit clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou
提取知识库特征,创建向量数据库。数据库向量化的过程应用到了 LangChain 的相关模块,默认嵌入和重排序模型调用的网易 BCE 双语模型,如果没有在 config.ini 文件中指定本地模型路径,茴香豆将自动从 HuggingFace 拉取默认模型。
除了语料知识的向量数据库,茴香豆建立接受和拒答两个向量数据库,用来在检索的过程中更加精确的判断提问的相关性,这两个数据库的来源分别是:
接受问题列表,希望茴香豆助手回答的示例问题
存储在 huixiangdou/resource/good_questions.json 中
拒绝问题列表,希望茴香豆助手拒答的示例问题
存储在 huixiangdou/resource/bad_questions.json 中
其中多为技术无关的主题或闲聊
如:“nihui 是谁”, “具体在哪些位置进行修改?”, “你是谁?”, “1+1”
运行下面的命令,增加茴香豆相关的问题到接受问题示例中:
cd /root/huixiangdou
mv resource/good_questions.json resource/good_questions_bk.jsonecho '["mmpose中怎么调用mmyolo接口","mmpose实现姿态估计后怎么实现行为识别","mmpose执行提取关键点命令不是分为两步吗,一步是目标检测,另一步是关键点提取,我现在目标检测这部分的代码是demo/topdown_demo_with_mmdet.py demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth 现在我想把这个mmdet的checkpoints换位yolo的,那么应该怎么操作","在mmdetection中,如何同时加载两个数据集,两个dataloader","如何将mmdetection2.28.2的retinanet配置文件改为单尺度的呢?","1.MMPose_Tutorial.ipynb、inferencer_demo.py、image_demo.py、bottomup_demo.py、body3d_pose_lifter_demo.py这几个文件和topdown_demo_with_mmdet.py的区别是什么,\n2.我如果要使用mmdet是不是就只能使用topdown_demo_with_mmdet.py文件,","mmpose 测试 map 一直是 0 怎么办?","如何使用mmpose检测人体关键点?","我使用的数据集是labelme标注的,我想知道mmpose的数据集都是什么样式的,全都是单目标的数据集标注,还是里边也有多目标然后进行标注","如何生成openmmpose的c++推理脚本","mmpose","mmpose的目标检测阶段调用的模型,一定要是demo文件夹下的文件吗,有没有其他路径下的文件","mmpose可以实现行为识别吗,如果要实现的话应该怎么做","我在mmyolo的v0.6.0 (15/8/2023)更新日志里看到了他新增了支持基于 MMPose 的 YOLOX-Pose,我现在是不是只需要在mmpose/project/yolox-Pose内做出一些设置就可以,换掉demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py 改用mmyolo来进行目标检测了","mac m1从源码安装的mmpose是x86_64的","想请教一下mmpose有没有提供可以读取外接摄像头,做3d姿态并达到实时的项目呀?","huixiangdou 是什么?","使用科研仪器需要注意什么?","huixiangdou 是什么?","茴香豆 是什么?","茴香豆 能部署到微信吗?","茴香豆 怎么应用到飞书","茴香豆 能部署到微信群吗?","茴香豆 怎么应用到飞书群","huixiangdou 能部署到微信吗?","huixiangdou 怎么应用到飞书","huixiangdou 能部署到微信群吗?","huixiangdou 怎么应用到飞书群","huixiangdou","茴香豆","茴香豆 有哪些应用场景","huixiangdou 有什么用","huixiangdou 的优势有哪些?","茴香豆 已经应用的场景","huixiangdou 已经应用的场景","huixiangdou 怎么安装","茴香豆 怎么安装","茴香豆 最新版本是什么","茴香豆 支持哪些大模型","茴香豆 支持哪些通讯软件","config.ini 文件怎么配置","remote_llm_model 可以填哪些模型?"
]' > /root/huixiangdou/resource/good_questions.json
再创建一个测试用的问询列表,用来测试拒答流程是否起效:
cd /root/huixiangdouecho '[
"huixiangdou 是什么?",
"你好,介绍下自己"
]' > ./test_queries.json
在确定好语料来源后,运行下面的命令,创建 RAG 检索过程中使用的向量数据库:
# 创建向量数据库存储目录
cd /root/huixiangdou && mkdir workdir # 分别向量化知识语料、接受问题和拒绝问题中后保存到 workdir
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json向量数据库的创建需要等待一小段时间,过程约占用 1.6G 显存。
完成后,Huixiangdou 相关的新增知识就以向量数据库的形式存储在 workdir 文件夹下。
检索过程中,茴香豆会将输入问题与两个列表中的问题在向量空间进行相似性比较,判断该问题是否应该回答,避免群聊过程中的问答泛滥。确定的回答的问题会利用基础模型提取关键词,在知识库中检索 top K 相似的 chunk,综合问题和检索到的 chunk 生成答案

2.3 运行茴香豆知识助手
我们已经提取了知识库特征,并创建了对应的向量数据库。现在,让我们来测试一下效果:
命令行运行:
# 填入问题
sed -i '74s/.*/ queries = ["huixiangdou 是什么?", "茴香豆怎么部署到微信群", "今天天气怎么样?"]/' /root/huixiangdou/huixiangdou/main.py# 运行茴香豆
cd /root/huixiangdou/
python3 -m huixiangdou.main --standalone
(InternLM2_Huixiangdou) root@intern-studio-061925:~/huixiangdou# cd /root/huixiangdou/
(InternLM2_Huixiangdou) root@intern-studio-061925:~/huixiangdou# python3 -m huixiangdou.main --standalone
/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/langchain/embeddings/__init__.py:29: LangChainDeprecationWarning: Importing embeddings from langchain is deprecated. Importing from langchain will no longer be supported as of langchain==0.2.0. Please import from langchain-community instead:`from langchain_community.embeddings import HuggingFaceEmbeddings`.To install langchain-community run `pip install -U langchain-community`.warnings.warn(
/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/langchain/embeddings/__init__.py:29: LangChainDeprecationWarning: Importing embeddings from langchain is deprecated. Importing from langchain will no longer be supported as of langchain==0.2.0. Please import from langchain-community instead:`from langchain_community.embeddings import HuggingFaceEmbeddings`.To install langchain-community run `pip install -U langchain-community`.warnings.warn(
2024-04-07 22:04:27.498 | INFO | __main__:run:180 - waiting for server to be ready..
2024-04-07 22:04:30.501 | INFO | __main__:run:180 - waiting for server to be ready..
2024-04-07 22:04:33.596 | INFO | __main__:run:180 - waiting for server to be ready..
2024-04-07 22:04:36.599 | INFO | __main__:run:180 - waiting for server to be ready..
04/07/2024 22:04:39 - [INFO] -accelerate.utils.modeling->>> We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set `max_memory` in to a higher value to use more memory (at your own risk).
Loading checkpoint shards: 0%| | 0/8 [00:00<?, ?it/s]2024-04-07 22:04:39.602 | INFO | __main__:run:180 - waiting for server to be ready..
Loading checkpoint shards: 12%|█████████ | 1/8 [00:02<00:17, 2.53s/it]2024-04-07 22:04:42.605 | INFO | __main__:run:180 - waiting for server to be ready..
Loading checkpoint shards: 25%|██████████████████ | 2/8 [00:05<00:14, 2.50s/it]2024-04-07 22:04:45.608 | INFO | __main__:run:180 - waiting for server to be ready..
Loading checkpoint shards: 38%|███████████████████████████ | 3/8 [00:07<00:12, 2.56s/it]2024-04-07 22:04:48.611 | INFO | __main__:run:180 - waiting for server to be ready..
Loading checkpoint shards: 50%|████████████████████████████████████ | 4/8 [00:10<00:10, 2.56s/it]2024-04-07 22:04:51.614 | INFO | __main__:run:180 - waiting for server to be ready..
Loading checkpoint shards: 62%|█████████████████████████████████████████████ | 5/8 [00:12<00:07, 2.59s/it]2024-04-07 22:04:54.617 | INFO | __main__:run:180 - waiting for server to be ready..
Loading checkpoint shards: 75%|██████████████████████████████████████████████████████ | 6/8 [00:15<00:05, 2.59s/it]2024-04-07 22:04:57.620 | INFO | __main__:run:180 - waiting for server to be ready..
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████| 8/8 [00:20<00:00, 2.54s/it]
======== Running on http://0.0.0.0:8888 ========
(Press CTRL+C to quit)
2024-04-07 22:05:00.623 | INFO | __main__:run:187 - Hybrid LLM Server start.
2024-04-07 22:05:00.625 | INFO | __main__:run:192 - Config loaded.
2024-04-07 22:05:00.626 | INFO | huixiangdou.service.retriever:__init__:202 - loading test2vec and rerank models
04/07/2024 22:05:05 - [INFO] -sentence_transformers.SentenceTransformer->>> Load pretrained SentenceTransformer: /root/models/bce-embedding-base_v1
/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/torch/_utils.py:776: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()return self.fget.__get__(instance, owner)()
04/07/2024 22:05:13 - [INFO] -BCEmbedding.models.RerankerModel->>> Loading from `/root/models/bce-reranker-base_v1`.
04/07/2024 22:05:15 - [INFO] -BCEmbedding.models.RerankerModel->>> Execute device: cuda; gpu num: 1; use fp16: True
04/07/2024 22:05:15 - [INFO] -faiss.loader->>> Loading faiss with AVX2 support.
04/07/2024 22:05:15 - [INFO] -faiss.loader->>> Could not load library with AVX2 support due to:
ModuleNotFoundError("No module named 'faiss.swigfaiss_avx2'")
04/07/2024 22:05:15 - [INFO] -faiss.loader->>> Loading faiss.
04/07/2024 22:05:15 - [INFO] -faiss.loader->>> Successfully loaded faiss.
/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/transformers/generation/configuration_utils.py:492: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.8` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.warnings.warn(
/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/transformers/generation/configuration_utils.py:497: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.8` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.warnings.warn(
/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/transformers/generation/configuration_utils.py:509: UserWarning: `do_sample` is set to `False`. However, `top_k` is set to `1` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_k`.warnings.warn(
2024-04-07 22:05:19.537 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('“huixiangdou 是什么?”\n请仔细阅读以上内容,判断句子是否是个有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。\n判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释。', '根据您提供的内容,我无法判断"huixiangdou 是什么?" 这个句子的主题,因为它不包含任何有关于主题的信息。所以,我无法给出 0~10 的分数。请提供更具体的信息,以便我能够更准确地评估。')
2024-04-07 22:05:19.537 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。
判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释 A:根据您提供的内容,我无法判断"huixiangdou 是什么?" 这个句子的主题,因为它不包含任何有关于主题的信息。所以,我无法给出 0~10 的分数。请提供更具体的信息,以便我能够更准确地评估。 remote local timecost 3.8726747035980225
04/07/2024 22:05:19 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:05:15 +0800] "POST /inference HTTP/1.1" 200 661 "-" "python-requests/2.31.0"
2024-04-07 22:05:20.198 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('告诉我这句话的主题,直接说主题不要解释:“huixiangdou 是什么?”', '主题:"huixiangdou" 的含义或定义。')
2024-04-07 22:05:20.198 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:告诉我这句话的主题,直接说主题不要解释:“huixiangdou 是什么? A:主题:"huixiangdou" 的含义或定义。 remote local timecost 0.6537926197052002
04/07/2024 22:05:20 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:05:19 +0800] "POST /inference HTTP/1.1" 200 246 "-" "python-requests/2.31.0"
You're using a XLMRobertaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
2024-04-07 22:05:22.347 | INFO | huixiangdou.service.retriever:query:158 - target README.md file length 15394
2024-04-07 22:05:22.348 | DEBUG | huixiangdou.service.retriever:query:185 - query:主题:"huixiangdou" 的含义或定义。 top1 file:README.md
2024-04-07 22:05:23.087 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('问题:“huixiangdou 是什么?”\n材料:“ <img alt="youtube" src="https://img.shields.io/badge/youtube-black?logo=youtube&logocolor=red" />\n</a>\n<a href="https://www.bilibili.com/video/bv1s2421n7mn" target="_blank">\n<img alt="bilibili" src="https://img.shields.io/badge/bilibili-pink?logo=bilibili&logocolor=white" />\n</a>\n<a href="https://discord.gg/tw4zbpzz" target="_blank">\n<img alt="discord" src="https://img.shields.io/badge/discord-red?logo=discord&logocolor=white" />\n</a>\n</div> \n</div> \nhuixiangdou is a **group chat** assistant based on llm (large language model). \nadvantages: \n1. design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772”\n请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。\n', '8')
2024-04-07 22:05:23.087 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:flooding, see arxiv2401.08772”
请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。 A:8 remote local timecost 0.7367064952850342
04/07/2024 22:05:23 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:05:22 +0800] "POST /inference HTTP/1.1" 200 171 "-" "python-requests/2.31.0"
2024-04-07 22:05:23.089 | WARNING | huixiangdou.service.llm_client:generate_response:95 - disable remote LLM while choose remote LLM, auto fixed
2024-04-07 22:05:47.063 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('材料:“ <img alt="youtube" src="https://img.shields.io/badge/youtube-black?logo=youtube&logocolor=red" />\n</a>\n<a href="https://www.bilibili.com/video/bv1s2421n7mn" target="_blank">\n<img alt="bilibili" src="https://img.shields.io/badge/bilibili-pink?logo=bilibili&logocolor=white" />\n</a>\n<a href="https://discord.gg/tw4zbpzz" target="_blank">\n<img alt="discord" src="https://img.shields.io/badge/discord-red?logo=discord&logocolor=white" />\n</a>\n</div> \n</div> \nhuixiangdou is a **group chat** assistant based on llm (large language model). \nadvantages: \n1. design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772\nEnglish | [简体中文](README_zh.md)\n<div align="center">\n<img src="resource/logo_black.svg" width="555px"/>\n<div align="center">\n <a href="resource/figures/wechat.jpg" target="_blank">\n <img alt="Wechat" src="https://img.shields.io/badge/wechat-robot%20inside-brightgreen?logo=wechat&logoColor=white" />\n </a>\n <a href="https://arxiv.org/abs/2401.08772" target="_blank">\n <img alt="Arxiv" src="https://img.shields.io/badge/arxiv-paper%20-darkred?logo=arxiv&logoColor=white" />\n </a>\n <a href="https://pypi.org/project/huixiangdou" target="_blank">\n <img alt="PyPI" src="https://img.shields.io/badge/PyPI-install-blue?logo=pypi&logoColor=white" />\n </a>\n <a href="https://youtu.be/ylXrT-Tei-Y" target="_blank">\n <img alt="YouTube" src="https://img.shields.io/badge/YouTube-black?logo=youtube&logoColor=red" />\n </a>\n <a href="https://www.bilibili.com/video/BV1S2421N7mn" target="_blank">\n <img alt="BiliBili" src="https://img.shields.io/badge/BiliBili-pink?logo=bilibili&logoColor=white" />\n </a>\n <a href="https://discord.gg/TW4ZBpZZ" target="_blank">\n <img alt="discord" src="https://img.shields.io/badge/discord-red?logo=discord&logoColor=white" />\n </a>\n</div>\n</div>\nHuixiangDou is a **group chat** assistant based on LLM (Large Language Model). \nAdvantages:\n1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see [arxiv2401.08772](https://arxiv.org/abs/2401.08772)\n2. Low cost, requiring only 1.5GB memory and no need for training\n3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable\nCheck out the [scenes in which HuixiangDou are running](./huixiangdou-inside.md) and join [WeChat Group](resource/figures/wechat.jpg) to try AI assistant inside.\nIf this helps you, please give it a star ⭐\n# 🔆 News\nThe web portal is available on [OpenXLab](https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web), where you can build your own knowledge assistant without any coding, using WeChat and Feishu groups.\nVisit web portal usage video on [YouTube](https://www.youtube.com/watch?v=ylXrT-Tei-Y) and [BiliBili](https://www.bilibili.com/video/BV1S2421N7mn).\n- \\[2024/04\\]”\n 问题:“huixiangdou 是什么?” \n 请仔细阅读参考材料回答问题。', 'HuixiangDou 是一个基于 LLM(大型语言模型)的群组聊天助手。它使用两阶段管道来处理群组聊天场景,以回答用户问题,而不会导致信息过载。该工具的优点包括:\n\n1. 两阶段管道:HuixiangDou 使用一个两阶段管道来处理群组聊天。首先,它使用一个预训练的模型来快速判断一个消息是否需要被处理。如果消息需要被处理,它将使用另一个模型来生成回答。这种设计可以避免信息过载,并提高处理效率。\n2. 低成本:HuixiangDou 只需要 1.5GB 的内存,并且不需要进行训练,因此它的成本相对较低。\n3. 完整套件:HuixiangDou 提供了 Web、Android 和管道源代码的完整套件,这些代码是工业级和商业上可行的。\n4. 运行场景:HuixiangDou 已经在多个场景中运行,包括 WeChat 和 Feishu 群组。\n5. 开源:HuixiangDou 的源代码是开源的,并且可以在 [OpenXLab](https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web) 上使用,用户可以轻松地构建自己的知识助手,而无需编写任何代码。\n\nHuixiangDou 的更多信息可以在 [arxiv2401.08772](https://arxiv.org/abs/2401.08772) 论文中找到。')
2024-04-07 22:05:47.063 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:https://www.bilibili.com/video/BV1S2421N7mn).
- \[2024/04\]”问题:“huixiangdou 是什么?”请仔细阅读参考材料回答问题 A:HuixiangDou 是一个基于 LLM(大型语言模型)的群组聊天助手。它使用两阶段管道来处理群组聊天场景,以回答用户问题,而不会导致信息过载。该工具的优点包括:1. 两阶段管道:HuixiangDou 使用一个两阶段管道来处理群组聊天。首先,它使用一个预训练的模型来快速判断一个消息是否需要被处理。如果消息需要被处理,它将使用另一个模型来生成回答。这种设计可以避免信息过载,并提高处理效率。
2. 低成本:HuixiangDou 只需要 1.5GB 的内存,并且不需要进行训练,因此它的成本相对较低。
3. 完整套件:HuixiangDou 提供了 Web、Android 和管道源代码的完整套件,这些代码是工业级和商业上可行的。
4. 运行场景:HuixiangDou 已经在多个场景中运行,包括 WeChat 和 Feishu 群组。
5. 开源:HuixiangDou 的源代码是开源的,并且可以在 [OpenXLab](https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web) 上使用,用户可以轻松地构建自己的知识助手,而无需编写任何代码。HuixiangDou 的更多信息可以在 [arxiv2401.08772](https://arxiv.org/abs/2401.08772) 论文中找到。 remote local timecost 23.97290277481079
04/07/2024 22:05:47 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:05:23 +0800] "POST /inference HTTP/1.1" 200 2369 "-" "python-requests/2.31.0"
2024-04-07 22:05:47.078 | INFO | __main__:lark_send_only:79 - ErrorCode.SUCCESS, huixiangdou 是什么?, HuixiangDou 是一个基于 LLM(大型语言模型)的群组聊天助手。它使用两阶段管道来处理群组聊天场景,以回答用户问题,而不会导致信息过载。该工具的优点包括:1. 两阶段管道:HuixiangDou 使用一个两阶段管道来处理群组聊天。首先,它使用一个预训练的模型来快速判断一个消息是否需要被处理。如果消息需要被处理,它将使用另一个模型来生成回答。这种设计可以避免信息过载,并提高处理效率。
2. 低成本:HuixiangDou 只需要 1.5GB 的内存,并且不需要进行训练,因此它的成本相对较低。
3. 完整套件:HuixiangDou 提供了 Web、Android 和管道源代码的完整套件,这些代码是工业级和商业上可行的。
4. 运行场景:HuixiangDou 已经在多个场景中运行,包括 WeChat 和 Feishu 群组。
5. 开源:HuixiangDou 的源代码是开源的,并且可以在 [OpenXLab](https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web) 上使用,用户可以轻松地构建自己的知识助手,而无需编写任何代码。HuixiangDou 的更多信息可以在 [arxiv2401.08772](https://arxiv.org/abs/2401.08772) 论文中找到。, ['README.md']
2024-04-07 22:05:49.793 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('“茴香豆怎么部署到微信群”\n请仔细阅读以上内容,判断句子是否是个有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。\n判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释。', '8.0\n\n该句子是一个有主语、谓语和宾语的疑问句,主语是"茴香豆",谓语是"怎么部署",宾语是"到微信群"。虽然句子中没有使用"是"、"吗"等疑问词,但句子的结构符合疑问句的特征,因此得分8.0。')
2024-04-07 22:05:49.794 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。
判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释 A:8.0该句子是一个有主语、谓语和宾语的疑问句,主语是"茴香豆",谓语是"怎么部署",宾语是"到微信群"。虽然句子中没有使用"是"、"吗"等疑问词,但句子的结构符合疑问句的特征,因此得分8.0。 remote local timecost 2.704132556915283
04/07/2024 22:05:49 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:05:47 +0800] "POST /inference HTTP/1.1" 200 681 "-" "python-requests/2.31.0"
2024-04-07 22:05:50.118 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('告诉我这句话的主题,直接说主题不要解释:“茴香豆怎么部署到微信群”', '主题:茴香豆的微信部署。')
2024-04-07 22:05:50.118 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:告诉我这句话的主题,直接说主题不要解释:“茴香豆怎么部署到微信群 A:主题:茴香豆的微信部署。 remote local timecost 0.3102278709411621
04/07/2024 22:05:50 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:05:49 +0800] "POST /inference HTTP/1.1" 200 242 "-" "python-requests/2.31.0"
2024-04-07 22:05:50.773 | INFO | huixiangdou.service.retriever:query:158 - target README_zh.md file length 11539
2024-04-07 22:05:50.773 | DEBUG | huixiangdou.service.retriever:query:185 - query:主题:茴香豆的微信部署。 top1 file:README_zh.md
2024-04-07 22:05:53.404 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('问题:“茴香豆怎么部署到微信群”\n材料:“ <img alt="youtube" src="https://img.shields.io/badge/youtube-black?logo=youtube&logocolor=red" />\n</a>\n<a href="https://www.bilibili.com/video/bv1s2421n7mn" target="_blank">\n<img alt="bilibili" src="https://img.shields.io/badge/bilibili-pink?logo=bilibili&logocolor=white" />\n</a>\n<a href="https://discord.gg/tw4zbpzz" target="_blank">\n<img alt="discord" src="https://img.shields.io/badge/discord-red?logo=discord&logocolor=white" />\n</a>\n</div> \n</div> \n茴香豆是一个基于 llm 的**群聊**知识助手,优势: \n1. 设计拒答、响应两阶段 pipeline 应对群聊场景,解答问题同时不会消息泛滥。精髓见技术报告\n2. 成本低至 1.5g 显存,无需训练适用各行业\n3. 提供一整套前后端 web、android、算法源码,工业级开源可商用 \n查看茴香豆已运行在哪些场景;加入微信群直接体验群聊助手效果。 \n如果对你有用,麻烦 star 一下⭐”\n请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。\n', '8.0分\n\n该问题与材料有较高的关联度,因为材料中提到了茴香豆是一个基于llm的群聊知识助手,并提供了其特点和优势,以及茴香菜豆的运行场景和体验方式。这与问题中关于茴香菜豆的部署到微信群是相关的。')
2024-04-07 22:05:53.405 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:验群聊助手效果。
如果对你有用,麻烦 star 一下⭐”
请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。 A:8.0分该问题与材料有较高的关联度,因为材料中提到了茴香豆是一个基于llm的群聊知识助手,并提供了其特点和优势,以及茴香菜豆的运行场景和体验方式。这与问题中关于茴香菜豆的部署到微信群是相关的。 remote local timecost 2.628042697906494
04/07/2024 22:05:53 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:05:50 +0800] "POST /inference HTTP/1.1" 200 721 "-" "python-requests/2.31.0"
2024-04-07 22:05:53.408 | WARNING | huixiangdou.service.llm_client:generate_response:95 - disable remote LLM while choose remote LLM, auto fixed
2024-04-07 22:06:34.131 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('材料:“ <img alt="youtube" src="https://img.shields.io/badge/youtube-black?logo=youtube&logocolor=red" />\n</a>\n<a href="https://www.bilibili.com/video/bv1s2421n7mn" target="_blank">\n<img alt="bilibili" src="https://img.shields.io/badge/bilibili-pink?logo=bilibili&logocolor=white" />\n</a>\n<a href="https://discord.gg/tw4zbpzz" target="_blank">\n<img alt="discord" src="https://img.shields.io/badge/discord-red?logo=discord&logocolor=white" />\n</a>\n</div> \n</div> \n茴香豆是一个基于 llm 的**群聊**知识助手,优势: \n1. 设计拒答、响应两阶段 pipeline 应对群聊场景,解答问题同时不会消息泛滥。精髓见技术报告\n2. 成本低至 1.5g 显存,无需训练适用各行业\n3. 提供一整套前后端 web、android、算法源码,工业级开源可商用 \n查看茴香豆已运行在哪些场景;加入微信群直接体验群聊助手效果。 \n如果对你有用,麻烦 star 一下⭐\n[English](README.md) | 简体中文\n<div align="center">\n<img src="resource/logo_black.svg" width="555px"/>\n<div align="center">\n <a href="resource/figures/wechat.jpg" target="_blank">\n <img alt="Wechat" src="https://img.shields.io/badge/wechat-robot%20inside-brightgreen?logo=wechat&logoColor=white" />\n </a>\n <a href="https://arxiv.org/abs/2401.08772" target="_blank">\n <img alt="Arxiv" src="https://img.shields.io/badge/arxiv-paper%20-darkred?logo=arxiv&logoColor=white" />\n </a>\n <a href="https://pypi.org/project/huixiangdou" target="_blank">\n <img alt="PyPI" src="https://img.shields.io/badge/PyPI-install-blue?logo=pypi&logoColor=white" />\n </a>\n <a href="https://youtu.be/ylXrT-Tei-Y" target="_blank">\n <img alt="YouTube" src="https://img.shields.io/badge/YouTube-black?logo=youtube&logoColor=red" />\n </a>\n <a href="https://www.bilibili.com/video/BV1S2421N7mn" target="_blank">\n <img alt="BiliBili" src="https://img.shields.io/badge/BiliBili-pink?logo=bilibili&logoColor=white" />\n </a>\n <a href="https://discord.gg/TW4ZBpZZ" target="_blank">\n <img alt="discord" src="https://img.shields.io/badge/discord-red?logo=discord&logoColor=white" />\n </a>\n</div>\n</div>\n茴香豆是一个基于 LLM 的**群聊**知识助手,优势:\n1. 设计拒答、响应两阶段 pipeline 应对群聊场景,解答问题同时不会消息泛滥。精髓见[技术报告](https://arxiv.org/abs/2401.08772)\n2. 成本低至 1.5G 显存,无需训练适用各行业\n3. 提供一整套前后端 web、android、算法源码,工业级开源可商用\n查看[茴香豆已运行在哪些场景](./huixiangdou-inside.md);加入[微信群](resource/figures/wechat.jpg)直接体验群聊助手效果。\n如果对你有用,麻烦 star 一下⭐\n# 🔆 新功能\n茴香豆 Web 版已发布到 [OpenXLab](https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web),可以创建自己的知识库、更新正反例、开关网络搜索,聊天测试效果后,集成到飞书/微信群。\nWeb 版视频教程见 [BiliBili](https://www.bilibili.com/video/BV1S2421N7mn) 和 [YouTube](https://www.youtube.com/watch?v=ylXrT-Tei-Y)。\n- \\[2024/04\\] 发布 [web 前后端服务源码](./web) 🔷\n- \\[2024/03\\] 支持 `ppt` 和 `html` 格式\n- \\[2024/03\\] 优化 `pdf` 和表格解析,改善精度并加速\n- \\[2024/03\\] 支持 [zhipuai](https://zhipuai.cn) 和 [xi-api 国内 gpt 代理](https://api.xi-ai.cn),见 `config.ini`\n- \\[2024/03\\] 新的[个人微信集成方法](./docs/add_wechat_accessibility_zh.md)和[**预编译 apk**](https://github.com/InternLM/HuixiangDou/releases/download/v0.1.0rc1/huixiangdou-1.0.0.apk) !\n- \\[2024/03\\] 支持 `pdf`/`word`/`excel`,返回引用的文件名或 Web URL\n- \\[2024/02\\] 用 [BCEmbedding](https://github.com/netease-youdao/BCEmbedding) rerank 提升检索精度 👍\n- \\[2024/02\\] [支持 dee”\n 问题:“茴香豆怎么部署到微信群” \n 请仔细阅读参考材料回答问题。', '要部署茴香豆到微信群,请按照以下步骤操作:\n\n1. **安装茴香豆**:\n - 首先,您需要从 GitHub 上下载茴香豆的源代码。\n - 在您的计算机上安装 Python 3.8 或更高版本。\n - 使用 `pip` 安装茴香豆的依赖项:`pip install -r requirements.txt`。\n\n2. **准备数据**:\n - 您需要为茴香豆提供一些数据,例如问题、答案和相关知识。\n - 将数据整理成 JSON 格式,并保存为 `data.json` 文件。\n\n3. **配置茴香豆**:\n - 打开 `config.ini` 文件,并根据您的需求配置参数。\n - 配置 `model` 参数,以选择您要使用的模型。\n - 配置 `data` 参数,以指定您要使用的数据文件。\n - 配置 `log` 参数,以指定日志文件的路径。\n\n4. **运行茴香豆**:\n - 在终端中,导航到茴香豆的根目录。\n - 运行 `python huixiangdou.py` 启动茴香豆。\n - 茴香豆将开始处理数据,并准备回答用户的问题。\n\n5. **集成到微信群**:\n - 在您的微信中,创建一个新的群聊。\n - 将茴香豆的 QQ 号添加到该群聊中。\n - 茴香豆将开始接收来自微信群的消息,并尝试回答用户的问题。\n\n6. **测试和优化**:\n - 测试茴香豆的性能,并根据需要进行调整。\n - 您可以通过添加更多数据、调整参数或使用更高级的模型来提高茴香豆的性能。\n\n请注意,以上步骤仅提供了一个基本的部署流程,您可能需要根据您的具体需求进行一些调整。同时,为了确保茴香豆的正常运行,请确保您的计算机具有足够的计算资源,并且您的数据集是干净、有组织且格式正确的。')
2024-04-07 22:06:34.132 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:etease-youdao/BCEmbedding) rerank 提升检索精度 👍
- \[2024/02\] [支持 dee”问题:“茴香豆怎么部署到微信群”请仔细阅读参考材料回答问题 A:要部署茴香豆到微信群,请按照以下步骤操作:1. **安装茴香豆**:- 首先,您需要从 GitHub 上下载茴香豆的源代码。- 在您的计算机上安装 Python 3.8 或更高版本。- 使用 `pip` 安装茴香豆的依赖项:`pip install -r requirements.txt`。2. **准备数据**:- 您需要为茴香豆提供一些数据,例如问题、答案和相关知识。- 将数据整理成 JSON 格式,并保存为 `data.json` 文件。3. **配置茴香豆**:- 打开 `config.ini` 文件,并根据您的需求配置参数。- 配置 `model` 参数,以选择您要使用的模型。- 配置 `data` 参数,以指定您要使用的数据文件。- 配置 `log` 参数,以指定日志文件的路径。4. **运行茴香豆**:- 在终端中,导航到茴香豆的根目录。- 运行 `python huixiangdou.py` 启动茴香豆。- 茴香豆将开始处理数据,并准备回答用户的问题。5. **集成到微信群**:- 在您的微信中,创建一个新的群聊。- 将茴香豆的 QQ 号添加到该群聊中。- 茴香豆将开始接收来自微信群的消息,并尝试回答用户的问题。6. **测试和优化**:- 测试茴香豆的性能,并根据需要进行调整。- 您可以通过添加更多数据、调整参数或使用更高级的模型来提高茴香豆的性能。请注意,以上步骤仅提供了一个基本的部署流程,您可能需要根据您的具体需求进行一些调整。同时,为了确保茴香豆的正常运行,请确保您的计算机具有足够的计算资源,并且您的数据集是干净、有组织且格式正确的。 remote local timecost 40.72147536277771
04/07/2024 22:06:34 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:05:53 +0800] "POST /inference HTTP/1.1" 200 3315 "-" "python-requests/2.31.0"
2024-04-07 22:06:34.153 | INFO | __main__:lark_send_only:79 - ErrorCode.SUCCESS, 茴香豆怎么部署到微信群, 要部署茴香豆到微信群,请按照以下步骤操作:1. **安装茴香豆**:- 首先,您需要从 GitHub 上下载茴香豆的源代码。- 在您的计算机上安装 Python 3.8 或更高版本。- 使用 `pip` 安装茴香豆的依赖项:`pip install -r requirements.txt`。2. **准备数据**:- 您需要为茴香豆提供一些数据,例如问题、答案和相关知识。- 将数据整理成 JSON 格式,并保存为 `data.json` 文件。3. **配置茴香豆**:- 打开 `config.ini` 文件,并根据您的需求配置参数。- 配置 `model` 参数,以选择您要使用的模型。- 配置 `data` 参数,以指定您要使用的数据文件。- 配置 `log` 参数,以指定日志文件的路径。4. **运行茴香豆**:- 在终端中,导航到茴香豆的根目录。- 运行 `python huixiangdou.py` 启动茴香豆。- 茴香豆将开始处理数据,并准备回答用户的问题。5. **集成到微信群**:- 在您的微信中,创建一个新的群聊。- 将茴香豆的 QQ 号添加到该群聊中。- 茴香豆将开始接收来自微信群的消息,并尝试回答用户的问题。6. **测试和优化**:- 测试茴香豆的性能,并根据需要进行调整。- 您可以通过添加更多数据、调整参数或使用更高级的模型来提高茴香豆的性能。请注意,以上步骤仅提供了一个基本的部署流程,您可能需要根据您的具体需求进行一些调整。同时,为了确保茴香豆的正常运行,请确保您的计算机具有足够的计算资源,并且您的数据集是干净、有组织且格式正确的。, ['README_zh.md']
2024-04-07 22:06:35.630 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('“今天天气怎么样?”\n请仔细阅读以上内容,判断句子是否是个有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。\n判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释。', '根据给定的标准,"今天天气怎么样?" 是一个有主语、谓语和宾语,并且是疑问句的句子。因此,它的得分是 10 分。')
2024-04-07 22:06:35.631 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。
判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释 A:根据给定的标准,"今天天气怎么样?" 是一个有主语、谓语和宾语,并且是疑问句的句子。因此,它的得分是 10 分。 remote local timecost 1.4678237438201904
04/07/2024 22:06:35 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:06:34 +0800] "POST /inference HTTP/1.1" 200 474 "-" "python-requests/2.31.0"
2024-04-07 22:06:35.819 | INFO | huixiangdou.service.llm_server_hybrid:generate_response:519 - ('告诉我这句话的主题,直接说主题不要解释:“今天天气怎么样?”', '主题:天气。')
2024-04-07 22:06:35.820 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:522 - Q:告诉我这句话的主题,直接说主题不要解释:“今天天气怎么样? A:主题:天气。 remote local timecost 0.18501067161560059
04/07/2024 22:06:35 - [INFO] -aiohttp.access->>> 127.0.0.1 [07/Apr/2024:22:06:35 +0800] "POST /inference HTTP/1.1" 200 206 "-" "python-requests/2.31.0"
2024-04-07 22:06:35.837 | INFO | __main__:lark_send_only:79 - ErrorCode.UNRELATED, 今天天气怎么样?, , ['HuixiangDou.pdf']
(InternLM2_Huixiangdou) root@intern-studio-061925:~/huixiangdou#
茴香豆:https://github.com/InternLM/HuixiangDou
https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web
茴香豆零编程接入微信
https://zhuanlan.zhihu.com/p/686579577
这篇关于书生·浦语大模型实战营之茴香豆:搭建你的 RAG 智能助理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








