本文主要是介绍【DETR系列目标检测算法代码精讲】01 DETR算法02 DETR算法数据预处理+图像增强+dataset代码精讲,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天这一节主要对DETR算法的数据预处理和数据增强部分的代码做逐行的精讲。
这一部分的代码主要的功能就是将COCO数据集中的原始图像和原始标注处理成能够输入到DETR网络中的图像和标注。
我首先采取任务流程逐行讲解的办法,然后再debug演示一下
准备
这个读取数据就是从我们本地的coco数据集中的图像和标注转换为可以输入到DETR网络中的图像和标注
main.py
我们首先看main.py的第142和143行

dataset_train = build_dataset(image_set='train', args=args)
dataset_val = build_dataset(image_set='val', args=args)
这两行代码就是构建训练数据集和验证数据集的代码,可以看到,这个build_dataset函数需要我们传入两个参数,一个是image_set是用来指明读取的是训练集还是验证数据集,另一个是args,是我们通过命令行解析获取的一系列的超参数。
build_dataset函数
我们再深入看看build_dataset函数是什么?
Ctrl+鼠标左键点击这个函数,发现
这个函数在 DETR/datasets/init.py文件中

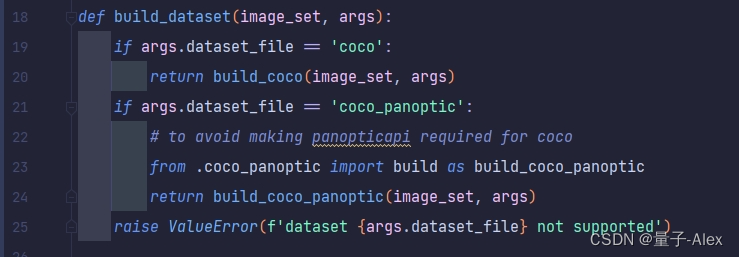
def build_dataset(image_set, args):if args.dataset_file == 'coco':return build_coco(image_set, args)if args.dataset_file == 'coco_panoptic':# to avoid making panopticapi required for cocofrom .coco_panoptic import build as build_coco_panopticreturn build_coco_panoptic(image_set, args)raise ValueError(f'dataset {args.dataset_file} not supported')
这段代码相对比较好理解,首先根据我们传入的args参数检查,我们是否要用coco数据集做目标检测或者是其他的任务,如果我们传入的是coco,那么就进一步调用build_coco函数,这个函数的输入就是build_dataset函数传入的两个参image_set和args。
因为DETR除了目标检测工作以外还做了全景分割的工作,所以这里可以看到下面如果我们在args里面传入的参数是coco_panoptic,这里就要调用build_coco_panoptic函数去构建全景分割的训练数据或者验证数据集,不过我们是以目标检测任务为主,这里就暂时先不去介绍全景分割部分的代码。
build_coco函数
我们再接着看看这个build_coco函数是怎么回事?
build_coco函数的位置如下:

在DETR/datasets/coco.py文件中

def build(image_set, args):root = Path(args.coco_path)assert root.exists(), f'provided COCO path {root} does not exist'mode = 'instances'PATHS = {"train": (root / "train2017", root / "annotations" / f'{mode}_train2017.json'),"val": (root / "val2017", root / "annotations" / f'{mode}_val2017.json'),}img_folder, ann_file = PATHS[image_set]dataset = CocoDetection(img_folder, ann_file, transforms=make_coco_transforms(image_set), return_masks=args.masks)return dataset
下面逐行来解释一下这段代码
build_coco函数有两个参数:image_set和args
image_set需要我们指定是训练集的dataset还是验证集的dataset
args里面是一系列超参数的字典,
首先根据我们定义的args超参数中coco数据集文件的路径,调用了pathlib库去构建一个路径,根据你运行Python的系统(例如,Windows、Linux、macOS等),实例化Path类会返回不同的对象。例如,在POSIX系统(如Linux或macOS)上,它会返回一个PosixPath对象;而在Windows上,它会返回一个WindowsPath对象。
我们转到main.py中,

–coco_path后面的default是我的电脑上coco2017数据集的路径,这里需要根据您的实际情况去做修改
下面一行代码,
assert root.exists(), f'provided COCO path {root} does not exist'
这是判断我们的coco数据集的路径是否存在。
下一行代码:
mode = 'instances'
这个代码的目的是为了拼接标注文件的文件名,为了方便大家理解,我粘贴coco数据集的文件构成
这个文件夹的路径就是我们在main.py中对于–coco_path的default中定义的coco2017数据集的路径,然后我们看annotations文件夹,所有的标注文件都在这里面
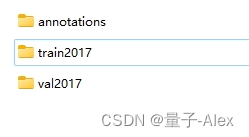

请记住这里我用红框标记的部分,待会要考
然后先看下面的代码:
PATHS = {"train": (root / "train2017", root / "annotations" / f'{mode}_train2017.json'),"val": (root / "val2017", root / "annotations" / f'{mode}_val2017.json'),}
这个PATHS的字典有两个键值对,实际上是有四个路径
还记得我们在main,py中默认的coco数据集的路径吗,这个参数通过args.coco_path和pathlib传给了root变量,root变量再拼接后面的train2017,这个拼接后的新的路径是什么?
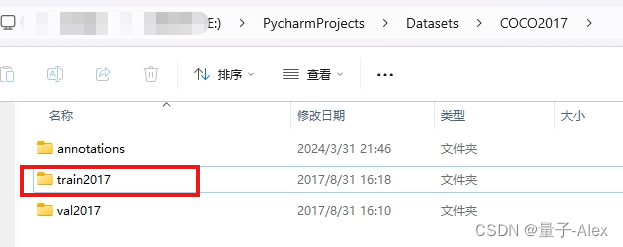
是不是就指向了训练数据文件夹?E:\PycharmProjects\Datasets\COCO2017\train2017

这里面就是118287张图像,那么我们再看另一个键值对
root拼接/annotation/f’{mode}_train2017.json
上面我们说了,这个mode就是instance,因此这个路径就指向了

同理,验证数据集的路径val的键值对也是这样的
一个是验证的图像文件夹的路径,另一个则是验证集的标注文件的路径
然后是
img_folder, ann_file = PATHS[image_set]
还记得我们在最开始传入的image_set这个参数吗,要么是train,要么是val
这里就是从PATHS字典里面取出对应的键值对,这个值就是图像文件夹的路径和对应的标注文件的路径。
dataset = CocoDetection(img_folder, ann_file, transforms=make_coco_transforms(image_set), return_masks=args.masks)
这个函数的最后一行代码,
我们刚才获得了训练/验证数据集的图像文件夹和标注文件夹的路径,
传入到这个类中,相当于实例化了一个类。这个类就是CocoDetection
CocoDetection类
这个类还是在DETR\datasets\coco.py文件中

我把全部代码先放在下面,然后一行一行地讲解
class CocoDetection(torchvision.datasets.CocoDetection):def __init__(self, img_folder, ann_file, transforms, return_masks):super(CocoDetection, self).__init__(img_folder, ann_file)self._transforms = transformsself.prepare = ConvertCocoPolysToMask(return_masks)def __getitem__(self, idx):img, target = super(CocoDetection, self).__getitem__(idx)image_id = self.ids[idx]target = {'image_id': image_id, 'annotations': target}img, target = self.prepare(img, target)if self._transforms is not None:img, target = self._transforms(img, target)return img, targetdef convert_coco_poly_to_mask(segmentations, height, width):masks = []for polygons in segmentations:rles = coco_mask.frPyObjects(polygons, height, width)mask = coco_mask.decode(rles)if len(mask.shape) < 3:mask = mask[..., None]mask = torch.as_tensor(mask, dtype=torch.uint8)mask = mask.any(dim=2)masks.append(mask)if masks:masks = torch.stack(masks, dim=0)else:masks = torch.zeros((0, height, width), dtype=torch.uint8)return masksclass CocoDetection(torchvision.datasets.CocoDetection):
可以看到DETR自定义了一个CocoDetection类,这个类是继承了torchvision.datasets.CocoDetection类
def __init__(self, img_folder, ann_file, transforms, return_masks):
然后可以看到初始化函数接受了四个参数,img_folder, ann_file, transforms, return_masks
img_folder, ann_file分别就是我们上一段通过PATHS字典取出来的训练/验证数据集的图像文件夹路径和标注文件路径。
第三个参数transforms是DETR定义的用于图像增强的类,将会在下面进行具体的介绍。
最后一个参数return_masks是说我们是否要返回masks,这个return_masks返回的是args.masks,是我们解析出来的超参数。默认是false,因为在这里是做的目标检测任务,暂时还用不到masks
CocoDetection类的__getitem__函数是整个数据预处理部分的核心,就这么一小段代码实际上就完成了读取数据+数据预处理+数据增强的三项任务

下面分别进行介绍
读取数据
img, target = super(CocoDetection, self).__getitem__(idx)image_id = self.ids[idx]target = {'image_id': image_id, 'annotations': target}
这几行代码实现了数据的读取,
要想了解是如何读取的,首先还是要了解DETR自定义的CocoDetection类所继承的那个torchvision.datasets.CocoDetection类的情况,点开torchvision.datasets.CocoDetection类
代码如下:
class CocoDetection(VisionDataset):"""`MS Coco Detection <https://cocodataset.org/#detection-2016>`_ Dataset.It requires the `COCO API to be installed <https://github.com/pdollar/coco/tree/master/PythonAPI>`_.Args:root (string): Root directory where images are downloaded to.annFile (string): Path to json annotation file.transform (callable, optional): A function/transform that takes in an PIL imageand returns a transformed version. E.g, ``transforms.PILToTensor``target_transform (callable, optional): A function/transform that takes in thetarget and transforms it.transforms (callable, optional): A function/transform that takes input sample and its target as entryand returns a transformed version."""def __init__(self,root: str,annFile: str,transform: Optional[Callable] = None,target_transform: Optional[Callable] = None,transforms: Optional[Callable] = None,) -> None:super().__init__(root, transforms, transform, target_transform)from pycocotools.coco import COCOself.coco = COCO(annFile)self.ids = list(sorted(self.coco.imgs.keys()))def _load_image(self, id: int) -> Image.Image:path = self.coco.loadImgs(id)[0]["file_name"]return Image.open(os.path.join(self.root, path)).convert("RGB")def _load_target(self, id: int) -> List[Any]:return self.coco.loadAnns(self.coco.getAnnIds(id))def __getitem__(self, index: int) -> Tuple[Any, Any]:id = self.ids[index]image = self._load_image(id)target = self._load_target(id)if self.transforms is not None:image, target = self.transforms(image, target)return image, targetdef __len__(self) -> int:return len(self.ids)torchvision.datasets.CocoDetection类是不支持在线下载数据集的,这和许多别的类不一样,就是如果本地的路径没有这个数据集,许多其他的类是可以在线下载数据集,而torchvision.datasets.CocoDetection类要求必须先下载好coco数据集。然后再使用torchvision.datasets.CocoDetection类来加载数据集。
torchvision.datasets.CocoDetection类有五个传入的参数:
root:这是指定的数据集图像的文件夹路径
annFile:这是指定的数据集标注文件的路径
transform:图像处理
target_transform;标注处理
transforms:图像和标注的处理
我们用debug看看

可以看到self也就是CocoDetection类有118287个对象
这里的idx是90932
通过父类的__getitem__函数读取这个图像和对应的标注


直接把返回值给一个image 一个给target
然后通过idx获取图像的id
接下来把图像的id和标注文件组成一个新的字典target
好的,下面我们回顾一下这段代码都干了些什么:
找到了本地的coco数据集和图像文件夹和标注文件的路径,然后通过idx去读取了一张图像和它对应的annotation信息
数据准备
img, target = self.prepare(img, target)
数据准备的实现代码其实就是这一段,可以看到这里调用了一个函数自定义的prepare函数
调用定义的prepare函数进行数据准备
传入两个参数,一个是img,是刚才获取到的原始图像,另一个是用图像id和图像的标注组成的一个新的字典target
我们去上面的初始化函数看看这个prepare函数到底是什么?
def __init__(self, img_folder, ann_file, transforms, return_masks):super(CocoDetection, self).__init__(img_folder, ann_file)self._transforms = transformsself.prepare = ConvertCocoPolysToMask(return_masks)
原来这里是调用了一个叫做ConvertCocoPolysToMask的类,而且还传入了一个return_masks的参数
ConvertCocoPolysToMask类
我们在这段代码打上断点debug一下,单步执行代码,然后就跳到了这个类
我首先把这个类的全部代码放在下面:
class ConvertCocoPolysToMask(object):def __init__(self, return_masks=False):self.return_masks = return_masksdef __call__(self, image, target):w, h = image.sizeimage_id = target["image_id"]image_id = torch.tensor([image_id])anno = target["annotations"]# 只获取 非crowd的目标( crowd 的目标是指: 人群、鸟群、等 类似的一群物体 )anno = [obj for obj in anno if 'iscrowd' not in obj or obj['iscrowd'] == 0]boxes = [obj["bbox"] for obj in anno]# guard against no boxes via resizingboxes = torch.as_tensor(boxes, dtype=torch.float32).reshape(-1, 4)# 坐标表示 :[xmin, ymin, width, height] ----> [xmin, ymin, xmax, ymax]boxes[:, 2:] += boxes[:, :2]boxes[:, 0::2].clamp_(min=0, max=w)boxes[:, 1::2].clamp_(min=0, max=h)classes = [obj["category_id"] for obj in anno]classes = torch.tensor(classes, dtype=torch.int64)if self.return_masks:segmentations = [obj["segmentation"] for obj in anno]masks = convert_coco_poly_to_mask(segmentations, h, w)keypoints = Noneif anno and "keypoints" in anno[0]:keypoints = [obj["keypoints"] for obj in anno]keypoints = torch.as_tensor(keypoints, dtype=torch.float32)num_keypoints = keypoints.shape[0]if num_keypoints:keypoints = keypoints.view(num_keypoints, -1, 3)keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])boxes = boxes[keep]classes = classes[keep]if self.return_masks:masks = masks[keep]if keypoints is not None:keypoints = keypoints[keep]target = {}target["boxes"] = boxestarget["labels"] = classesif self.return_masks:target["masks"] = maskstarget["image_id"] = image_idif keypoints is not None:target["keypoints"] = keypoints# for conversion to coco apiarea = torch.tensor([obj["area"] for obj in anno])iscrowd = torch.tensor([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno])target["area"] = area[keep]target["iscrowd"] = iscrowd[keep]target["orig_size"] = torch.as_tensor([int(h), int(w)])target["size"] = torch.as_tensor([int(h), int(w)])return image, target接下来开始逐行解析:
def __init__(self, return_masks=False):self.return_masks = return_masks
首先是初始化函数,只接受了一个参数,return_masks=False,而且被指定为False
然后再是__call___方法,
def __call__(self, image, target):
这个方法首先接受了两个参数,这里在上一节数据读取部分讲过,image是原始图像640*427,target是一个字典,键值对是图像的id-标注信息annotations,
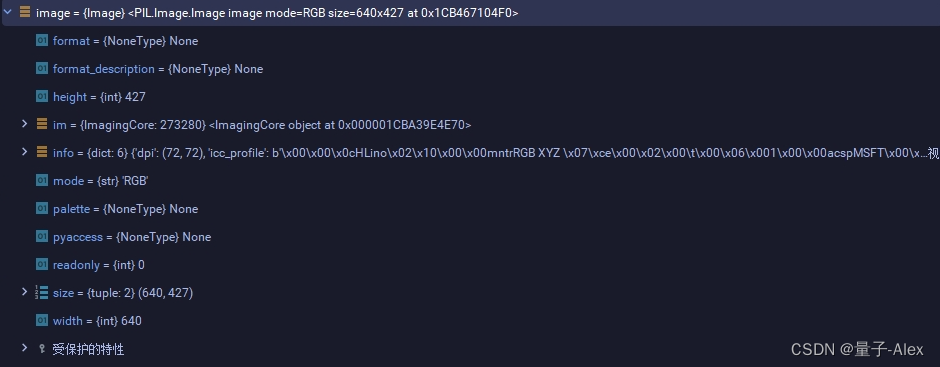

可以看到target里面的annotations有两个列表,这意味着这张图像中有两个目标。

然后获取image的宽高,id并且把id转换为tensor格式
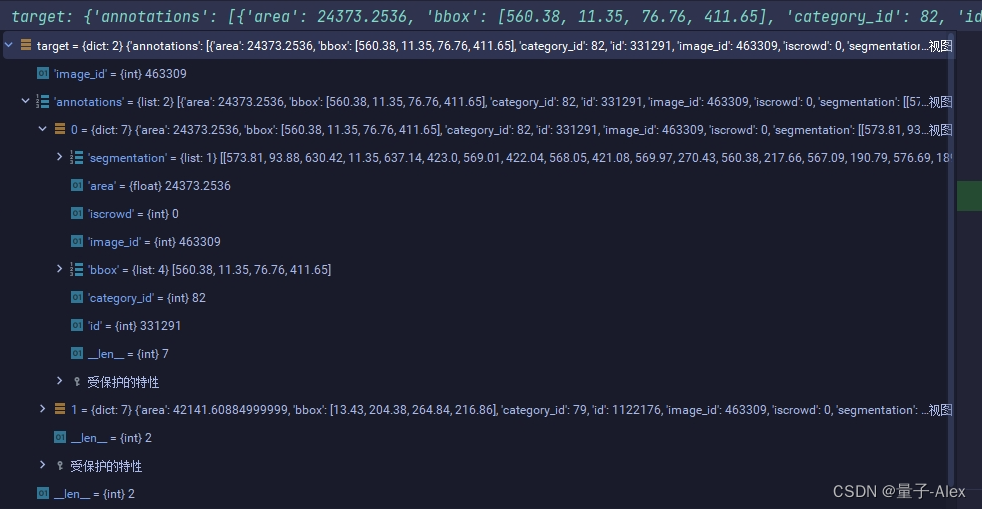
我们可以结合debug的target信息看一看,
这里就是直接读取了target中的image_id,

可以看到target中的annotations里面有一个iscrowd,这个是指目标是否是集群目标,
这里的两行代码就是读取target中的annotations,然后根据annotations中的iscrowd项来选择哪些非集群目标,如果annotations中没有标注iscrowd或者iscrowd为0,那么就把这个目标选择出来。

这一段代码则是读取annotations中的bbox也就是标注框的信息,这里因为图像中有两个目标,因此读取了两个标注框信息。
然后把标注框信息转化为tensor格式,也就是一个2*4的矩阵


我们知道一般的标注框是xywh,但是这里换成了xmin,ymin,xmax,ymax
也就是左上角坐标和右下角坐标,下面的代码就是完成了这个步骤,说白了就是把w,h加到前面的xmin,ymin上面就得到了xmax,ymax,
为了便于大家理解:

这是之前的格式,x,y,w,h
之后的形式是:
 就是把w,h加到前面的xmin,ymin上面
就是把w,h加到前面的xmin,ymin上面
后面的两行代码则是判断这个bbox有没有出图像的边界,如果超过了图像的边界就把它裁剪掉

这两行代码是提取annotation中图像的类别信息,

前面说了,这张图像中有两类目标,因此这里的类别信息就有两个,一个个是第82个类,一个是第79个类。
之后的两段代码是关于关键点和masks的,目前都用不上,因此跳过。

然后是这段代码:

首先是检测xmax是否大于xmin,ymax是否大于ymin,即bbox的坐标是否有效
然后提取出有效的坐标和有效的类别
之后的两个if这里也用不上,跳过

这段代码又重新定义了一个叫做target的空字典,z
然后给字典传入了boxes的键值对,这是刚才通过处理后的bbox信息,[xmin,ymin,xmax,ymax]
传入labels键值对,这里的值是图像中的类别信息[82,79]
再传入图像的id,
方便大家直观理解,这里用debug的结果演示一下

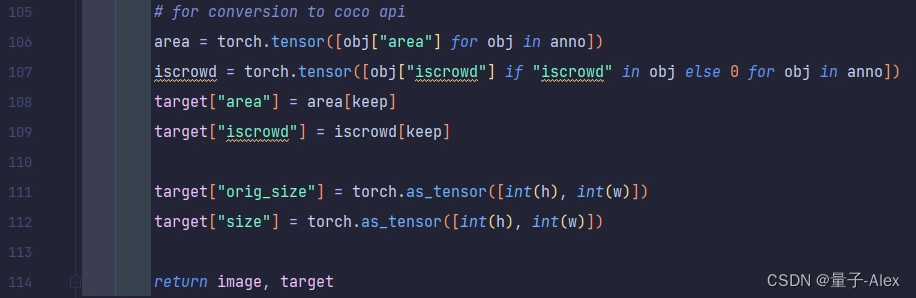
上面的这一段代码则是从annotation中提取了area面积信息和iscrowd信息。然后还提取了orig_size和size信息,这里可以看到两个信息都是完全一样的,640*427,相当于是备份了两次,其中orig_size是原始的图像尺寸,这里我们后续也不会做改变,size则是后面我们需要去调整的
最后形成的target字典的全部信息如下:

好的,我们现在回顾一下这段代码都做了哪些事情:
首先是读取了一张图像和它对应的annotation信息,
将annotation信息中的bbox,ids,class,size,iscrowd,area等信息都提取出来,对其中的部分信息比如bbox做了变换处理(由xmin,ymin,w,h)变成了(xmin,ymin,xmax,ymax),然后检查有没有超过图像的边缘。对于iscrowd,提取非集群目标,上述的所有信息全部转换为tensor格式,然后被传入了一个新建的target的字典里面
最后我们得到了一张原始图像和对应的信息字典。
数据转换与数据增强

好的,再回到CocoDetection类的__getitem__类下面,
蓝色框标记的部分是我们刚才两节讲过的数据读取和数据准备部分的代码
剩下的红色框就是数据转换与数据增强部分的代码了,我们接着逐行分析
首先可以看到self._transforms方法是在初始化函数里面定义的,

而这个定义的方法又是从外面传入的,我们需要回到调用CocoDetection类的地方,还记得是哪里吗?
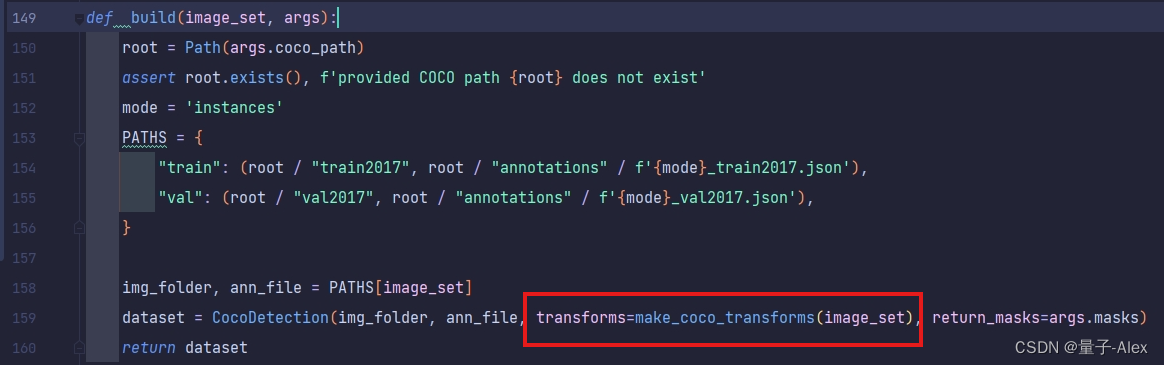
就是在datasets/coco.py文件下面的
_build函数下面
这里可以看到调用了一个make_coco_transforms的方法,这个方法传入的是image_set参数
这个方法就在coco.py文件下面,代码如下:
def make_coco_transforms(image_set):normalize = T.Compose([T.ToTensor(),T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]if image_set == 'train':return T.Compose([T.RandomHorizontalFlip(),T.RandomSelect(T.RandomResize(scales, max_size=1333),T.Compose([T.RandomResize([400, 500, 600]),T.RandomSizeCrop(384, 600),T.RandomResize(scales, max_size=1333),])),normalize,])if image_set == 'val':return T.Compose([T.RandomResize([800], max_size=1333),normalize,])raise ValueError(f'unknown {image_set}')make_coco_transforms方法
如果我们传入的image_set是train的话,就执行这一段代码作为tranforms

如果我们传入的image_set是val的话,就执行这一段代码作为tranforms

接下来进一步看看具体操作
normalize = T.Compose([T.ToTensor(),T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])首先定义了一个normalize,这里定义的T并不是直接调用torchvision中的transforms,而是在datasets中重写了一个transforms文件,

对于这里,稍后会重点讲解这个部分
先讲讲这正则化的设计:
首先会将图像转换为张量(T.ToTensor()),然后对其进行标准化(T.Normalize())。标准化使用的均值是 [0.485, 0.456, 0.406],标准差是 [0.229, 0.224, 0.225]。
scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]
这是一个包含多个尺度的列表,
下面一段代码:

在训练模式下,返回一个变换组合,该组合包括:
T.RandomHorizontalFlip():随机水平翻转图像。
T.RandomSelect(…):随机选择两种变换之一:
T.RandomResize(scales, max_size=1333):随机选择 scales 列表中的一个尺寸来调整图像大小,但最大不超过 1333。
一个更复杂的组合,包括:
T.RandomResize([400, 500, 600]):随机选择 400、500 或 600 作为图像的新大小。
T.RandomSizeCrop(384, 600):随机裁剪图像,使其大小在 384 到 600 之间。
T.RandomResize(scales, max_size=1333):再次随机调整图像大小,但最大不超过 1333。
normalize:应用前面定义的标准化变换。
如果我们传入的image_set参数是train,就执行下面的数据增强部分的代码,这里的函数都是DETR重写的transforms.py中的,
因为是目标检测任务,我们在对图像进行增强变换的时候也需要对bbox标注框进行同样的变换,而torchvision原本的tranforms是无法对bbox标注框进行变换的,
下面就讲一讲重写的tranforms.py
transforms.py
首先来看Compose类:
Compose类实现定义transforms操作集合
class Compose(object):def __init__(self, transforms):self.transforms = transformsdef __call__(self, image, target):for t in self.transforms:image, target = t(image, target)return image, targetdef __repr__(self):format_string = self.__class__.__name__ + "("for t in self.transforms:format_string += "\n"format_string += " {0}".format(t)format_string += "\n)"return format_string
首先定义了一个名为Compose的新类,它继承自object。在Python 3中,所有类都是新式类,即使你不显式地继承自object。同时接收一个transforms的list,
类的初始化方法。当创建一个Compose对象时,需要传入一个转换操作的列表transforms。transforms的列表里面定义了一系列的转换操作。接受两个参数:image和target,并返回处理后的image和target。
def call(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
这是一个特殊的方法,使得Compose类的实例可以被像函数一样调用。
当有一个Compose对象,并传入一个image和一个target时,这个方法会按照transforms列表中的顺序,依次应用每一个transforms操作。
每一次循环,它都会调用列表中的转换操作,并将结果(处理后的image和target)传递给下一次循环。
最后,它返回经过所有转换操作处理后的image和target。
def repr(self):
这是另一个特殊的方法,它返回一个字符串,描述了Compose对象的内容。
这个方法首先获取类的名称,然后遍历transforms列表,并为每一个转换操作生成一个字符串表示。
最后,它返回一个格式化的字符串,描述了Compose对象和其内部的转换操作。
总结一下,Compose类接收一个列表,能够让image和target按照列表中每个 操作的顺序依次进行。
RandomHorizontalFlip类实现随机水平翻转
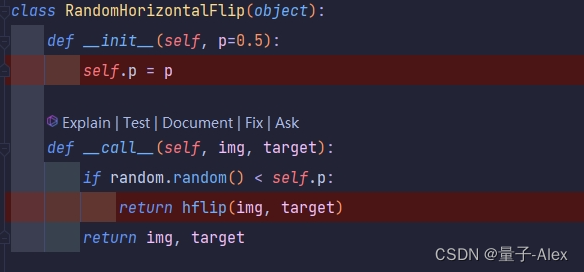
这个方法使得RandomHorizontalFlip的实例可以被像函数那样调用。当你有一个RandomHorizontalFlip的实例(例如flipper),可以使用flipper(img, target)来调用它。
在这个__call__方法中,首先使用random.random()生成一个0到1之间的随机数。如果这个随机数小于self.p(即小于我们设定的翻转概率),则调用hflip(img, target)函数来翻转图像。否则,直接返回原始图像和目标。
hflips方法
hflips方法的代码如下:
def hflip(image, target):flipped_image = F.hflip(image)w, h = image.sizetarget = target.copy()if "boxes" in target:boxes = target["boxes"]boxes = boxes[:, [2, 1, 0, 3]] * torch.as_tensor([-1, 1, -1, 1]) + torch.as_tensor([w, 0, w, 0])target["boxes"] = boxesif "masks" in target:target['masks'] = target['masks'].flip(-1)return flipped_image, target
定义一个名为 hflip 的函数,接受两个参数:image 和 target。
使用 F.hflip 函数水平翻转 image,并将结果存储在 flipped_image 中
获取原始图像的宽度(w)和高度(h)。
target = target.copy()
复制 target字典,以避免修改原始数据。
if “boxes” in target:
检查 target 字典是否包含键 “boxes”。
boxes = target[“boxes”]
如果包含 “boxes”,则获取其值并存储在 boxes 中。
boxes = boxes[:, [2, 1, 0, 3]] * torch.as_tensor([-1, 1, -1, 1]) + torch.as_tensor([w, 0, w, 0])
boxes 是一个形状为 [N, 4] 的张量,其中 N 是边界框的数量,每一行包含 [x1, y1, x2, y2] 形式的坐标(左上角和右下角的坐标)。
[2, 1, 0, 3] 用于交换 x1 和 x2 的位置,实现水平翻转。
*torch.as_tensor([-1, 1, -1, 1]) 用于将 x1 和 x2 的值乘以 -1,以考虑翻转。
+torch.as_tensor([w, 0, w, 0]) 用于将 x1 和 x2 的值加上图像的宽度 w,以确保边界框的坐标在翻转后的图像中仍然有效。
target[“boxes”] = boxes
更新 target 字典中的 “boxes” 键的值。
为了方便大家能够get到这里面翻转的操作:

我画了几幅图来帮助大家理解:

我想通过这幅对比图大家就非常能够直观的理解了,
图像要水平翻转,bbox边界框也要水平翻转
什么是水平翻转,我们可以这么想:目标的边界框有4条边,上下两条边相对于图像的上下两条边的相对位置并没有随着水平翻转而变化,但是左右两条边相对于图像的左右两条边的距离是发生了变化的,而且前后是相反的,可以理解为图像中间有一条中垂线,标注框以这条线为轴做了翻转,那么现在的问题就是如果表达体现翻转前后标注框左右两边到图像的左右两边距离相反这一现象呢?
我们回顾一下我们现在的已知量,我们知道整个图像的宽w,我们知道翻转前的bbox的左上角坐标和右下角坐标,那么我们是不是可以用这几个值来表示我们上面说的标注框左右两边到图像的左右两边距离呢?
当然是可以的,翻转前,标注框左边距离图像左边是x_min,也就是标注框左上角的横坐标,标注框右边距离图像右边是w-x_max,就是图像的宽度减去标注框右下角的横坐标,
那么也就是说,我们水平翻转后,
标注框左右两边到图像的左右两边距离要反过来,标注框左边到图像左边是w-x_max,标注框右边到图像右边是x_min,那么我们在这个基础上反推翻转后的标注框坐标,左上角的横坐标就是标注框左边到图像左边距离w-x_max,右下角的横坐标等于图像宽度减去标注框右边到图像右边距离x_min,那么就是w-x_min,而由于是水平翻转,两个点的高度不变,因此这就是推导过程。
RandomSelect类实现对操作的随机选择
代码如下:
class RandomSelect(object):"""Randomly selects between transforms1 and transforms2,with probability p for transforms1 and (1 - p) for transforms2"""def __init__(self, transforms1, transforms2, p=0.5):self.transforms1 = transforms1self.transforms2 = transforms2self.p = pdef __call__(self, img, target):if random.random() < self.p:return self.transforms1(img, target)return self.transforms2(img, target)
这段代码定义了一个名为RandomSelect的类,这个类的主要功能是根据一定的概率(p)随机地选择并应用两组图像转换(transforms1 和 transforms2)。
在__init__方法中,transforms1和transforms2是两个参数,它们应该是实现了__call__方法的对象,这样它们就可以像函数一样被调用。p是一个可选参数,默认值为0.5,表示选择transforms1的概率。
call方法使得RandomSelect类的实例可以像函数一样被调用。当调用这个实例时,它会接收两个参数img和target,然后根据random.random()生成的随机数是否小于self.p来决定应用哪个转换。
如果random.random()生成的随机数小于self.p,则应用transforms1。
否则,应用transforms2。
那么这个transforms1和transforms2在DETR的数据预处理和数据增强操作中到底是什么呢
回到make_coco_transforms方法中

transform1就是红框的部分,
transform2就是蓝框的部分。
RandomResize类实现随机缩放
这个类的全部代码如下:
class RandomResize(object):def __init__(self, sizes, max_size=None):assert isinstance(sizes, (list, tuple))self.sizes = sizesself.max_size = max_sizedef __call__(self, img, target=None):size = random.choice(self.sizes)return resize(img, target, size, self.max_size)这个类接收两个参数,一个是sizes,一个是max_size,这两个参数是从make_coco_transforms函数指定的

可以看到max_size是scales这个列表,max_size是1333。
def __call__(self, img, target=None):size = random.choice(self.sizes)return resize(img, target, size, self.max_size)
这里是从sizes的列表中随机出来一个值,然后这个值和img,target,max_size一起传入resize函数
resize方法
resize方法的全部代码如下:
def resize(image, target, size, max_size=None):# size can be min_size (scalar) or (w, h) tupledef get_size_with_aspect_ratio(image_size, size, max_size=None):w, h = image_sizeif max_size is not None:min_original_size = float(min((w, h)))max_original_size = float(max((w, h)))if max_original_size / min_original_size * size > max_size:size = int(round(max_size * min_original_size / max_original_size))if (w <= h and w == size) or (h <= w and h == size):return (h, w)if w < h:ow = sizeoh = int(size * h / w)else:oh = sizeow = int(size * w / h)return (oh, ow)def get_size(image_size, size, max_size=None):if isinstance(size, (list, tuple)):return size[::-1]else:return get_size_with_aspect_ratio(image_size, size, max_size)size = get_size(image.size, size, max_size)rescaled_image = F.resize(image, size)if target is None:return rescaled_image, Noneratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))ratio_width, ratio_height = ratiostarget = target.copy()if "boxes" in target:boxes = target["boxes"]scaled_boxes = boxes * torch.as_tensor([ratio_width, ratio_height, ratio_width, ratio_height])target["boxes"] = scaled_boxesif "area" in target:area = target["area"]scaled_area = area * (ratio_width * ratio_height)target["area"] = scaled_areah, w = sizetarget["size"] = torch.tensor([h, w])if "masks" in target:target['masks'] = interpolate(target['masks'][:, None].float(), size, mode="nearest")[:, 0] > 0.5return rescaled_image, target可以看到这个方法里面又有两个方法:get_size和get_size_with_aspect_ratio
get_size方法
get_size方法的代码如下:
def get_size(image_size, size, max_size=None):if isinstance(size, (list, tuple)):return size[::-1]else:return get_size_with_aspect_ratio(image_size, size, max_size)
我们来看这段代码,方法传入了三个参数image_size size和max_size
那么这三个参数是从哪里来的呢
首先可以追溯到get_size方法

然后,get_size方法传入的三个参数又是从哪里来的呢?

是从RandomResize中传入的,size是从sizes也就是从make_coco_transforms的scale尺度列表中随机选择的

同时也可以看到这里就指定了max_size是1333。
再继续说get_size方法的具体内容
首先if isinstance(size, (list, tuple)):是判断传入的size是一个数值还是一个列表或者还是一个元组,我们可以debug看一下:

可以看到size是一个数值,因此跳到else的get_size_with_aspect_ratio函数,
get_size_with_aspect_ratio方法
这个方法的全部代码如下:
def get_size_with_aspect_ratio(image_size, size, max_size=None):w, h = image_sizeif max_size is not None:min_original_size = float(min((w, h)))max_original_size = float(max((w, h)))if max_original_size / min_original_size * size > max_size:size = int(round(max_size * min_original_size / max_original_size))if (w <= h and w == size) or (h <= w and h == size):return (h, w)if w < h:ow = sizeoh = int(size * h / w)else:oh = sizeow = int(size * w / h)return (oh, ow)
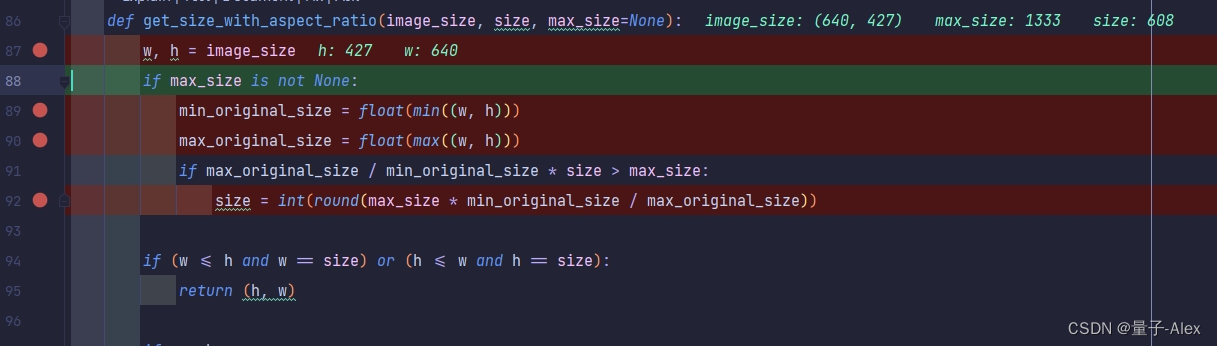
首先解析出图像的尺寸
如果设置了max_size,就执行下面的操作
max_size是用来设置操作后图像的较长边的长度
就是resize之后图像较长边的长度不能大于max_size

首先判断图像中的较长边和较短边 ,这里判断图像的max_original_size较长边是640,min_original_size较短边是427,
size是我们自定义的resize之后较短边的边长,
max_original_size / min_original_size * size 是保持原图像的宽高比,再乘上我们自定义的resize之后较短边的边长,得到的就是较长边的长度。
接下来把这个长度与max_size进行比较,如果小于max_size就作为较长边的长度,如果大于max_size,就以max_size作为较长边的长度,用int(round(max_size * min_original_size / max_original_size))作为较短边的长度

如果图像较短边的长度等于我们计算出来的size
就返回高和宽

我们把size给较短边,用原始图像的宽高比去计算新的较长边的边长。
这里我们传入的size是608,608*640/427并不大于我们指定的max_size 1333,因此resize后的较短边就是608,

根据这个方法,我们计算出resize后的较长边是911
然后返回新的尺寸

通过这两行代码对图像进行缩放
下面的代码就是对标注框的缩放



首先分别取出缩放前后的宽和高,对应地计算宽的缩放比和高的缩放比


将target字典复制一遍,取出复制后的bbox的坐标信息,与计算得到的宽和高的缩放比相乘,得到新的bbox的坐标,重新保存在target字典中,

同样的,把target里面的面积也提取出来乘以宽的缩放比和高的缩放比

然后将缩放后的尺寸转换为tensor格式
也写入target字典
最后返回随机缩放后的图像和target字典
RandomSizeCrop类实现随机裁剪

class RandomSizeCrop(object):def __init__(self, min_size: int, max_size: int):self.min_size = min_sizeself.max_size = max_sizedef __call__(self, img: PIL.Image.Image, target: dict):# 在指定范围内,分别随机出 高/宽尺寸,用于裁剪w = random.randint(self.min_size, min(img.width, self.max_size))h = random.randint(self.min_size, min(img.height, self.max_size))# 返回的region为裁剪的尺寸,形为:(top, left, height, width)region = T.RandomCrop.get_params(img, [h, w])return crop(img, target, region)随机裁剪类的代码如上:
首先传入两个参数 min_size和max_size

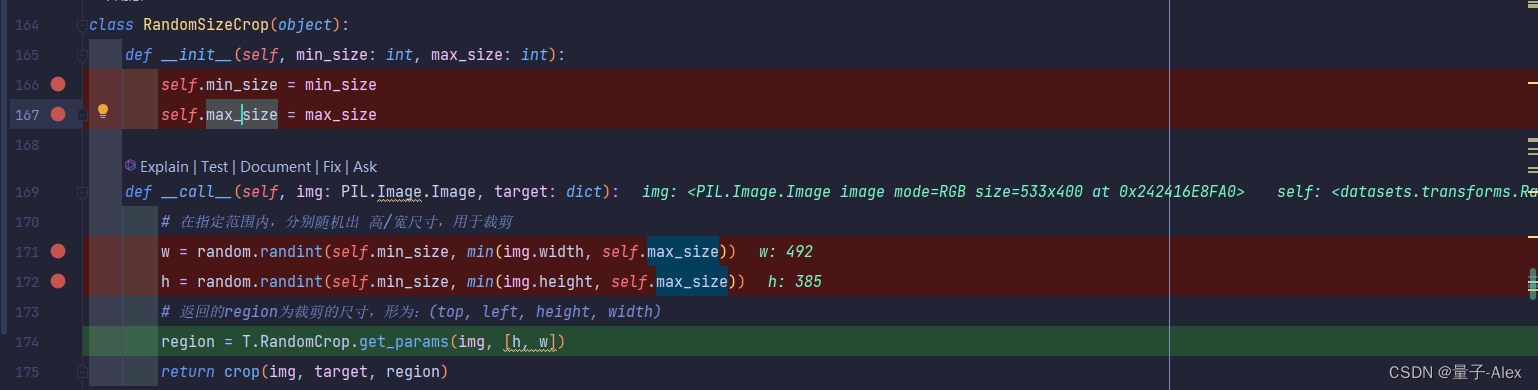
首先判断图像的高和宽与max_size的大小,
将较小的值作为上界,将min_size作为下界,在这个范围内随机出两个值作为高和宽进行裁剪
然后得到裁剪的尺寸与坐标

region的四个值分别为裁剪区域的顶部坐标、左侧坐标、高度和宽度
然后调用crop方法
crop方法
代码如下
def crop(image, target, region):# 将图像按照region 指定的尺寸进行裁剪cropped_image = F.crop(image, *region)target = target.copy()i, j, h, w = region# 保存裁剪后的尺寸target["size"] = torch.tensor([h, w])# 保存字段名,方便后面用于检查fields = ["labels", "area", "iscrowd"]if "boxes" in target:boxes = target["boxes"]# 将裁剪后的图像宽高转换为 tensormax_size = torch.as_tensor([w, h], dtype=torch.float32)# 调整bbox的坐标,将bbox的(xmin, ymin, xmax, ymax) 分别减去(left, top, left, top)cropped_boxes = boxes - torch.as_tensor([j, i, j, i])# 处理边界情况,若bbox的坐标落在裁剪区域外,则将bbox的坐标进行截断cropped_boxes = torch.min(cropped_boxes.reshape(-1, 2, 2), max_size) # 处理bbox的xmax和ymaxcropped_boxes = cropped_boxes.clamp(min=0) # 处理bbox的xmin和ymin# 求出裁剪后的图像面积,代码等价于 :area =(xmax - xmin) * (ymax - ymin)area = (cropped_boxes[:, 1, :] - cropped_boxes[:, 0, :]).prod(dim=1)target["boxes"] = cropped_boxes.reshape(-1, 4)target["area"] = areafields.append("boxes")if "masks" in target:target['masks'] = target['masks'][:, i:i + h, j:j + w]fields.append("masks")if "boxes" in target or "masks" in target:# 删除落在裁剪区域外的bbox,这部分bbox经过上面的处理之后: xmin=xmax, ymin=ymaxif "boxes" in target:cropped_boxes = target['boxes'].reshape(-1, 2, 2)keep = torch.all(cropped_boxes[:, 1, :] > cropped_boxes[:, 0, :], dim=1)else:keep = target['masks'].flatten(1).any(1)# 删除无效的bboxfor field in fields:target[field] = target[field][keep]return cropped_image, target接收三个参数,image,target和裁剪区域
首先直接调用crop函数进行裁剪,然后对bbox进行处理

可能会出现一些特殊情况,也就是bbox可能会落在裁剪的区域之外,如果出现这种情况就将其截断
还有可能出现的情况是bbox完全落到了裁剪区域之外,这里首先进行判断,如果确实是这样就将其剔除
ToTensor类转换
class ToTensor(object):def __call__(self, img, target):return F.to_tensor(img), targetNormalize类归一化
class Normalize(object):def __init__(self, mean, std):self.mean = meanself.std = stddef __call__(self, image, target=None):image = F.normalize(image, mean=self.mean, std=self.std)if target is None:return image, Nonetarget = target.copy()h, w = image.shape[-2:]if "boxes" in target:boxes = target["boxes"]boxes = box_xyxy_to_cxcywh(boxes)boxes = boxes / torch.tensor([w, h, w, h], dtype=torch.float32)target["boxes"] = boxesreturn image, target直接将图像中的每一个像素减去均值再除以标准差,
接下来的代码对bbox的坐标进行转换
这里调用了一个函数box_xyxy_to_cxcywh方法
def box_xyxy_to_cxcywh(x):# 将bbox的坐标形式由 (xmin, ymin, xmax,ymax) 转换为 (center_x, center_y, width, height)x0, y0, x1, y1 = x.unbind(-1)b = [(x0 + x1) / 2, (y0 + y1) / 2,(x1 - x0), (y1 - y0)]return torch.stack(b, dim=-1)
把坐标转换为中心点的坐标和宽高
boxes = boxes / torch.tensor([w, h, w, h], dtype=torch.float32)这行代码把刚才的坐标转换为相对位置坐标 都除以图像的宽和高
这就是最终的bbox处理后的信息,重新写入target字典
我们debug以下

这是传入的bbox坐标
然后进入box_xyxy_to_cxcywh方法
 计算出来的b
计算出来的b

转换后的bbox就是这样
这篇关于【DETR系列目标检测算法代码精讲】01 DETR算法02 DETR算法数据预处理+图像增强+dataset代码精讲的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





