本文主要是介绍二十四种设计模式与六大设计原则(三):【装饰模式、迭代器模式、组合模式、观察者模式、责任链模式、访问者模式】的定义、举例说明、核心思想、适用场景和优缺点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
接上次博客:二十四种设计模式与六大设计原则(二):【门面模式、适配器模式、模板方法模式、建造者模式、桥梁模式、命令模式】的定义、举例说明、核心思想、适用场景和优缺点-CSDN博客
目录
装饰模式【Decorator Pattern】
定义
举例说明
核心思想
适用场景
优缺点
迭代器模式【Iterator Pattern】
定义
举例说明
核心思想
适用场景
优缺点
组合模式【Composite Pattern】
定义
举例说明
核心思想
适用场景
优缺点
观察者模式【Observer Pattern】
定义
举例说明
核心思想
适用场景
优缺点
责任链模式【Chain of Responsibility Pattern】
定义
举例说明
核心思想
适用场景
优缺点
访问者模式【Visitor Pattern】
定义
举例说明
核心思想
适用场景
优缺点
装饰模式【Decorator Pattern】
定义
装饰器模式(Decorator Pattern)是一种结构型设计模式,允许在不改变对象自身结构的情况下,动态地给对象添加额外的功能。它通过将对象封装在一个或多个装饰器中,从而使得客户端可以根据需要透明地、逐层地包装对象。
装饰器模式 允许向现有对象添加新功能而不改变其结构。这种类型的设计模式属于结构型模式,它允许向现有类添加新的功能,同时又不改变其结构。这种模式创建了一个装饰器类,用来包装原有的类,并在不改变原有类结构的前提下,添加了新的功能或责任。

在装饰器模式中,有如下几个角色:
-
组件接口(Component):定义了具体组件和装饰器需要实现的接口或抽象类。它是被装饰的对象的公共接口,可以是抽象类或接口。
-
具体组件(Concrete Component):实现了组件接口,并定义了基本行为。
-
装饰器(Decorator):实现了组件接口,并包含一个组件对象,它可以通过该对象实现对原有组件的功能扩展。通常它会维护一个指向组件对象的引用,并在调用原始对象的基本操作之前或之后执行附加的操作。
-
具体装饰器(Concrete Decorator):实现了装饰器接口,并扩展了被装饰对象的行为。
装饰器模式的关键优势在于它提供了一种灵活的方式来扩展类的功能,而无需使用子类继承。这样可以避免创建大量的子类,使得类的结构更加灵活,并且符合开闭原则。
举例说明
假设你是一位咖啡爱好者,经常去一家咖啡馆喝咖啡。这家咖啡馆提供了各种口味的咖啡,包括美式咖啡、拿铁、卡布奇诺等。你发现虽然咖啡馆提供了丰富的选择,但有时候你想要的口味并不在标准菜单上。于是你想到了一个主意:为什么不给每种咖啡添加额外的口味,以满足自己更多的口味需求呢?
在这个场景中,咖啡可以被看作是被装饰的对象,而不同口味的添加则可以被看作是装饰器。例如,你可以选择在美式咖啡中添加焦糖味、香草味或榛果味等。这样,你可以根据自己的口味喜好,动态地给咖啡添加不同的口味,而不需要咖啡馆专门提供每种口味的单独菜单。
具体来说,假设你点了一杯拿铁咖啡,但你想要让这杯拿铁咖啡更加丰富一点,你可以选择添加巧克力口味或是焦糖口味。在这里,拿铁咖啡就是被装饰的对象,而巧克力口味和焦糖口味就是装饰器。通过装饰器,你可以在不改变拿铁咖啡本身的情况下,为其添加额外的口味,从而让咖啡味道更加层次丰富。
// 咖啡接口
interface Coffee {String getDescription();double cost();
}// 具体咖啡类:拿铁
class Latte implements Coffee {@Overridepublic String getDescription() {return "拿铁咖啡";}@Overridepublic double cost() {return 15.0;}
}// 装饰器:口味装饰器
abstract class FlavorDecorator implements Coffee {protected Coffee coffee;public FlavorDecorator(Coffee coffee) {this.coffee = coffee;}@Overridepublic String getDescription() {return coffee.getDescription();}@Overridepublic double cost() {return coffee.cost();}
}// 具体装饰器:巧克力口味
class ChocolateFlavor extends FlavorDecorator {public ChocolateFlavor(Coffee coffee) {super(coffee);}@Overridepublic String getDescription() {return coffee.getDescription() + " + 巧克力口味";}@Overridepublic double cost() {return coffee.cost() + 5.0; // 巧克力口味额外收费5元}
}// 具体装饰器:焦糖口味
class CaramelFlavor extends FlavorDecorator {public CaramelFlavor(Coffee coffee) {super(coffee);}@Overridepublic String getDescription() {return coffee.getDescription() + " + 焦糖口味";}@Overridepublic double cost() {return coffee.cost() + 3.0; // 焦糖口味额外收费3元}
}// 客户端代码
public class CoffeeShop {public static void main(String[] args) {// 原始订单:拿铁咖啡Coffee order = new Latte();System.out.println("原始订单:" + order.getDescription() + ",价格:" + order.cost() + "元");// 在拿铁咖啡中添加巧克力口味order = new ChocolateFlavor(order);System.out.println("添加巧克力口味后:" + order.getDescription() + ",价格:" + order.cost() + "元");// 在拿铁咖啡中再添加焦糖口味order = new CaramelFlavor(order);System.out.println("再添加焦糖口味后:" + order.getDescription() + ",价格:" + order.cost() + "元");}
}
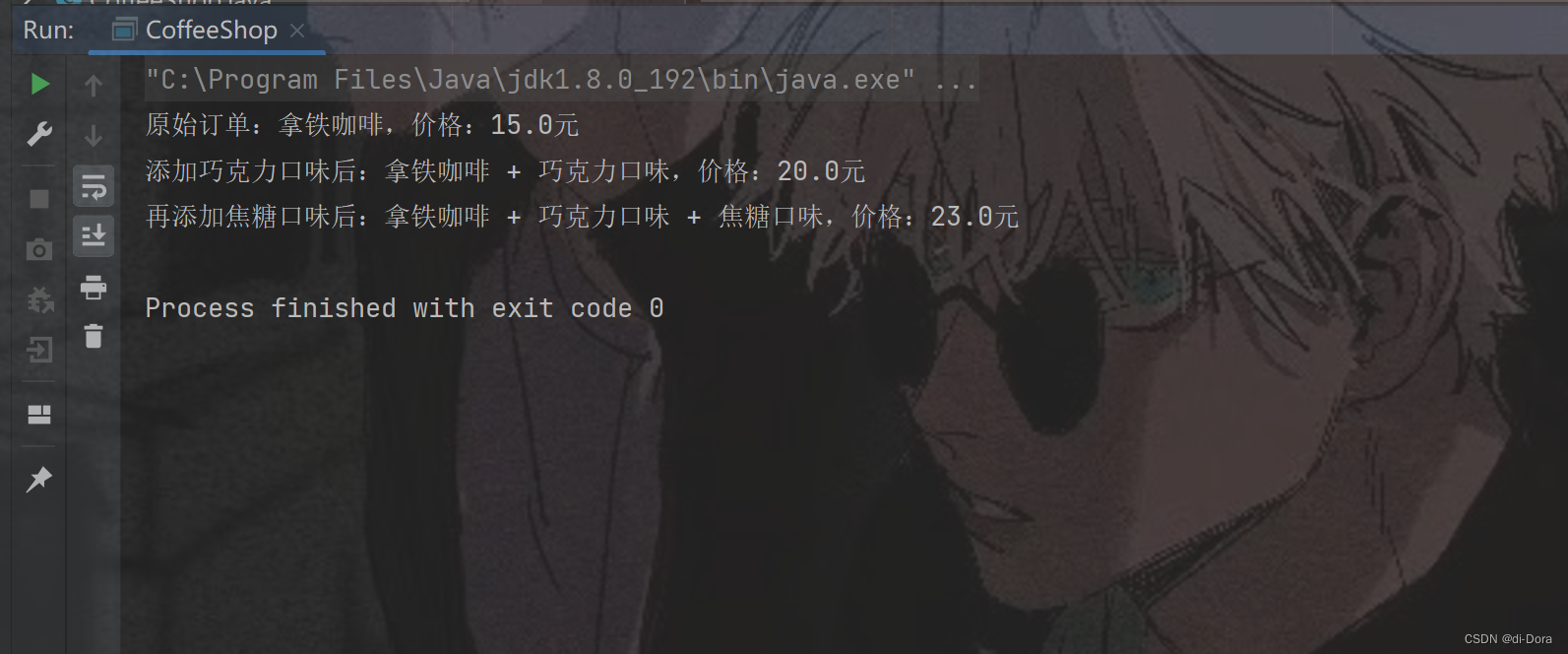
这个例子中的装饰模式体现在动态地给咖啡添加额外的口味,而不需要修改咖啡本身的结构。这种方式使得你可以根据自己的口味需求,灵活地定制咖啡的口味,同时也让咖啡馆的菜单更加简洁明了。
核心思想
装饰器模式的核心思想是在不改变现有对象结构的情况下,动态地给对象添加额外的功能。这一模式通过创建一个包装对象,即装饰器,来实现功能的动态增加。
其核心思想可以总结如下:
-
组件抽象化:定义一个抽象组件接口,描述了被装饰对象和装饰器共同的行为,确保它们可以互相替代。
-
装饰器封装:创建装饰器类,实现组件接口,并在内部维护一个指向具体组件对象的引用。装饰器可以通过组合的方式包装具体组件,并在其基础上添加额外的功能。
-
透明性:保持装饰器和具体组件的透明性,即客户端无需知道装饰器和具体组件的具体实现细节,可以统一对待。
-
递归组合:装饰器可以递归地嵌套组合,从而实现对对象功能的多层次扩展。这使得在运行时动态地添加或删除功能成为可能。
-
开闭原则:通过装饰器模式,可以实现对现有代码的功能扩展,而无需修改原有代码,从而符合开闭原则。
总之,装饰器模式允许动态地给对象添加功能,同时保持对象结构的稳定,使得功能的增加和变化变得更加灵活和可控。
适用场景
装饰器模式通常在以下情况下适用:
-
需要动态地给对象添加额外的功能:装饰器模式允许在运行时动态地给对象添加功能,而不影响其结构。这在需要根据不同需求动态地增加或删除对象功能时非常有用。
-
避免使用子类进行功能扩展:通过继承会导致类的爆炸性增长,而装饰器模式通过组合的方式避免了这种问题,使得功能的增加更加灵活。
-
需要扩展或修改现有对象的功能,但又不希望修改其代码:装饰器模式允许在不修改现有代码的情况下,通过添加装饰器来扩展或修改对象的功能,符合开闭原则。
-
需要在不影响其他对象的情况下对对象进行功能增强:装饰器模式通过独立的装饰器类对对象进行包装,使得对象的功能增强不会影响其他对象,从而保持了系统的灵活性和可维护性。
-
需要在不同情况下组合和使用对象的不同功能组合:装饰器模式允许根据不同需求动态地组合和使用对象的不同功能,从而实现更加灵活和可定制的功能组合。
装饰器模式适用于需要动态地给对象添加功能,同时又希望保持对象结构稳定的情况下,以及需要在不修改现有代码的情况下扩展或修改对象功能的场景。
优缺点
装饰器模式的优点包括:
-
动态添加功能:装饰器模式允许在运行时动态地给对象添加新的功能,而无需修改其原始类的代码,使得功能的扩展变得灵活方便。
-
避免类爆炸:通过装饰器模式,可以避免使用大量子类来实现不同的功能组合,从而避免了类的爆炸性增长。
-
符合开闭原则:装饰器模式通过组合的方式扩展对象的功能,而不是通过继承,符合开闭原则,即对扩展开放,对修改关闭。
-
单一职责原则:每个装饰器类只关注于一个特定的功能扩展,使得类更加简洁、高内聚。
-
灵活性:可以根据需求任意组合和排列各种装饰器,以实现不同的功能组合,从而满足不同客户的需求。
装饰器模式的缺点包括:
-
增加了对象数量:每个装饰器都会增加一个对象,可能会导致系统中对象的数量增加,增加了系统的复杂度。
-
可能产生过多小对象:如果使用过多的装饰器进行功能扩展,可能会产生大量的小对象,增加了系统的内存消耗和运行开销。
-
容易出错:由于装饰器模式允许动态地给对象添加功能,但不影响其结构,因此在设计和使用过程中容易出错,需要谨慎设计和管理。
综上所述,装饰器模式适用于需要动态地给对象添加功能,同时又希望保持对象结构稳定的情况下,但在使用过程中需要注意控制装饰器的数量,避免引入过多的复杂性。
迭代器模式【Iterator Pattern】
定义
迭代器模式(Iterator Pattern)是一种行为设计模式,它允许在不暴露集合底层表示的情况下顺序访问集合中的元素。迭代器模式提供了一种方法来遍历一个聚合对象中各个元素,而不暴露该对象的内部结构。

具体来说,迭代器模式包含两个核心角色:迭代器(Iterator)和聚合对象(Aggregate)。
-
迭代器(Iterator):迭代器是一个接口,它定义了在集合对象上遍历元素的方法,包括获取下一个元素、判断是否还有元素、重置迭代器等。
-
聚合对象(Aggregate):聚合对象是一个接口,它定义了创建相应迭代器对象的方法。聚合对象可能是一个集合,例如列表、数组、树等,也可能是一个复杂的数据结构。
迭代器模式的关键思想是将遍历集合的责任委托给迭代器对象,而不是将遍历逻辑硬编码在聚合对象中。这样做的好处是,可以更容易地实现不同类型的迭代器以适应不同类型的聚合对象,同时将遍历逻辑与集合的具体实现解耦,提高了代码的灵活性和可维护性。
总之,迭代器模式允许通过统一的接口来访问不同类型的集合,使得客户端代码可以更加简洁地遍历集合中的元素,同时提供了一种方法来隐藏集合的内部实现细节。
举例说明
假设你是一位图书馆管理员,需要管理图书馆中的各种书籍。你决定设计一个简单的图书管理系统,其中包括图书馆的书籍存储和检索功能。为了实现这一目标,你考虑使用迭代器模式来管理图书馆中的书籍集合。
在这个图书馆管理系统中,你有以下角色和元素:
-
书籍类(Book):代表图书馆中的一本书,包括书名、作者和出版日期等属性。
-
书架类(Bookshelf):代表图书馆中的书架,用于存放书籍。书架内部维护一个书籍列表,并提供了添加、删除和获取书籍的方法。
-
迭代器接口(Iterator):定义了迭代器的基本操作,如遍历下一个元素、判断是否还有下一个元素等。
-
具体迭代器类(BookIterator):实现了迭代器接口,用于遍历书架中的书籍列表。
在这个系统中,迭代器模式的核心思想是将书籍集合(书架)和遍历算法(迭代器)分离开来,使得你可以通过迭代器来访问书架中的书籍,而无需关心书架内部的具体实现。
举个例子,假设你有一个书架,上面摆放了几本书,包括《Java编程入门》、《Python实战指南》和《C++从入门到精通》。你可以使用迭代器模式来遍历这些书籍,并进行检索、借阅等操作,而无需直接操作书架内部的书籍列表。
通过这样的设计,你可以更加灵活地管理图书馆中的书籍,并且可以轻松地扩展系统,例如添加新的书籍类型或修改遍历算法,而不会影响到已有的代码逻辑。
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;// 书籍类
class Book {private String title;private String author;public Book(String title, String author) {this.title = title;this.author = author;}public String getTitle() {return title;}public String getAuthor() {return author;}@Overridepublic String toString() {return "Book{" +"title='" + title + '\'' +", author='" + author + '\'' +'}';}
}// 书架类
class Bookshelf implements Iterable<Book> {private List<Book> books;public Bookshelf() {this.books = new ArrayList<>();}public void addBook(Book book) {books.add(book);}public void removeBook(Book book) {books.remove(book);}@Overridepublic Iterator<Book> iterator() {return new BookIterator();}// 具体迭代器类private class BookIterator implements Iterator<Book> {private int index;@Overridepublic boolean hasNext() {return index < books.size();}@Overridepublic Book next() {if (hasNext()) {return books.get(index++);}throw new IndexOutOfBoundsException("No more books in the shelf.");}}
}public class LibrarySystem {public static void main(String[] args) {// 创建书架Bookshelf bookshelf = new Bookshelf();// 向书架添加书籍bookshelf.addBook(new Book("Java编程入门", "张三"));bookshelf.addBook(new Book("Python实战指南", "李四"));bookshelf.addBook(new Book("C++从入门到精通", "王五"));// 使用迭代器遍历书架中的书籍并打印Iterator<Book> iterator = bookshelf.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}}
}
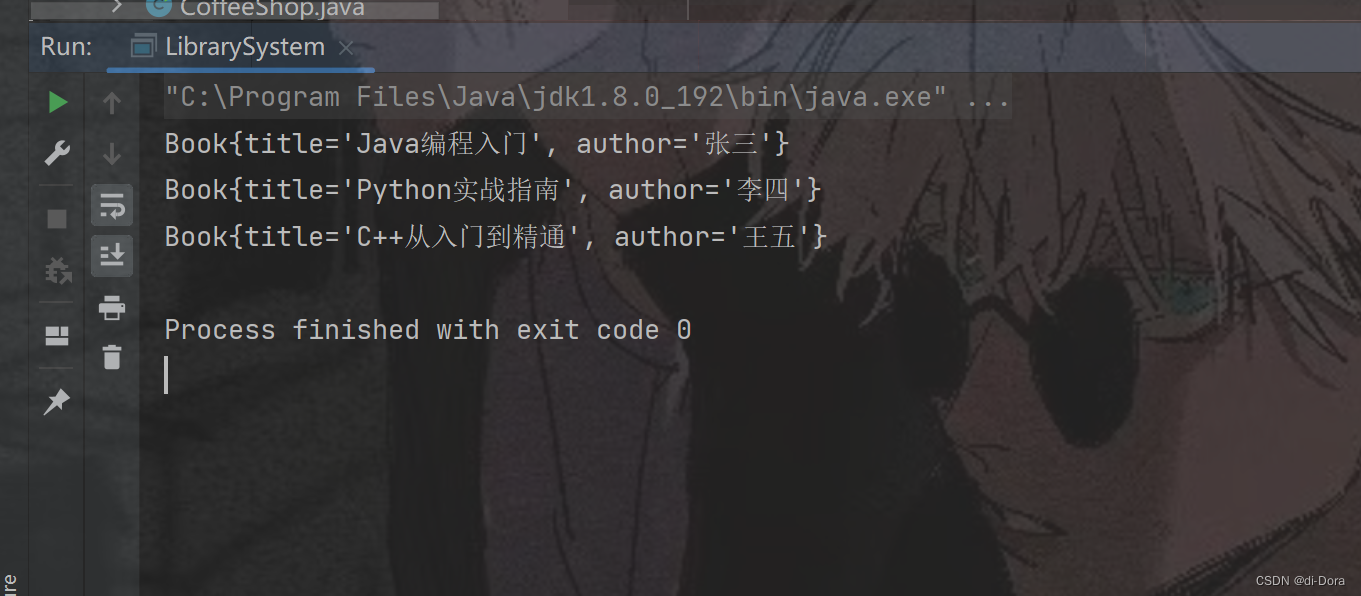
核心思想
迭代器模式的核心思想是将遍历集合的责任从集合对象中分离出来,将其封装在一个单独的迭代器对象中。这样,客户端就可以通过迭代器对象逐个访问集合中的元素,而不必了解集合内部的结构和实现细节。
迭代器模式包含以下关键思想:
-
分离集合和遍历逻辑:迭代器模式将集合的遍历操作从集合对象中抽离出来,放置在一个独立的迭代器对象中。这样一来,客户端就可以通过迭代器对象来访问集合元素,而无需了解集合的内部结构。
-
统一遍历接口:迭代器模式定义了一个统一的遍历接口,包括获取下一个元素、判断是否还有元素、重置迭代器等方法。所有的迭代器都实现了这个接口,使得客户端可以通过相同的方式来遍历不同类型的集合。
-
支持多种遍历方式:迭代器模式可以支持多种不同的遍历方式,例如顺序遍历、逆序遍历、深度优先遍历、广度优先遍历等。通过提供不同的迭代器实现类,客户端可以选择合适的遍历方式来满足自己的需求。
总之,迭代器模式的核心思想是通过将遍历逻辑抽象出来,使得集合和遍历逻辑可以独立变化,从而提高了代码的灵活性和可维护性。
适用场景
迭代器模式适用于以下场景:
-
需要访问一个聚合对象的内容,而又不暴露其内部表示的情况:迭代器模式可以提供一种访问聚合对象的方式,同时又不暴露其内部结构和实现细节,从而使得客户端可以安全地遍历集合中的元素。
-
需要对聚合对象提供多种遍历方式:迭代器模式可以定义多个不同的迭代器实现类,每个实现类可以提供不同的遍历方式,如顺序遍历、逆序遍历、深度优先遍历、广度优先遍历等,从而满足不同的需求。
-
需要统一对待不同类型的聚合对象:通过使用迭代器模式,可以为不同类型的聚合对象提供统一的遍历接口,使得客户端可以以相同的方式处理不同类型的集合,提高了代码的复用性和可扩展性。
-
需要在不同集合之间切换遍历方式:迭代器模式可以为集合对象提供多个不同的迭代器实现类,客户端可以根据需要在不同的集合之间切换遍历方式,而无需修改客户端代码,从而提高了代码的灵活性。
总之,迭代器模式适用于需要统一访问集合对象并提供多种遍历方式的情况,以及需要解耦集合对象和遍历逻辑的情况。
优缺点
迭代器模式的优点包括:
-
简化集合遍历:迭代器模式提供了一种统一的方式来遍历集合对象,无需关心集合的具体实现细节,使得遍历操作变得简单和统一。
-
解耦集合和遍历逻辑:通过迭代器模式,集合对象和遍历逻辑之间的耦合度降低,集合对象可以独立于遍历算法进行变化和修改,从而提高了代码的灵活性和可维护性。
-
多种遍历方式:迭代器模式可以定义多个不同的迭代器实现类,每个实现类可以提供不同的遍历方式,使得客户端可以根据需要选择合适的遍历方式,从而满足不同的需求。
-
支持逆向遍历:迭代器模式可以支持逆向遍历,即从集合末尾向集合开头遍历,这在某些情况下是非常有用的。
迭代器模式的缺点包括:
-
增加了系统复杂度:引入迭代器模式会增加额外的类和接口,增加了系统的复杂度,特别是在需要定义多种不同的迭代器实现类时,可能会导致类的数量增加。
-
遍历速度慢:在某些情况下,使用迭代器模式可能会导致遍历速度较慢,特别是在遍历大型集合对象时,因为每次迭代都需要调用迭代器的方法。
-
不适合对数据结构修改频繁的情况:迭代器模式适用于对集合对象进行频繁遍历的情况,但不适用于对集合对象进行频繁修改的情况,因为在遍历过程中修改集合对象可能会导致迭代器失效或遍历结果不确定。
组合模式【Composite Pattern】
定义
组合模式(Composite Pattern)是一种结构型设计模式,有时又叫做部分—整体模式(Part-Whole),主要是用来描述整体与部分的关系,用的最多的地方就是树形结构。它允许我们将对象组合成树形结构来表现“整体—部分”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
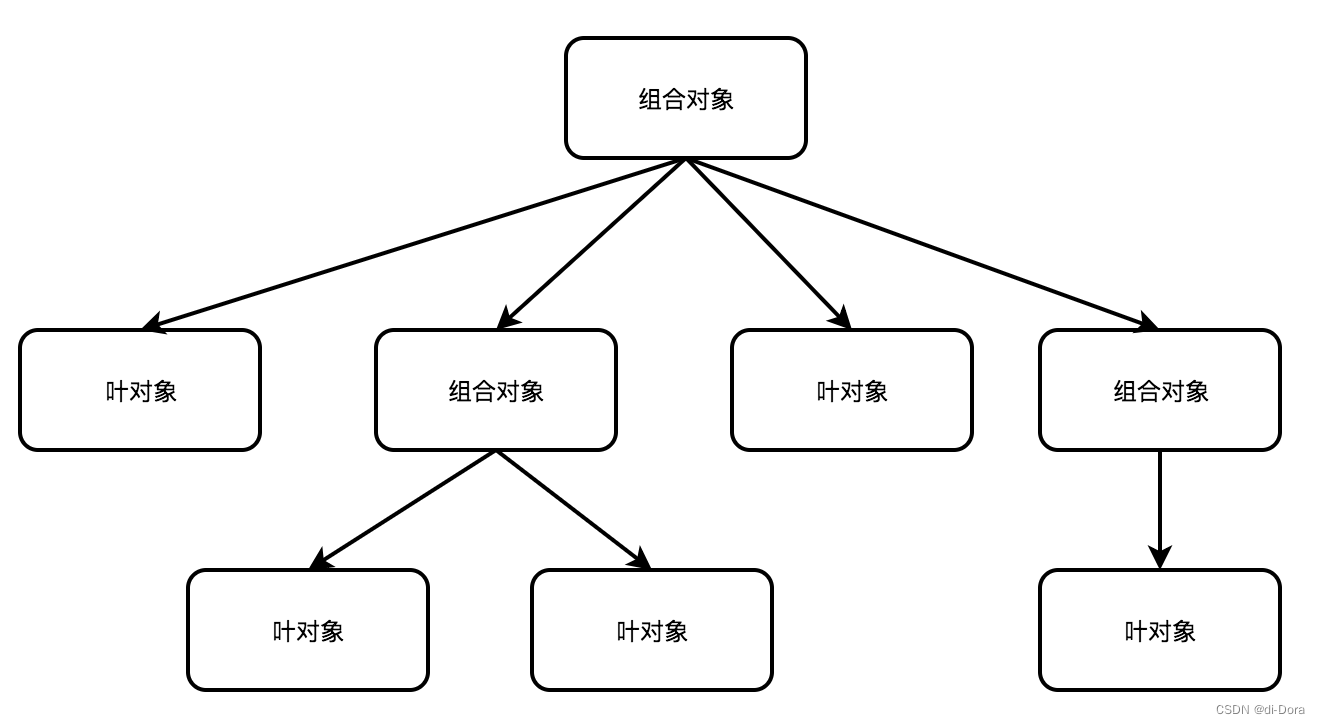
组合模式允许客户端代码统一对待单个对象和组合对象。在组合模式中,单个对象(叶节点)和组合对象(树枝节点)都实现了相同的接口,这样客户端就可以统一调用这些对象的方法,而无需关心它们是单个对象还是组合对象。组合模式通过递归组合的方式来构建树形结构,使得整个结构可以被一致地处理。
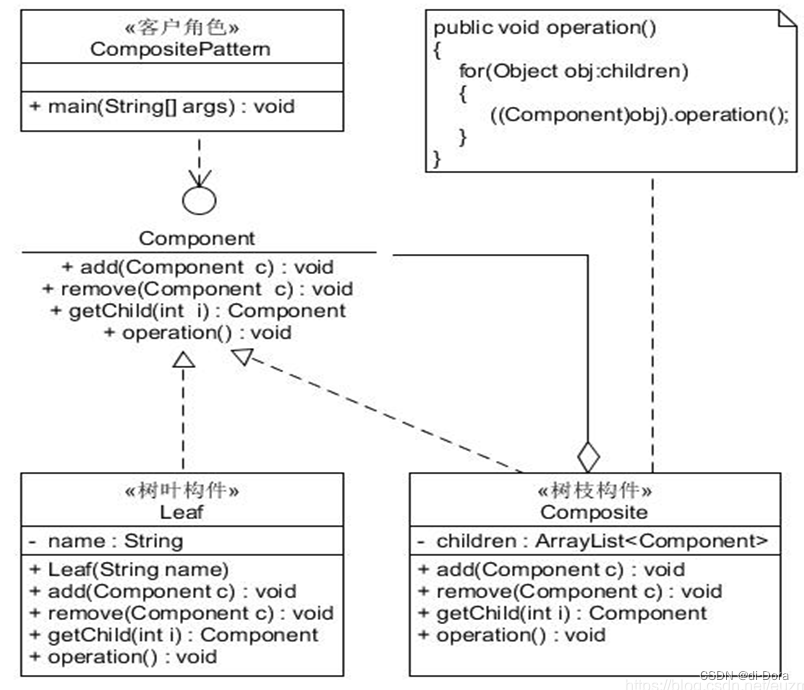
在组合模式中,一般会有以下角色:
-
Component(组件): 定义组合中所有对象的通用接口,可以是抽象类或接口,声明了叶子节点和组合节点的共同点,提供了管理子节点的方法,如添加、移除、获取子节点等。
-
Leaf(叶子节点): 表示组合中的叶子节点对象,它没有子节点,实现了组件接口的方法。
-
Composite(组合节点): 表示组合中的组合节点对象,它有子节点,通常存储子节点的集合,并实现了组件接口的方法,用于管理其子节点。
在组合模式中,可以根据叶子节点和组合节点的公共接口是否包含对子节点的管理方法来区分两种不同的实现方式,即透明模式和安全模式。
-
透明模式(Transparent Mode):
- 在透明模式中,抽象组件(Component)接口中包含了对子节点的管理方法,如添加子节点、移除子节点、获取子节点等。这意味着无论是叶子节点还是组合节点都必须实现这些管理方法,即使叶子节点并不具备子节点,但它们仍然需要提供这些方法。
- 透明模式让客户端对叶子节点和组合节点的处理更加统一,因为它们都遵循了相同的接口。但是,叶子节点实现了一些对于自身并不适用的方法,这可能会导致一些不必要的复杂性。
-
安全模式(Safe Mode):
- 在安全模式中,抽象组件(Component)接口不包含对子节点的管理方法,而是将这些方法放在了组合节点(Composite)中。叶子节点(Leaf)不需要实现这些管理方法,因为它们本身就没有子节点。
- 安全模式更加清晰和简洁,每个对象都只需要实现自己相关的方法,不会有额外的冗余。但是,客户端需要对叶子节点和组合节点进行类型检查,以确保调用的方法是合法的,这可能增加一些额外的逻辑处理。
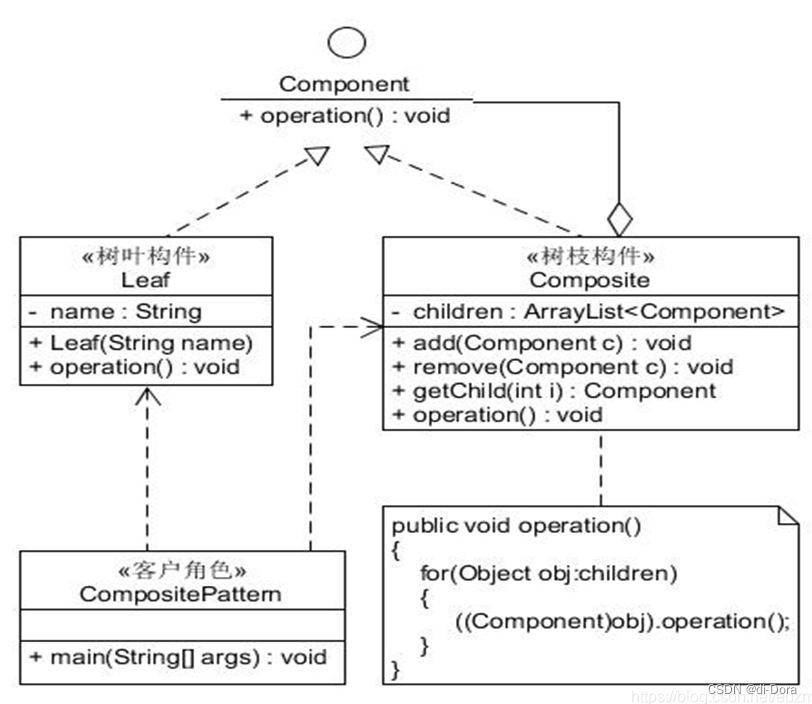
因此,透明模式在提供统一接口方面更加便利,但可能会引入一些不必要的方法实现;而安全模式更加清晰简洁,但需要客户端对节点类型进行检查以确保方法调用的合法性。选择适合的模式取决于具体的应用场景和需求。
举例说明
假设你是一位园艺爱好者,你有一个植物园,里面有各种各样的植物,包括树木、花卉和灌木等。现在你想要设计一个植物目录系统,方便游客查找和了解各种植物。
在这个场景中,你可以使用组合模式来管理植物目录。你可以将植物分为两种类型:单个植物和植物组合。单个植物指的是具体的一种植物,例如玫瑰、松树等;而植物组合则是由多种植物组成的集合,例如花园、森林等。
当你开始设计植物目录系统时,首先需要考虑的是如何表示植物及其组合。为此,你可以创建一个抽象的植物组件接口,让所有植物和植物组合都实现这个接口。这样,无论是单个植物还是植物组合,都能够被当做同一种类型来处理。
// 植物组件接口
interface PlantComponent {void display();
}
接着,你可以定义两个具体的类来实现这个接口:单个植物类和植物组合类。单个植物类表示具体的一种植物,它会包含植物的名称、描述等信息;而植物组合类表示由多种植物组成的集合,它会包含一个植物列表,用来存储所有组成该组合的植物。
// 单个植物类
class SinglePlant implements PlantComponent {private String name;private String description;public SinglePlant(String name, String description) {this.name = name;this.description = description;}@Overridepublic void display() {System.out.println("植物名称:" + name);System.out.println("植物描述:" + description);}
}
在创建植物目录时,你可以按照层次结构逐步组合植物。比如,你可以先创建一些单个植物对象,如玫瑰、松树等,然后将它们组合成一个花园,再将多个花园组合成一个更大的景点,如森林或者公园。
import java.util.ArrayList;
import java.util.List;// 植物组合类
class PlantComposite implements PlantComponent {private List<PlantComponent> children = new ArrayList<>();// 添加植物或植物组合public void add(PlantComponent component) {children.add(component);}// 移除植物或植物组合public void remove(PlantComponent component) {children.remove(component);}@Overridepublic void display() {for (PlantComponent component : children) {component.display();}}
}
除了表示植物的层次结构外,你还可以为植物组合类提供一些额外的方法,如添加植物、移除植物等,以便动态地管理植物的组成。
最后,在展示植物目录时,你可以调用植物组合类的显示方法,它会递归地遍历所有的子植物和子植物组合,并将它们的信息逐一展示出来,让游客能够清晰地了解每种植物及其组合的情况。
public class Main {public static void main(String[] args) {// 创建单个植物SinglePlant rose = new SinglePlant("玫瑰", "红色花朵");SinglePlant pine = new SinglePlant("松树", "常绿树木");// 创建植物组合PlantComposite garden = new PlantComposite();garden.add(rose);garden.add(pine);// 创建更大的植物组合PlantComposite forest = new PlantComposite();forest.add(garden);// 显示植物目录System.out.println("植物目录:");forest.display();}
}
这样一来,你就可以利用组合模式来设计一个灵活而强大的植物目录系统,方便游客查找和了解各种植物,同时也为你管理植物园提供了便利。
核心思想
组合模式的核心思想是将对象组织成树形结构,使得单个对象和组合对象(容器对象)具有一致的接口,从而使客户端可以统一地对待单个对象和组合对象。这种统一性使得客户端无需关心处理的是单个对象还是组合对象,而只需通过统一的接口进行操作。
具体来说,组合模式由以下几个要点构成其核心思想:
-
抽象构件(Component): 定义了对象接口,可以是组合对象或叶子对象,它们具有相同的接口,可以作为组合结构的基类。抽象构件声明了在组合对象和叶子对象中都可以被调用的操作。
-
叶子构件(Leaf): 是组合结构中的叶子节点,表示对象的基本单元,叶子节点没有子节点,通常实现了抽象构件接口的操作。
-
组合构件(Composite): 是组合结构中的容器节点,可以包含叶子节点和其他组合节点,它实现了抽象构件接口,并且通常包含了一个集合用于存储子节点。
-
客户端(Client): 通过抽象构件接口操作组合结构,客户端无需区分是单个对象还是组合对象,统一地处理组合结构中的各个节点。
-
递归遍历: 组合模式通常使用递归来遍历组合结构,客户端可以通过递归遍历整个树形结构,从而对组合对象和叶子对象进行操作。
总的来说,组合模式的核心思想是通过统一的接口和树形结构来组织对象,使得客户端可以统一地对待单个对象和组合对象,从而简化了客户端的使用和维护
适用场景
组合模式适用于以下场景:
-
对象的结构具有树形层次结构: 当对象的结构呈现树形层次结构,且客户端需要统一地处理单个对象和组合对象时,可以考虑使用组合模式。例如,文件系统中的文件夹和文件之间的关系,以及菜单和菜单项之间的关系。
-
希望客户端统一处理单个对象和组合对象: 当希望客户端能够统一地对待单个对象和组合对象时,组合模式可以很好地满足这一需求。客户端无需关心处理的是单个对象还是组合对象,只需通过统一的接口进行操作。
-
需要递归地处理组合对象的情况: 组合模式适用于需要递归地处理组合对象的情况。通过递归遍历整个树形结构,可以方便地对组合对象和叶子对象进行操作。
-
希望在不同层次对对象进行操作: 组合模式可以让客户端在不同的层次对对象进行操作,例如在树形结构中,客户端可以在整个树上进行操作,也可以仅在某个分支上进行操作,从而实现灵活的操作。
组合模式适用于对象的结构具有树形层次结构,且希望客户端能够统一处理单个对象和组合对象的情况。
优缺点
组合模式(Composite Pattern)的优点和缺点如下:
优点:
- 统一的接口: 组合模式提供了统一的接口,使得客户端可以统一处理单个对象和组合对象,简化了客户端的代码逻辑。
- 灵活性: 可以通过组合模式轻松地构建树形结构,且可以动态地添加或删除对象,从而实现灵活的结构。
- 易于扩展: 添加新类型的组合对象或叶子对象很容易,不会影响到已有的代码。
- 便于管理: 组合模式将单个对象和组合对象统一对待,使得对象的管理更加方便。
缺点:
- 设计复杂性: 实现组合模式可能需要定义多个类和接口,增加了系统的复杂性。
- 不易理解: 对于初学者来说,理解组合模式的思想可能有一定难度,需要花费一些时间和精力。
- 性能问题: 在处理大量对象时,可能会带来一些性能上的开销,因为需要递归遍历整个树形结构。
总的来说,组合模式适用于需要构建树形结构并统一处理单个对象和组合对象的情况,但在设计时需要权衡好复杂性和性能问题。
观察者模式【Observer Pattern】
定义
观察者模式是一种行为设计模式,它允许对象(称为观察者)订阅另一个对象(称为主题或可观察者),以便在主题状态发生变化时自动接收通知。在观察者模式中,主题维护一组观察者,并在其状态发生变化时通知它们,使得观察者可以自动更新。
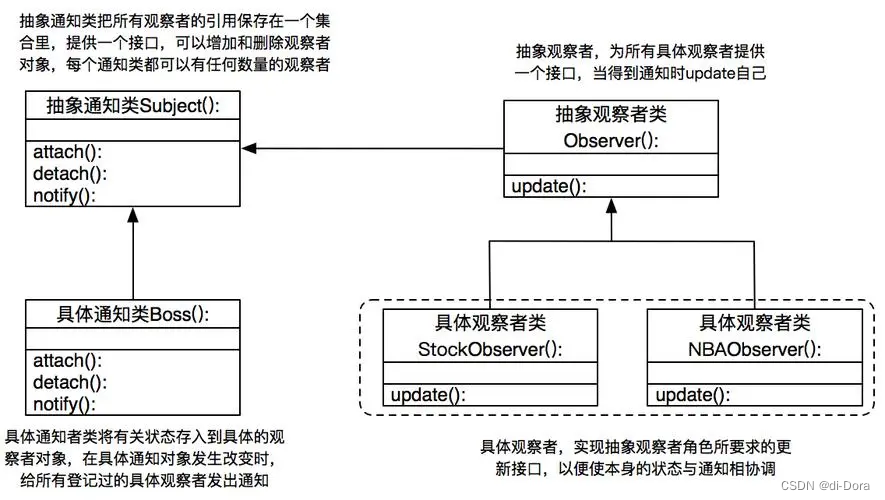
具体来说,观察者模式包含以下几个关键角色:
-
Subject(主题):也称为可观察者,维护一组观察者对象,并提供方法来注册(订阅)和移除观察者,以及通知观察者状态变化的方法。
-
Observer(观察者):定义一个更新接口,使得在主题状态发生变化时能够得到通知并进行相应的更新操作。
-
ConcreteSubject(具体主题):实现主题接口,具体主题内部状态发生变化时会通知其注册的所有观察者。
-
ConcreteObserver(具体观察者):实现观察者接口,定义具体的更新逻辑,以便在接收到主题通知时进行相应的更新操作。
通过观察者模式,实现了主题与观察者之间的解耦,使得主题状态变化时能够灵活地通知到所有相关的观察者,从而实现了对象之间的一对多依赖关系。
举例说明
假设你经营一家宠物商店,你想要实现一个宠物领养系统,让用户可以及时了解到新到达的可爱小动物。在这个场景中,你可以使用观察者模式来实现。
具体地说,你可以将用户视为观察者(或订阅者),而新到达的小动物视为目标(或主题)。当有新的小动物到达时,所有订阅了通知的用户都会收到相应的消息,以便他们可以及时了解到并前来领养。
这个例子中,宠物商店管理员充当主题,而顾客充当观察者。当有新的小动物到达时,管理员会通知所有已订阅的顾客,并提供相关的信息,如动物种类、性别、年龄等。顾客可以根据这些信息来决定是否前来领养新的小宠物。
import java.util.ArrayList;
import java.util.List;// 主题接口
interface Subject {void registerObserver(Observer observer);void removeObserver(Observer observer);void notifyObservers(String animalType, String gender, int age);
}// 具体主题:宠物商店管理员
class PetStoreManager implements Subject {private List<Observer> observers;public PetStoreManager() {this.observers = new ArrayList<>();}@Overridepublic void registerObserver(Observer observer) {observers.add(observer);}@Overridepublic void removeObserver(Observer observer) {observers.remove(observer);}@Overridepublic void notifyObservers(String animalType, String gender, int age) {for (Observer observer : observers) {observer.update(animalType, gender, age);}}// 新到达小动物的方法public void newAnimalArrival(String animalType, String gender, int age) {System.out.println("New animal arrived: " + animalType + ", " + gender + ", " + age + " years old");notifyObservers(animalType, gender, age);}
}// 观察者接口
interface Observer {void update(String animalType, String gender, int age);
}// 具体观察者:顾客
class Customer implements Observer {private String name;public Customer(String name) {this.name = name;}@Overridepublic void update(String animalType, String gender, int age) {System.out.println(name + " received notification: New " + animalType + " available - Gender: " + gender + ", Age: " + age);}
}public class PetAdoptionSystem {public static void main(String[] args) {// 创建宠物商店管理员PetStoreManager petStoreManager = new PetStoreManager();// 创建两个顾客Customer customer1 = new Customer("Alice");Customer customer2 = new Customer("Bob");// 注册顾客为观察者petStoreManager.registerObserver(customer1);petStoreManager.registerObserver(customer2);// 模拟新小动物到达petStoreManager.newAnimalArrival("Cat", "Male", 2);petStoreManager.newAnimalArrival("Dog", "Female", 1);// 顾客可以选择领养// ...}
}
核心思想
观察者模式的核心思想是定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。当这个主题对象的状态发生变化时,所有依赖于它的观察者都会得到通知并自动更新。
这种设计模式的核心思想可以总结为两点:
-
解耦性:观察者模式实现了主题和观察者之间的解耦。主题不需要知道观察者的具体实现,只需知道它们都实现了相同的接口即可。这样一来,主题对象可以自由地改变和添加观察者,而不需要修改自身的代码。
-
通知机制:主题对象维护了一个观察者列表,当自身状态发生变化时,会依次通知所有的观察者。这种通知机制使得观察者可以实时获取到主题的最新状态,并进行相应的处理和更新。
总的来说,观察者模式的核心思想是基于事件的通知机制,它允许对象之间建立一种松耦合的关系,从而实现了对象之间的动态交互和通信。
适用场景
观察者模式通常在以下情况下使用:
-
当一个对象的状态发生变化需要通知其他对象,并且不需要知道具体是哪些对象需要被通知时,可以使用观察者模式。这样的情况下,被观察对象(主题)就充当了消息的发布者,而观察者则充当了消息的订阅者。
-
当一个对象需要将自己的变化通知给多个其他对象,并且这些对象需要在状态变化后执行不同的操作时,也可以使用观察者模式。观察者模式允许多个观察者订阅同一个主题,每个观察者可以根据自身需要执行相应的操作,而不需要被通知的对象知道其他对象的存在。
观察者模式适用于以下场景:
-
发布-订阅系统:当一个对象的状态发生变化需要通知其他对象,并且这些对象的数量和类型在运行时可能发生变化时,可以使用观察者模式。例如,新闻订阅系统中,订阅者可以选择订阅感兴趣的新闻主题,并在发布新闻时收到相应的通知。
发布/订阅模型就是观察者模式的一种变体,也被称为 Pub/Sub 模式。与传统的观察者模式不同,发布/订阅模型中,发布者(发布主题)和订阅者之间不直接进行通信,而是通过一个称为消息代理(Message Broker)或事件通道(Event Channel)的中介来进行交互。
在发布/订阅模型中,发布者(或称为生产者)负责向消息代理发布消息,而订阅者(或称为消费者)则向消息代理订阅感兴趣的主题或频道。当发布者发布了新的消息时,消息代理会将消息传递给所有订阅了相应主题的订阅者。
这种模式的好处是发布者和订阅者之间解耦,发布者不需要知道谁订阅了它的消息,而订阅者也不需要知道消息来自哪个发布者。这样可以更灵活地组织和管理消息传递,适用于分布式系统和大规模应用场景。
-
GUI开发:在图形用户界面(GUI)开发中,经常需要实时更新界面上的数据或状态,观察者模式可以用于实现界面和数据之间的同步。例如,一个数据模型的变化可以触发多个界面组件的更新。
-
事件驱动系统:在事件驱动的系统中,观察者模式常被用于处理事件的订阅和分发。当某个事件发生时,可以通知所有相关的观察者进行相应的处理。例如,网络服务器收到请求时,可以通过观察者模式通知注册的请求处理器进行处理。
-
异步编程:在异步编程中,观察者模式可以用于处理异步任务的完成通知。当一个异步任务完成时,可以通知所有注册的观察者进行后续的处理。例如,JavaScript中的Promise对象就提供了类似的观察者机制。
关于观察者模式的两个重点问题:
-
广播链的问题:当观察者模式中的观察者之间存在相互依赖或者相互通知的情况时,可能会形成广播链,导致不必要的性能消耗和逻辑复杂度。为了解决这个问题,可以使用消息代理或者事件总线等中间件来进行消息的发布和订阅,将消息的传递和处理解耦,避免形成广播链。
-
异步处理问题:当观察者模式中的消息处理逻辑比较复杂或者耗时较长时,可能会阻塞消息的发布者,影响系统的响应速度。为了解决这个问题,可以使用异步处理机制来处理观察者收到的消息,将消息的处理逻辑放在异步任务中进行处理,从而提高系统的并发能力和响应速度。当然,异步处理就要考虑线程安全和队列的问题。
总的来说,观察者模式适用于任何需要在对象之间建立动态的、松耦合的通信机制的场景。它可以帮助实现对象之间的解耦,提高系统的灵活性和可维护性。
优缺点
观察者模式的优点包括:
-
松耦合性:观察者模式使得目标对象和观察者对象之间保持松耦合关系,它们之间并不直接相互调用,而是通过抽象的接口进行通信。
-
可扩展性:通过增加或移除观察者,可以灵活地扩展系统的功能,无需修改目标对象或其他观察者。
-
复用性:观察者模式使得目标对象和观察者对象可以在不同的地方复用,增加了代码的可复用性。
-
通知机制:目标对象发生变化时,会自动通知所有注册的观察者,使得观察者可以及时获取更新的信息。
观察者模式的缺点包括:
-
过多的细节:当观察者很多时,目标对象通知所有观察者可能会导致性能问题。此外,如果观察者之间有循环依赖关系,可能会导致系统的复杂性增加。
-
可能引起内存泄漏:在Java等语言中,如果观察者没有被正确地释放,可能会导致内存泄漏问题。
-
通知顺序不确定:观察者模式中观察者的通知顺序通常是不确定的,这可能会导致一些问题,例如某个观察者依赖于其他观察者的通知顺序。
综上所述,观察者模式适用于需要实现对象之间松耦合、动态通信的场景,但在设计时需要注意控制观察者数量,避免过多的细节和潜在的性能问题。
责任链模式【Chain of Responsibility Pattern】
定义
责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,用于解耦发送者和接收者之间的请求。在该模式中,多个对象(处理者)依次处理同一个请求,直到其中一个处理者能够处理该请求为止。
责任链模式包含一系列对象,每个对象都有指定的职责。当收到请求时,每个对象有两种处理方式:
- 将请求传递给下一个处理者。
- 自己处理请求。
责任链模式的核心思想是将多个处理者组成一条链,请求沿着这条链传递,直到有一个处理者能够处理它为止。这样可以使请求的发送者和接收者解耦,同时灵活地添加、修改或移除处理者,而不会影响到整个链条的结构。
在责任链模式中,通常会建立一个抽象处理者(Handler)类,其中包含处理请求的方法以及一个指向下一个处理者的引用。具体的处理者(ConcreteHandler)继承自抽象处理者,并实现自己的处理逻辑和判断条件。当收到请求时,抽象处理者首先判断自己是否能够处理该请求,如果可以则进行处理,否则将请求传递给下一个处理者,直到有一个处理者能够处理它为止。

举例说明
假设你是一家快递公司的客服代表,负责处理客户的投诉问题。有时候客户可能会投诉包裹未按时送达、包裹损坏或丢失等问题。为了高效处理这些投诉,你可以使用责任链模式。
在这个场景中,快递公司的客户投诉可以分为多个级别,例如普通投诉、紧急投诉和重大投诉。每个级别的投诉都需要不同级别的处理者来处理,而且处理者之间存在着优先级关系。
具体地说,你作为客服代表是责任链的起始点,负责接收客户的投诉并进行初步处理。如果投诉是普通级别的,你可以直接处理;如果是紧急级别的,你需要将投诉转发给紧急处理者;如果是重大级别的,你需要将投诉转发给重大处理者。
紧急处理者可能是客户服务主管,负责处理一些比较紧急但不是很严重的投诉问题,例如包裹送错地址、派送延误等。而重大处理者可能是公司高层管理人员,负责处理一些非常严重的投诉问题,例如大面积包裹丢失、严重的服务质量问题等。
这样,当客户提交投诉时,投诉会根据其级别被依次转发给不同级别的处理者,直到找到合适的处理者为止。这就是责任链模式的核心思想:将请求沿着处理链进行传递和处理,直到有一个处理者能够处理该请求为止。
// 客户投诉类
class CustomerComplaint {private String level;private String description;public CustomerComplaint(String level, String description) {this.level = level;this.description = description;}public String getLevel() {return level;}public String getDescription() {return description;}
}// 投诉处理者接口
interface ComplaintHandler {void handleComplaint(CustomerComplaint complaint);
}// 客服代表,责任链的起始点
class CustomerServiceRepresentative implements ComplaintHandler {private ComplaintHandler nextHandler;public void setNextHandler(ComplaintHandler nextHandler) {this.nextHandler = nextHandler;}@Overridepublic void handleComplaint(CustomerComplaint complaint) {if (complaint.getLevel().equals("普通")) {System.out.println("客服代表处理了普通投诉:" + complaint.getDescription());} else if (nextHandler != null) {nextHandler.handleComplaint(complaint);} else {System.out.println("没有合适的处理者来处理投诉:" + complaint.getDescription());}}
}// 紧急处理者
class EmergencyHandler implements ComplaintHandler {private ComplaintHandler nextHandler;public void setNextHandler(ComplaintHandler nextHandler) {this.nextHandler = nextHandler;}@Overridepublic void handleComplaint(CustomerComplaint complaint) {if (complaint.getLevel().equals("紧急")) {System.out.println("紧急处理者处理了紧急投诉:" + complaint.getDescription());} else if (nextHandler != null) {nextHandler.handleComplaint(complaint);} else {System.out.println("没有合适的处理者来处理投诉:" + complaint.getDescription());}}
}// 重大处理者
class MajorHandler implements ComplaintHandler {@Overridepublic void handleComplaint(CustomerComplaint complaint) {if (complaint.getLevel().equals("重大")) {System.out.println("重大处理者处理了重大投诉:" + complaint.getDescription());} else {System.out.println("没有合适的处理者来处理投诉:" + complaint.getDescription());}}
}// 客户端代码
public class ComplaintHandlingSystem {public static void main(String[] args) {CustomerServiceRepresentative representative = new CustomerServiceRepresentative();EmergencyHandler emergencyHandler = new EmergencyHandler();MajorHandler majorHandler = new MajorHandler();// 设置责任链关系representative.setNextHandler(emergencyHandler);emergencyHandler.setNextHandler(majorHandler);// 模拟客户投诉CustomerComplaint complaint1 = new CustomerComplaint("普通", "包裹未按时送达");CustomerComplaint complaint2 = new CustomerComplaint("紧急", "包裹损坏");CustomerComplaint complaint3 = new CustomerComplaint("重大", "大面积包裹丢失");// 客服代表处理投诉representative.handleComplaint(complaint1);representative.handleComplaint(complaint2);representative.handleComplaint(complaint3);}
}
核心思想
责任链模式的核心思想是将请求的发送者和接收者解耦,通过一条链(链表)将多个接收者组织起来,每个接收者都有机会处理请求。当请求被发送时,它沿着这条链传递,直到有一个接收者处理它为止。这样可以避免请求的发送者需要知道具体的接收者,从而提高系统的灵活性和可扩展性。
具体而言,责任链模式包含一系列处理者(Handler)对象,每个处理者都有指定的职责和处理逻辑。当一个请求到达时,它首先由链中的第一个处理者进行处理。如果该处理者能够处理该请求,则处理完毕;否则,它将请求传递给链中的下一个处理者,以此类推,直到有一个处理者处理了请求为止。
责任链模式的核心思想是将请求和处理者解耦,每个处理者只需关心自己能否处理请求,而不需要关心请求的具体来源和去向。这样可以轻松地添加、修改或删除处理者,而不会影响到整个系统的结构和稳定性。
适用场景
责任链模式通常适用于以下场景:
-
请求需要被多个对象处理:当一个请求需要经过多个对象处理,并且每个对象都可能处理或部分处理该请求时,可以使用责任链模式。例如,一个请求需要经过多个审批层级才能最终被批准。
-
请求的处理者之间存在动态变化:责任链模式允许动态地增加或修改处理者,而不需要修改客户端代码。这使得系统更加灵活和可扩展。例如,在一个日志处理系统中,可以根据需要动态地添加不同级别的日志处理者。
-
请求的发送者不需要知道具体的处理者:责任链模式可以将请求的发送者和接收者解耦,发送者只需将请求发送到责任链上,而不需要知道具体的接收者是谁。
-
请求需要被处理者中的一个或多个处理:责任链模式可以确保一个请求被处理者中的一个或多个处理,而不是只有一个处理者处理请求。这种情况下,每个处理者都有机会对请求进行处理,增加了系统的灵活性和可配置性。
优缺点
责任链模式的优点包括:
-
降低耦合度:责任链模式将请求的发送者和接收者解耦,发送者不需要知道具体的接收者是谁,而只需将请求发送到责任链上即可。这样可以降低系统各部分之间的耦合度,提高系统的灵活性和可维护性。
-
灵活性和可扩展性:责任链模式允许动态地增加或修改处理者,而不需要修改客户端代码。这样可以根据需要灵活地调整责任链的结构和处理逻辑,使系统更具可扩展性。
-
责任分担:责任链模式将请求分配给多个处理者,每个处理者都有机会对请求进行处理。这样可以避免将所有处理逻辑集中到一个类中,提高代码的可读性和可维护性。
-
单一职责原则:每个具体处理者只需关注自己的处理逻辑,不需要关心其他处理者的实现细节。这有助于确保每个类都遵循单一职责原则,使代码更加清晰和易于理解。
责任链模式的缺点包括:
-
请求处理不确定性:由于请求的处理者是动态确定的,并且一个请求可能被多个处理者处理,因此可能导致请求的处理结果不确定性,难以追踪和调试。
-
性能问题:责任链模式可能会导致请求在责任链上遍历多次,直到找到合适的处理者为止。如果责任链过长或处理者逻辑复杂,可能会影响系统的性能。
-
可能导致循环引用:在责任链中,处理者之间可能会相互引用,形成闭环。如果处理者之间的引用关系设置不当,可能会导致循环引用,从而影响系统的正常运行。
补充说明:观察者广播链和责任链虽然都涉及到消息的传递,但它们在实现方式和应用场景上有明显的区别:
-
受众数量不同:
- 观察者广播链可以实现 1:N 的方式广播,即一个事件发生后可以通知多个观察者,并且每个观察者可以再通知其他观察者,形成一个广播链。
- 责任链要求是 1:1 的传递,即一个请求只能被一个责任链中的处理者处理,责任链中的节点是线性的,请求只能按照责任链的顺序依次传递,直到找到合适的处理者为止。
-
请求内容不同:
- 观察者广播链中的信息可以在传播中改变,每个观察者都可以对接收到的消息进行处理或修改,并将修改后的消息传递给下一个观察者。这种情况下,消息的内容可能会随着传播路径的不同而改变。
- 责任链中的请求是不可改变的,一旦请求被创建,其内容就不会在传递过程中改变。责任链中的每个处理者要么处理请求,要么将请求传递给下一个处理者,不会对请求进行修改。
-
处理逻辑不同:
- 观察者广播链主要用于触发联动动作,当一个事件发生时,通过观察者模式通知所有相关的观察者,并让它们执行相应的动作,形成一个联动。
- 责任链则是对一个类型的请求按照既定的规则进行处理,责任链中的每个节点都有可能处理请求,但只有符合特定条件的节点才会真正处理请求,其他节点会将请求传递给下一个节点。
总的来说,观察者广播链适用于需要多个对象之间进行松耦合通信的场景,而责任链适用于需要按照特定顺序处理请求,并且每个请求只能被一个处理者处理的场景。
访问者模式【Visitor Pattern】
定义
访问者模式(Visitor Pattern)是一种行为设计模式,它允许我们在不修改现有类的情况下定义一些新的操作。访问者模式将算法与操作的元素结构进行分离,使得可以在不修改这些元素的情况下,定义作用于这些元素的新操作。
具体来说,访问者模式包含以下几个要素:
-
访问者(Visitor):定义了对对象结构中每个元素进行访问的操作。这些操作可以是不同的,根据具体的需求进行设计。通常情况下,访问者模式会定义一个抽象的访问者接口,包含对每个元素对象进行访问的方法。
-
具体访问者(Concrete Visitor):实现了访问者接口,提供了对元素对象的不同操作的具体实现。每个具体访问者都可以根据需要来定义自己的操作。
-
元素对象(Element):定义了一个接受访问者访问的接口,通常包含一个接受操作的方法。元素对象可以是单个对象,也可以是一个对象的集合。
-
具体元素对象(Concrete Element):实现了元素对象接口,提供了具体的接受操作的实现。
-
对象结构(Object Structure):扮演了元素对象的容器角色,可以是一个单独的对象,也可以是一个集合。对象结构提供了一个接受访问者访问的方法,使得访问者可以访问对象结构中的每个元素对象。
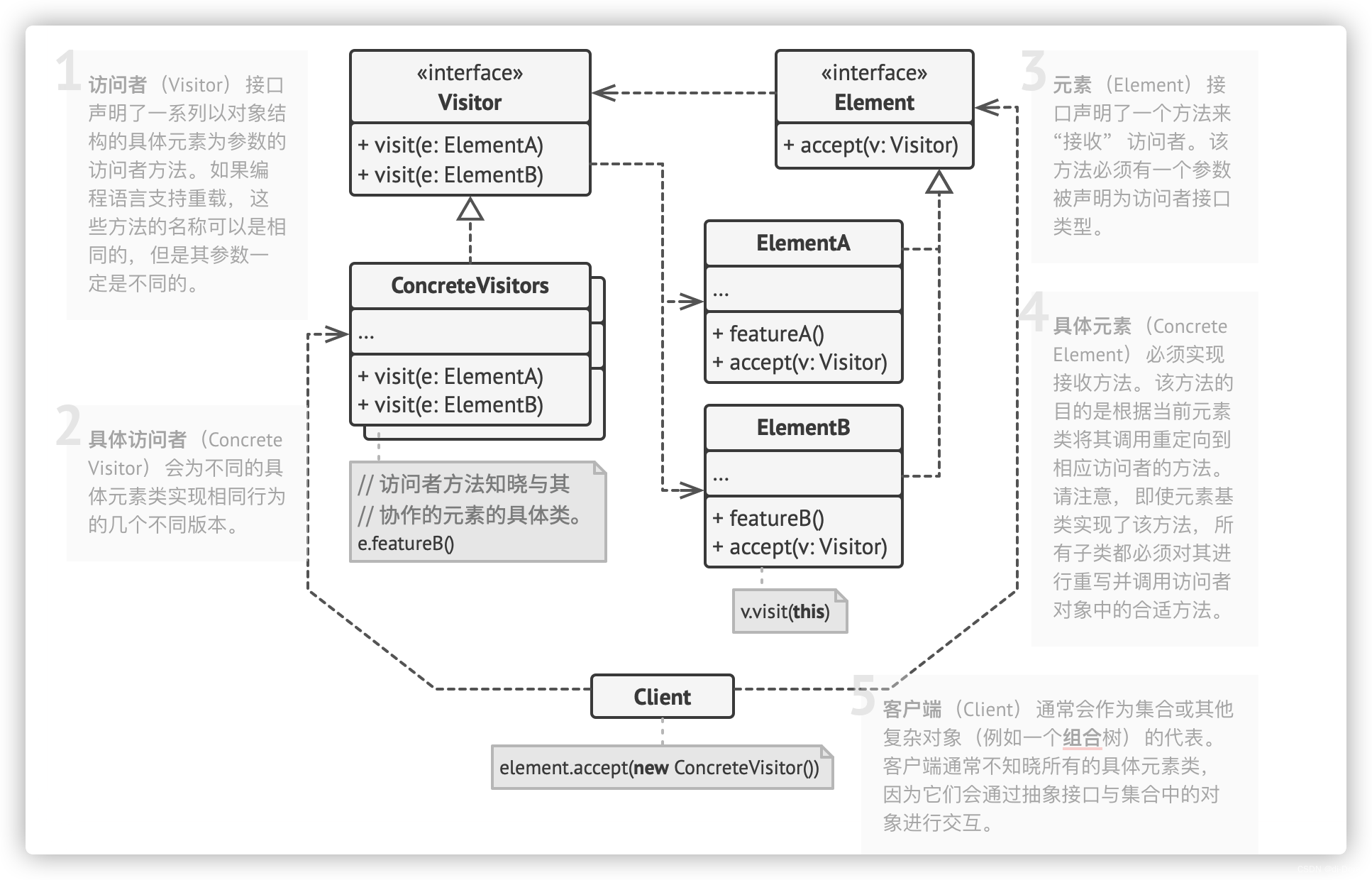
通过访问者模式,我们可以在不修改元素对象的情况下,定义新的操作,同时也不会破坏元素对象的封装性。这种分离了元素对象和操作的设计方式使得访问者模式在处理复杂的对象结构和多种操作时非常有用。
举例说明
假设你是一位博物馆管理员,你管理着一个博物馆,里面展示着各种珍贵的文物,包括陶器、绘画、雕塑等。现在你想要设计一个文物评估系统,方便专家对文物进行评估,并根据评估结果进行分类和处理。
在这个场景中,你可以使用访问者模式来实现文物评估系统。你可以将文物分为不同的类型,例如陶器、绘画、雕塑等,每种类型的文物都有自己的特点和评估标准。评估专家可以作为访问者,根据自己的专业领域对文物进行评估,并给出评估结果。
具体地说,你可以设计一个文物类(Artifact),其中包含各种类型的文物,例如陶器、绘画、雕塑等。然后你可以设计一个评估专家接口(Evaluator),其中包含各种评估方法,例如评估陶器的质量、绘画的艺术价值、雕塑的历史意义等。每个评估专家都实现了评估接口中的方法,根据自己的专业领域对文物进行评估。最后,你可以设计一个评估系统(EvaluationSystem),负责管理文物和评估专家,并将文物交给评估专家进行评估,然后根据评估结果进行分类和处理。
这个例子中,博物馆管理员充当对象结构,各种类型的文物充当具体元素,评估专家充当访问者,评估系统充当客户端。评估系统将文物交给评估专家进行评估,然后根据评估结果进行后续处理,实现了文物评估系统的设计和应用。
// 文物接口
interface Artifact {void accept(Evaluator evaluator);
}// 具体文物:陶器
class Pottery implements Artifact {@Overridepublic void accept(Evaluator evaluator) {evaluator.evaluatePottery(this);}
}// 具体文物:绘画
class Painting implements Artifact {@Overridepublic void accept(Evaluator evaluator) {evaluator.evaluatePainting(this);}
}// 具体文物:雕塑
class Sculpture implements Artifact {@Overridepublic void accept(Evaluator evaluator) {evaluator.evaluateSculpture(this);}
}// 评估专家接口
interface Evaluator {void evaluatePottery(Pottery pottery);void evaluatePainting(Painting painting);void evaluateSculpture(Sculpture sculpture);
}// 具体评估专家:陶器评估专家
class PotteryEvaluator implements Evaluator {@Overridepublic void evaluatePottery(Pottery pottery) {System.out.println("评估陶器的质量和历史价值。");}@Overridepublic void evaluatePainting(Painting painting) {// 陶器评估专家不评估绘画}@Overridepublic void evaluateSculpture(Sculpture sculpture) {// 陶器评估专家不评估雕塑}
}// 具体评估专家:绘画评估专家
class PaintingEvaluator implements Evaluator {@Overridepublic void evaluatePottery(Pottery pottery) {// 绘画评估专家不评估陶器}@Overridepublic void evaluatePainting(Painting painting) {System.out.println("评估绘画的艺术价值和历史意义。");}@Overridepublic void evaluateSculpture(Sculpture sculpture) {// 绘画评估专家不评估雕塑}
}// 具体评估专家:雕塑评估专家
class SculptureEvaluator implements Evaluator {@Overridepublic void evaluatePottery(Pottery pottery) {// 雕塑评估专家不评估陶器}@Overridepublic void evaluatePainting(Painting painting) {// 雕塑评估专家不评估绘画}@Overridepublic void evaluateSculpture(Sculpture sculpture) {System.out.println("评估雕塑的艺术价值和历史意义。");}
}// 评估系统
class EvaluationSystem {public static void main(String[] args) {// 创建文物Artifact[] artifacts = { new Pottery(), new Painting(), new Sculpture() };// 创建评估专家Evaluator potteryEvaluator = new PotteryEvaluator();Evaluator paintingEvaluator = new PaintingEvaluator();Evaluator sculptureEvaluator = new SculptureEvaluator();// 评估文物for (Artifact artifact : artifacts) {artifact.accept(potteryEvaluator);artifact.accept(paintingEvaluator);artifact.accept(sculptureEvaluator);}}
}

核心思想
访问者模式的核心思想是将数据结构与数据操作相分离。它通过在数据结构中添加一个接受访问者访问的方法,并将具体的数据操作封装在访问者中,实现了对数据结构的操作与数据结构本身的解耦。
具体来说,访问者模式的核心思想包括以下几点:
-
数据结构:数据结构由一组元素组成,这些元素可以是单个对象,也可以是对象的集合。数据结构通常包含一个接受访问者访问的方法,即accept(visitor)方法,通过该方法,数据结构可以接受不同的访问者来进行操作。
-
访问者:访问者是对数据结构中元素进行操作的对象。访问者包含了一系列具体的操作方法,每个方法用于处理数据结构中的不同类型的元素。通过访问者模式,可以将对数据结构的操作从数据结构中分离出来,使得可以根据需要定义不同的操作,而无需修改数据结构本身。
-
双分派机制:在访问者模式中,存在一种双分派(Double Dispatch)的机制。在调用元素对象的accept(visitor)方法时,实际执行的是访问者中与该元素对象类型匹配的方法。这种双分派机制使得可以根据元素对象和访问者的实际类型来确定执行的操作,从而实现了动态绑定。
-
适用于复杂对象结构:访问者模式适用于处理复杂的对象结构,例如组合模式中的树形结构。通过访问者模式,可以将对复杂对象结构的操作统一封装在访问者中,简化了代码的管理和维护。
总之,访问者模式的核心思想是通过在数据结构中添加接受访问者的方法,并将具体的操作封装在访问者中,实现了数据结构与数据操作的解耦,使得可以根据需要定义不同的操作,而无需修改数据结构本身。
适用场景
访问者模式通常适用于以下场景:
-
对象结构稳定,但操作算法经常变化:当对象结构相对稳定,但需要对其进行多种不同的操作时,可以考虑使用访问者模式。通过将操作封装在不同的访问者中,可以轻松地添加新的操作,而无需修改对象结构。
-
对象结构包含多种不同类型的元素:当对象结构中包含多种不同类型的元素,并且针对每种元素需要执行不同的操作时,访问者模式是一种有效的设计方式。通过在访问者中定义针对不同类型元素的操作方法,可以灵活地处理对象结构中的各种元素。
-
数据结构与操作分离:访问者模式适用于需要将数据结构与数据操作相分离的场景。通过将操作封装在访问者中,可以使得数据结构专注于自身的组织结构,而操作则由访问者来负责执行,实现了数据结构与操作的解耦。
-
对对象结构的操作需要扩展,而不希望修改对象结构本身:当需要对对象结构的操作进行扩展,但不希望修改对象结构本身时,可以考虑使用访问者模式。通过添加新的访问者来扩展操作,可以实现对对象结构的功能增强,同时保持对象结构的稳定性。
访问者模式适用于需要对对象结构中的多种元素进行不同操作,并且希望将操作与对象结构解耦的场景。它提供了一种灵活的方式来处理复杂的对象结构,并支持对操作的扩展和修改,而不影响对象结构本身。
优缺点
访问者模式(Visitor Pattern)具有如下优点和缺点:
优点:
- 增加新的操作:访问者模式可以通过增加新的访问者类来实现对已有的对象结构进行新的操作,而无需修改对象结构本身,符合开闭原则。
- 提高扩展性:访问者模式将数据结构与操作分离,使得可以在不修改已有代码的情况下,扩展对象结构的操作。
- 访问者和数据结构分离:访问者模式将具体操作封装在访问者中,使得数据结构和操作分离,符合单一职责原则和开闭原则。
- 适用于稳定的数据结构:访问者模式适用于对象结构相对稳定,但需要经常变化的操作算法的场景。
- 符合单一职责原则:访问者模式将具体元素类与访问者类分离,每个类负责自己的职责,使得系统更加清晰和易于维护。
- 支持不同的操作集:通过增加新的访问者类,可以实现不同的操作,而不需要修改原有的元素类,符合开闭原则。
- 增加新的数据结构较为容易:如果需要在系统中增加新的数据结构,只需增加新的具体元素类和对应的访问者类即可,无需修改原有代码。
缺点:
- 增加新的具体元素类和访问者类比较困难:如果需要在对象结构中添加新的元素,需要修改所有访问者类的接口,可能会导致修改量较大。当系统中具体元素类和访问者类较多,且相互之间的关系比较复杂时,增加新的类可能会导致类的数量急剧增加,维护困难。
- 破坏封装性:访问者模式会将具体元素暴露给访问者,可能会破坏对象的封装性。
- 增加了系统复杂度:访问者模式引入了访问者接口、具体访问者、对象结构等新的角色和类,可能会增加系统的复杂度和理解难度。
- 公开了元素的内部细节:为了让访问者能够访问元素的内部状态,元素类可能需要暴露一些内部细节,这与迪米特法则不太一致,增加了系统的耦合性。
总的来说,访问者模式适用于需要对对象结构中的元素进行多种不同操作,并且希望将操作与对象结构解耦的场景。它能够提高系统的扩展性和灵活性,但也会增加系统的复杂度和理解难度。因此,我们在使用访问者模式时需要权衡其优缺点,根据具体情况进行选择。
补充说明:
访问者模式与迭代器模式有一些相似之处,但它们的关注点和应用场景略有不同。
-
迭代器模式主要关注遍历和访问集合中的元素,它提供一种统一的方法来访问同类或同接口的数据集合,并隐藏了数据集合的具体实现细节。迭代器模式适用于需要顺序访问集合元素的情况,例如遍历列表、数组等。
-
而访问者模式则更加关注对不同类型的对象执行不同的操作,它允许在不修改对象结构的前提下定义新的操作。通过访问者模式,我们可以将数据结构与对数据的操作分离,实现了数据结构和操作的解耦。这使得我们可以轻松地添加新的操作,而无需修改现有的对象结构。访问者模式适用于需要对复杂对象结构进行操作并且这些操作可能随时发生变化的情况,例如编译器的语法分析、解释器的语义分析等。
迭代器模式用于遍历集合元素,而访问者模式用于对不同类型的对象执行不同的操作,可以作为拦截器(Interceptor)来拦截对对象的访问并执行相应的操作。
访问者模式是会经常用到的模式,三个扩展功能可供参考:
-
统计功能:通过访问者模式,可以轻松实现对数据的统计功能。访问者类可以针对不同的元素类实现不同的统计逻辑,例如计算总数、求平均值、查找最大值等,而具体元素类则负责提供数据。这样,系统就可以实现灵活的统计功能,而不需要修改原有的数据结构和统计逻辑。
-
多个访问者:访问者模式支持多个访问者对同一个对象结构进行访问,每个访问者可以实现不同的操作,从而实现对对象结构的多种处理。这种灵活性使得系统更加可扩展,可以根据需要随时增加新的访问者,而不会影响已有的访问逻辑。
-
拦截器:通过访问者模式实现简单的拦截器功能,可以对被拦截的对象进行检查和修改。拦截器类作为访问者类,负责访问被拦截对象,并根据需要进行检查和修改。这样,系统就可以实现灵活的拦截器功能,对数据进行有效的过滤和处理,而不需要修改原有的业务逻辑。
综上所述,访问者模式不仅可以实现基本的数据遍历和操作,还可以通过扩展实现更加丰富和复杂的功能,是一种非常灵活和强大的设计模式。
这篇关于二十四种设计模式与六大设计原则(三):【装饰模式、迭代器模式、组合模式、观察者模式、责任链模式、访问者模式】的定义、举例说明、核心思想、适用场景和优缺点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






