本文主要是介绍海量电动汽车数据无法解决?不放试试基于MonteCarlo方法的大规模电动汽车充放电模型程序代码!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
电动汽车大规模入网充电时会导致系统内负载峰值拔高的问题,和分布式电源一样,都会对电网的安全稳定运行造成冲击,需要在满足系统运行经济效益最优的同时,尽量降低大量电动汽车入网无序充电对系统造成的不良影响。通过分析电动汽车充电负荷的影响因素,针对私家车、公交车和出租车这三种类型电动汽车以及常规充电和快速充电这两种充电模式,采用MonteCarlo抽取不同类型车辆的日行驶里程和不同充电模式的开始充电时间,得到起始荷电状态,计算出充电时间长度,最后计算出充电负荷,获得充电负荷曲线,计算结果为研究电动汽车的有序充电策略提供了一定的理论依据。
程序算例丰富、注释清晰、干货满满,可扩展性和创新性很高!足以撑起一篇高水平论文!下面对程序做简要介绍!
适用平台:Matlab+Yalmip+Cplex
蒙特卡洛方法
蒙特卡洛方法(Monte Carlo method),又称统计模拟方法,是一种以概率统计论为指导的数值计算方法,由S.M,乌拉姆与J.冯·诺伊曼最先提出。蒙特卡洛方法可广泛应用于经济学、物理学、动力学、金融工程学等多种领域。
蒙特卡洛方法的理论基础源于中心极限定理与大数定律,其基本思想是通过多次随机试验,得到某随机变量或事件的概率及期望。用数学语言表述为:假设需求解的问题为Y=f(x),X=(x1,x2,x3…),其中X为服从某概率分布的随机变量,计算时无法通过解析方式得到Y=f(X)的概率统计。若采用蒙特卡洛方法即可对每个X进行抽样,代入求解出Y,通过大量计算可以得到Y的概率特征。
可知蒙特卡洛方法主要步骤如下:
(1)描述概率方程或模型:
(2)从已知概率函数实现抽样,产生满足概率分布的(伪)随机数;
(3)建立各种估计量;
电动汽车充电负荷影响因素
1)电动汽车类型
通过分析中国电动汽车发展现状,总结出我国电动汽车未来发展趋势大体为:2010~2015年,电动汽车主要为公交车、公务车和出租车;2016~2020年主要为公共交通系统、公务车,私家车较少;2021~2030年电动私家车加速发展,其比例逐年上升。
2)电池特性
电动汽车的电池目前主要有铅酸电池、镍氢电池和锂离子电池三种类型,采用的主要是恒流-恒压两阶段的充电方式,电能的补充主要来自于恒压充电阶段,在这一阶段充电功率的变化不是很明显。本程序将电动汽车电池的充电过程近似为恒功率充电。
3)电能补给方式
根据我国2010年通过的《电动汽车传导式接口》可知,充电模式分为慢速充电(充电模式L1)、常规充电(充电模式L2)和快速充电(充电模式L3),其中,L1、L2为交流充电,L3为直流充电,见表1。

4)开始充电时刻和日行驶里程
电动汽车的开始充电时刻和日行驶里程取决于用户的行驶习惯。目前,各种类型电动汽车日行驶里程缺乏实际的数据统计,因此假设电动汽车的使用不改变用户的行驶规律,以传统燃油车的行驶规律概率特性为基础。根据 NHTS统计得到电动汽车日行驶里程和充电开始时刻数据,通过Matlab工具箱进行拟合,日行驶里程的概率密度函数为
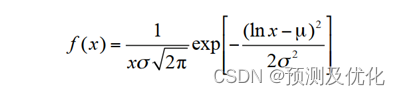
其中,各类型电动汽车日行驶里程对数正态分布参数拟合见表2。

5)充电功率概率分布
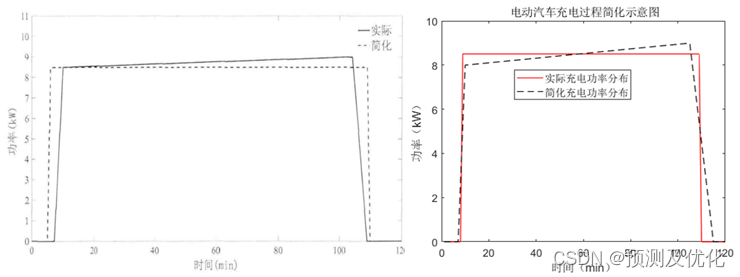
电动汽车的充电过程属于常规慢速无电,均速充电时间较长、比之下,充电行为呈现非匀速的起始充电阶段和结束阶段在整个充电过样中所占比例极低,因此在研究过程中进行简化处理,忽略起始和结束阶段对整体计的影响,在时间-功率直角坐标轴下简化为一条水平直线,电动汽车充放电过程的简化示意图和程序结果如下图所示。
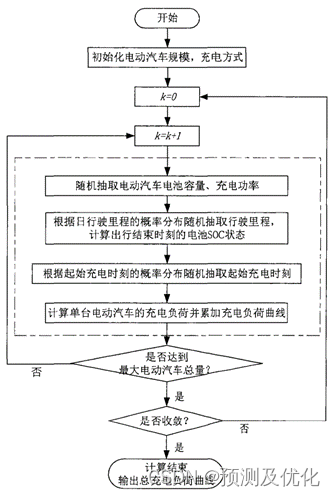
基于蒙特卡洛抽样的电动汽车充电负荷计算步骤
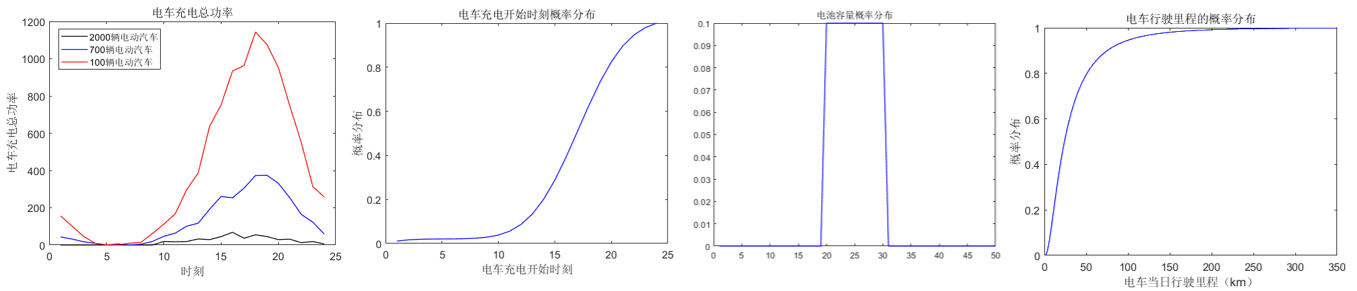
程序结果


部分程序
%按照流程图进行蒙特卡洛的电车负荷计算%先是初始化,该配电网区域的电车日出行总数
N_EV = 2000;
%利用蒙特卡洛方法生成多车行驶里程
%首先,调用函数km%生成 对数正态分布去生成日行驶里程
p_km = rand();A=find(Fs_km-p_km>0 ); KM(i) = A(1);
%根据各车的行驶里程除以7.5计算出各自所需要的充电量kwh
W = KM / 7.5;
figure(4)plot(W,'*');
%根据各车充电量,除以8.5可以得到各车所需要的充电时间。
T = W/8.5;
figure(5)plot(T,'*');
%
下面是利用蒙特卡洛法,随机生成各车充电开始时刻
% 几个步骤% 概率密度得到概率分布
% 随机生成rand()与概率分布比较,利用find得到开始时刻
% 处理24这个数值,当发现位置>= 25时,位置改为x-24,而后各个位置赋值8.5
% 最后是把700量车充电负荷累加,观察总电车负荷曲线趋势
ChargeStartTime;
%生成 对数正态分布去生成开始充电的时间
p_C = rand();B=find(Fs_C-p_C >0 ); TC(i) = B(1);
figure(8)plot(TC,'*');
%
下面将开始时刻,与充电时长-
1
叠加,得到的是未修正的充电开始结束时刻位置
TC_Start = TC;TC_End = ceil( TC + T -1 ) ;
%先给充电功率赋初值P_Charge = zeros( N_EV , 48 ) ;P_Charge_End = ( T - floor( T) )*8.5 ; %最后一个时刻的功率比8.5小
P_Charge(i,TC_Start(i): TC_End(i)-1 ) = 8.5;
P_Charge(i, TC_End(i) ) = P_Charge_End(i); 部分内容源自网络,侵权联系删除!
欢迎感兴趣的小伙伴关注并私信获取完整版代码,小编会不定期更新高质量的学习资料、文章和程序代码,为您的科研加油助力!
这篇关于海量电动汽车数据无法解决?不放试试基于MonteCarlo方法的大规模电动汽车充放电模型程序代码!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




