海量专题

三.海量数据实时分析-FlinkCDC实现Mysql数据同步到Doris
FlinkCDC 同步Mysql到Doris 参考:https://nightlies.apache.org/flink/flink-cdc-docs-release-3.0/zh/docs/get-started/quickstart/mysql-to-doris/ 1.安装Flink 下载 Flink 1.18.0,下载后把压缩包上传到服务器,使用tar -zxvf flink-xxx-

免费赠与c/c++海量视频 学习资料的
如果有需要 c/c++海量视频 学习资料的 可以试试以下方法(和朋友自己业余搞的公众号,目前处于推广时期): 微信关注 “金喜鹊论文发表” 账号, 公众号中也有c/c++视频 ,大家也可以 输入 程序 或者 资料, 即可获取 海量的c/c++资料。 关注后,输入 2013 , 之后就会回复 visual studio 2013 安装软件

【加密社】比特币海量数据问题解决方案
加密社 比特币是无敌的存在,刚翻了一遍中本聪的论文(其实以前看过一次,那时不明觉厉),发现咱们一直在考虑的问题,基本都能在其论文上找到解决方案了。。 现在出现的这些问题,完全是因为bitcoin-qt、bitcoind的实现有问题,根据其设计思想,完全是可以解决的。 (比如可以二次开发一些轻量级的神器来辅助的。) 现阶段,主要发现的问题有: 1. 庞大的数据库问题。 2. 未来单位时

批量修改海量cad文件名——vba实现
如果需要修改大量dwg文件名,可将dwg文件放入一个文件夹,采用此dvb插件加载到cad ,输入 vbaman加载插件,输入vbarun运行插件,根据提示选择文件夹,即可一键完成海量文件名的自动复制修改。具体需求可专门代写代码、插件。 部分代码如下: Sub 批量dwg改名() 'yngqq Dim folderPath As String Dim counter As In

二.海量数据实时分析-Doris数据表设计
前言 Apache Doris 支持标准 SQL 语法,采用 MySQL 网络连接协议,高度兼容 MySQL 相关生态。因此,在数据类型支持方面,尽可能对齐 MySQL 相关数据类型。 数据表设计 1.数据类型 Apache Doris 支持的数据类型比较丰富,完整的类型可以通过官网(https://doris.incubator.apache.org/zh-CN/docs/table-d

【C++杂货铺】海量数据处理(位图、布隆过滤器)
目录 🌈前言🌈 📁 位图 📂 概念 📂 模拟实现 📂 C++中位图 📂 位图的优缺点 📁 布隆过滤器 📂 概念 📂 模拟实现 📂 应用场景 📁 海量数据处理 📁 总结 🌈前言🌈 本期【C++杂货铺】,将介绍关于哈希表的扩展内容,即位图和布隆过滤器,以及如何通过位图和布隆过滤器解决海量数据处理问题。

在Redis里,如何从海量key中查询出某一个固定前缀所有的key?
在Redis里,如何从海量key中查询出某一个固定前缀所有的key? 在Redis里,如何从海量key中查询出某一个固定前缀所有的key? 答:如果该机器是生产环境正在对外提供服务,不建议使用keys * pattern的方法进行查询,可能会使服务器卡顿,而出现事故。 一般生产服务器建议使用Scan命令,例如: SCAN 0 MATCH aaa* COUNT
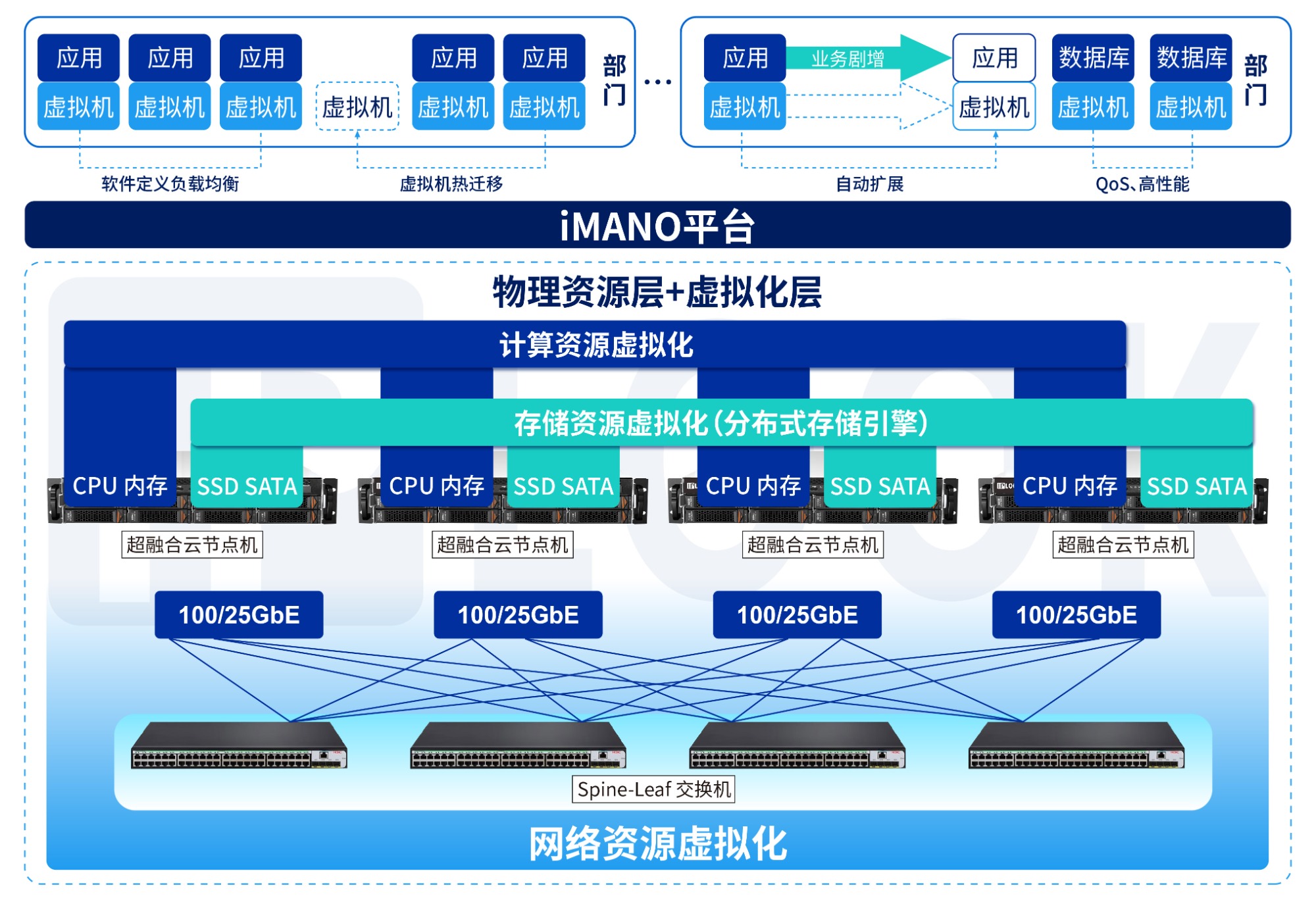
爱浦路云化核心网:支持百万用户规模,构筑超快海量连接网络
广州爱浦路网络技术有限公司(简称:IPLOOK)是全球领先的4G/5G/6G核心网厂商,致力于向全球客户提供端到端的移动通信解决方案,其产品和服务覆盖了卫星通信、能源通信、电网通信等多个重要领域。经过十二年的探索与发展,IPLOOK的核心网产品已在50多个国家和地区实现规模化商用,具备丰富的商业网络部署经验。 IPLOOK专注自研,融合尖端技术 IPLOOK研发团队具有多年的技术积累和现网
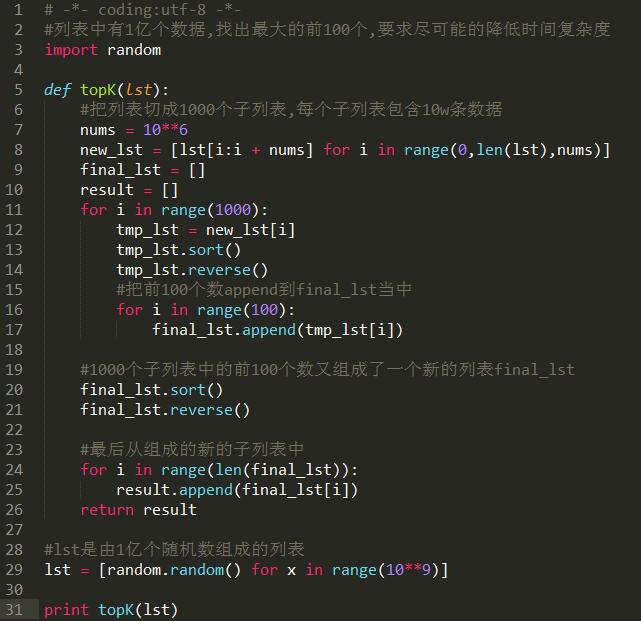
海量数据取top K问题
一个列表中有1亿个数据,需要取出其中最大的前100个数据,如何尽可能的降低时间复杂度? 最容易想到的方法是先对这1亿个数据排序,然后取出最大的100个数据,这样的话时间复杂度就是O(nlogn),显然方法不合适。 可以考虑的方法如下: 1.把这个列表截取成1000个子列表; 2.然后分别找出这1000个子列表中的最大的100个数据; 3.把这1000个子列表中的100个数据全部放到一个新
视频单条剪、脚本靠手写?云微客开启海量视频时代
老板们注意了,现在已不再是视频单条剪,脚本靠手写的时代!在这个信息爆炸的时代,短视频已经成为了现代信息传播和娱乐消费的重要载体,那么我们该如何高效、快速地制作出大量高质量的短视频内容呢?这就需要云微客AI智能剪辑系统,通过强大的批量混剪功能为企业或个人开启海量视频剪辑的时代。 很多企业进军短视频赛道,都会面临着这些问题:不知道拍什么?没有短视频经验?视频制作效率低?运营团队太烧钱等等。随

【MySQL进阶之路】为什么索引能快速的在海量数据中查找
目录 引言 认识磁盘 磁盘的寻址 磁盘的抽象化理解 系统IO交互的基本单位 MySQL 与磁盘交互基本单位 理解Page方案 数据结构组织数据 单个page 多个page 大量数据 不同的数据类型 为什么不采用其他数据结构 B树和B+树的区别 聚簇索引 VS 非聚簇索引 🤗个人主页:东洛的克莱斯韦克-CSDN博客 基础约束查询示例MySQL基础

交易中台架构设计:海量并发高扩展,新业务秒级接入
今天将从以下这三方面,来分享一些海量高并发的经验: 中台模式和微服务架构到底有什么样的关系 海量并发的业务中台架构如何设计与实践 秒级新业务接入的交易中台如何设计和实践 一、中台模式与微服务架构的关系 现在大家应该都知道,中台最早是由芬兰一家著名的游戏公司Supercell提出的,以小前台的模式来组织若干个开发团队。 也就是说,你的每个前台的开发团队,只需要

(分析篇章)从海量信息中脱颖而出:Workflow智能分析解决方案,大语言模型为AI科技文章打造精准摘要评分体系
从海量信息中脱颖而出:Workflow智能分析解决方案,大语言模型为AI科技文章打造精准摘要评分体系(分析篇章) 流程说明: 分析流程的输入同样是网站的文章ID。借助Workflow内置的HTTP调用节点和代码节点,我们能够方便地调用网站的API,从而获取到文章的元数据(涵盖标题、来源、链接、语言等信息)以及全文内容。为了确保不遗漏文章中的任何关键信息,分析流程首先会判断文章的长度。如果文

位图与布隆过滤器 —— 海量数据处理
🌈 个人主页:Zfox_ 🔥 系列专栏:C++从入门到精通 目录 🚀 位图 一: 🔥 位图概念 二: 🔥 位图的实现思路及代码实现三: 🔥 位图的应用四: 🔥 STL中的 bitset 🚀 布隆过滤器 一: 🔥 布隆过滤器提出 二: 🔥 布隆过滤器概念 三: 🔥 布隆过滤器的误判率推导四: 🔥 布隆过滤器的实现五: 🔥 布隆过滤器的删除六: 🔥 布
算法10—海量数据处理之top k算法
第一部分:Top K 算法详解 问题描述 百度面试题: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
海量数据处理经典思想
第一部分、十五道海量数据处理 1. 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url? 方案1:可以估计每个文件安的大小为50G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。 遍历文件a,对每个url求取,然后根据所取得的值将url分别存储到1000个小文件(
App推广告别邀请码,Xinstall助您一键触达海量用户!
在移动互联网高速发展的今天,App的推广与运营已成为每个开发者都必须面对的问题。然而,随着互联网流量的日益分散和用户需求的不断变化,传统的App推广方式已经难以满足现代市场的需求。尤其是在获取用户时,很多开发者还在采用传统的邀请码模式,这不仅增加了用户的操作难度,也限制了App的推广范围。那么,如何在这个竞争激烈的市场中脱颖而出呢?今天,我们要为您介绍的是——Xinstall,一个无需邀请码,即可

数据加密两大政企实践案例 | 麒麟信安护航海量核心数据安全无虞
数据作为数字经济时代的关键生产要素,是推动经济高质量发展的重要引擎。但随着数据产生、流转、应用过程日益复杂化,关键数据随意篡改、网络攻击层出不穷、核心技术严重泄密等数据安全问题逐渐暴露。同时,国家正大力推进“商用密码改造”工作,在此趋势下,越来越多的行业用户意识到,全面保障核心敏感信息安全是当下迫切且艰巨的任务。 麒麟信安以用户需求为导向,深入了解各类行业及具体业务场景,近来为某区政府、中国烟

1688商品详情API:一键解锁海量批发数据
引言 1688作为阿里巴巴旗下的B2B交易平台,拥有庞大的商品数据库和丰富的供应商资源。对于想要获取商品详细信息的开发者和企业而言,1688提供的API接口是获取一手数据的关键途径。本文将详细介绍如何使用1688商品详情API,包括注册、获取API密钥、构造请求以及处理响应数据。 正文 1. 注册并获取API凭证 第一步:访问开放平台官网,注册账号。第二步:创建应用项目,获取App
引领潮流!Xinstall创新技术让App免填邀请码成为可能,轻松吸引海量用户!
在快速变化的互联网环境下,App推广和运营面临着诸多挑战。如何迅速搭建起满足用户需求的运营体系,提高获客转化的效率和用户留存,成为了众多企业急待解决的问题。而邀请码作为App推广中常见的手段,其繁琐的填写过程常常让用户望而却步,导致推广效果不佳。 然而,现在有了Xinstall这一创新品牌,这些问题将迎刃而解!Xinstall凭借其独特的技术优势,推出了免填邀请码功能,让App推广变得更加轻松
TDengine 签约天合富家,支持百万电站海量数据管理
在全球能源转型和数字化浪潮的双重推动下,天合富家能源股份有限公司凭借其领先的分布式光伏技术和系统解决方案,在分布式能源市场中稳居领先地位。在持续创新的道路上,其面临的一个主要挑战是如何高效处理来自全国各地百万电站的海量数据。 在早期阶段,天合富家使用 MySQL 处理其数据需求,随着业务的快速增长,他们发现需要一种更高效的解决方案来应对数据量的激增。尽管后来转向使用 MongoDB,但很快发现在

超级底层:10WQPS/PB级海量存储HBase/RocksDB,底层LSM结构是什么?
一次穿透:10WQPS/PB级海量存储HBase/RocksDB的底层LSM结构 LSM tree 是很多数据库内部的核心数据结构,包括BigTable,ClickHouse、Cassandra, Scylla, RocksDB,HBase。 ClickHouse基于Log-Structured Merge-Tree 结构(思想),实现磁盘的顺序写入,和数据的预排序。 Cassandra 是
分布式系统如何做到海量数据边云协同?看 TDengine 油气领域解决方案
在某大型油田生产管理方案中,用户需要实现生产现场的自动化采集与控制、生产视频系统、工业物联网、生产数据服务、智能化生产管控应用以及各个环节的信息化采集标准建设等内容。在 TDengine 的帮助下,该大型项目成功完成了技术优化升级。本篇文章将就本次优化工作进行进一步的分析解读,给到大家参考。 TDengine 应用历程 这个项目此前的应用系统主要采用 Oracle 来存储和处理时序数据,但随着

入侵检测 - 海量告警筛选
20210316 - (本人非专业人士,请谨慎参考文章内容) 0. 引言 在之前的文章中,谈到过为了进行降低告警的数量,通过告警关联的方法,将告警日志降低;关于这部分内容,一直只是知道需求,但对于具体的技术不是很理解,通过搜索关键词,在谷歌学术上找不到太多的相关内容,有的也是一些利用频繁项挖掘的方法。(可能是我搜索的关键词不对,我觉得这部分应该是一个非常重要的方向) 从这部分来说,能够有研究

哪里有海量的短视频素材,以及短视频制作教程?
在当下,短视频已成为最火爆的内容形式之一,尤其是在抖音上。但很多创作者都面临一个问题:视频素材从哪里来?怎么拍摄才能吸引更多观众?别担心,今天我将为大家推荐几个宝藏网站,确保你素材多到用不完,还有各种教程教你如何拍摄高质量的视频。 蛙学府 首先介绍一下蛙学府,这是一个宝藏网站,提供各种无水印高清素材。无论是情感励志、解压助眠、美食、影视MV,还是健康养生等30多个分类,你都能在蛙学府找到合