本文主要是介绍PredRNN: Recurrent Neural Networks for Predictive Learning using Spatiotemporal LSTMs,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是一篇2017年发表在顶级期刊NIPS上的文章,作者通过发现传统RNN/LSTM网络的不足,提出了一种新的网络结构PredRNN,并且为这一网络结构设计了一种新的RNN单元(ST-LSTM)。由于博主能力有限,通过阅读原文短时间能只是领悟到PredRNN这一网络结构的思想,而并未对ST-LSTM的设计灵感有更深的体会。
下面这篇博文主要是来介绍一下什么是PredRNN,以及通过作者的设计思路能带给我们的思考是什么。首先简单的说一下这篇文章的目的:这篇文章所要解决的问题同之前一篇博文所介绍的论文 Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting 一样,都是通过对历史序列数据的训练学习来预测来下一时刻的结果,并且这类数据都是类“图片”形式的,也就是二维且多通道。例如前面说的降雨量预测模型(ConvLSTM),交通流量预测模型(DeepST)等都符合预测具有这类特征的数据。下面就是论文的大致内容:
1.对当前现有方法的总结
在论文中,作者首先对现有该领域的一些方法做了总结,并将之大体分为两类:
The RNN-based architectures: their predicted images tend to blur due to a loss of fine-grained visual appearances
The CNN-based architectures: prone to focus on spatial appearances and relatively weak in capturing long-term motions.
作者指出,基于RNN结构的缺点在于丢失了空间上的信息;基于CNN的结构则着重于空间上的特征而丢失了时间维度上的信息。但知晓ConvLSTM的朋友可能会问,那为什么不用ConvLSTM呢?而这就要从RNN/LSTM网络结构上的根源说起。虽然这篇论文有两个创新点:PredRNN网络结构和新的RNN单元ST-LSTM,但是在我自己看来最为重要的还是PredRNN这一网络结构的思想。同时,既然作者提出了PredRNN这一网络结构,那显然就是按照作者的意图,传统的结构丢失了某些东西,因而提出了新的网络结构。
2.PredRNN
以作者论文中所列举的4层ConvLSTM为例(图p0087),按照作者的观点这种结构的缺陷在于层与层之间是独立的,其忽略了顶层单元对底层单元的影响。
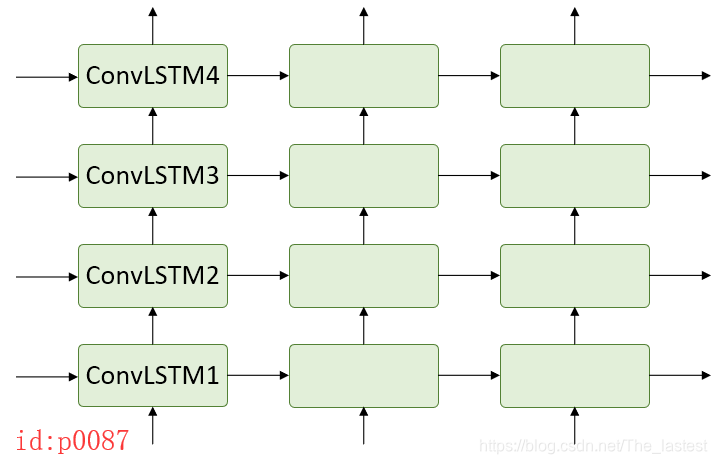
In this process, spatial representations are encoded layer-by-layer, with hidden states being delivered from bottom to top. However, the memory cells that belong to these four layers are mutually independent and updated merely in time domain. Under these circumstances, the bottom layer would totally ignore what had been memorized by the top layer at the previous time step.
也就是说,传统的多层RNN网络之间的连接方式忽略了 t 时刻顶层cell对 t+1 时刻底层cell的影响,并且在作者看来这种影响的作用是非常大的。那怎么办呢?于是乎作者就设计出了PredRNN这一网络结构(如图p0088).
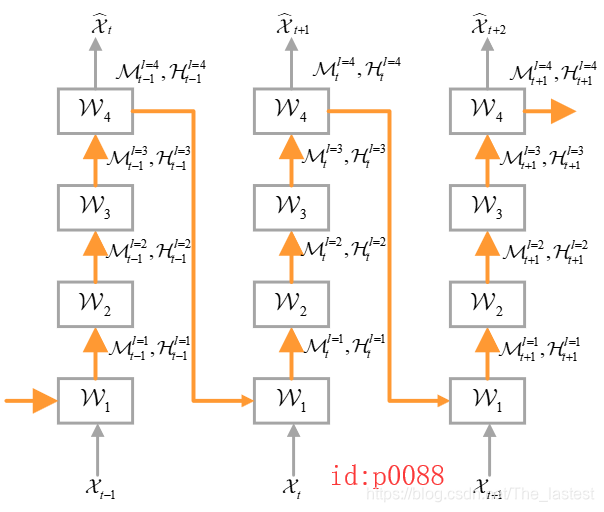
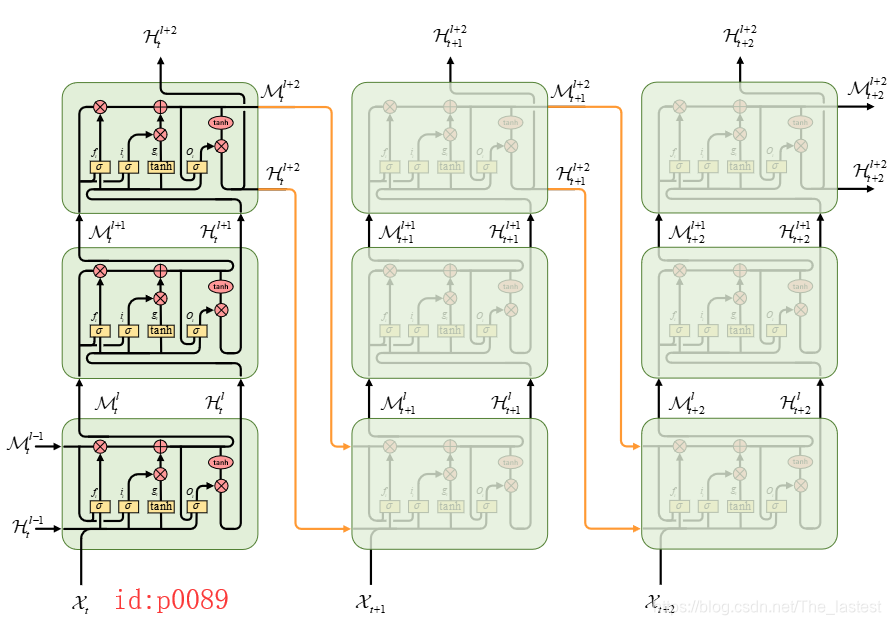
图中的橙色箭头作者称之为"Spatiotemporal memory flow",这种连接方式就解决了前面所提到的问题。下图(p0089)是一个更直观的在ConvLSTM上以PredRNN连接方式的网络。
3.ST-LSTM
作者为了使得这种网络结构能够发挥出更好的效果,又重新设计了一种新的RNN单元,作者称之为"Spatiotemporal LSTM(ST-LSTM)"。至于作者提出ST-LSTM的原因我们放到后面再总结。
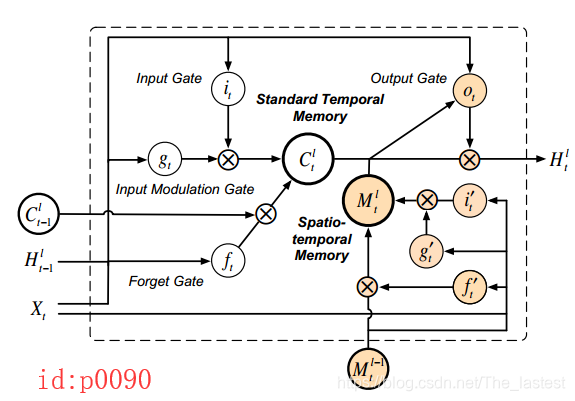
如图p0090就是ST-LSTM的结构图,为了便于理解我画成了如下形式(p0091)
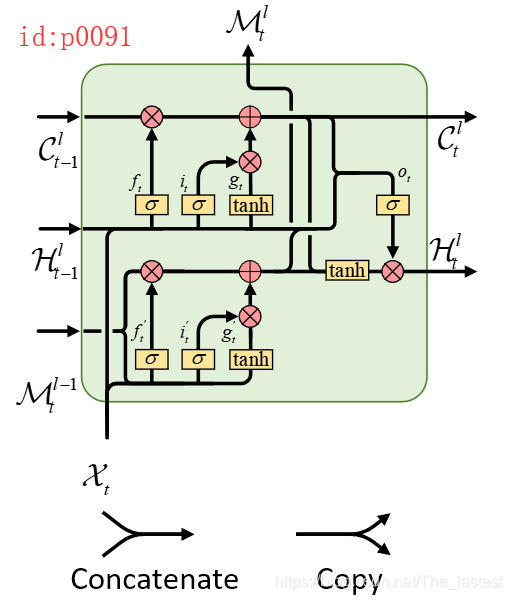
可以发现,其总体的连接结构为两个LSTM的组合,且通过 M \mathcal{M} M来作为Spatiotemporal memory flow。同时,作者将图p0091中的上半部分称为’Standard Temporal Memory’,下半部分称为’Spatiotemporal Memory’。具体的计算公式如下:
g t = t a n h ( W g ∗ [ X t , H t − 1 l ] + b g ) i t = σ ( W i ∗ [ X t , H t − 1 l ] + b i ) f t = σ ( W f ∗ [ X t , H t − 1 l ] + b f ) C t l = f t ⊙ C t − 1 l + i t ⊙ g t g t ′ = tanh ( W g ′ ∗ [ X t , M t l − 1 ] + b g ′ ) i t ′ = σ ( W i ′ ∗ [ X t , M t l − 1 ] + b i ′ ) f t ′ = σ ( W i ′ ∗ [ X t , M t l − 1 ] + b f ′ ) M t l = f t ′ ⊙ M t l − 1 + i t ′
这篇关于PredRNN: Recurrent Neural Networks for Predictive Learning using Spatiotemporal LSTMs的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







