本文主要是介绍【YOLOV5 入门】——detect.py简单解析模型检测基于torch.hub的检测方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:笔记是毕设时根据B站博主视频学习时自己编写,请勿随意转载!
一、打开detect.py(文件解析)
打开上节桌面创建的yolov5-7.0文件夹里的detect.py文件(up主使用的是VScode,我这里使用pycharm)

YOLOv5中的detect.py文件是用于执行目标检测任务的主要脚本文件。一般来说,detect.py文件包含以下几个主要部分(代码只截取部分):
-
导入库和依赖项:包括导入PyTorch库、其他必要的Python库以及YOLOv5相关的自定义库和模块。
-
import argparse #用于解析命令行参数的模块 import os #用于与操作系统交互的模块 import platform #用于获取操作系统平台信息的模块 import sys #用于访问Python解释器相关信息的模块 from pathlib import Path #用于处理文件路径的模块中的Path类import torch #PyTorch库#常量和全局变量的定义,包括FILE、ROOT、以及一些默认参数。 FILE = Path(__file__).resolve() ROOT = FILE.parents[0] # YOLOv5 root directory if str(ROOT) not in sys.path:sys.path.append(str(ROOT)) # add ROOT to PATH ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relativefrom models.common import DetectMultiBackend ... -
定义运行函数(加载模型:加载预训练的YOLOv5模型,通常是通过
torch.load()函数加载预训练权重文件。图像预处理:对输入图像进行预处理,例如调整大小、归一化、转换为张量等操作。执行检测:利用加载的模型对预处理后的图像进行目标检测,通常是通过调用模型的前向传播方法来实现。后处理:对检测结果进行后处理,包括解析预测结果、筛选置信度较低的检测框、进行非极大值抑制(NMS)等操作。可视化结果:将检测结果可视化并保存到指定的输出目录中,通常包括绘制检测框、标签、置信度等信息。结果输出:将处理后的结果输出到文件或者打印到控制台,通常包括检测到的目标类别、位置信息以及置信度等。) -
@smart_inference_mode() def run(weights=ROOT / 'yolov5s.pt', # model path or triton URLsource=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)data=ROOT / 'data/coco128.yaml', # dataset.yaml pathimgsz=(640, 640), # inference size (height, width)conf_thres=0.25, # confidence thresholdiou_thres=0.45, # NMS IOU threshold ...# Directories处理输入参数和设置运行环境,如模型路径、数据路径、设备选择、保存路径等save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run ...# Load model加载模型,并根据输入图像大小进行适当调整device = select_device(device)model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half) ...# Dataloader加载数据,支持从文件、目录、URL以及摄像头等多种数据源bs = 1 # batch_sizeif webcam:view_img = check_imshow(warn=True) ...# Run inference执行目标检测,包括图像预处理、模型推理、后处理(非极大值抑制、结果解析等)等操作。model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup ...# Inference模型推理 ...# NMS非极大值抑制 ...# Process predictions每张图像的检测结果进行可视化,并根据参数选择是否保存结果 ...# Print results输出检测结果和性能统计信息 ... -
解析命令行参数函数,就是在terminal终端指定参数进行解析
def parse_opt():parser = argparse.ArgumentParser()parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image') ... -
主函数
#主函数用于检查环境要求并调用run函数执行目标检测任务
def main(opt):check_requirements(exclude=('tensorboard', 'thop'))run(**vars(opt))- 辅助函数
"""
最后这段代码是Python中的一个常用的惯用法,
这样设计的好处是,在将脚本作为主程序直接执行时,会执行主要的逻辑;
而当将脚本作为模块导入到其他程序中时,不会执行主要逻辑,
而是只导入函数和类等定义,以供其他程序使用。
"""
if __name__ == "__main__": #判断当前模块是否是作为主程序直接执行的opt = parse_opt() #首先调用parse_opt()函数解析命令行参数,并将解析后的参数保存到变量opt中main(opt) #将解析后的参数opt作为参数传递给main函数,执行主要的目标检测任务逻辑二、指定关键参数(模型检测)
detect.py文件最上面的注释中有关键参数的可选值以及意义说明
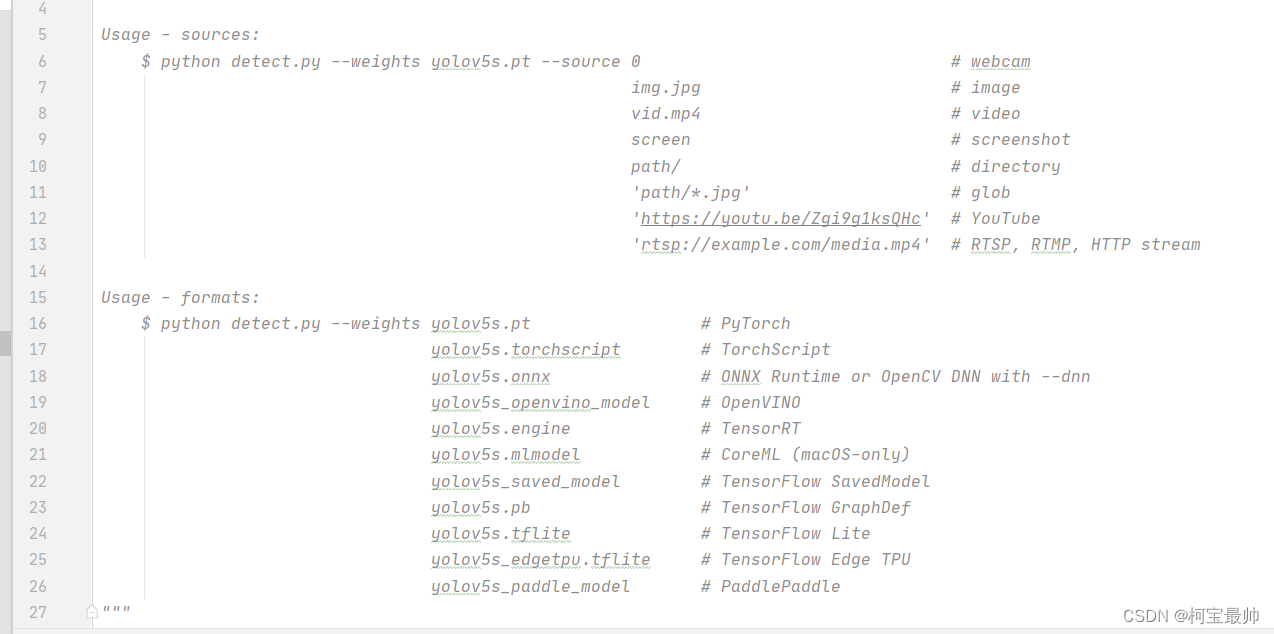
1、weights:训练好的模型文件
YOLOv5官方网站有各种模型,可以选择使用。这里使用yolov5-7.0文件夹自带的yolov5s.pt模型文件。终端输入以下命令(注意先激活环境):
python detect.py --weights yolov5s.pt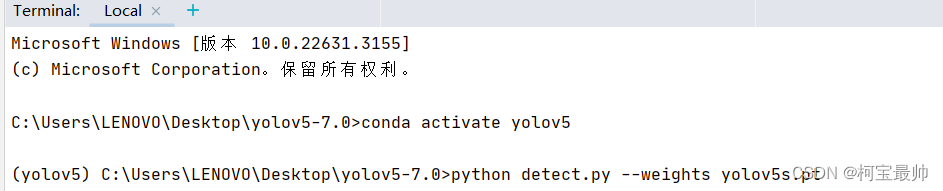
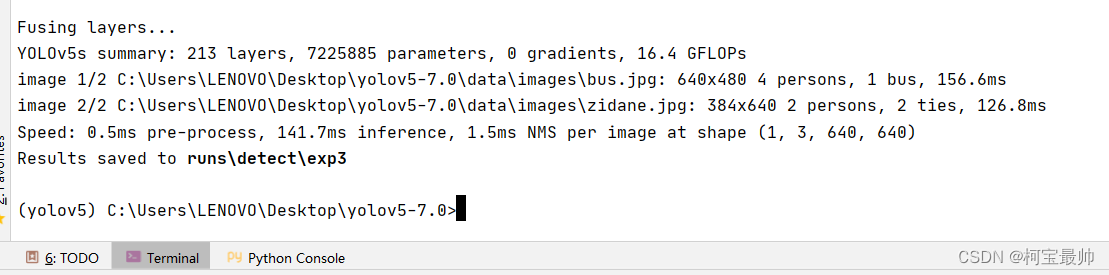
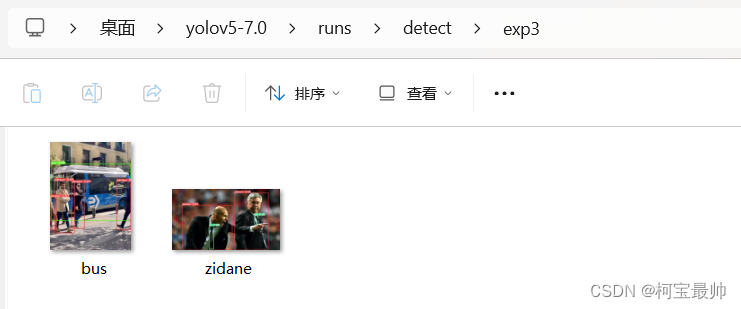
推理完成,第一张图检测出4个人,1辆车,第2张图检测出2个人,2个领带(还是模型自带的data\images里的两张图片),保存路径再run\detect\exp3
也可以在官网下载其他weights模型文件:
- yolov5l.pt
- yolov5x.pt
- yolov5n.pt
- yolov5m.pt等
2、source:指定检测的目标
可以是单张图片、文件夹、屏幕或者摄像头。(在上面没指定sources默认执行检测data\images自带的那两个图片)
①对图片进行检测(代码最后一段是图片路径data\images里的bus)
python detect.py --weights yolov5s.pt --source data/images/bus.jpg

②对屏幕检测
python detect.py --weights yolov5s.pt --source screen
3、conf-thres:置信度阈值
越高要求越严,最后的框越少;越低要求越低,框越多。下面是设定不同置信度阈值的结果:
python detect.py --weights yolov5s.pt --conf-thres 0.85
python detect.py --weights yolov5s.pt --conf-thres 0.65
python detect.py --weights yolov5s.pt --conf-thres 0.25

4、iou-thres:IOU阈值
可以理解为与conf-thres相反,越低框越少,越高框越多。此处不做赘述。
5、其他

--max-det 指定最大的检测数量;--device指定设备;--view-img检测完可以弹出检测结果,其他的可以自行查找或者询问GPT。
三、基于torch.hub的检测方法
1、简介
基于torch.hub的检测方法是一种利用PyTorch Hub的功能来进行目标检测任务的方法。
PyTorch Hub是PyTorch官方提供的一个模型库和预训练模型资源平台,它提供了许多经过预训练的深度学习模型,包括图像分类、目标检测、语义分割等任务的模型。
在进行目标检测时,可以通过torch.hub.load()函数来加载PyTorch Hub中提供的目标检测模型,然后利用加载的模型进行目标检测任务。通常,PyTorch Hub中提供的目标检测模型会在标准数据集上进行了预训练,例如COCO数据集,因此这些模型通常具有较好的检测性能。
2、实操
该detect.py文件的内容太多,到后续的可视化界面设计等章节时会造成不便,这里可以尝试基于torch.hub的检测方法,只需要几行代码。
import torch#Model ,第一个参数是模型所在文件夹
model= torch.hub.load("./", "yolov5s", source = "local")#Images对象路径
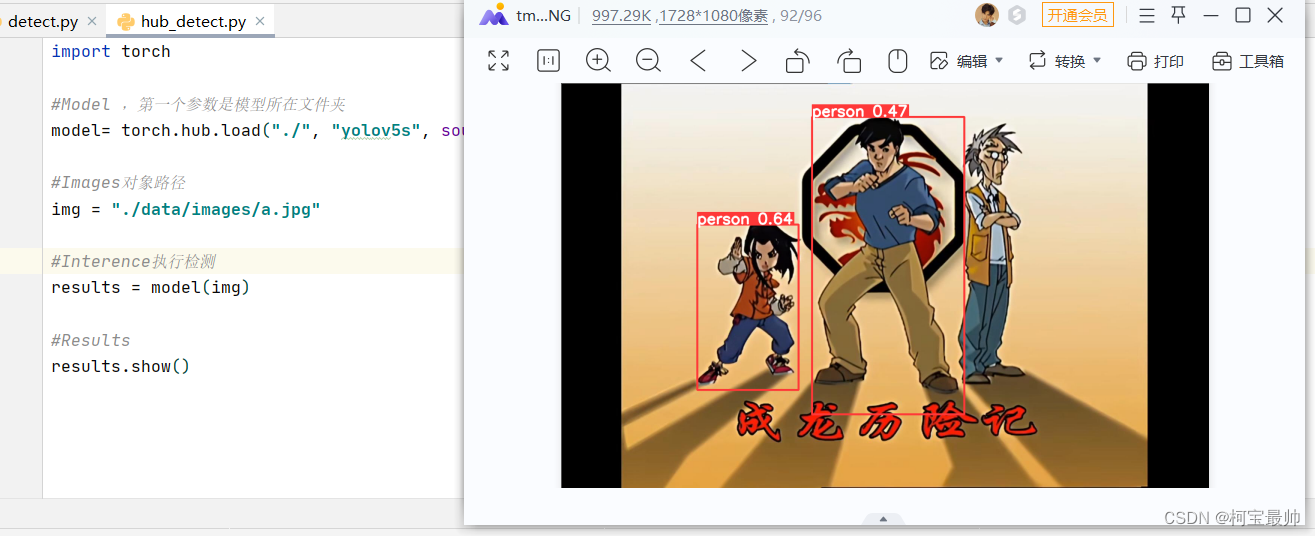
img = "./data/images/zidane.jpg"#Interence执行检测
results = model(img)#Results
results.show()这里出现了一个问题,直接右键点击“运行”弹出找不到torch(似乎不在环境内),只能在下面的“terminal”终端,激活yolov5环境后用命令运行:
conda activate yolov5
python hub_detect.py![]()
调查设置的项目解释器后发现似乎之前的torch、pillow包都安装在了之前我学习ML时安装的python3.6的环境,而新安装的miniconda环境里却没有,这个怎么回事??但是无论解释器配置为python3.6还是miniconda环境,都能在虚拟环境的终端运行,这个会影响后续吗??

结果如下:
3、用Jupyter运行
也可使用jupyter运行(观察结果更方便):
pip install jupyterlab
使用国内镜像安装的时候要把翻Q软件关了!
然后在根目录下新建一个hub_detect.ipynb的文件:

运行时报错说环境未安装jupyter package,似乎是我装的python环境太多这里没选定造成,这里添加下新安装的conda环境(没问题的可以跳过):
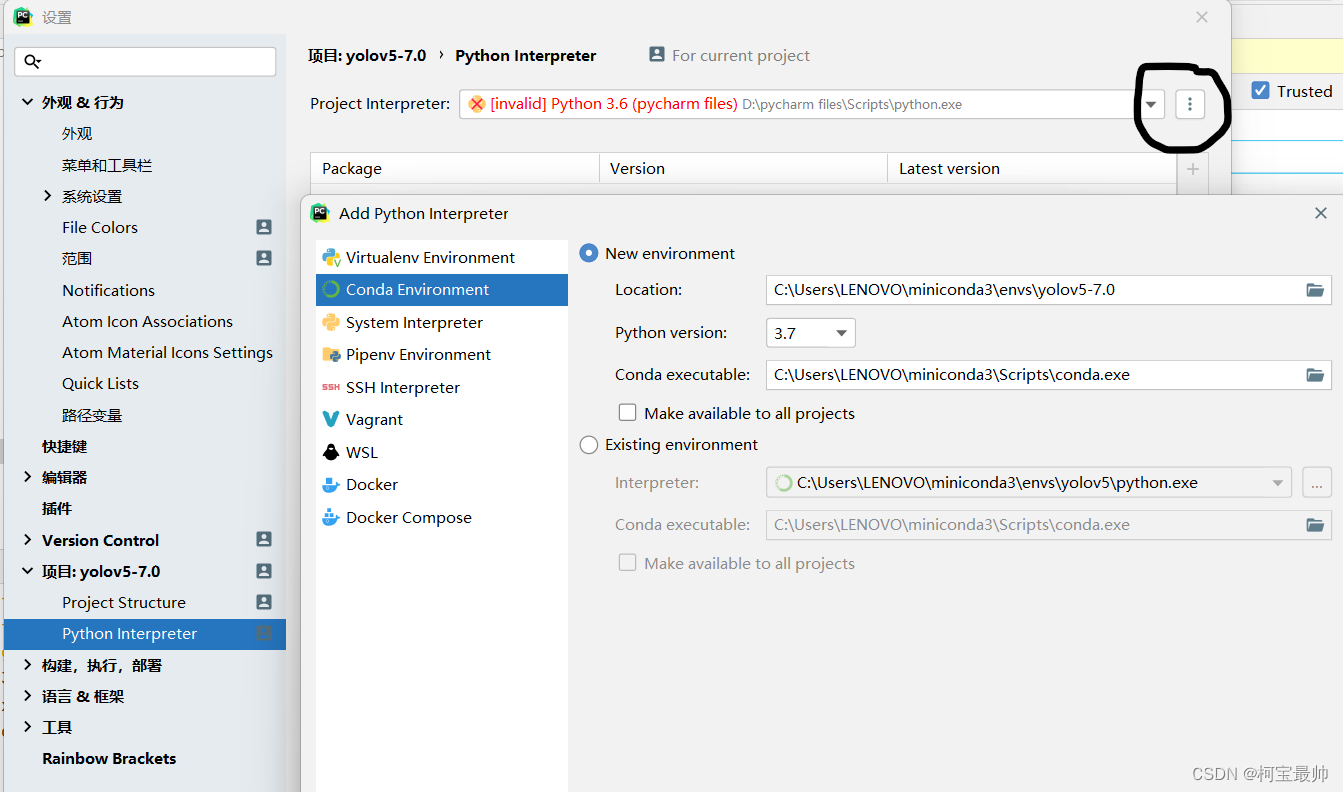
然后点击提示install jupyter package

这里安装太慢不做演示,最后运行也可以成功。
虽说hub_detec方法的检测参数没有原来的detect.py文件丰富,但十分利于后续的封装!!
四、拓展
有时候一些知识简单拓展下,日积月累就可对这个领域了解更深刻!
1、torch.hub.load()其他参数
torch.hub.load()函数还有一个常用参数pretrained。pretrained=True是torch.hub.load()函数的一个参数,用于指示是否加载预训练的模型权重。
- 当
pretrained=True时,torch.hub.load()函数会从指定的模型文件夹中加载预训练的权重,这些权重通常是在大规模数据集上进行训练得到的,并具有一定的泛化能力。加载预训练权重的模型通常可以直接用于实际任务中,而不需要再进行额外的训练。 当pretrained=False或者不指定这个参数,torch.hub.load()函数将加载模型的结构定义文件,但不会加载预训练的权重。这样加载的模型是一个随机初始化的模型,需要用户自行进行训练,或者使用迁移学习等方法进行参数微调,才能适应具体的任务。
其他参数了解:

2、YOLO和Mask R-CNN对比
YOLO(You Only Look Once)和Mask R-CNN都是用于目标检测的流行算法,但它们在设计理念和算法结构上有很大的不同。以下是它们之间的关系和区别:
关系:
-
目标检测任务:YOLO和Mask R-CNN都是用于解决目标检测任务的,即在图像中检测并定位图像中的目标对象。
-
深度学习框架:两者都是基于深度学习技术实现的,可以使用主流的深度学习框架(如TensorFlow、PyTorch)进行实现。
区别:
-
检测方式:
- YOLO:采用单阶段(One-Stage)检测方法,将目标检测任务视为回归问题,直接通过卷积神经网络输出目标的位置和类别信息。
- Mask R-CNN:采用两阶段(Two-Stage)检测方法,首先利用区域建议网络(Region Proposal Network,RPN)生成候选区域,然后对候选区域进行分类和边界框回归,同时还可以生成目标的分割掩码。
-
输出信息:
- YOLO:输出每个检测框的边界框位置和置信度以及对应的类别信息。
- Mask R-CNN:除了输出边界框位置和类别信息外,还额外输出了目标的分割掩码信息。
-
精度和速度:
- YOLO:因为采用单阶段检测方法,YOLO在速度上通常比较快,但相对精度可能稍逊于两阶段方法。
- Mask R-CNN:虽然在精度上可能更优,但由于采用两阶段检测方法,速度通常会较慢。
-
应用场景:
- YOLO:由于速度快且适合实时应用,常被用于需要快速检测的应用场景,如自动驾驶、视频监控等。
- Mask R-CNN:由于精度较高,常被用于需要精确目标检测和分割的场景,如医学图像分析、遥感图像分析等。
综上所述,YOLO和Mask R-CNN在目标检测任务中有着不同的设计理念和算法结构,适用于不同的应用场景和需求。选择合适的算法取决于具体的任务要求和性能指标。
往期精彩
STM32专栏(付费9.9)![]() http://t.csdnimg.cn/E2F88
http://t.csdnimg.cn/E2F88
OpenCV-Python专栏(付费9.9)![]() http://t.csdnimg.cn/zK1jV
http://t.csdnimg.cn/zK1jV
AI底层逻辑专栏(付费9.9)![]() http://t.csdnimg.cn/zic0f
http://t.csdnimg.cn/zic0f
机器学习专栏(免费)![]() http://t.csdnimg.cn/FaXzAFreeRTOS专栏(免费)
http://t.csdnimg.cn/FaXzAFreeRTOS专栏(免费)![]() http://t.csdnimg.cn/SjIqU电机控制专栏(免费)
http://t.csdnimg.cn/SjIqU电机控制专栏(免费)![]() http://t.csdnimg.cn/FNWM7
http://t.csdnimg.cn/FNWM7
这篇关于【YOLOV5 入门】——detect.py简单解析模型检测基于torch.hub的检测方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







