本文主要是介绍[论文精读]A dynamic graph convolutional neural network framework reveals new insights into connectome,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文全名:A dynamic graph convolutional neural network framework reveals new insights into connectome dysfunctions in ADHD
论文网址:A dynamic graph convolutional neural network framework reveals new insights into connectome dysfunctions in ADHD - ScienceDirect
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用!
目录
1. 省流版
1.1. 心得
1.2. 论文总结图
2. 论文逐段精读
2.1. Abstract
2.2. Introduction
2.3. Methods
2.3.1. Data acquisition and preprocessing
2.3.2. Proposed approach
2.4. Results
2.4.1. Experimental comparison
2.4.2. Ablation study
2.4.3. Interpretation of ADHD diagnostic biomarkers
2.5. Discussion
2.5.1. Advantages of dGCN in brain network analysis
2.5.2. Limitations and future work
2.6. Conclusions
3. 知识补充
3.1. Etiology and Pathology
3.2. Isolation forest
4. Reference List
1. 省流版
1.1. 心得
(1)提到subject-level graph的时候说节点特征可以是灰质体积、表面积或ROI时间序列,边特征是两个节点的皮尔逊相关
(2)我感觉我有点不知道它动态在哪里?它说GCN和GAT是1-hop,然后它是筛选性2-hop就是动态了吗
(3)⭐“保留32个成对距离在动态图卷积聚合函数中构建邻接矩阵”和“Pearson 相关系数的前 20% 被保留为邻接矩阵”是什么玩意儿?是同一个东西吗?我没看到有俩邻接矩阵啊?但是116的20%并不是32诶
(4)又分类又预测是值得被肯定的
1.2. 论文总结图

2. 论文逐段精读
2.1. Abstract
①The symptoms of attention deficit hyperactivity disorder (ADHD) are hard to identify and further diagnose
②They proposed a novel model that works on functional magnetic resonance imaging (fMRI), named dynamic graph convolutional network (dGCN)
③Through the model, the authors identified that ADHD can cause abnormalities in the temporal pole, rectus gyrus, and cerebellar gyrus of the temporal lobe, frontal lobe, and cerebellum
rectus n. 直肌;外直肌 cerebellar adj.小脑的 lobe n.(身体器官的)叶;(尤指)肺叶,脑叶
cerebellum n.小脑
2.2. Introduction
①Briefly introduce ADHD and express both the pathology and etiology of ADHD have not been accurately studied
②⭐However, only based on behavioral assessment will obstructe researchers from discovering specific and effective biomarkers and true brain causes. Because emotional disorder is the pathology of all adult ADHD psychopathology, post-traumatic stress disorder and major depression. Thus, they emphasized the importance of searching for relevant brain regions
③As a competition which promotes the further research of ADHD, ADHD-200 provide rich resting-state fMRI (rs-fMRI) data of ADHD
④Expound the historical and current model for brain research
⑤Their contributions: a) dynamic graph and 2 hop aggregation, b) new READOUT, c) interpretability
morphological n.同 morphologic adj.形态学(上)的;【语】词法的
homotopic adj.等位(的),(数学)同伦的 dysregulation n.失调;调节异常;调节障碍
2.3. Methods
2.3.1. Data acquisition and preprocessing
①Dataset: ADHD-200 database
②Sites: 8, contains New York University Medical Center (NYU), Peking University (PK), Kennedy Krieger Institute (KKI), NeuroIMAGE Sample, Bradley Hospital/Brown University, Oregon Health & Science University, University of Pittsburgh (UP), and Washington University in St. Louis
③Screen: they remain 635 first (不是最终选择!!) from NYU, PK, KKI, and UP. ⭐The reason is only the four sites have the compelete information (complete personal characteristic data, PCD)
④Preprocessing: Athena toolbox:
| (a) | removal of the first four echo-planar imaging volumes |
| (b) | slice timing |
| (c) | reorientation into right/posterior/inferior orientation |
| (d) | motion correction by realigning echo-planar imaging volumes to the first volume |
| (e) | brain extraction |
| (f) | calculation of mean functional image and co-register of the mean image with the corresponding structural MRI |
| (g) | transforming fMRI data and mean image into 4 × 4 × 4 mm3 MNI space |
| (h) | estimation of white matter (WM), cerebrospinal fluid (CSF) time signals from down-sampled WM and CSF masks |
| (i) | regressing out WM, CSF, and six motion parameters time series |
| (j) | applying a band-pass filter to exclude frequencies and blurring the data with a 6 mm FWHM Gaussian filter |
⑤They continued to eliminate the influence of head motion by isolation forest, then they screen 603 from 635, with 260 ADHD and 343 HC.
confounder n. 混淆;混杂因素;混杂变量;混杂因子;干扰因子
2.3.2. Proposed approach
①The give a specific explaination of each notation:

So... I start to be curious about your ⭐node feature
(1)Construction of graphs
①⭐In node-level graph, each subject is a node. The node feature is the combination of FC and PCD information vector, and the edge feature is extracted in adjacency matrix(我感觉类似聚类吧,就是那种聚类图,同一个label的就挨得近。但是局限是没有拓扑性质。问题就是脑子很难拓扑吧??搞电流流向吗?)However, this method is hard to predict unseen object and troublesome in new training
②⭐In subject-level graph, each subject is a whole graph. The edge is the pairwise Pearson's correlation or other similarity measurements between 2 ROIs, the node contains various features such as the FC of gray matter volume, surface area or ROI time series
③For better presenting the brain dysfunction, they choose subject-level graph
(2)Graph convolutional network
①The typical aggregate and update in GCN:
it firstly aggregates the features of neighbors and then construct new nodes
②Both aggregate and update functions can be changed to any form
permutation n.置换;排列(方式);组合(方式)
(3)Graph convolution layer (Normconv)
①There will be vanishing gradients in an over-deep GCN network
②Thus, they turn to construct a aggregation layer to aggregate 1 and 2 hop information:
where are the weights in MLP layer;
represents concatenation;
MLP is regarded as a update function and MEAN is regarded as an aggregation function;
seems to be the 1-hop nodes and
seems to be 2-hop nodes...
(4)Dynamic edge convolution layer (Edgeconv)
①Dynamic convolution will get better performance in representations capturing
②The approach is:
③The screen of top- firstly brings sparsity and secondly uniformly capture information from neighboring nodes. Moreover, they indicate a brain region is actually mainly associated with a small number of other regions
④Aggregation and update operations are the same with Normconv layer:
(5)Convolutional readout
①Their readout layer is different from traditional direct prediction. They add a subject-level representation between graph convolution and final classification layer. See below, where A is a traditional method and B is their convolutional readout:
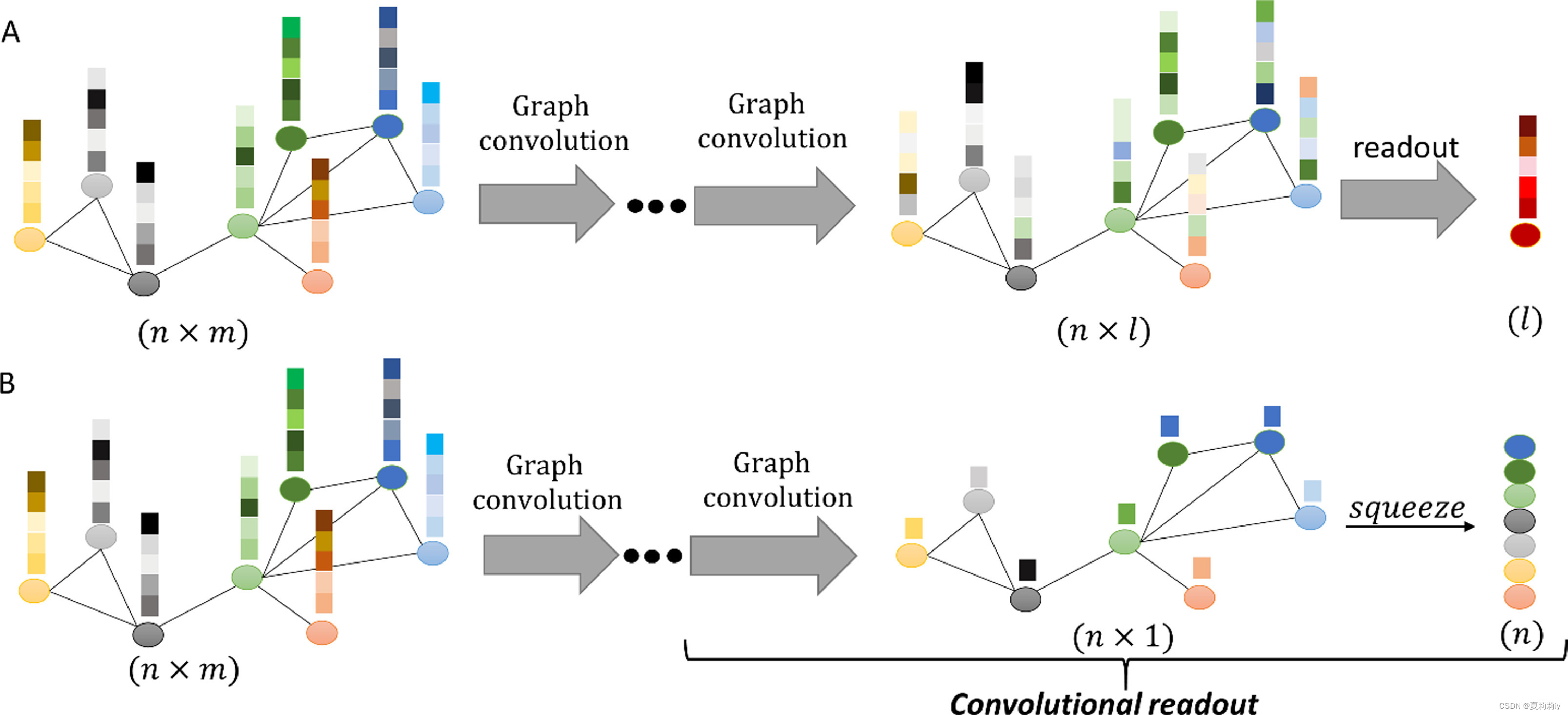
对于这个图,查宝是这样理解的:

因此总结一下他的意思,A最后得到的是一个人的向量(并没有分类,比如说如果要做node-level graph的话这个向量就是里面一个node的节点特征),后面可能还需要根据二分类再来个MLP;B里面得到的就是把那个图结构每个节点压在一起,也只是一个人的向量罢了,最后再MPL分类一下。此图中没有分类。
②They define a readout layer:
which is the concatenation of mean and max
③The squeeze the high-dimension feature to one dimension
(6)Implementation details
①The overall workflow:
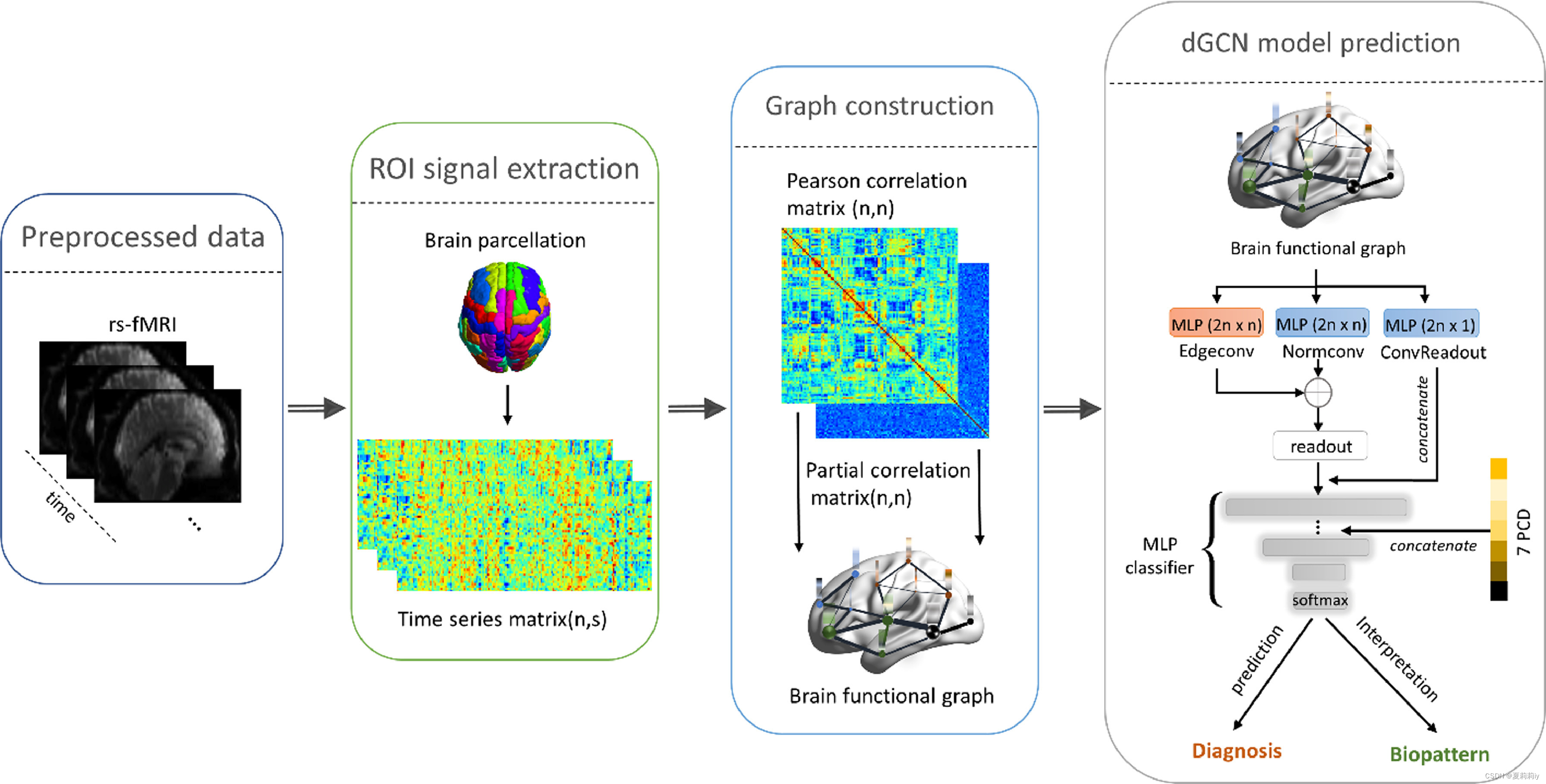
②Atlas: anatomical automated labeling (AAL) atlas, with 116 ROIs
③7 non-image information/PCD/node features: age, gender, handedness, IQ measurement, and three Wechsler Intelligence Scale evaluation IQ variables(这玩意儿ADHD里有吗?我没有这个数据集).⭐它是在中间嵌入的!!!不是一开始就有,要看图,就是最右边那个黄色的7PCD
④Learning rate in Adam optimizer: 0.01
⑤Batch size: 140
⑥Dropout ratio: 0.5, with 0.3 drop edge to avoiding overfitting
⑦Loss function: and
⑧The ratio of top: 20%
⑨Only the top 32 pairwise distances were remained for constructing adjacency matrix
2.4. Results
2.4.1. Experimental comparison
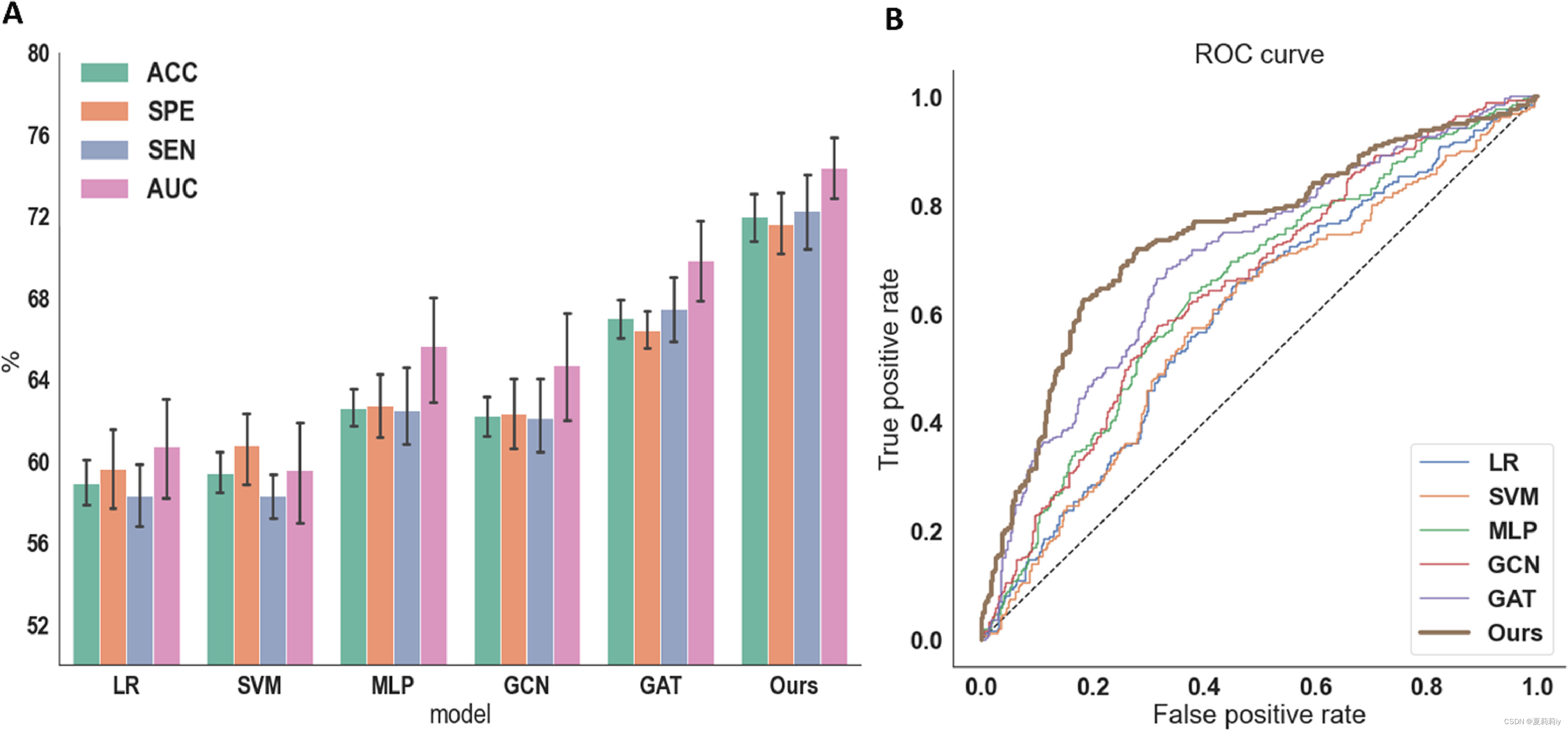
①They compared their dGCN with SVM, LR, MLP, GCN and GAT
②Cross-validation: 10-fold
③Measurements: accuracy (ACC), specificity (SPE), sensitivity (SEN), and area under the curve (AUC) of receiver operating characteristic (ROC)
④They provide the calculating methods of ACC, SPE and SEN:
⑤Comparison of different model:
⑥⭐Detecting model generalization by training three known sites to predict another site:
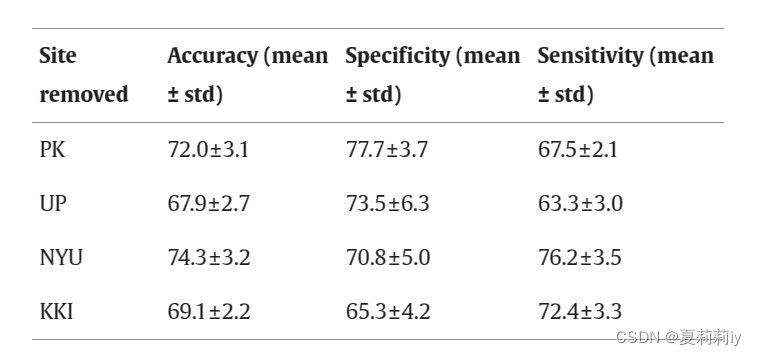
(可以见得⑤中ACC是72%的样子,这里也没有低很多,所以还是很鲁棒的)
stratify vt.分层;(使)成层
2.4.2. Ablation study
①Ablation study of each Conv layer:
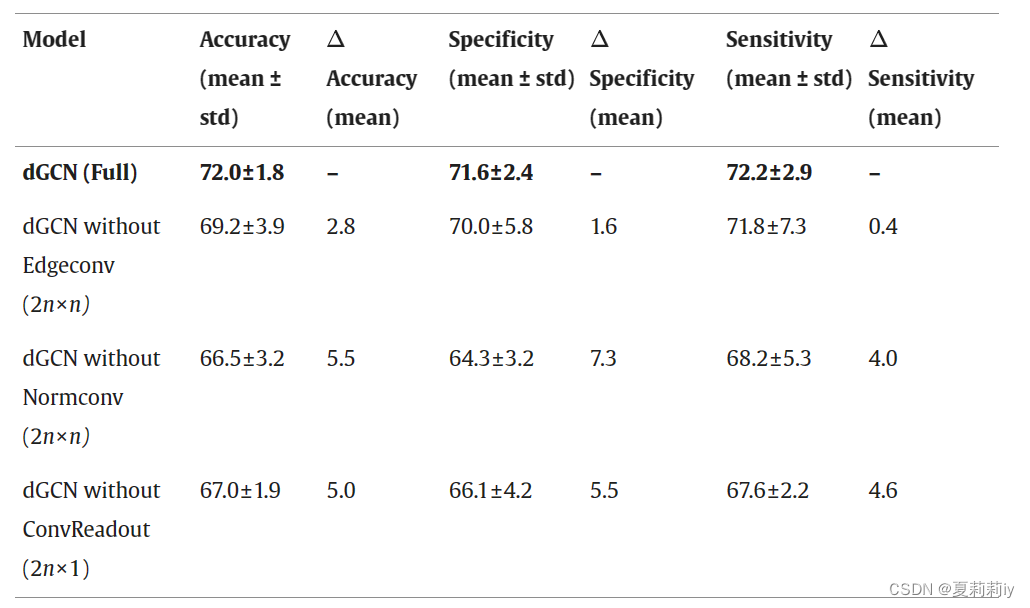
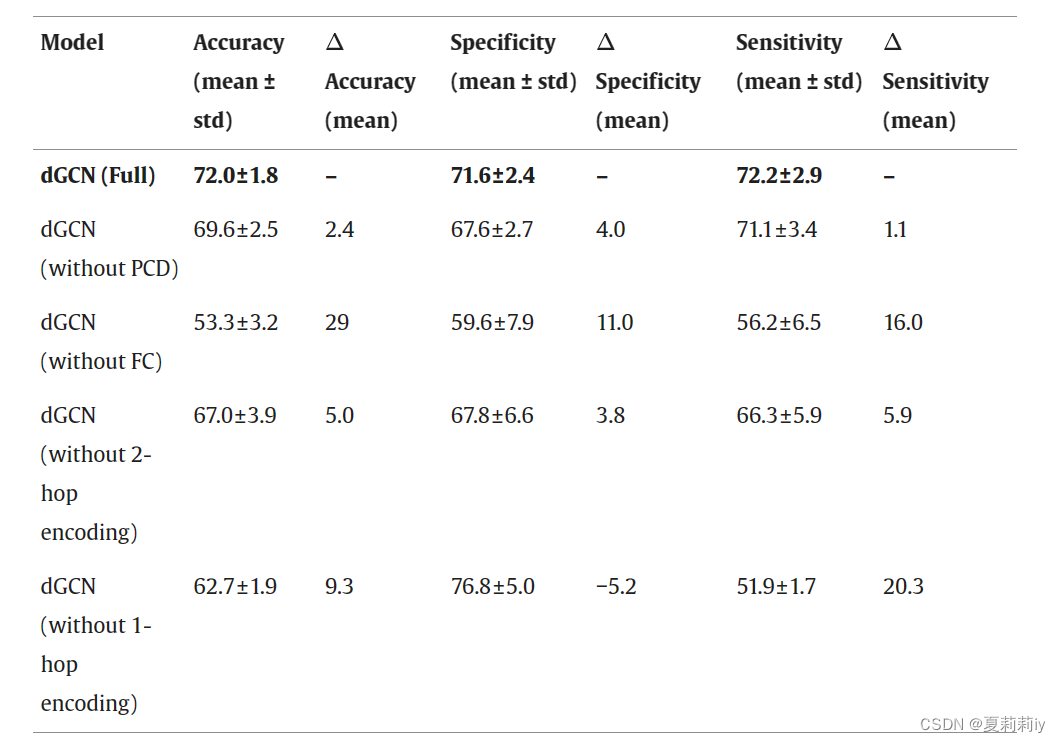
②Ablation study of PCD, FC and the number of hops:
2.4.3. Interpretation of ADHD diagnostic biomarkers
(1)Most discriminative brain regions and connections
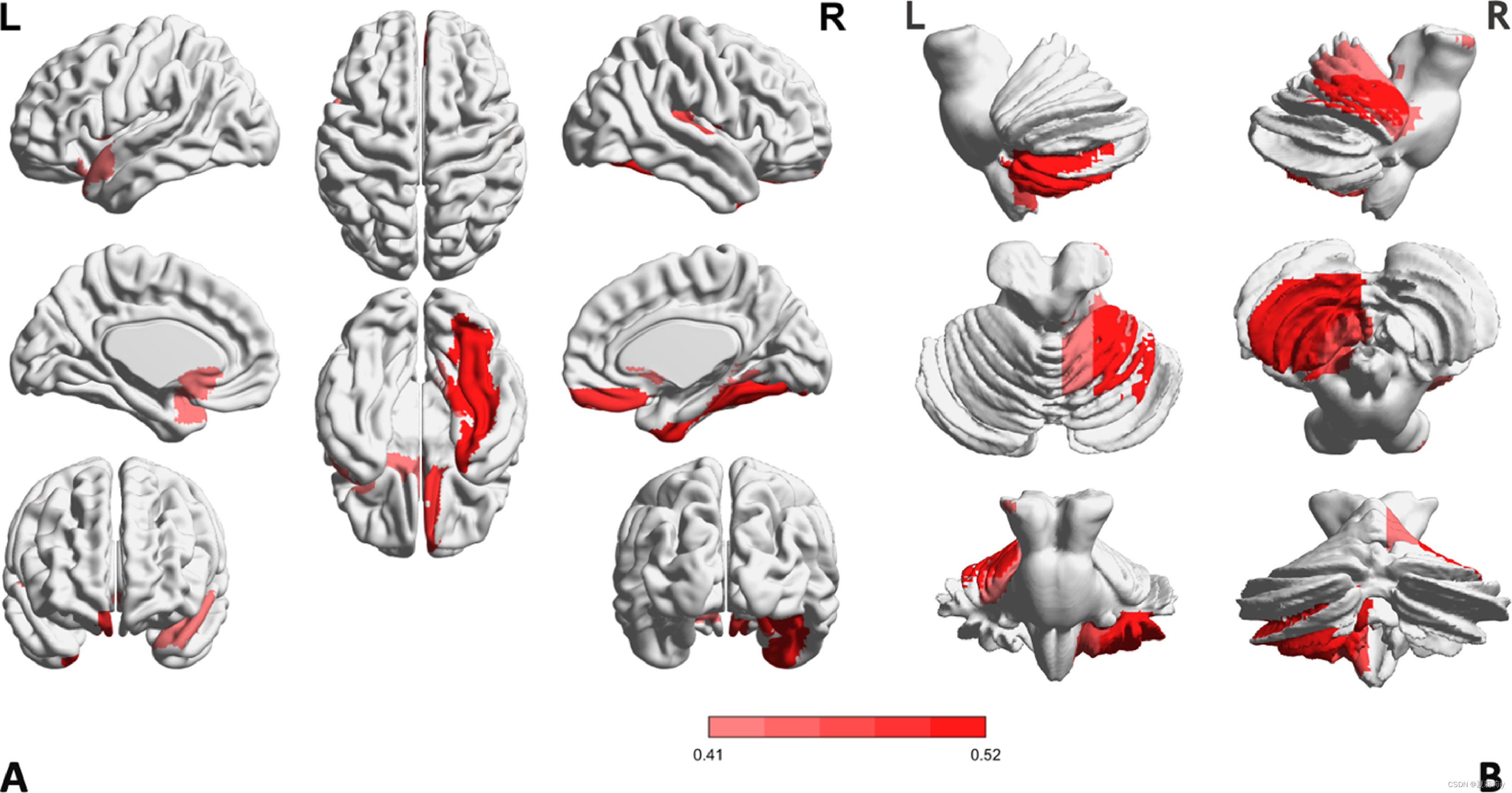
①⭐The get the mean value of weights in Edgeconv and Normconv after cross validation, then draw a conclusion that ROIs in frontal lobe, occipital lobe, subcortical lobe, temporal lobe, and posterior-fossa occupy the main weights:
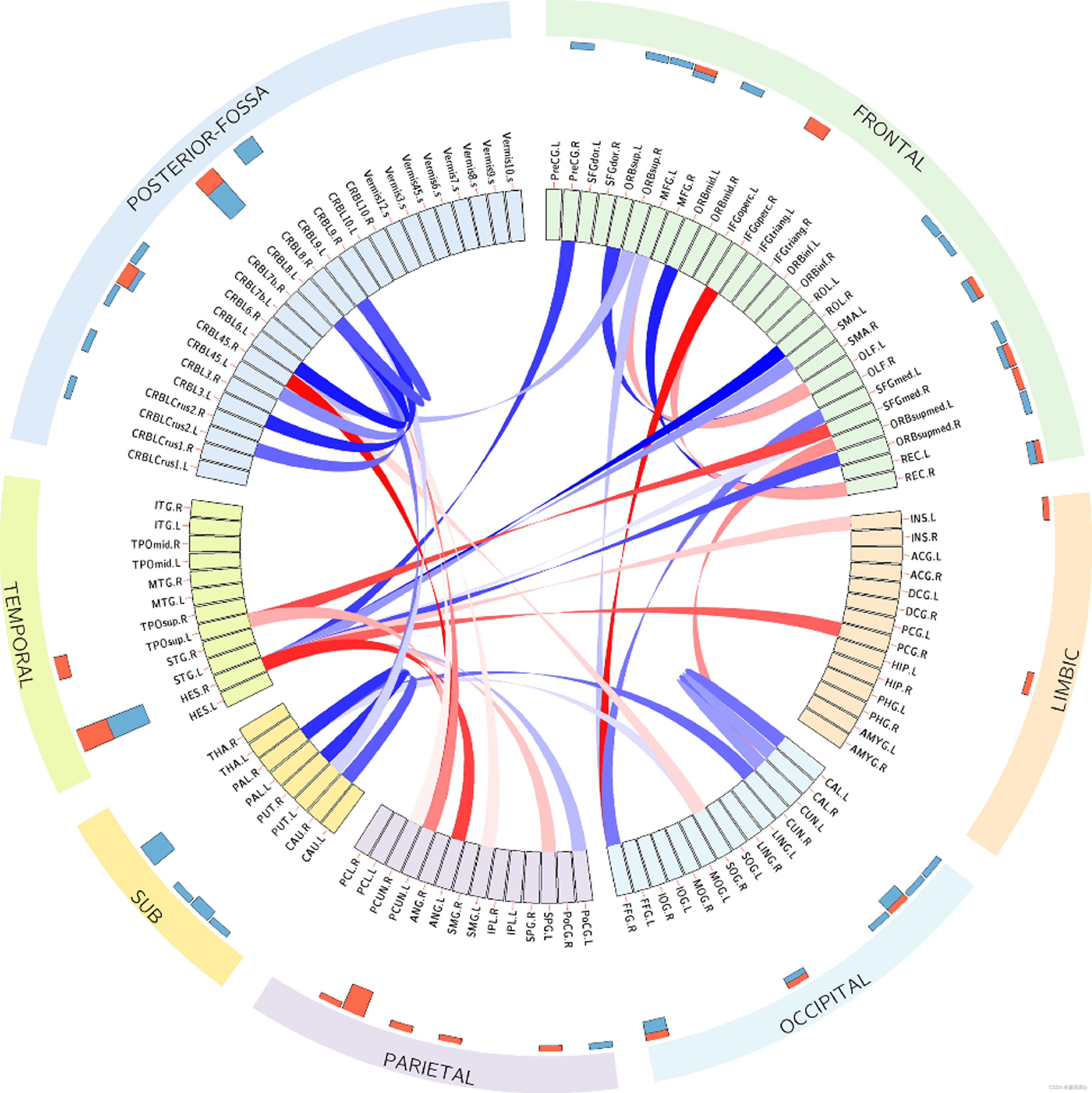
②Differences in connectivity between ADHD and HC corresponding to the top 40 key ROIs, verified by two-sample t-tests. In this figure, blue denotes hyper-connection and red indicates hypo-connection:
(2)Prediction ability of connectomic abnormalities for ADHD symptoms
①They predict the scores of scale through the subjects' fMRI and non-image data and calculate the correlation:
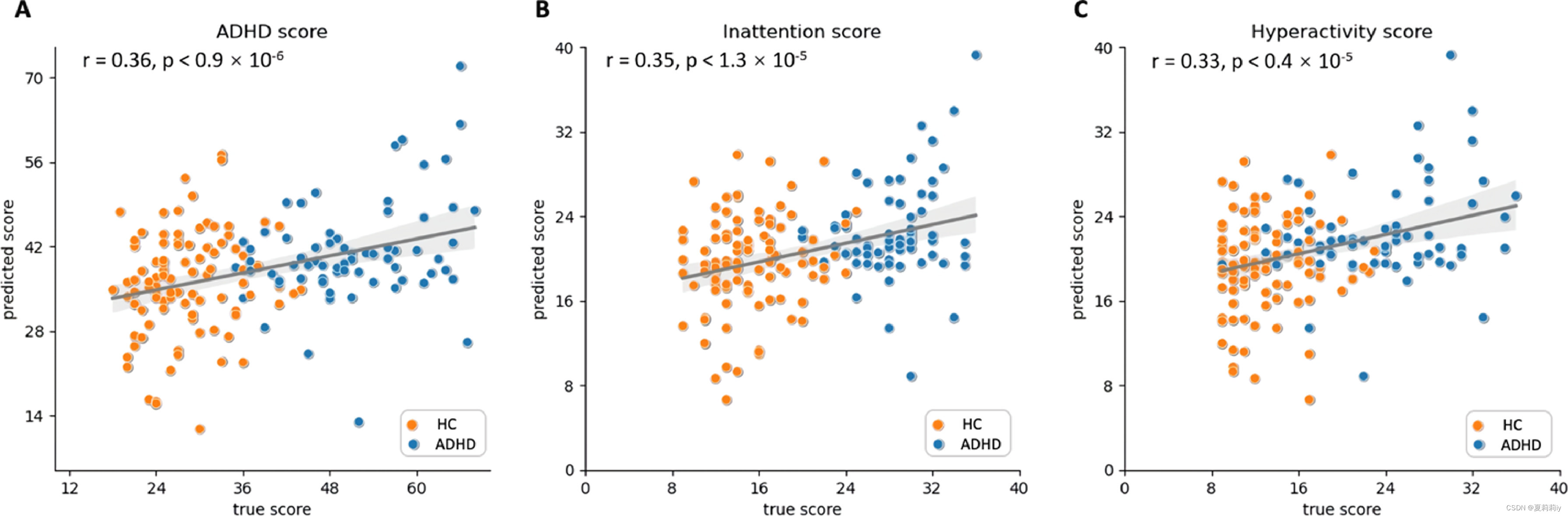
②"Nodal strength was calculated by averaging the absolute values of all connectomic features for each of the top 20% discriminative ROIs"(我没看懂这句话)
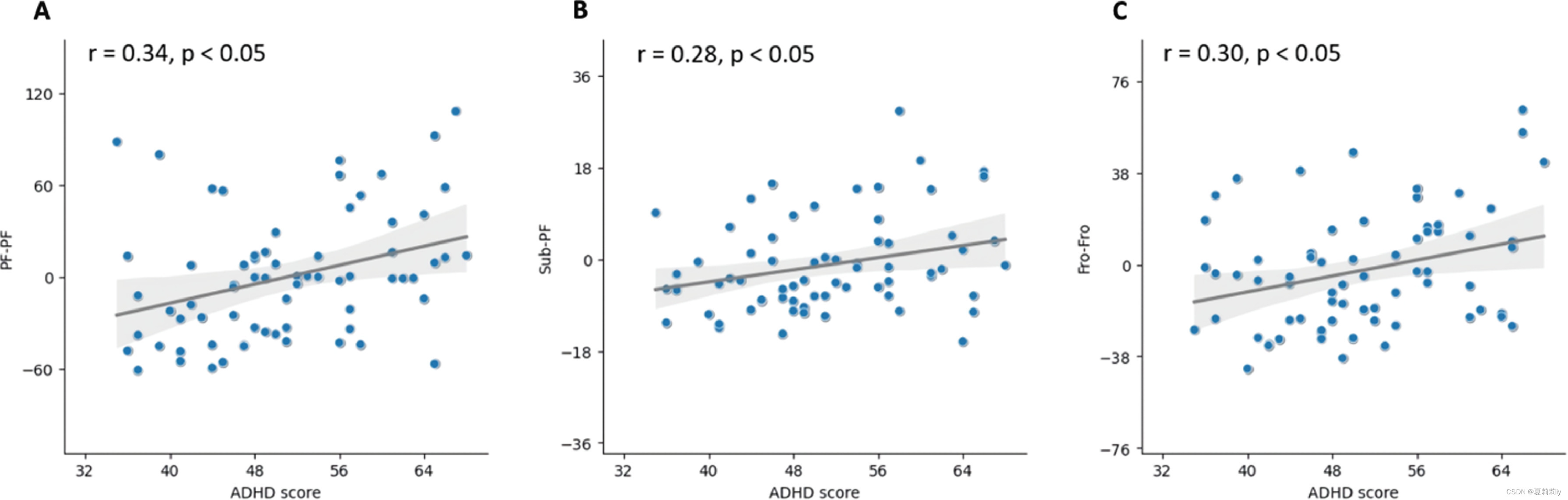
(3)Correlation between brain dysfunctions and ADHD score
They discuss the relationship between posterior fossa/subcortical lobe and posterior fossa/frontal lobe and ADHD score respectively:
2.5. Discussion
2.5.1. Advantages of dGCN in brain network analysis
①dGCN inherits the spatial advantage of GCN
②dGCN is able to predict a new subject directly. There is no need for another complete retraining
③Their inference is that the frontal lobe, subcortical lobe, and cerebellum may be the main areas of functional impairment in patients with ADHD
cingulate adj.扣带的;有色带的;(昆虫腹部)有色带环绕的
2.5.2. Limitations and future work
①They want to combine sMRI and fMRI together in the future
②They hold a view that PCD is a little bit simple
2.6. Conclusions
The dGCN presents the sparsity, has new readout layer and wider ROI detecting
3. 知识补充
3.1. Etiology and Pathology
(1)Pathology: the symptoms of a disease
(2)Etiology: the causes of the disease
3.2. Isolation forest
(1)网址:隔离林 |IEEE会议出版物 |IEEE Xplore的
4. Reference List
Zhao K. et al. (2022) 'A dynamic graph convolutional neural network framework reveals new insights into connectome dysfunctions in ADHD', NeuroImage, vol. 246. doi: Redirecting
这篇关于[论文精读]A dynamic graph convolutional neural network framework reveals new insights into connectome的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






