本文主要是介绍Amazon SageMaker + Stable Diffusion 搭建文本生成图像模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果我们的计算机视觉系统要真正理解视觉世界,它们不仅必须能够识别图像,而且必须能够生成图像。文本到图像的 AI 模型仅根据简单的文字输入就可以生成图像。

近两年,以ChatGPT为代表的AIGC技术崭露头角,逐渐从学术研究的象牙塔迈向工业应用的广阔天地。随着下游行业对快速处理柔性商业业务的需求日益增长,如何提供一个便捷、高效且完整的企业级人工智能解决方案成为了业界亟待解决的问题。幸运的是,亚马逊云服务推出了Amazon SageMaker平台,为企业提供了一站式的人工智能解决方案,满足了市场的迫切需求。
本篇文章将采用Amazon SageMaker+Stable Diffusion实现文本生成图像Demo!
一、Amazon SageMaker简介
Amazon SageMaker是一款亚马逊云服务旗下的全面托管机器学习平台。该平台集成了众多高效工具和服务,使得构建、训练和部署机器学习模型变得前所未有的简单。Amazon SageMaker拥有灵活的计算资源及配置选项,无论项目规模大小,它都能以强大的计算能力,助力训练大型模型。此外,它还提供了强大的管理和监控功能,确保机器学习工作流程的顺畅运行。

Amazon SageMaker机器学习平台提供了一系列能够快速构建、训练和部署机器学习模型的工具和服务,使机器学习工作流程更加高效、易用和可扩展。现在进入
亚马逊云科技: https://mic.anruicloud.com/url/1037
可以免费试用!

二、Amazon SageMaker + Stable Diffusion实践
2.1、创建Amazon SageMaker实例
首先打开亚马逊云控制台,在查找服务处搜索关键词SageMaker,进入Amazon SageMaker环境:

随后,在界面左侧定位至“笔记本”选项并点击。接着,依次选择“笔记本实例”和“创建笔记本实例”,进入配置页面。在此页面中,需注意选择适合的“笔记本实例类型”申请资源的类型,这里建议选择加速型g4dn.xlarge实例,确保高效的计算性能。
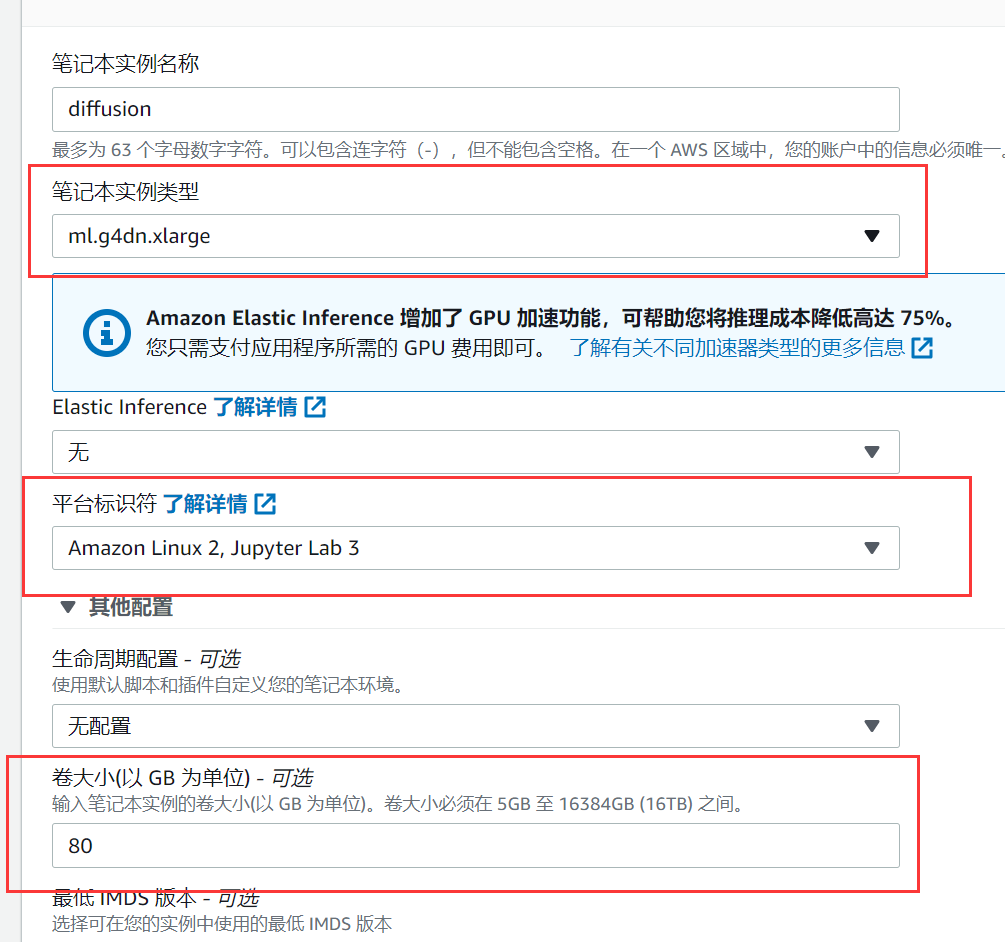
在操作系统方面,推荐选择Amazon Linux 2,并搭配Jupyter Lab 3这一交互式编程环境。“卷大小”可根据个人需求进行选择,建议至少设置为20GB,最后点击确定。
2.2、简单测试(可选)
创建实例成功后,可以新建一个初始notebook,复制并粘贴以下代码片段到笔记本的单元格,安装所需依赖
pip install --upgrade -q aiobotocorepip install -q xgboost==1.3.1然后复制并粘贴以下代码片段,点击run运行:
import pandas as pd
import boto3
import sagemaker
import json
import joblib
import xgboost as xgb
from sklearn.metrics import roc_auc_score# Set SageMaker and S3 client variables
sess = sagemaker.Session()region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)sagemaker_role = sagemaker.get_execution_role()# Set read and write S3 buckets and locations
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims" train_data_key = f"{read_prefix}/train.csv"
test_data_key = f"{read_prefix}/test.csv"
model_key = f"{write_prefix}/model"
output_key = f"{write_prefix}/output"train_data_uri = f"s3://{read_bucket}/{train_data_key}"
test_data_uri = f"s3://{read_bucket}/{test_data_key}"
hyperparams = {"max_depth": 3,"eta": 0.2,"objective": "binary:logistic","subsample" : 0.8,"colsample_bytree" : 0.8,"min_child_weight" : 3}num_boost_round = 100
nfold = 3
early_stopping_rounds = 10# Set up data input
label_col = "fraud"
data = pd.read_csv(train_data_uri)# Read training data and target
train_features = data.drop(label_col, axis=1)
train_label = pd.DataFrame(data[label_col])
dtrain = xgb.DMatrix(train_features, label=train_label)# Cross-validate on training data
cv_results = xgb.cv(params=hyperparams,dtrain=dtrain,num_boost_round=num_boost_round,nfold=nfold,early_stopping_rounds=early_stopping_rounds,metrics=["auc"],seed=10,
)metrics_data = {"binary_classification_metrics": {"validation:auc": {"value": cv_results.iloc[-1]["test-auc-mean"],"standard_deviation": cv_results.iloc[-1]["test-auc-std"]},"train:auc": {"value": cv_results.iloc[-1]["train-auc-mean"],"standard_deviation": cv_results.iloc[-1]["train-auc-std"]},}
}print(f"Cross-validated train-auc:{cv_results.iloc[-1]['train-auc-mean']:.2f}")
print(f"Cross-validated validation-auc:{cv_results.iloc[-1]['test-auc-mean']:.2f}")这段代码的主要作用是在Amazon S3存储桶中的的汽车保险索赔数据集上,训练一个 XGBoost 二进制分类模型,并评估模型的性能并使用交叉验证来评估其性能,运行单元格后会显示交叉验证训练和验证 AUC 分数。
2.3、Stable Diffusion实践
上一步运行没问题后,我们重新打开Jupyter页面,进入对应实例,选择右侧upload,上传Notebook代码,代码下载链接:
https://static.us-east-1.prod.workshops.aws/public/648e1f0c-f5e0-40eb-87b1-7f3638dba539/static/code/notebook-stable-diffusion.ipynb
上传到笔记本实例当中,上传成功后,点击打开,选择conda_pytorch_p39核,并点击set kernel

这个Diffusion Model的Amazon SageMaker Jupyter文件已经为我们写好了所有配置步骤,环境安装,我们直接点击Run:

该代码在笔记本实例中下载并测试Stable Diffusion模型文件,然后编写模型推理入口,打包模型文件,并上传至S3桶,最后使用代码部署模型至Amazon SageMaker Inference Endpoint。
在juypter notebook的最后,加上这样一段代码,然后将想要生成的句子可以写在prompt里面,就可以实现完整的文本生成图像功能:
from PIL import Image
from io import BytesIO
import base64# helper decoderdef decode_base64_image(image_string):base64_image = base64.b64decode(image_string)buffer = BytesIO(base64_image)return Image.open(buffer)#run prediction
response = predictor[SD_MODEL].predict(data={"prompt": ["A cute panda is sitting on the sofa","a siamese cat wearing glasses, working hard at the computer",],"height" : 512,"width" : 512,"num_images_per_prompt":1}
)#decode images
decoded_images = [decode_base64_image(image) for image in response["generated_images"]]#visualize generationfor image in decoded_images:display(image)如上,我们试着生成一张可爱的熊猫坐在沙发上面,等待几秒钟后,推理完成,得到如下结果:

三、Amazon SageMaker 的功能特性
Amazon SageMaker以其强大的功能特性和灵活的配置选项,为数据科学家、业务分析师以及广大开发者提供了全面、高效的机器学习解决方案。
首先,Amazon SageMaker能够让不同背景的用户都能够轻松利用机器学习进行创新。对于数据科学家而言,其提供了功能强大的集成开发环境(IDE),使得他们能够轻松构建、训练和部署复杂的机器学习模型。而对于业务分析师,其提供了无代码界面,即便没有深厚的编程背景,也能通过简单的操作实现机器学习的应用。

其次,Amazon SageMaker 支持如 TensorFlow、PyTorch 和 Apache MXNet多种主流的机器学习框架、支持如scikit-learn、XGBoost等各种机器学习工具包、支持Python、R 等多种编程语言,使得用户能够充分利用现有的技术资源和经验,在机器学习领域实现更快速、更高效的创新。无论是数据科学家、机器学习工程师还是开发者,都能从 Amazon SageMaker 中受益,推动机器学习技术的不断发展和应用。

最后,Amazon SageMaker拥有完全托管、可扩展的基础设施。用户无需担心底层硬件的维护和扩展问题,只需专注于模型的开发和优化。Amazon SageMaker通过高性能、经济实惠的基础设施支持,帮助用户轻松构建自己的机器学习模型和生成式人工智能应用程序的开发。
现在进入亚马逊云科技: https://mic.anruicloud.com/url/1037
可以获取Studio 笔记本上每月 250 个小时的 ml.t3.medium,或者按需笔记本实例上每月 250 个小时的 ml.t2 medium 或 ml.t3.medium,每月 50 个小时的 m4.xlarge 或150小时 的m5.xlarge 实例试用。除此之外,更有云服务器(Amazon EC2),云存储(Amazon S3),负载均衡(Elastic Load Balancing),虚拟服务器VPS(Amazon Lightsail)、视频会议(Amazon Chime )等等100 余种云产品或服务免费试用。

这篇关于Amazon SageMaker + Stable Diffusion 搭建文本生成图像模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








