本文主要是介绍ES8生产实践——ES跨集群数据迁移方案测评,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
场景需求
经常有小伙伴咨询如何将整个es集群数据如何迁移到另一个集群,其中往往会涉及到以下的问题:
跨es版本:老版本es集群数据迁移到新版本es集群。
跨集群:源数据和目的数据分布在两个不同的集群。
跨网络:两套集群分布数据不同的局域网、一套在公有云、一套在自建机房。
迁移思路
目前主流的解决方案分为以下两类:
批量读取旧集群的数据然后再批量写入新集群:elasticsearch-dump、esm、reindex、logstash都是采用这种方式。
底层文件备份恢复:snapshot直接把旧集群的底层的文件进行备份,在新的集群中恢复出来,相比较scroll query + bulk的方式,snapshot的方式迁移速度最快。
环境准备
测试环境
源数据集群:单节点rpm方式部署的es7.17.18集群,ip地址为192.168.10.70。
目的数据集群:3节点rpm方式部署的es8.12.2集群,ip地址为192.168.10.61/62/63。
数据中转操作节点:可同时连接两套es集群,用于中转数据。
测试数据
使用esrally工具生成测试数据,模拟生产环境大小为2.6G的业务数据。具体可参考文档:https://www.cuiliangblog.cn/detail/article/81
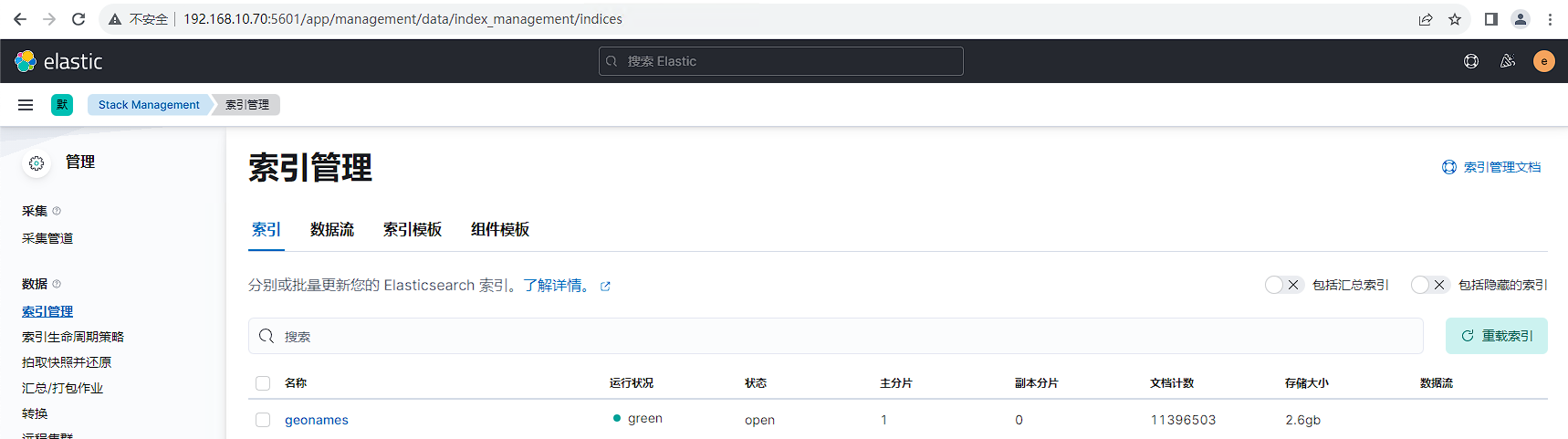
运行日志生成程序,模拟生产环境中持续写入的日志数据。具体可参考文档:https://www.cuiliangblog.cn/detail/article/63
全量迁移方案对比测试
数据迁移流程思路
我们先在目的集群设置索引模板,保证写入速率最大化。
PUT _template/geonames
{"index_patterns": ["geonames*"],"order": 100,"settings": {"refresh_interval": "-1","number_of_shards": "3","translog": {"sync_interval": "60s","durability": "async"},"number_of_replicas": "0"}
}
然后使用迁移工具,将源数据导出至目的集群。
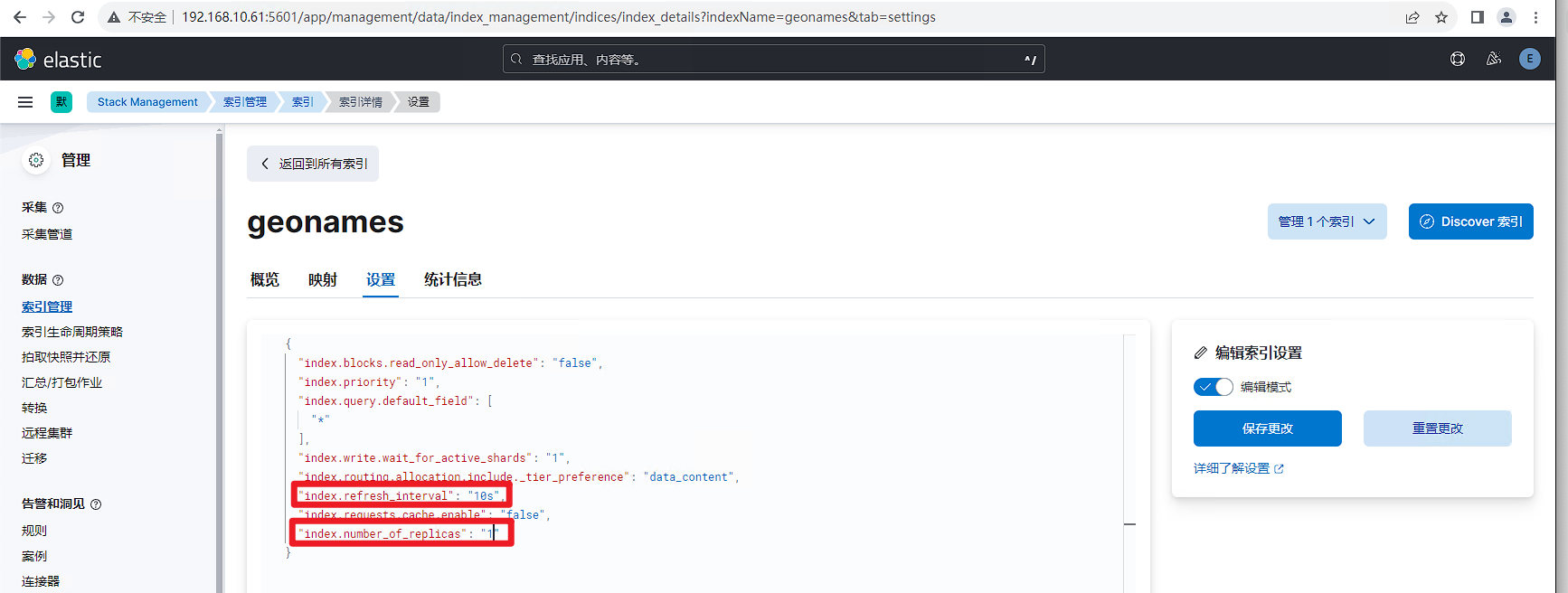
最后在索引管理中将number_of_replicas和refresh_interval参数设置为合适的值即可。
snapshot方案
ES支持快照功能,用于实现数据的备份与恢复。我们可以生成单个索引或整个集群的快照,并将其存储在共享文件系统上的存储库中,并且有一些插件支持 S3、HDFS、Azure、Google Cloud Storage 等上的远程存储库。
本实验以NFS为例演示es的快照备份与恢复。
源集群配置
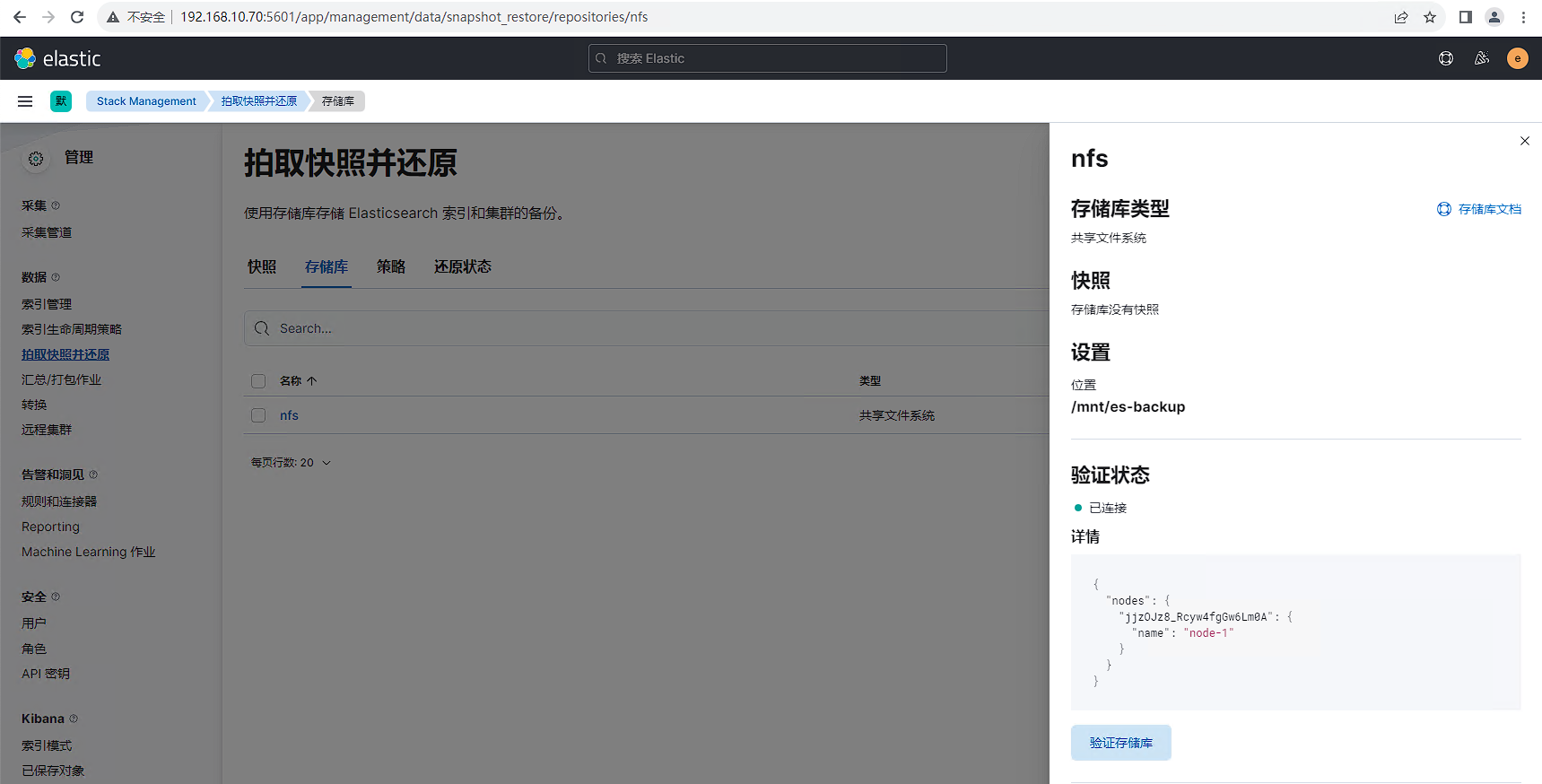
源数据集群配置NFS共享存储库具体可参考文档:https://www.cuiliangblog.cn/detail/section/162073776,配置完后效果如下所示:
接下来配置索引快照存储策略,配置完后后点击立即运行。
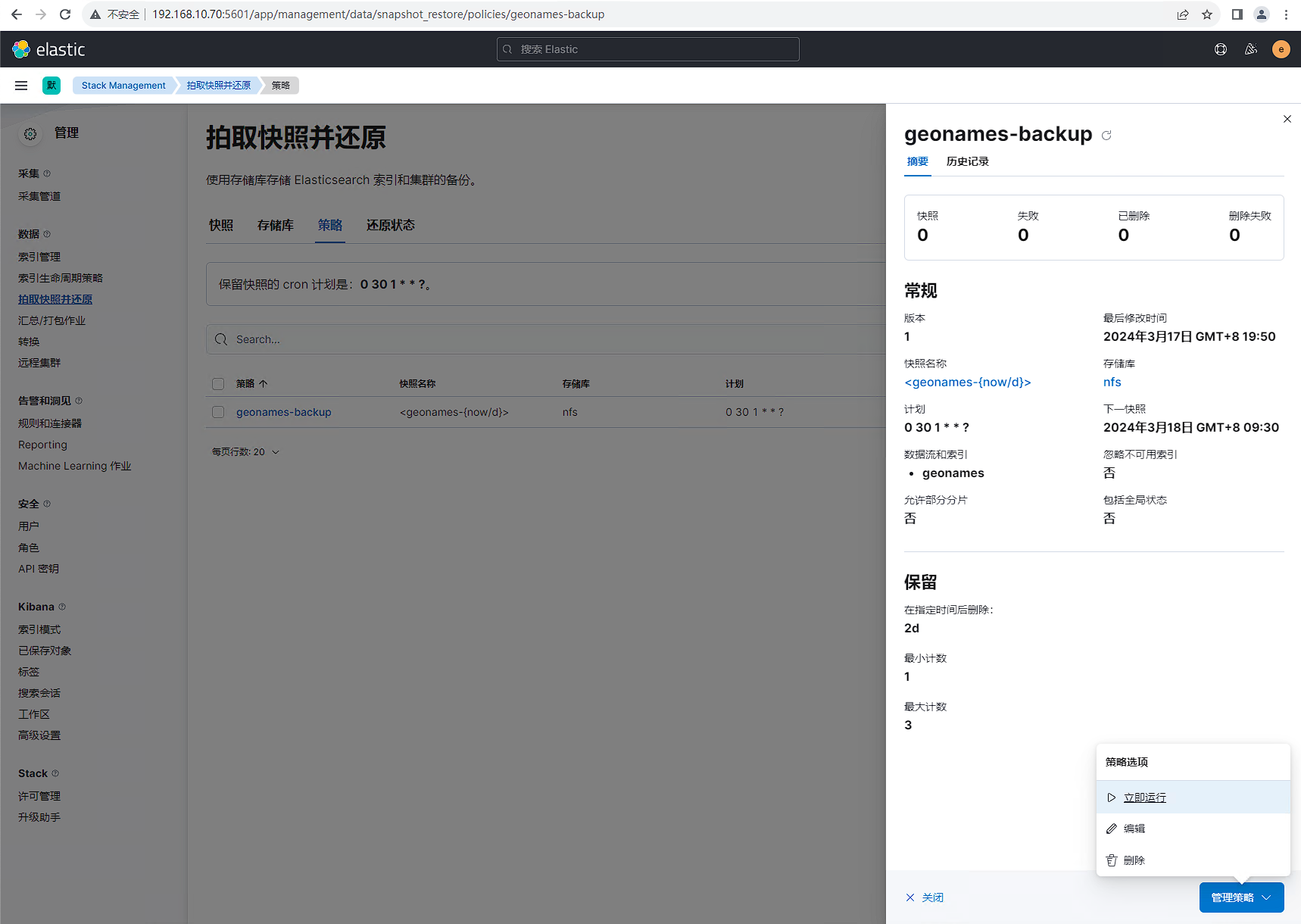
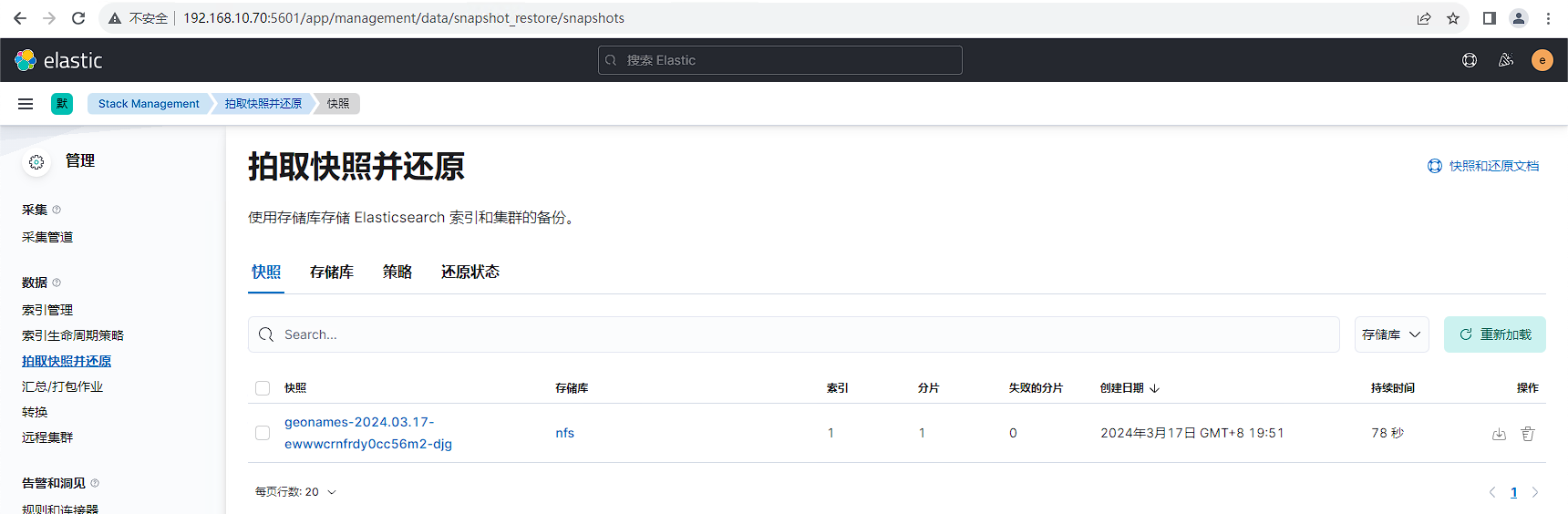
等待备份完成,查看备份结果,2.6G数据备份耗时78秒
目的集群配置
操作与源集群类似,先配置nfs共享存储仓库,配置完后效果如下所示:
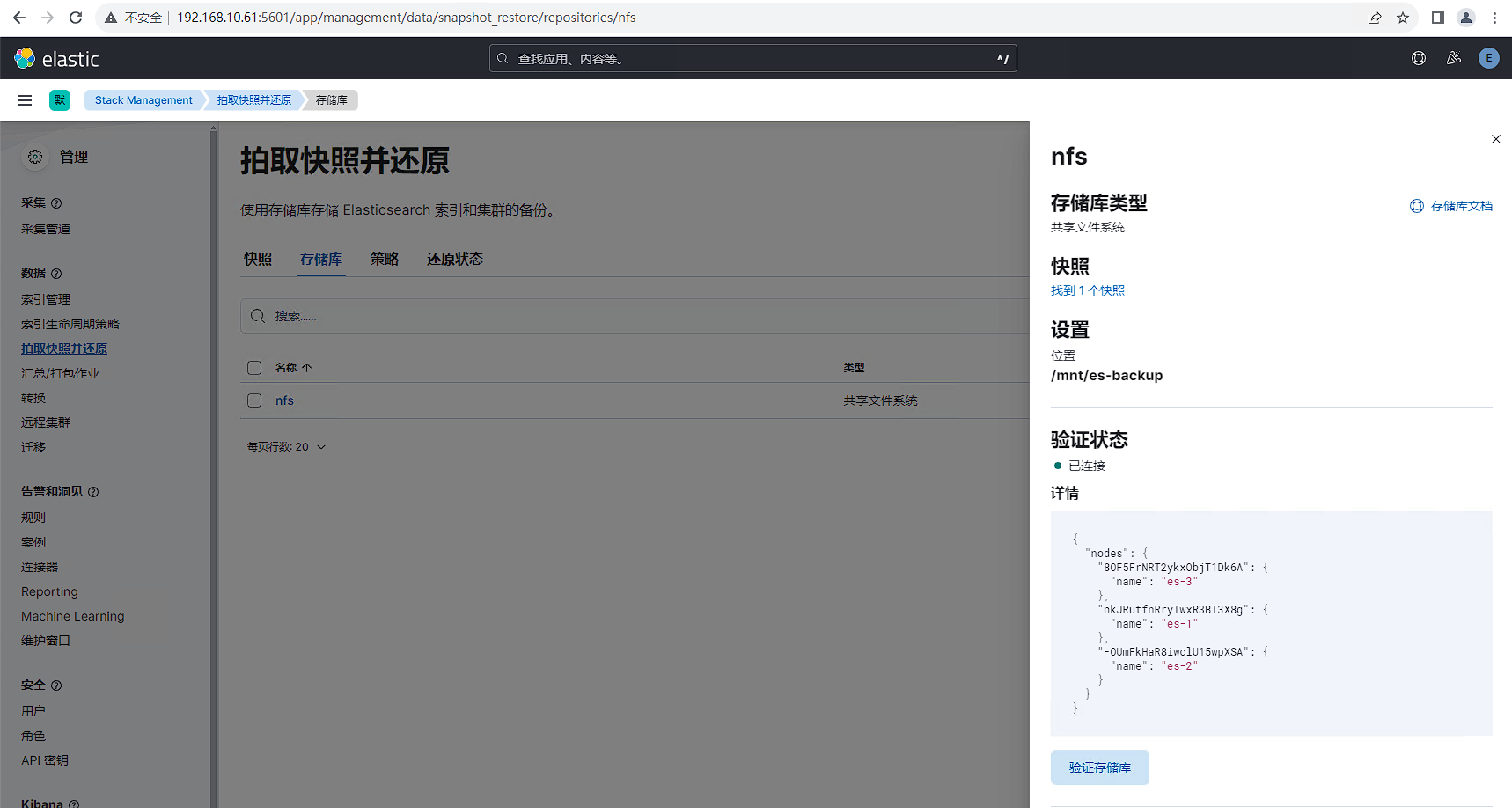
因为源集群和目的集群使用同一个备份存储库,所以目的集群配置完存储库后就可以加载出源集群的备份数据。
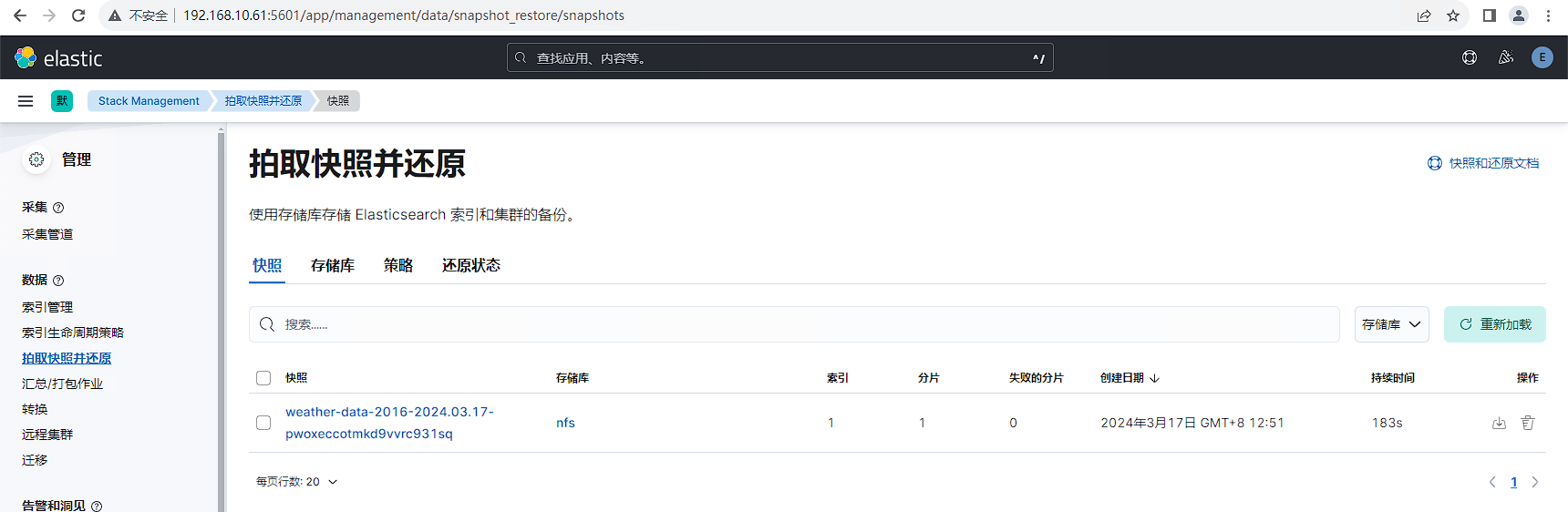
在还原过程中通常会设置number_of_replicas: 0和refresh_interval: -1两个参数,以加速数据恢复。
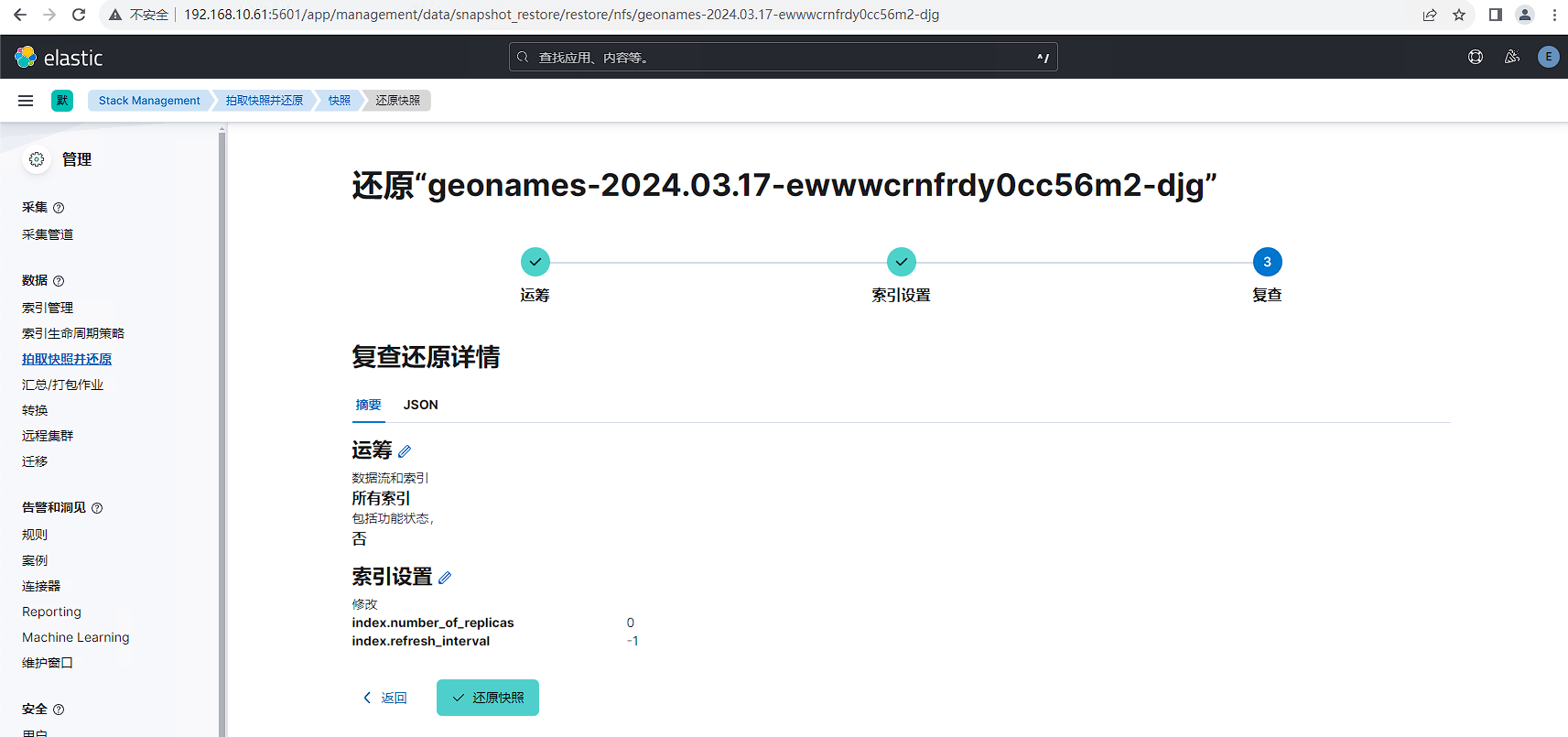
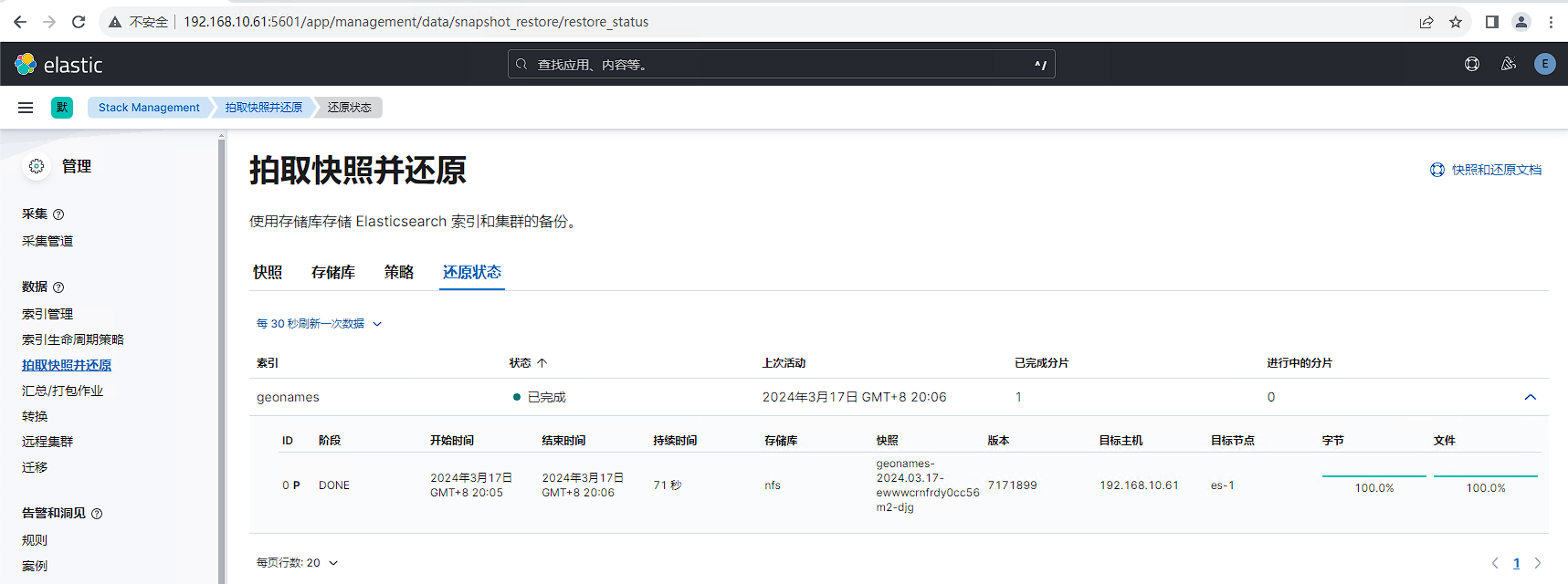
等待还原完成,查看还原结果,2.6G数据还原耗时71秒
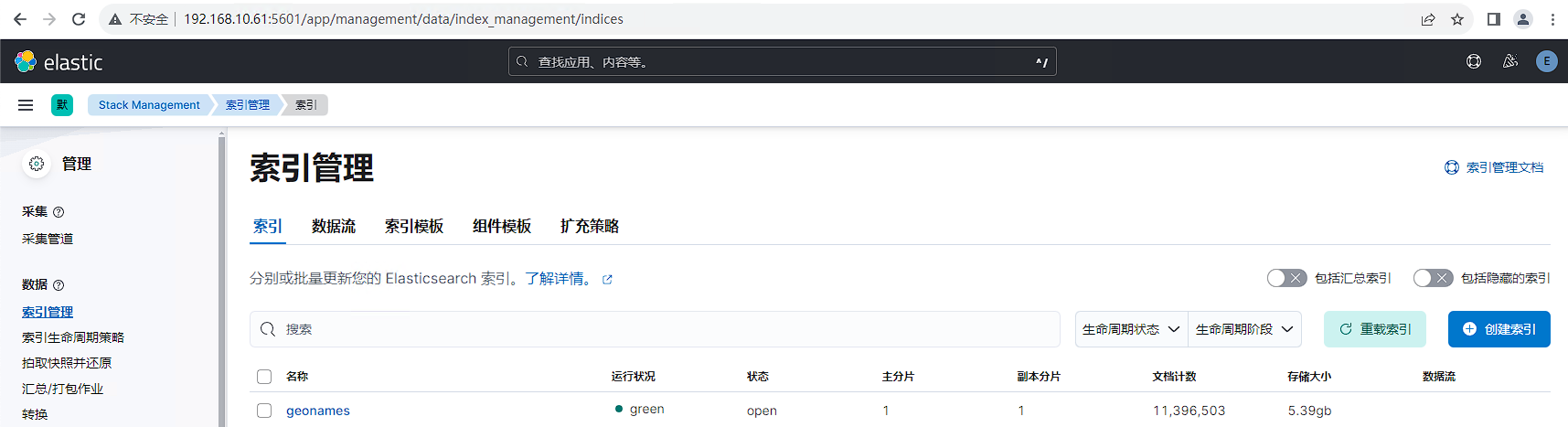
恢复后的索引数据如下所示,由于设置了1个副本,因此存储大小变为5.3G
elasticsearch-dump方案
elasticsearch-dump是一个开源的使用JavaScript语言开发的Elasticsearch数据迁移工具,详细信息请参见文档:https://github.com/elasticsearch-dump/elasticsearch-dump
中转操作节点安装部署
安装elasticdump
[root@tiaoban ~]# dnf install nodejs npm -y
[root@tiaoban ~]# npm install elasticdump -g
Elasticdump标准指令是
elasticdump --input SOURCE --output DESTINATION [OPTIONS]
- input SOURCE表示读取数据源SOURCE
- output DESTINATION表示将数据源传输到目的地DESTINATION。
- SOURCE/DESTINATION两者都可以是Elasticsearch URL或文件,如果是Elasticsearch URL,例如http://127.0.0.1/index,就意味着是直接往地址为http://127.0.0.1ES库里导入或者从其导出索引相关数据。
- [OPTIONS]是操作选项,比较常用有type和limit,其他操作这里就不展开介绍。
type是ES数据导出导入类型,Elasticdum工具支持以下数据类型的导入导出。
| type类型 | 说明 |
|---|---|
| mapping | ES的索引映射结构数据 |
| data | ES的数据 |
| settings | ES的索引库默认配置 |
| analyzer | ES的分词器 |
| template | ES的模板结构数据 |
| alias | ES的索引别名 |
整个迁移过程分为先设置索引参数参数,再迁移mapping结构,待数据迁移完成后再修改number_of_replicas和refresh_interval为合适的值。
迁移mapping
使用elasticdump工具,将es7单节点的geonames索引mapping迁移到三节点es8集群中。
[root@tiaoban ~]# NODE_TLS_REJECT_UNAUTHORIZED=0 elasticdump \
--input=http://elastic:123.com@192.168.10.70:9200/geonames \
--output=https://elastic:yoVU+Pit0YnVvr+xO_B1@192.168.10.61:9200/geonames \
--type=mappingSun, 17 Mar 2024 11:11:12 GMT | starting dumpSun, 17 Mar 2024 11:11:12 GMT | got 1 objects from source elasticsearch (offset: 0)
Sun, 17 Mar 2024 11:11:12 GMT | sent 1 objects to destination elasticsearch, wrote 2
Sun, 17 Mar 2024 11:11:12 GMT | got 0 objects from source elasticsearch (offset: 1)
Sun, 17 Mar 2024 11:11:12 GMT | Total Writes: 2
Sun, 17 Mar 2024 11:11:12 GMT | dump complete
mapping迁移完成后,查看索引信息,已经创建名为geonames的索引。
迁移data
与迁移mapping类似,我们只需要将type从mapping改为data即可,观察控制台输出,每迁移1万条数据耗时约95秒。
[root@tiaoban ~]# date
2024年 03月 17日 星期日 19:12:50 CST
[root@tiaoban ~]# NODE_TLS_REJECT_UNAUTHORIZED=0 elasticdump \
--input=http://elastic:123.com@192.168.10.70:9200/geonames \
--output=https://elastic:yoVU+Pit0YnVvr+xO_B1@192.168.10.61:9200/geonames \
--type=data
Sun, 17 Mar 2024 12:43:07 GMT | starting dump
Sun, 17 Mar 2024 12:43:08 GMT | got 100 objects from source elasticsearch (offset: 0)
Sun, 17 Mar 2024 12:43:08 GMT | sent 100 objects to destination elasticsearch, wrote 100
Sun, 17 Mar 2024 12:43:08 GMT | got 100 objects from source elasticsearch (offset: 100)
Sun, 17 Mar 2024 12:43:08 GMT | sent 100 objects to destination elasticsearch, wrote 100
Sun, 17 Mar 2024 12:43:08 GMT | got 100 objects from source elasticsearch (offset: 200)
elasticdump执行完成后查看目的集群索引,已成功完成迁移,整个过程耗时约3个小时。
esm方案
esm迁移过程原理与elasticsearch-dump类似,区别在于esm使用go语言开发,号称每分钟可以迁移一千万条数据,仓库地址:https://github.com/medcl/esm
中转操作节点安装部署
安装esm
[root@tiaoban ~]# cd /opt/
[root@tiaoban opt]# wget https://github.com/medcl/esm/releases/download/v0.7.0/esm-linux-amd64esm标准指令是
esm -s SOURCE -d DESTINATION -x INDEX_NAME [OPTIONS]
- -s表示读取数据源SOURCE
- -d表示将数据源传输到目的地DESTINATION。
- -x表示需要复制的index名称
- -q表示指定条件的查询语句
- -n表示base认证的用户名和密码
- -w表示并发数,默认为1
- -b表示buck大小,默认5MB
- -f表示复制前删除已有重名索引
- –refresh表示完成后再刷新索引
迁移数据
使用esm工具,将es7单节点的geonames索引模板与数据迁移到三节点es8集群中。
[root@tiaoban opt]# ./esm-linux-amd64 -s http://192.168.10.70:9200 -m elastic:123.com -x "geonames" -d https://192.168.10.61:9200 -n "elastic:yoVU+Pit0YnVvr+xO_B1" -c 10000 -w10 -b=20 -f --refresh
[03-17 22:20:26] [INF] [ migrator.go:115 ,ParseEsApi] source es version: 7.17.18
[03-17 22:20:30] [INF] [ migrator.go:115 ,ParseEsApi] dest es version: 8.12.2
geonames
[03-17 22:20:30] [INF] [ main.go:432 ,main] start data migration..
Scroll 250000 / 11396503 [==>--------------------------------------------------------------------------------------------------------------------] 2.19% 1h07m33s
Bulk 0 / 11396503 [---------------------------------------------------------------------------------------------------------------------------------------] 0.00%
通过控制台可知,整个迁移过程需要时间约1个小时10分钟。
reindex方案
设置索引模板
在迁移数据前,我们先设置索引模板,保证写入速率最大化
PUT _template/geonames
{"index_patterns": ["geonames*"],"order": 100,"settings": {"refresh_interval": "-1","number_of_shards": "3","translog": {"sync_interval": "60s","durability": "async"},"number_of_replicas": "0"}
}
配置集群白名单
需要修改目的集群每个节点配置,新增源数据集群es地址,然后重启elasticsearch服务。
[root@es-1 ~]# vim /etc/elasticsearch/elasticsearch.yml
reindex.remote.whitelist: "192.168.10.70:9200"
[root@es-1 ~]# systemctl restart elasticsearch.service
执行reindex迁移
在目的集群使用dev tools工具执行如下指令。
- 其中size表示每批次的数据量,默认值1000
- slice表示切片数量,我们有3个数据节点,可将参数设置为3。
- wait_for_completion=false表示异步执行,ES将会以task 来描述此类执行任务
# 请求
POST _reindex?wait_for_completion=false
{"source": {"remote": {"host": "http://192.168.10.70:9200","username": "elastic","password": "123.com"},"index": "geonames","size": 5000,"slice": {"id": 0,"max": 3}},"dest": {"index": "geonames"}
}
# 响应
{"task": "nkJRutfnRryTwxR3BT3X8g:8989"
}
查询异步任务。
# 请求
GET _tasks/nkJRutfnRryTwxR3BT3X8g:8989
# 响应
{"completed": false,"task": {"node": "nkJRutfnRryTwxR3BT3X8g","id": 8989,"type": "transport","action": "indices:data/write/reindex","status": {"slice_id": 0,"total": 11396503,"updated": 0,"created": 1590000,"deleted": 0,"batches": 319,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0},"description": """reindex from [host=192.168.10.70 port=9200 query={"match_all" : {"boost" : 1.0}
} username=elastic password=<<>>][geonames] to [geonames]""","start_time_in_millis": 1710686333672,"running_time_in_nanos": 54938483353,"cancellable": true,"cancelled": false,"headers": {"trace.id": "8e6e3043b5c916eb3f8f569f9132d9ab"}}
}
实测2.6GB数据迁移用时15分钟。
logstash方案
安装logstash
[root@tiaoban ~]# wget https://artifacts.elastic.co/downloads/logstash/logstash-8.12.2-x86_64.rpm
[root@tiaoban ~]# rpm -ivh logstash-8.12.2-x86_64.rpm
[root@tiaoban ~]# ln -s /usr/share/logstash/bin/logstash /usr/bin/logstash
[root@tiaoban ~]# logstash -V
Using bundled JDK: /usr/share/logstash/jdk
logstash 8.12.2
配置logstash
[root@tiaoban ~]# vim /etc/logstash/conf.d/es-migrate.conf
input{elasticsearch{hosts => ["http://192.168.10.70:9200"] # 源端ES地址。# 安全集群配置登录用户名密码。user => "elastic"password => "123.com"index => "geonames" # 需要迁移的索引列表,多个索引以英文以逗号(,)分隔。# 以下三项保持默认即可,包含线程数和迁移数据大小和Logstash JVM配置相关。docinfo=>trueslices => 5size => 5000}
}
filter {# 去掉一些Logstash自己加的字段。mutate {remove_field => ["@timestamp", "@version"]}
}
output{elasticsearch{hosts => ["https://192.168.10.61:9200"] # 目标端ES地# 安全集群配置登录用户名密码。user => "elastic"password => "yoVU+Pit0YnVvr+xO_B1"index => "geonames" # 目标端索引名称ssl_enabled => true # 如果是https协议,需要设置为truessl_verification_mode => none # 是否跳过证书验证,如果为false需要指定证书路径}
}
启动logstash
[root@tiaoban ~]# logstash -f /etc/logstash/conf.d/es-migrate.conf
# 也可以通过systemctl start logstash方式启动
实测2.6GB数据迁移用时8分钟。
增量迁移方案
业务场景
ES除了用于存储业务类数据外,日志和指标数据存储也是其另一大使用场景,在这类业务场景下,数据迁移往往还需要考虑到采集日志客户端逐渐切换过程中日志数据增量迁移的问题。
迁移方案
CCR方案:ES官方推出了CCR跨集群复制方案,可以完美实现数据的实时增量迁移,具体可参考文档https://www.cuiliangblog.cn/detail/section/83558841,需要注意的是开源社区版不支持该功能。
定时任务+时间范围查询方案:然后通过定时任务工具每分钟执行一次迁移工具,查询最近3分钟数据(主要取决于源数据refresh_interval参数,查询时间范围应大于refresh_interval参数),在写入es集群时指定文档id为原始数据id,以保证写入新集群时数据唯一。需要注意的是此方案只能针对数据有增无减的场景使用。可以使用sdk开发程序,或者使用logstash来实现。在增量同步前先执行一次全量迁移任务,保证先前历史数据迁移至新集群,然后再启动增量迁移任务。
logstash迁移方案
修改配置文件,我们只需要将pipeline放置在/etc/logstash/conf.d/目录下并以.conf结尾,logstash启动时会去扫描该目录下所有conf结尾的pipeline并加载。
[root@tiaoban ~]# vim /etc/logstash/conf.d/es-migrate.conf
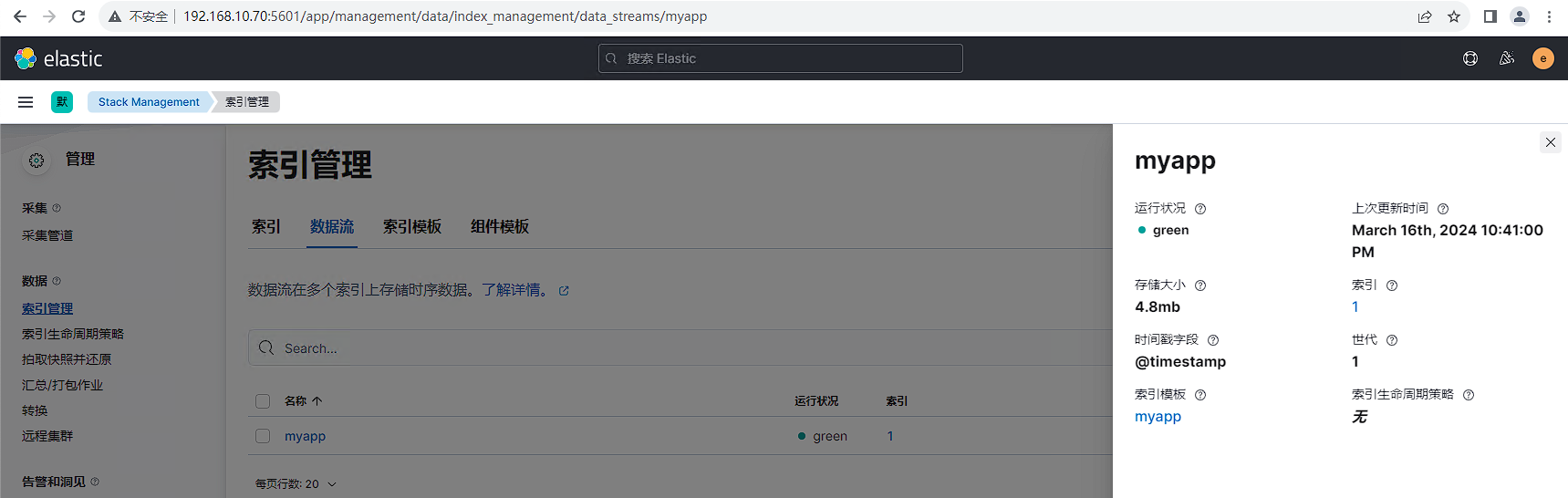
input{elasticsearch{hosts => ["http://192.168.10.70:9200"] # 源端ES地址。# 安全集群配置登录用户名密码。user => "elastic"password => "123.com"index => "logs-myapp-default" # 需要迁移的索引列表,多个索引以英文以逗号(,)分隔。# 包含线程数和迁移数据大小和Logstash JVM配置相关。slices => 5size => 5000# 获取文档元数据信息docinfo=> truedocinfo_target => "[@metadata][doc]"# 按时间范围查询增量数据,以下配置表示查询最近3分钟的数据。query => '{"query":{"range":{"@timestamp":{"gte":"now-3m","lte":"now/m"}}}}'# 定时任务,以下配置表示每分钟执行一次。schedule => "* * * * *"# 滚动查询活动时间scroll => "3m"}
}
filter {# 去掉一些Logstash自己加的字段。mutate {remove_field => ["@timestamp", "@version"]}
}
output{elasticsearch{hosts => ["https://192.168.10.61:9200"] # 目标端ES地# 安全集群配置登录用户名密码。user => "elastic"password => "yoVU+Pit0YnVvr+xO_B1"# 目标数据流配置data_stream => "true"data_stream_type => "logs"data_stream_dataset => "myapp"data_stream_namespace => "default"ssl_enabled => true # 如果是https协议,需要设置为truessl_verification_mode => none # 是否跳过证书验证,如果为false需要指定证书路径document_id => "%{[@metadata][doc][_id]}" # 目标端数据的id,id存在会覆盖,保证数据唯一。}
}
启动logstash迁移服务
[root@tiaoban ~]# systemctl start logstash
[root@tiaoban ~]# systemctl enable logstash
结果验证
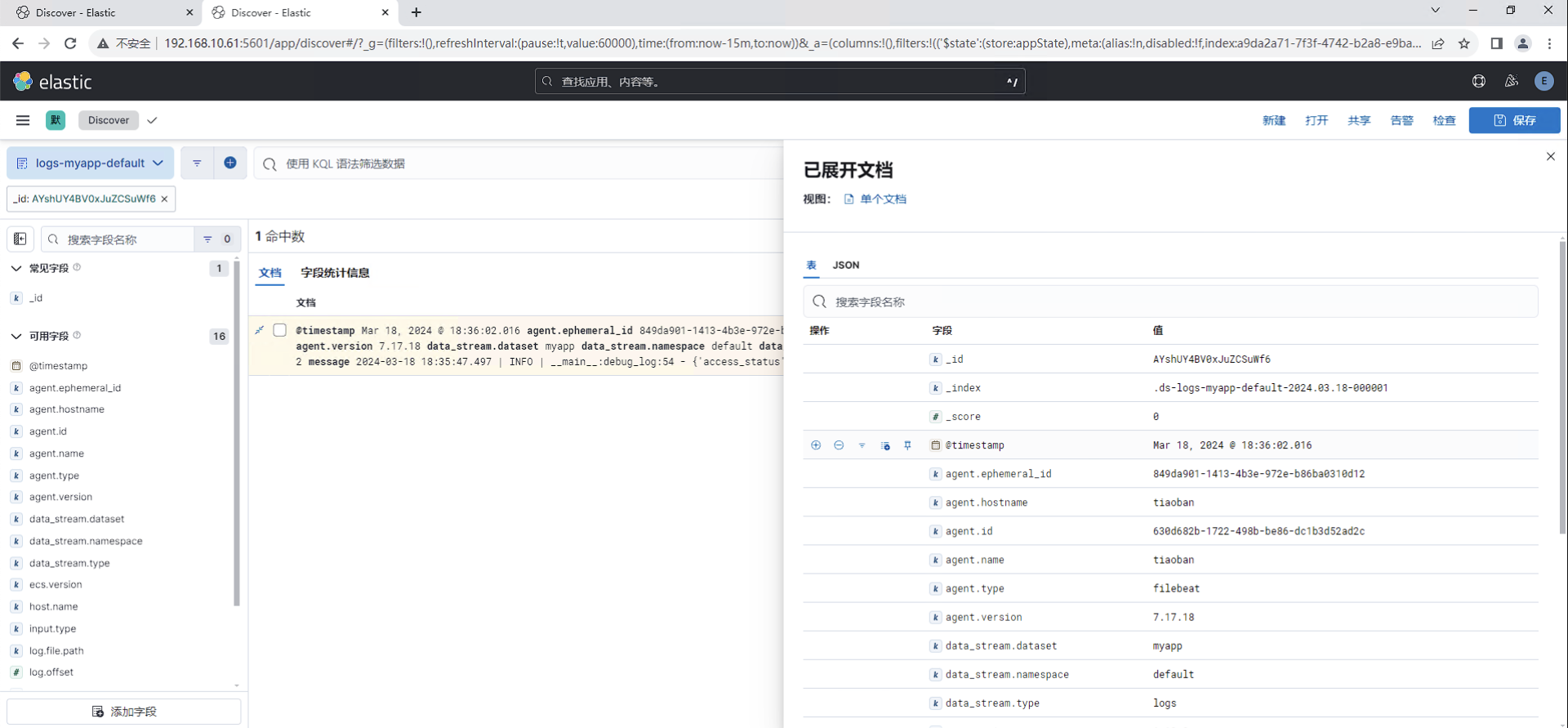
es7集群搜索id为"AYshUY4BV0xJuZCSuWf6"的文档,查看信息。
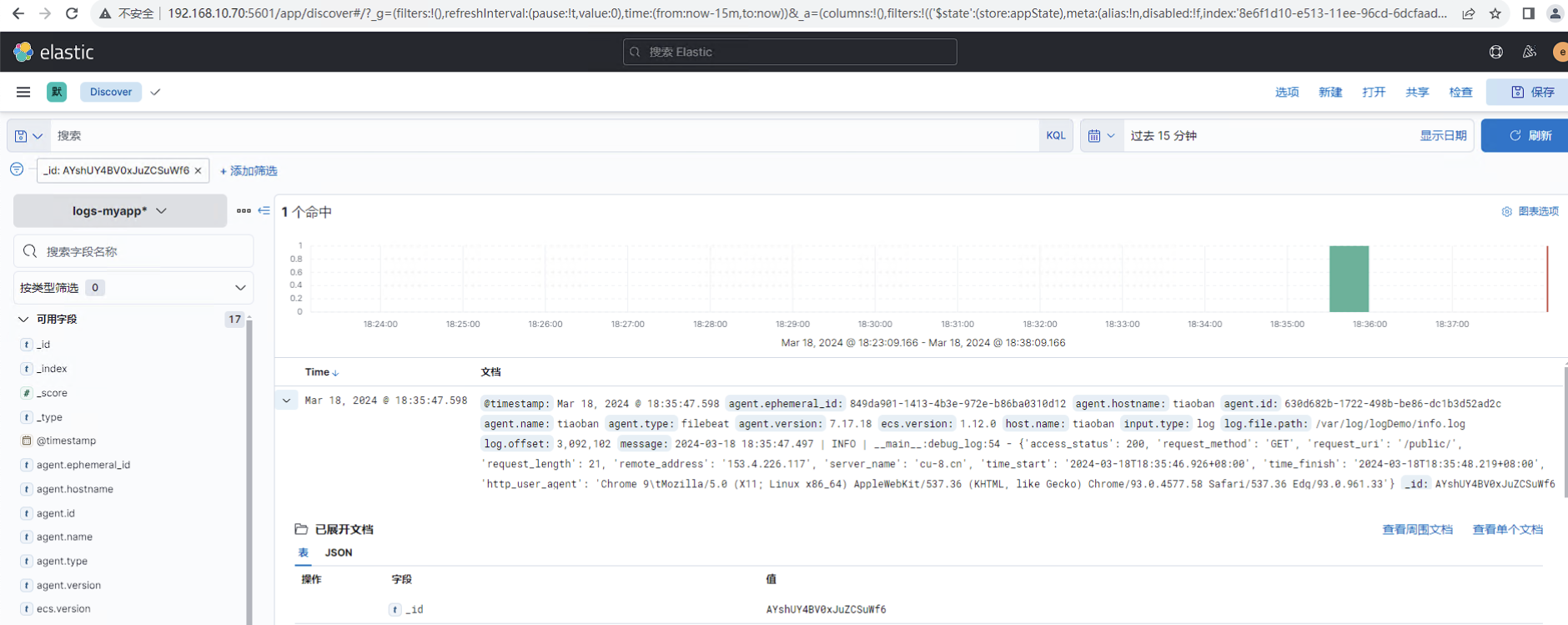
es8集群同样可以查询到id为"AYshUY4BV0xJuZCSuWf6"的文档,且内容完全一致。
方案总结
| 方案 | elasticsearch-dump | esm | reindex | logstash | snapshot |
|---|---|---|---|---|---|
| 基本原理 | 逻辑备份,类似mysqldump将数据一条一条导出后再执行导入 | ESM 是 medcl 开源的派生自:Elasticsearch Dumper 的工具,基于 go 语言开发。 | reindex 是 Elasticsearch 提供的一个 API 接口,可以把数据从一个集群迁移到另外一个集群 | 从一个集群中读取数据然后写入到另一个集群 | 从源集群通过Snapshot API 创建数据快照,然后在目标集群中进行恢复 |
| 网络要求 | 无网络互通要求 | 无网络互通要求 | 网络需要互通 | 网络需要互通 | 无网络互通要求 |
| 迁移速度 | 最慢 | 很慢 | 一般 | 很快 | 最快 |
| 适合场景 | 适用于数据量小的离线场景 | 适用于数据量小的离线场景 | 适用于数据量中等,在线迁移数据的场景 | 适用于数据量很大,实时数据传输的场景 | 适用于数据量特大,离线数据迁移的场景 |
| 配置复杂度 | 简单 | 简单 | 中等 | 中等 | 复杂 |
| 缺点 | 速度全宇宙最慢,没有之一 | 跨大版本不能迁移mapping,需要手动迁移 | 需要设置集群白名单,重启elasticsearch服务 | logstash对资源要求较高,建议单独的一台服务器运行。 | 在快照还原过程中无法修改分片数,分片数取决于源集群索引设置。 |
| 迁移时长(1100万条数据) | 3小时 | 1小时10分钟 | 15分钟 | 8分钟 | 2分钟 |
查看更多
微信公众号
微信公众号同步更新,欢迎关注微信公众号《崔亮的博客》第一时间获取最近文章。
博客网站
崔亮的博客-专注devops自动化运维,传播优秀it运维技术文章。更多原创运维开发相关文章,欢迎访问https://www.cuiliangblog.cn
这篇关于ES8生产实践——ES跨集群数据迁移方案测评的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








