本文主要是介绍Illumina Fastq Q-score,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Illumina Nextseq500 Miseq HiseqXten 测序仪 Q-score均采用下面的编码格式,仅作简要介绍。
Q-score
Q-score 在fastq中每个序列的第4行,代表测序错误的概率。
Quality Score Q(X) ## Error Probability P(~X)
Q40 ## 0.0001 (1 in 10,000)
Q30 ## 0.001 (1 in 1,000)
Q20 ## 0.01 (1 in 100)
Q10 ## 0.1 (1 in 10)
Q-score = -10 log10(P(~X))
Q-score 在 [0, 40] 范围, ASCII - 33
下图是Illumina 官方软件 bcl2fastq 给出的对应关系。
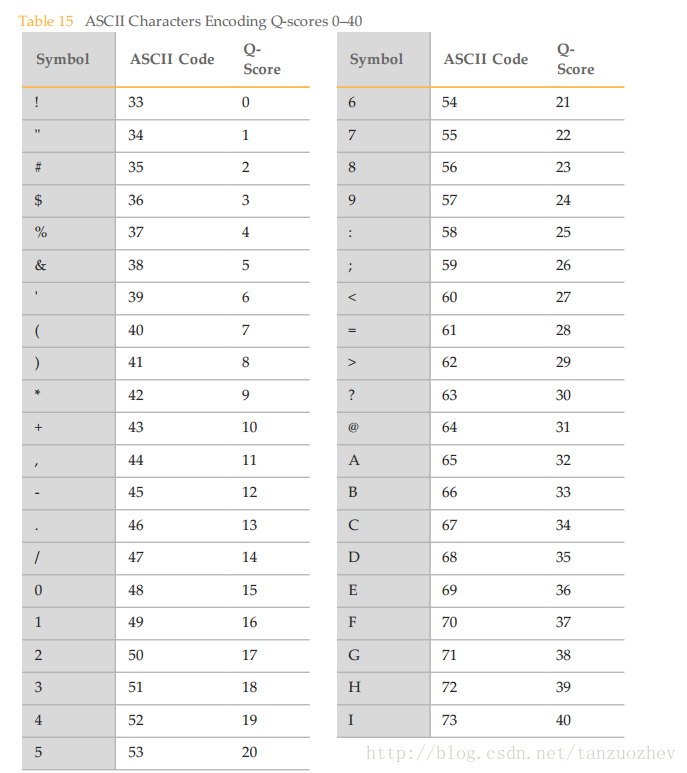
python 计算
可以采用 ord 和 chr 在字母和ASCII码直接转换
ord('!') # 33 Q-score 0
ord('I') # 73 Q-score 40 chr(33) # !
chr(77) # I这篇关于Illumina Fastq Q-score的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!