本文主要是介绍Python 导入Excel三维坐标数据 生成三维曲面地形图(体) 5-3、线条平滑曲面且可通过面观察柱体变化(三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境和包:
环境
python:python-3.12.0-amd64包:
matplotlib 3.8.2
pandas 2.1.4
openpyxl 3.1.2
scipy 1.12.0
代码:
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from scipy.interpolate import griddata
from matplotlib.colors import ListedColormap
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import font_manager
from matplotlib.image import imread
from matplotlib.widgets import Button
from tkinter import messagebox#解决中文乱码问题
plt.rcParams['font.sans-serif']=['kaiti']
plt.rcParams["axes.unicode_minus"]=False #解决图像中的"-"负号的乱码问题# 创建自定义颜色调色板
def create_custom_colormap(name, colors):colors = np.array(colors)cmap = plt.get_cmap(name)cmap.set_over(colors[-1])cmap.set_under(colors[0])cmap.set_bad(colors[0])return cmap# 定义一些颜色
#colors = ['red', 'blue', 'green', 'yellow', 'purple']
colors = ['red', 'orange', 'yellow', 'green', 'blue']
# 创建自定义颜色映射对象
my_colormap = create_custom_colormap('turbo', colors)
# 读取Excel文件
df = pd.read_excel('煤仓模拟参数41.xlsx')
#df = pd.read_excel('煤仓模拟参数222.xlsx')
#去除无效点
# 根据A列和B列分组,并将每组中C列的值更改为该组中C列的最小值
df['Z轴'] = df.groupby(['X轴', 'Y轴'])['Z轴'].transform('min')
#print('数量:',df)
# 提取x、y、z数据
x = df['X轴'].values
y = df['Y轴'].values
z = df['Z轴'].values
plt.rcParams['figure.facecolor'] = 'lightblue'
# 创建三维坐标轴对象
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 设置figure标题# 使用平滑曲面插值方法创建地形图(假设使用样条插值方法)
#smoothed_terrain = ax.scatter(x, y, z, cmap='viridis')# 使用griddata函数进行插值,这里使用最近邻插值法,你也可以选择其他的插值方法
# 插值后的数据用于绘制平滑曲面地形图
grid_x, grid_y = np.mgrid[min(x):max(x):100j, min(y):max(y):100j]
grid_z = griddata((x, y), z, (grid_x, grid_y), method='cubic')
# 设置颜色映射和透明度
cmap = plt.get_cmap('RdYlBu') # 选择颜色映射
norm = plt.Normalize(vmin=-5, vmax=5) # 标准化高度值
alpha = norm(grid_z).data # 计算透明度
colors = cmap(norm(grid_z).data) # 计算颜色值
# 使用平滑曲面插值后的数据绘制地形图
# 绘制地形图(camp:coolwarm,viridis,plasma,inferno,magma,cividis,rainbow)
cmap = ListedColormap(['blue', 'green', 'yellow', 'orange','Red'])
ax.contourf(grid_x, grid_y, grid_z, levels=300, cmap=my_colormap)
#ax.contourf(grid_x, grid_y, grid_z, levels=60, cmap='viridis')
# 绘制x-y,Z=16452的平面
grid_z1 = griddata((x, y), np.ones(x.shape) * 16452, (grid_x, grid_y), method='cubic')
ax.contourf(grid_x, grid_y, grid_z1,colors='blue')
# 生成圆柱数据,底面半径为r,高度为h。
# 查找列'X'的绝对值等于9000的行,并获取列'Z'中的最小值
h_min = df[(abs(df['X轴']) == 9000) & (df['Z轴'].notnull())]['Z轴'].min()
# 先根据极坐标方式生成数据
u1 = np.linspace(0, 2 * np.pi, 50) # 把圆分按角度为50等分
h1 = np.linspace(16650, h_min-200, 20) # 把高度9000均分为20份
x1 = np.outer(np.sin(u1), np.ones(len(h1))*9000) # x值重复20次
y1 = np.outer(np.cos(u1), np.ones(len(h1))*9000) # y值重复20次
z1 = np.outer(np.ones(len(u1)), h1) # x,y 对应的高度# Plot the surface
ax.plot_surface(x1, y1, z1, cmap=plt.get_cmap('Blues'))
ax.grid(True)# 添加颜色条
cbar = plt.colorbar(plt.imshow(grid_z, cmap=cmap), ax=ax)
cbar.set_label('Height')
# 读取背景图
img = imread('1.jpeg')
# 添加背景图
ax.imshow(img, alpha=0.5)
# 设置x轴的刻度间隔
ax.set_xticks(np.arange(-9000, 9000, 2500)) # 从-7500到7500,步长为2500# 设置y轴的刻度间隔
ax.set_yticks(np.arange(-9000, 9000, 2500)) # 从-7500到7500,步长为2500# 设置z轴的刻度间隔
#ax.set_zticks(np.arange(16452, 36316, 2500)) # 从10000到31000,步长为2500# 创建包含不规则刻度的数组
z_ticks = np.array([16452,18952,21452,23952,26452,28952,31452,33952,36316])# 设置z轴刻度间隔
ax.set_zlim([16452, 36316]) # 设置z轴的范围
ax.set_zticks(z_ticks) # 设置z轴刻度的值# 设置新的刻度列表
ax.set_zticks(z_ticks) # 设置新的刻度列表# 设置x轴和y轴的标签为空字符串,并隐藏它们
ax.set_xlabel('')
ax.set_ylabel('')
ax.set_xticks([])
ax.set_yticks([])
# 设置坐标轴的位置和方向
ax.spines['right'].set_color('none') # 隐藏右侧的坐标轴线
ax.spines['top'].set_color('none') # 隐藏顶部的坐标轴线
ax.spines['bottom'].set_color('none') # 隐藏右侧的坐标轴线
ax.spines['left'].set_color('none') # 隐藏顶部的坐标轴线
#计算面积,容积,最高料位等
h = df['Z轴'].mean()-16452#print(h)# 计算圆柱体的体积
#pi = np.pi
#V = np.pi * r**2 * h # 圆柱体体积公式:πr²h r 9000 h-16452 983.6 3000上下就是对的
#print(V)# 计算圆柱体的体积
r=9000
pi = np.pi
V = np.pi * r**2 * h # 圆柱体体积公式:πr²h r 9000 h-16452 983.6 3000上下就是对的
#print('V=',V)def mm3_to_m3(mm3):m3 = mm3 / (1000**3)return m3# 测试代码
mm3_value = V # 1立方米等于1000000立方毫米
m3_value = mm3_to_m3(mm3_value)
print(m3_value)m3_value_1=m3_value+983.6
print('体积=',m3_value_1)zl=1.5*m3_value_1
print('质量=',zl)
VP=m3_value_1/6022.72#6022.72为总桶的总体积
print('容积=',VP)# 找到该列的最大值和最小值
max_value = df['Z轴'].max()
min_value = df['Z轴'].min()
h=h+16342
# 打印结果
print("最高料位=",max_value)
print("最低料位=",min_value)
print("平均料位=",h)
# 添加标题和坐标轴标签
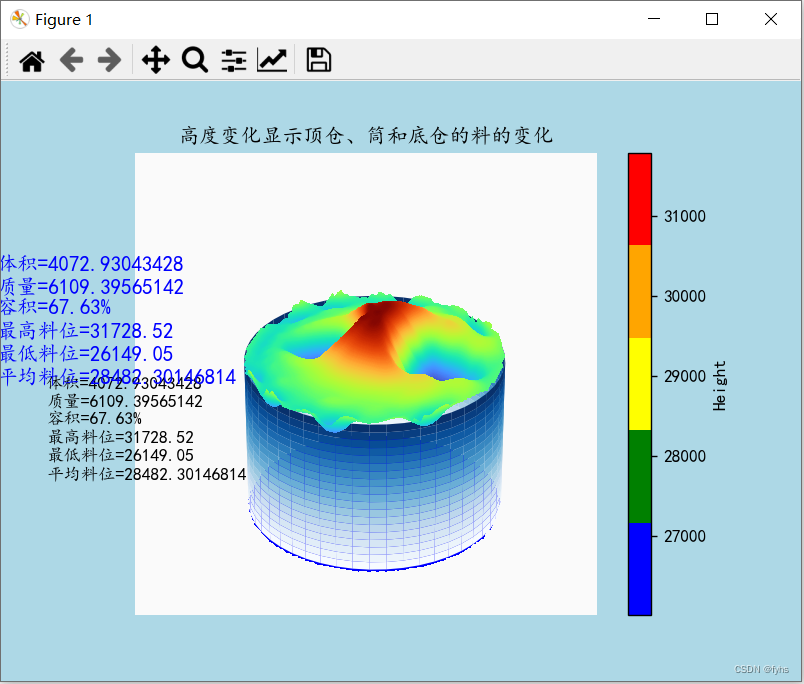
ax.set_title('高度变化显示顶仓、筒和底仓的料的变化')
# 在图形上添加文本
str = "体积="+np.array2string(m3_value_1)+"\n质量="+np.array2string(zl)+"\n容积="+"{:.2%}".format(VP)+"\n最高料位="+np.array2string(max_value)+"\n最低料位="+np.array2string(min_value)+"\n平均料位="+np.array2string(h)
ax.text(-28000,-5000,10000,str)
# 在指定位置添加文本
ax.text2D(-0.3, 0.5, str, transform=ax.transAxes, fontsize=12, color='b')
# 改变图形显示的角度
ax.view_init(elev=30, azim=-73)# 设置图形比例,使X、Y轴和面板底部重合
ax.set_aspect('equal', adjustable='box')
# 设置图形比例,使X、Z轴重合
ax.set_axis_off() # 关闭坐标轴plt.show()效果图:
资源下载(分享-->资源分享):
链接:https://pan.baidu.com/s/1UlP0lsma8OWchfV5kstEFQ
提取码:kdgr
这篇关于Python 导入Excel三维坐标数据 生成三维曲面地形图(体) 5-3、线条平滑曲面且可通过面观察柱体变化(三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





