本文主要是介绍论文复现:一种基于强化学习的车辆队列控制策略,用于减少交通振荡中的能量消耗,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文复现:一种基于强化学习的车辆队列控制策略,用于减少交通振荡中的能量消耗
文章目录
- 论文复现:一种基于强化学习的车辆队列控制策略,用于减少交通振荡中的能量消耗
- 预备工作
- SUMO安装
- pytorch
- 文章创新点
- 强化学习
- 环境设置(前车领航跟随式通信拓扑)
- 状态空间
- 动作空间
- 奖励函数
- 课程学习
- 训练结果
- 论文描述
- 自己的训练结果
- SUMO的配置说明
- SUMO结果可视化
- 代码
- 后记
论文原文地址:
A Reinforcement Learning-Based Vehicle Platoon Control Strategy for Reducing Energy Consumption in Traffic Oscillations
论文翻译:
论文翻译:一种基于强化学习的车辆队列控制策略,用于减少交通振荡中的能量消耗-CSDN博客
预备工作
SUMO安装
关键是在python中添加TraCI
首先找到traci的安装目录:sumo\tools
打开python的安装目录(或者anaconda安装目录)—> Lib —> site-packages,在该目录下新建traci.pth文件,在该文件中输入traci的安装目录。
参考sumo与python的接口——TraCI_python安装sumolib-CSDN博客
pytorch
pytorch版本1.12之前就行,需要安装cuda。
文章创新点
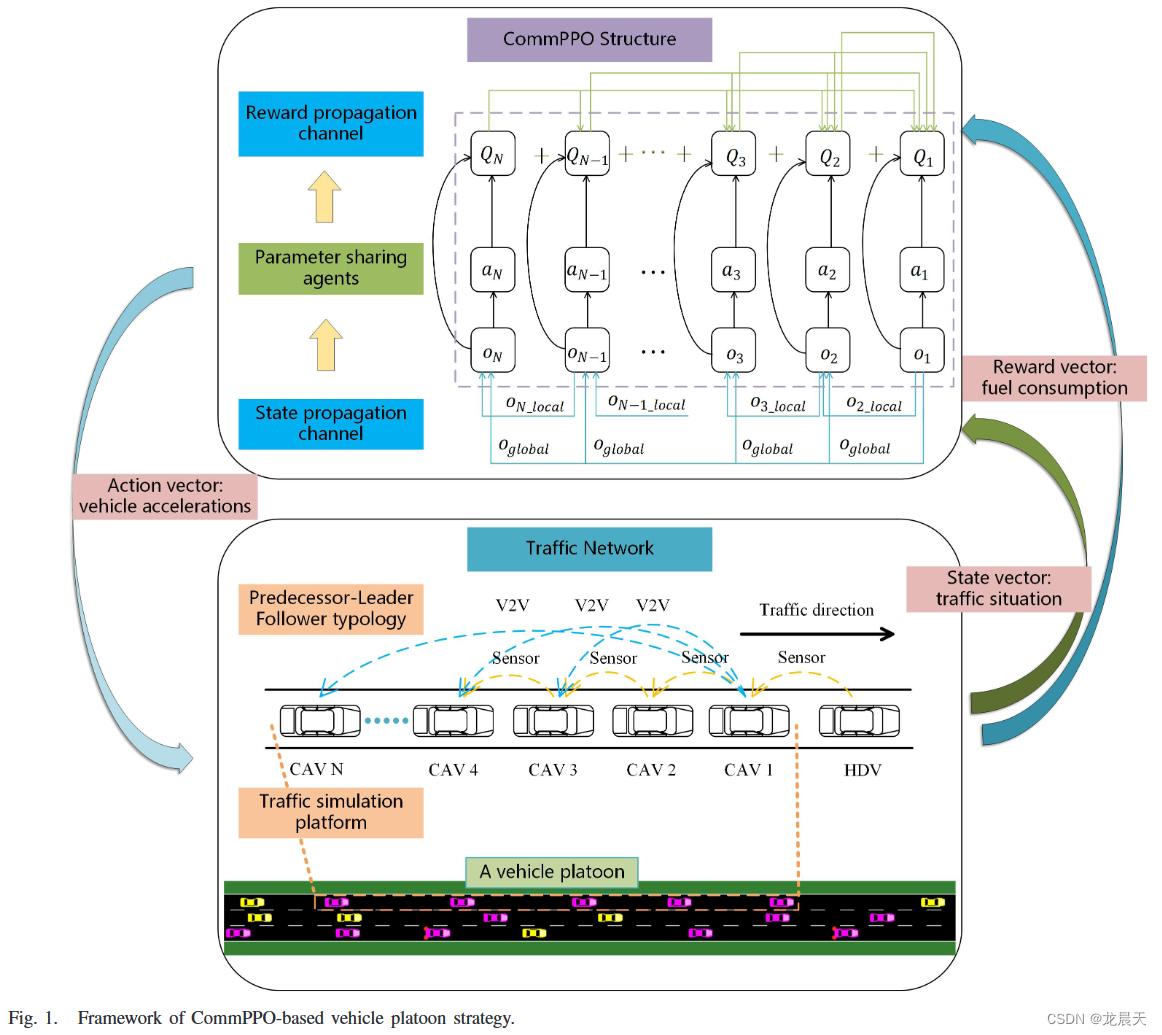
本文提出了一种通信近端策略优化(CommPPO)算法来控制车辆队列。主要贡献如下三点。
- 本研究构建了一个多智能体强化学习框架来控制车辆队列,以实现保证交通安全和驾驶效率的目标。
通过仔细平衡两个关键要素(交通安全和驾驶效率),所提出的基于强化学习的队列控制框架即使在联网自动驾驶车辆(CAV)和人类驾驶车辆(HDV)的混合交通中也能确保车辆队列的合理驾驶状态。我们需要较大的探索率来帮助产生更好的性能,但它通常会带来大量的碰撞,特别是在大型车辆队列中。因此,我们在开始阶段采用课程学习来训练小型队列并加快训练速度:首先学习简单的任务(即小型队列),然后基于该知识来解决困难的任务(即,一个更长/大的队列)。
- 设计了一种新颖的信息通信协议来增强智能体之间的合作,以提高多智能体系统的性能。
所提出的通信协议中有两个信息传输通道。一是状态传输通道:在充分观测的基础上,采用广泛使用的前车-领导跟随类型车辆队列,将精心选择的状态信息传输给智能体,解决了部分观测带来的非平稳问题,避免了信息传递效率低下。另一种是奖励传输通道:不直接采用局部或全局奖励,而是提出一种新的奖励传播通道,为每个智能体分配更明确和有代表性的奖励,避免“懒惰智能体”问题。
- 采用参数共享的强化学习结构来降低计算复杂度并控制具有可变智能体数量的智能体。
我们提出的CommPPO算法采用参数共享结构,其中每个智能体共享单个网络的权重,以降低大型系统中的计算复杂度。由于各种队列的动态,包括队列的分裂和合并,智能体的数量随着智能体在环境中的进出而变化。参数共享结构很好地处理了不同智能体使用一组参数的问题。
强化学习
环境设置(前车领航跟随式通信拓扑)
前车领航跟随式通信拓扑可能是车辆队列中使用最广泛的通信拓扑,本研究也采用这种协议来增强智能体之间的合作。
从图1的交通网络部分可以看出,一个拥有N辆CAV的队列跟随一辆HDV。假设:每个CAV都有一个车载传感器来检测其前身的速度和位置,2)V2V通信技术使领航的CAV能够向队列中的其他CAV广播信息。基于上述假设,将修改后的前车-领导追随类型应用于状态通信,并且CAV接收两种信息:
- 其前车的状态(黄色虚线)
- 其领航车的状态队列(蓝色虚线)。
在我们当前的研究中,主要重点是提出一个强化学习框架,该框架可以找到最佳的车辆队列控制策略以减少能源。因此,我们没有考虑通信故障。
状态空间
在CommPPO算法中,状态空间由反映队列的交通状态的几个变量来表示。对于 C A V i CAV_i CAVi,根据通信拓扑,状态向量由五个变量组成:1)HDV和CAV_i之间的速度差(前者减去后者);2) C A V i CAV_i CAVi与其前身 C A V i − 1 CAV_{i−1} CAVi−1之间的速度差(后者减去前者);3) C A V i CAV_i CAVi的速度;4) C A V i CAV_i CAVi与其前身 C A V i − 1 CAV_{i−1} CAVi−1之间的差距;5)序数i。值得一提的是,对于 C A V 1 CAV_1 CAV1,其前身是HDV,因此第一个值等于第二个值。
状态空间代码计算如下,除以10是为了限幅,防止其值过大反而学不到东西。
def state_calc(vehicle, position, speed, acc):state = [0] * 5state[0] = (speed[vehicle] - speed[vehicle + 1]) / 10state[1] = (speed[vehicle + 1] - Platoonsize_Max) / Platoonsize_Max # 这个有点小问题state[2] = (math.sqrt(max(position[vehicle] - position[vehicle + 1] - 5, 0)) - 20) / 20state[3] = (vehicle - Platoonsize_Max // 2) / Platoonsize_Maxstate[4] = acc[0] / 3return state原文的空间如下:
def calcstate(che,po,sp,acc,kexing):#自己速度是sp[che+1]
# print(che,acc,acc[che])s=[0]*5
# s[0]=(sp[0]-sp[che+1])/10s[0]=(sp[che]-sp[che+1])/10s[1]=(sp[che+1]-16)/16s[2]=(math.sqrt(max(po[che]-po[che+1]-5,0))-20)/20s[3]=(che-8)/16s[4]=acc[0]/3return s
基本一致。
动作空间
a)动作:每个智能体通过调整加速度来控制其对应的CAV,这被认为是基于CommPPO的队列控制策略中的动作。以往研究中推荐的CAV控制的总体原则是为驾驶员提供更舒适的驾驶体验。因此,之前的研究应用了 − 3 m / s 2 -3m/s^2 −3m/s2和 3 m / s 2 3m/s^2 3m/s2的加速度范围来进行CAV控制(参见[23]、[25]),我们的研究也采用了该加速度范围。
args.state_dim = 5args.action_dim = 1args.max_action = 3
通过args.max_action设置加速度范围。
奖励函数
奖励:本文旨在在保证交通安全和效率的情况下,最大限度地减少交通振荡场景下的燃料消耗。根据文献[8],频繁加减速的低速行驶状态是导致油耗高的主要因素。因此,智能体受到加速度惩罚,定义为实际加速度与加速度界限之比的平方范数。
在现实场景中,车辆不能为了燃油效率而完全牺牲交通安全或行驶速度。否则,可能会出现一些异常驾驶行为(例如撞车)。为了确保可接受的行驶速度并避免低速行驶状态,当前方间隙大于间隙阈值 L t h r e s h o l d L_{threshold} Lthreshold时添加惩罚。根据文献[39],当前方间隙大于120m时,车辆处于自由流动状态,因此将 L t h r e s h o l d L_{threshold} Lthreshold值设置为120m,以保证车辆保持跟车模式。
此外,为了避免碰撞,引入了最大冲突加速度。交通冲突是代表碰撞风险的交通安全指标[40],[41]。当交通冲突指数超过预设阈值时,就有可能发生交通冲突。因此,当发生交通冲突时,车辆可以主动减速以避免碰撞。避免碰撞减速度(DRAC)是现有研究中广泛使用的交通冲突指标[40],[42],特别是在评估追尾碰撞风险时。DRAC定义为后车为匹配前车速度以避免碰撞所需的最小减速度,如下:
DRAC i = { ( v i − v i − 1 ) 2 x i − 1 − x i − L i − 1 , if v i > v i − 1 0 , else \begin{align*} \text {DRAC}_{i}=\begin{cases} \displaystyle \frac {\left ({v_{i}-v_{i-1}}\right)^{2}}{x_{i-1}-x_{i}-L_{i-1}}, & \text {if } v_{i}>v_{i-1} \\ \displaystyle 0, & \text {else } \end{cases}\tag{6}\end{align*} DRACi=⎩ ⎨ ⎧xi−1−xi−Li−1(vi−vi−1)2,0,if vi>vi−1else (6)
DRAC基于反应时间的假设,CAV控制信号的计算时间在某种程度上可以被认为是CAV的反应时间。在现实场景中,如果DRAC超出其阈值,一辆CAV需要立即减速以避免碰撞。因此,我们引入DRAC作为反映交通安全状态的指标,它可以根据V2V通信技术获得的即时交通状态来计算,而无需了解人类驾驶员的反应。为了判断是否发生交通冲突,应用了最大阈值指标,即最大可用减速率(MADR)。如果DRAC>MADR,则认为后面的车辆与前车发生冲突。在文献中,本研究采用了广泛接受的MADR值 1.4 m / s 2 1.4m/s^2 1.4m/s2。因此,可以相应地计算出无交通冲突( a c o n f l i c t a_{conflict} aconflict)的最大加速度。当实际加速度 a a a大于 a c o n f l i c t a_{conflict} aconflict时添加惩罚。车辆的加速度被设置为 a a a和 a c o n f l i c t a_{conflict} aconflict的最小值。总体而言,当智能体脱离跟车模式或与前一个智能体发生交通冲突时,就会受到惩罚。智能体i的奖励值可以计算如下:
r i = { − ( a a max ) 2 − 1 , if gap > L threshold or a > a conflict − ( a a max ) 2 , else \begin{align*} {r_{i}}=\begin{cases} \displaystyle -\left ({\frac {a}{a_{\max }}}\right)^{2}-1, & {~\text {if }} \text {gap}>\text {$L_{\text {threshold}}$or } a>a_{\text {conflict}} \\ \displaystyle -\left ({\frac {a}{a_{\max }}}\right)^{2}, & \text {else} \end{cases}\!\!\! \\\tag{7}\end{align*} ri=⎩ ⎨ ⎧−(amaxa)2−1,−(amaxa)2, if gap>Lthresholdor a>aconflictelse
其中 a a a是车辆 i i i的瞬时加速度, g a p gap gap是车辆i前方的间隙, a max a_{\max} amax是加速度界限。
代码如下:
def reward_calc(vehicle, position, speed, acc, chongtu, chaoguo,acc_last = [], Platoonsize_Max = 16):'''作者开源的代码无法收敛,太痛苦了。'''# 与前车的车头距离headway = (position[vehicle] - position[vehicle + 1])energy = 0discount = 1# 折扣因子for i in range(Platoonsize_Max - vehicle):a = acc[vehicle + i + 1]energy += a ** 2 / 9 * discountdiscount *= 0.4if headway > 50:energy += headway / 50if chongtu == 1 or chaoguo == 1:# 发生冲突或者超车,奖励值 + 1energy += 1# 放缩方便训练?energy *= 100return -energy原文代码如下:
def calcreward(che,po,sp,acc,chongtu,chaoguo):#自己速度是sp[che+1]headway=(po[che]-po[che+1])energy=0discount=1for i in range(16-che):a=acc[che+i+1]energy+=a**2/9*discountdiscount*=0.4if headway>100:energy+=headway/100if chongtu==1 or chaoguo==1:energy+=1energy*=100return -energy
除了Actor部分之外,Critic部分也形成为参数共享结构。仅使用全局奖励的一个潜在缺点是“懒惰智能体”问题,即一个智能体学习有用的策略,而其他智能体则不鼓励学习[13]。事实上,每个智能体往往都有自己的目标来推动协作。如果简单地为每个智能体分配本地奖励,智能体可能会收到源自其他智能体的虚假奖励信号。因此,使用奖励传播通道提出了反映智能体之间相互作用的复合奖励(见图1)。更具体地说,在 N N N个智能体队列中,智能体 m m m影响其后续车辆,因此智能体 m m m的实际奖励可以通过以下等式计算:
R m = ∑ i = m N r i ∗ discount ( i − m ) \begin{equation*} R_{m}=\sum _{i=m}^{N}r_{i}*\text {discount}^{\left ({i-m}\right)} \tag{4}\end{equation*} Rm=i=m∑Nri∗discount(i−m)(4)
其中 r i r_i ri是智能体 i i i根据其流量状态计算的奖励, R m R_m Rm是智能体 m m m更新critic的奖励, d i s c o u n t discount discount是折扣因子。请注意,前车的影响可能与车辆顺序、速度、相对速度、加速度、距离等有关。我们假设它只受顺序的影响,因为影响评估不是本研究的主要重点。此外,前面的智能体的影响通过车辆串衰减并保持恒定的折扣因子。
说明:我的代码没有进行折扣奖励。需要可以参考原文(貌似有些坑)。
课程学习
强化学习的动作很可能在预定义的范围内随机分布,特别是在训练开始时。当实施随机动作来控制车辆队列时,车辆之间可能会发生碰撞,并且训练也会中断。在大多数情况下,交通碰撞会随着随机动作迅速发生,特别是在长/大规模车辆队列场景中,因此智能体很难学习最优策略。因此,为了更好的训练,本研究采用了课程学习方法:首先学习简单的任务,然后基于该知识来解决困难的任务。更具体地说,训练两个CAV队列,并且一开始只有两个智能体采样数据。当他们稳定移动后,训练一个由四个CAV队列组成的队列,然后是八个、十六个……通过简单的课程学习方法,智能体数量加倍,直到目标智能体数量。
算法1描述了基于单智能体PPO的参数共享训练方法。我们首先初始化演员和评论家网络并设置步长参数。智能体人数根据课程学习逐渐增加。在算法的每次迭代中,来自不同智能体( S S S、 A A A、 R R R和 S n e x t S_{next} Snext)的采样轨迹被收集在一起以更新网络中的参数。与分布式PPO(DPPO)[38]不同,每个工作人员根据自己的经验计算梯度并将其传递给中央PPO,CommPPO通过最大化以下目标来计算所有轨迹的梯度,以获得更稳健的性能:
L ( θ ) = E i ∼ [ 1 , m ] [ min ( r t ( θ ) A ^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] \begin{align*} L\left ({\theta }\right)=\mathbb {E}_{i \sim \left [{1,m}\right]}\left [{\min \left ({r_{t}\left ({\theta }\right) \hat {A}_{t}, \mathrm {clip}\left ({r_{t}\left ({\theta }\right), 1-\epsilon, 1+\epsilon }\right) \hat {A}_{t}}\right)}\right] \\\tag{5}\end{align*} L(θ)=Ei∼[1,m][min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]

课程学习的实现:
for episode in range(episode_max * 5):if episode // episode_max >= 0:Platoonsize = 1if episode // episode_max >= 1:Platoonsize = 2if episode // episode_max >= 2:Platoonsize = 4if episode // episode_max >= 3:Platoonsize = 8if episode // episode_max >= 4:Platoonsize = 16if episode % episode_max == 0:args.batch_size = Platoonsize * 16args.mini_batch_size = Platoonsizereplay_buffer = ReplayBuffer(args)ppo.batch_size = Platoonsize * 16ppo.mini_batch_size = Platoonsize
训练结果
论文描述
交通振荡就是所谓的走走停停波,这是高速公路和城市道路上的常见现象[8],[41]。走走停停的行为表示一辆车减速一段时间,然后加速到原来的速度。然后,其后续车辆依次进行走走停停的行为。这一系列走走停停的行为造成了大量的交通拥堵。此外,根据[8],频繁的加速和减速很大程度上导致了高燃油消耗。因此,我们尝试将CommPPO应用于交通振荡场景中,以实现燃料消耗最小化。
在此场景中,一辆领先的车辆后面跟着一个由16辆车组成的队列在单车道高速公路上装载(请注意,队列的大小逐渐增加)。初始车头时距和速度分别为 2 s 2s 2s和 20 m / s 20m/s 20m/s。前车保持原始速度40秒,然后减速30秒( − 1 m / s 2 −1m/s^2 −1m/s2),然后加速( 1 m / s 2 1m/s^2 1m/s2)一段时间,直到达到原始速度。然后,它保持速度直到模拟结束。总运行时间为150秒。值得一提的是,当模拟时间耗尽时,一集就会结束。
在SUMO中车辆由传统IDM模型控制的基线场景中,振荡很好地形成并持续传播到上游。每辆车都会经历紧急减速。相比之下,使用基于CommPPO的控制,车辆队列几乎可以抑制振荡。从轨迹可以看出,基于CommPPO控制的车辆主动减速到合适的速度,以保持前方相对较大的间隙,从而减少振荡的传播。结果表明,基于CommPPO控制的油耗分别为0.343和0.388Ah/km,降低了11.6%。然而,在BiCNet和PS-PPO控制的场景中,振荡仅得到部分抑制,车辆在经历振荡后试图与其前身保持更大的差距。结果表明,仅降低了2.79%和3.45%的油耗。原因可能是通讯CommPPO中的信道为智能体提供了更多有价值的信息,以便车辆可以知道领导者会做什么并主动采取行动。为了探究不同算法控制的车辆的真实行驶状态,最后一辆车的加速度曲线也绘制在图3中。发现仅在CommPPO控制的场景下,加速度的最大绝对值(0.95m/s)小于前车的初始绝对加速度(1m/s)。因此,交通波动得到抑制,车辆行驶平稳。
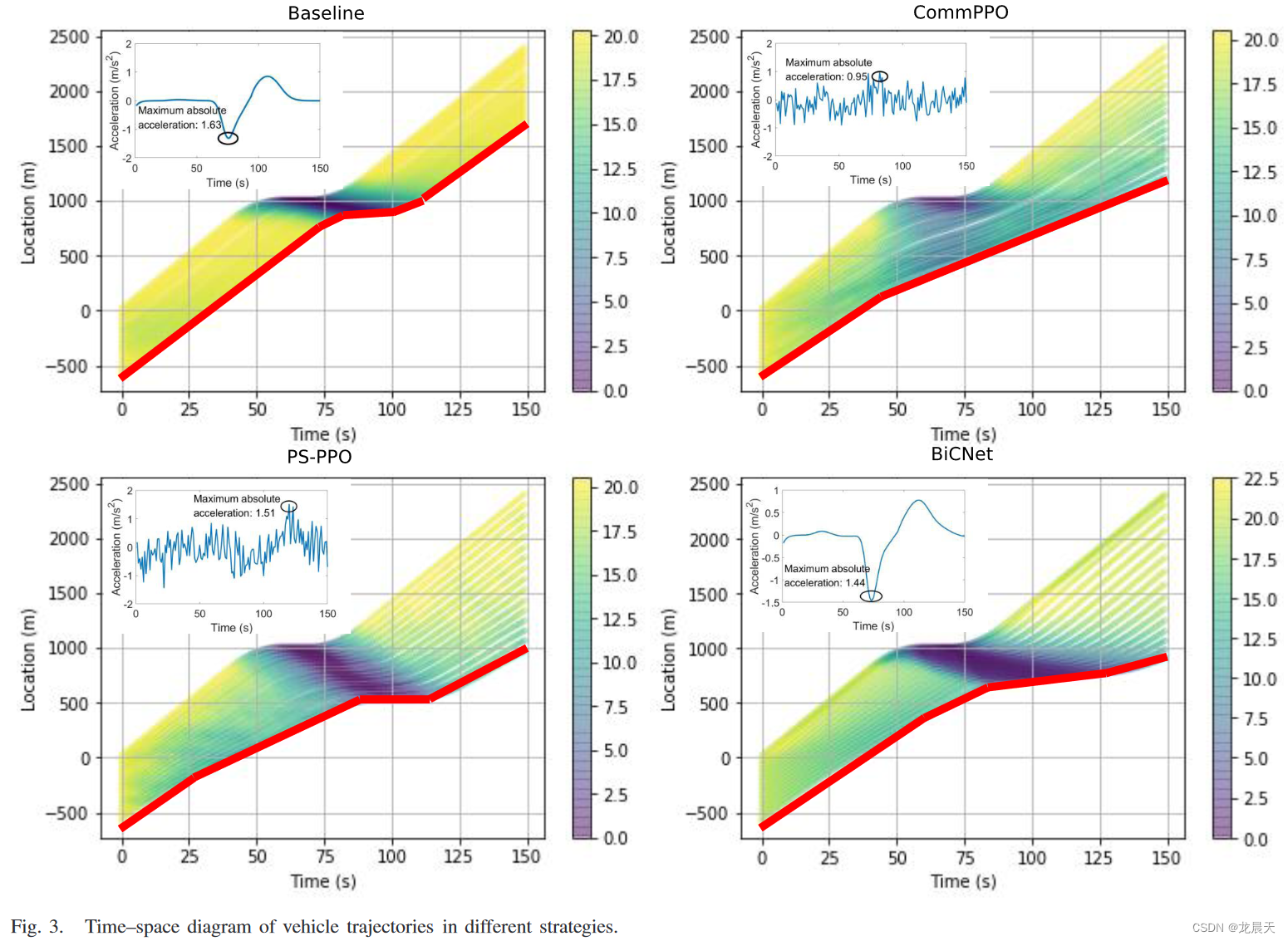
可以注意到,车辆在基准情况下恢复到原始状态,而在其他情况下则不会恢复到更省油的驾驶模式。没有必要总是保持最高速度(或理想速度限制),因为根据燃料消耗函数(相对于速度的凹曲线),相对较低的速度往往会带来较少的燃料消耗。因此,车辆不太可能在短时间内恢复初始速度。同时,为了缓解未来可能出现的振荡,车辆往往会与前车保持较大的差距,这导致了振荡前后交通状态的差异。实际上,强化学习是一种启发式算法,因此多智能体强化学习控制的系统并不具有均匀的平衡状态。换句话说,RL控制下的队列的车间间隙不一定恢复到初始值。在文献[8]提出的基于单智能体强化学习的振荡缓解策略中,振荡前后的交通状态也并不总是相同,这反映了强化学习算法的相同特性,即受扰动影响平衡状态可能会改变。
自己的训练结果
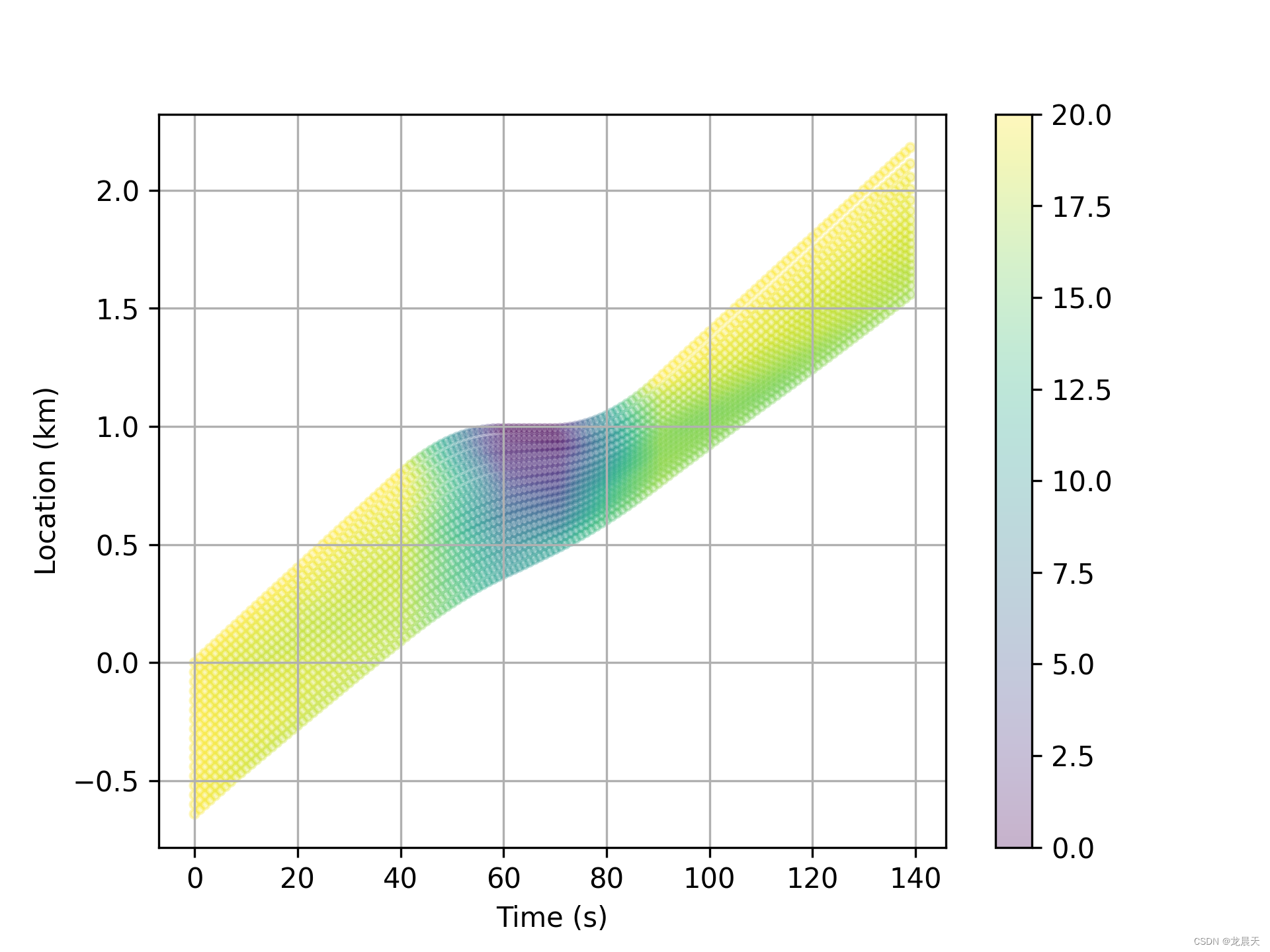
基本符合论文中描述的内容,后续跟随车辆减速程度没有之前的大,从而减少排放,达到节约能源的效果。
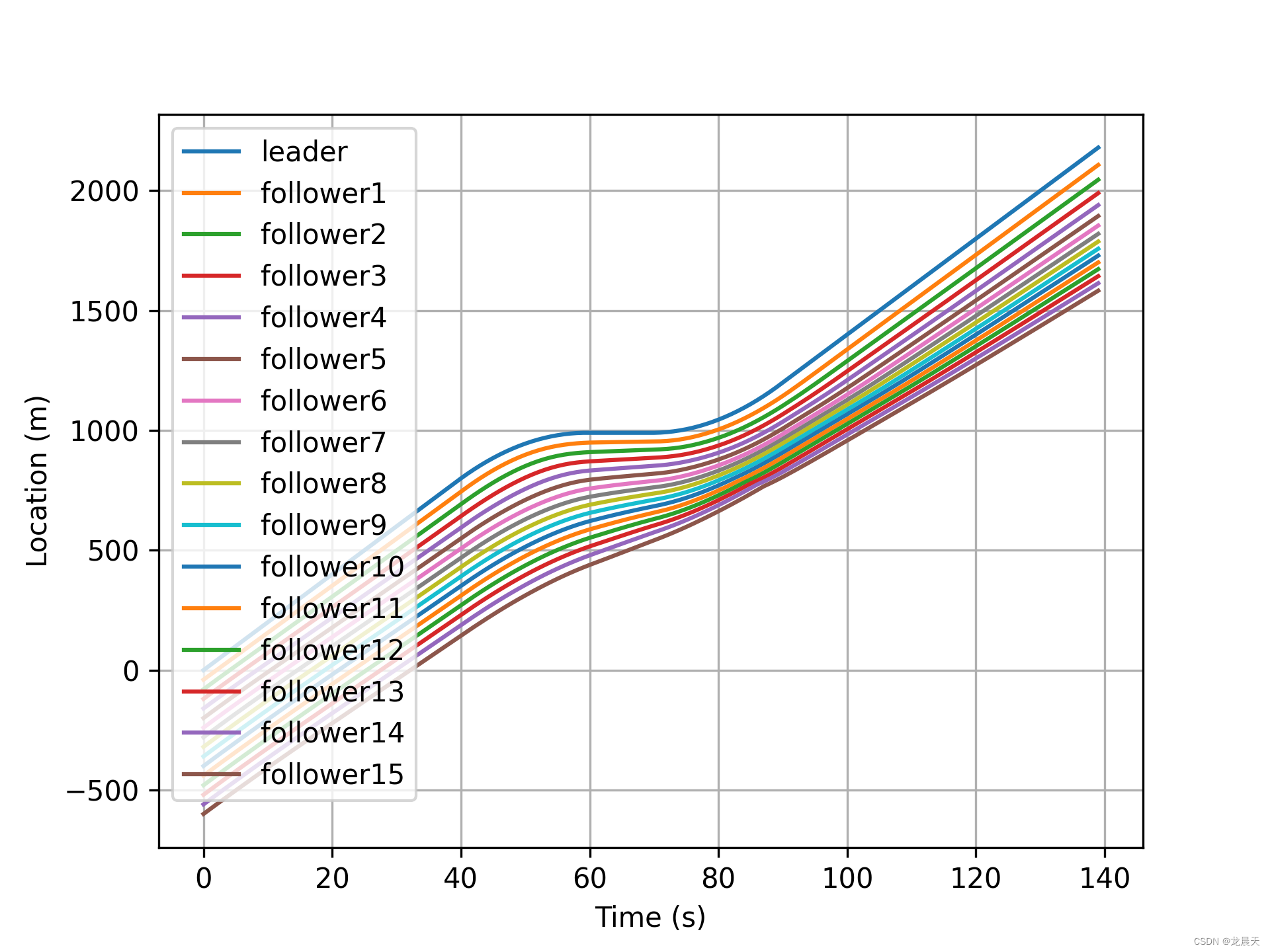
速度曲线如下:
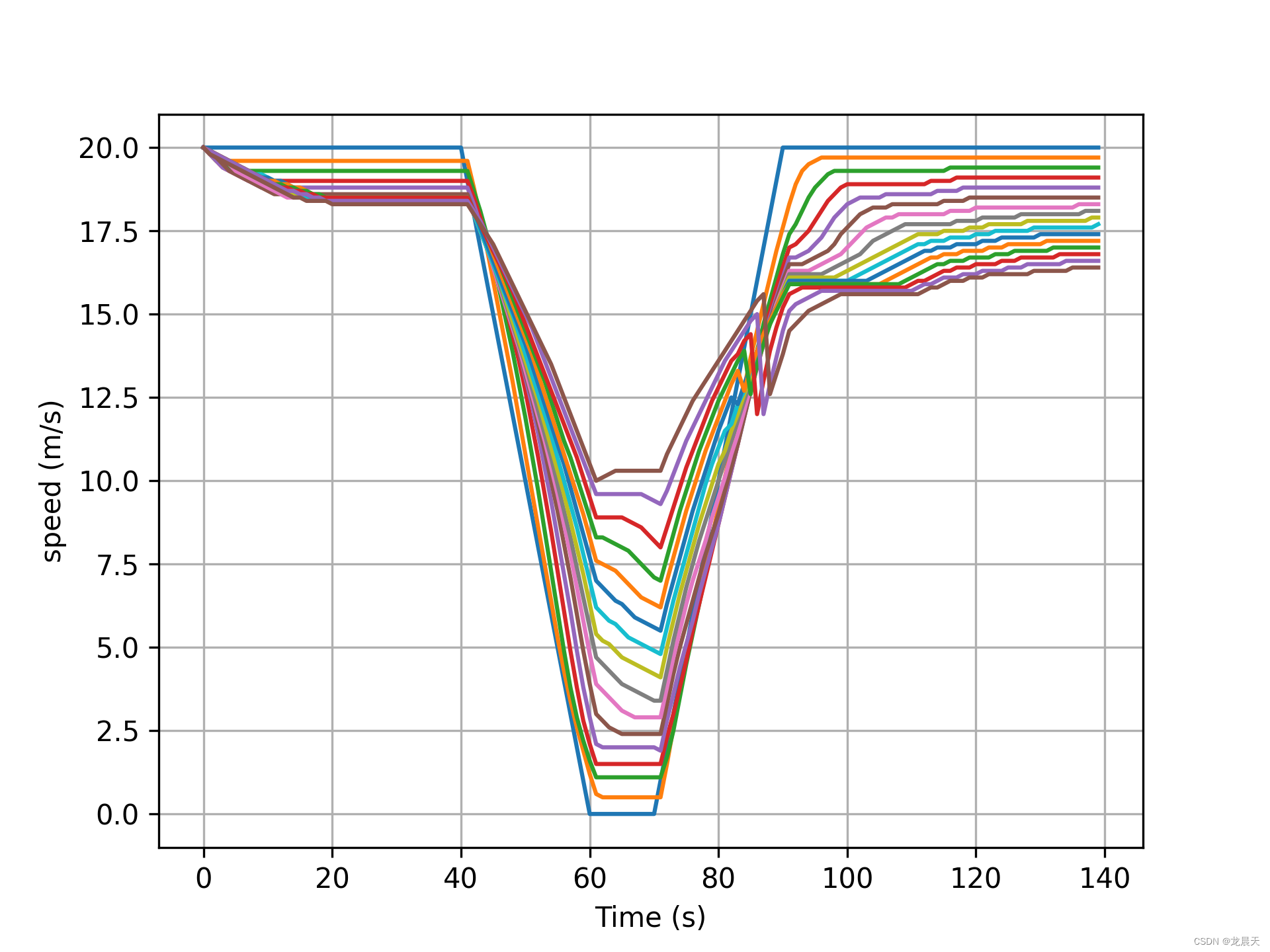
速度误差如下:
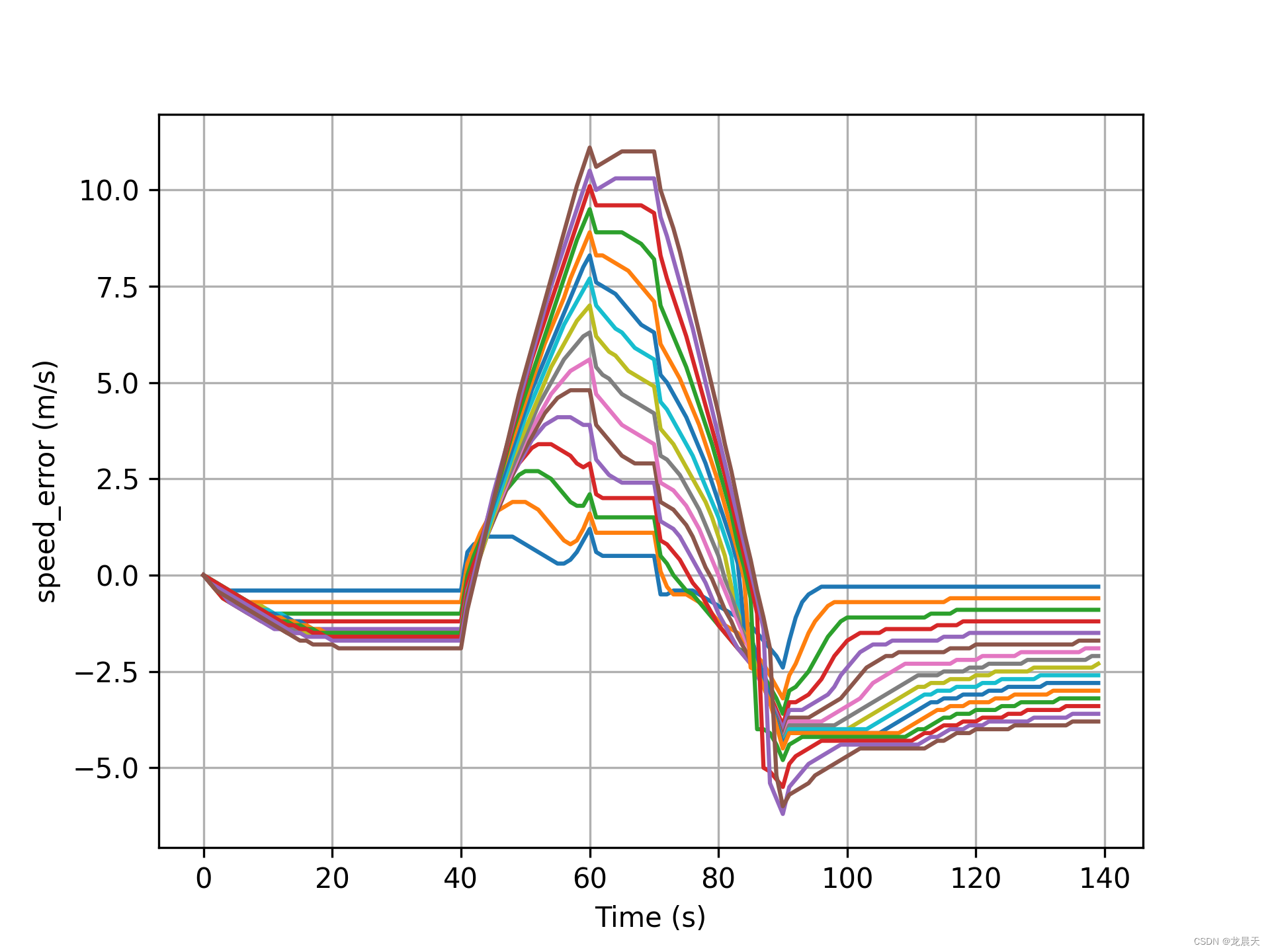
就不把距离误差放出来了,因为惨不忍睹。
训练代码如下:
def main(args, seed):m = 1200Af = 2.5Cd = 0.32rouair = 1.184g = 9.8speedmode = 6miu = 0.015con = []ave = 20madr = 1.4sumoBinary = checkBinary('sumo')# sumoBinary = checkBinary('sumo-gui')speed_init = 20leading = []for i in range(0, 40):leading.append(0)for i in range(40, 70):leading.append(-1)for i in range(70, 150):leading.append(1)for i in range(150, 300):leading.append(0)np.random.seed(seed)torch.manual_seed(seed)episode_reward = [0]args.state_dim = 5args.action_dim = 1args.max_action = 3args.max_episode_steps = 300replay_buffer = ReplayBuffer(args)ppo = PPO_continuous(args)state_norm = Normalization(shape=args.state_dim) # Trick 2:state normalizationif args.use_reward_norm: # Trick 3:reward normalizationreward_norm = Normalization(shape=1)elif args.use_reward_scaling: # Trick 4:reward scalingreward_scaling = RewardScaling(shape=1, gamma=args.gamma)# while total_steps < args.max_train_steps:for episode in range(episode_max * 5):if episode // episode_max >= 0:Platoonsize = 1if episode // episode_max >= 1:Platoonsize = 2if episode // episode_max >= 2:Platoonsize = 4if episode // episode_max >= 3:Platoonsize = 8if episode // episode_max >= 4:Platoonsize = 16if episode % episode_max == 0:args.batch_size = Platoonsize * 16args.mini_batch_size = Platoonsizereplay_buffer = ReplayBuffer(args)ppo.batch_size = Platoonsize * 16ppo.mini_batch_size = PlatoonsizePosition = [0] * (Platoonsize + 1)Speed = [0] * (Platoonsize + 1)Acc = [0] * (Platoonsize + 1)position_plot = []speed_plot = []acc_plot = []time_plot = []done = Falseconsumption = 0distance = 0reward_ave = 0# traci.start([sumoBinary, "-c", "car_str.sumocfg"])traci.start([sumoBinary, "-c", "car_str_16.sumocfg"])state = [[] for i in range(Platoonsize + 1)]reward = [[] for i in range(Platoonsize + 1)]action = [[] for i in range(Platoonsize + 1)]action_logprob = [[] for i in range(Platoonsize + 1)]state_next = [[] for i in range(Platoonsize + 1)]buffer_reward = [[] for i in range(Platoonsize + 1)]# 初始化先跑一秒,才能读到车辆 # 相当于reset环境traci.simulationStep()exist_list = traci.vehicle.getIDList()for car in exist_list:ind = exist_list.index(car)if ind <= Platoonsize:traci.vehicle.setSpeedMode(car, speedmode)Position[ind] = traci.vehicle.getPosition(car)[0]Speed[ind] = round(traci.vehicle.getSpeed(car), 1)Acc[ind] = traci.vehicle.getAcceleration(car)accelerate_accepted = [3] * (Platoonsize + 1)for step in range(step_max):for i in range(Platoonsize + 1):position_plot.append(Position[i] / 1000)speed_plot.append(Speed[i])time_plot.append(step)# 得到限定加速度区间for i in range(Platoonsize):if Speed[i] - 3 < Speed[i + 1]:# 前车速度小于后车速度3,就是说后车加速度3的话可能碰撞 gap<0就要减速gap = Position[i] - Position[i + 1] - 5 - Speed[i + 1] + max(Speed[i] - 3, 0)if gap < 0:amax = -3else:amax = min(gap / 3, math.sqrt(madr * gap)) + Speed[i] - Speed[i + 1] - 3amax = np.clip(amax, -3, 3)else:amax = 3accelerate_accepted[i + 1] = amaxacc_matrix = [0] * (Platoonsize + 1)# 状态值获取for i in range(1, Platoonsize + 1):state[i].append(state_calc(i - 1, Position, Speed, Acc))if args.use_state_norm:for i in range(1, Platoonsize + 1):state[i][-1] = state_norm(state[i][-1])if args.use_reward_scaling:reward_scaling.reset()for i in range(1, Platoonsize + 1):# 这里一定要是-1,因为状态是存储了多个时间步的act, act_log_prob = ppo.choose_action(np.array(state[i][-1]))if args.policy_dist == "Beta":act = 3 * (act - 0.5) * args.max_action # [0,1]->[-max,max][-3,3]action[i].append(act)action_logprob[i].append(act_log_prob)for i in range(1, Platoonsize + 1):acc_matrix[i] = action[i][-1][0]pos_beyond = [0] * (Platoonsize + 1)pos_conflict = [0] * (Platoonsize + 1)# 作者在原文这里添加了领航车的速度处理speed_next = np.clip(Speed[0] + leading[step], 0, speed_init)traci.vehicle.setSpeed(exist_list[0], speed_next)for i in range(1, Platoonsize + 1):# 他是按照倒立摆的DPPO模板改的,里面最大输出动作是2,要输出最大加速度在-3到3之间,所以要乘以1.5accc = min(acc_matrix[i], accelerate_accepted[i])if acc_matrix[i] > accelerate_accepted[i] + 0.5:# 这里应该就是a_conflictpos_beyond[i] = 1speed_next = np.clip(Speed[i] + accc, 0, 35)if i < Platoonsize + 1:# 前期碰撞先设置固定加速度,防止碰撞后无法进行下一步traci.vehicle.setSpeed(exist_list[i], speed_next)Acc_last = AccPosition = [0] * (Platoonsize + 1)Speed = [0] * (Platoonsize + 1)Acc = [0] * (Platoonsize + 1)traci.simulationStep()exist_list = traci.vehicle.getIDList()if 'a' not in exist_list:traci.close()#这里要提前结束了if episode % episode_max == 0:episode_reward[0] = reward_ave / step / Platoonsizeelse:reward_ave = reward_ave / step / Platoonsize * 0.8 + episode_reward[-1]*0.2 # 让曲线更平滑episode_reward.append(reward_ave)breakfor car in exist_list:ind = exist_list.index(car)# print(car)if ind <= Platoonsize:Position[ind] = traci.vehicle.getPosition(car)[0]Speed[ind] = round(traci.vehicle.getSpeed(car), 1)Acc[ind] = traci.vehicle.getAcceleration(car)for i in range(1, Platoonsize + 1):# 这里判断是否发生碰撞,碰撞的话车会消失,所以一般要结束进程了,或许前期可以通过算法挽回以下,让他跑更多的时间步if i > 0 and (Position[i] > Position[i - 1] - 5 or Position[i] < -10000):pos_conflict[i] = 1# 下一时刻状态值获取for i in range(1, Platoonsize + 1):state_next[i].append(state_calc(i - 1, Position, Speed, Acc))for i in range(1, Platoonsize + 1):reward[i].append(reward_calc(i - 1, Position,Speed, Acc,pos_beyond[i], pos_conflict[i],Acc_last, Platoonsize))if args.use_state_norm:for i in range(1, Platoonsize + 1):state_next[i][-1] = state_norm(state_next[i][-1])if args.use_reward_norm:reward[i][-1] = reward_norm(reward[i][-1])elif args.use_reward_scaling:reward[i][-1] = reward_scaling(reward[i][-1])if step == step_max - 1:done = Trueif done and sum(pos_conflict) == 0:dw = Trueelse:dw = False# for i in range(1, Platoonsize + 1):# buffer_reward[i].append((reward[i][-1] + ave) / ave)# reward_ave += buffer_reward[i][-1]for i in range(1, Platoonsize + 1):replay_buffer.store(state[i][-1],action[i][-1],action_logprob[i][-1],reward[i][-1],state_next[i][-1],dw, done)if replay_buffer.count >= args.batch_size:ppo.update(replay_buffer, episode)replay_buffer.count = 0if sum(pos_conflict) > 0:traci.close()sys.stdout.flush()print('车辆发生碰撞')print(step, pos_conflict)if episode % episode_max == 0:episode_reward[0] = reward_ave / step / Platoonsizeelse:reward_ave = reward_ave / step / Platoonsize * 0.8 + episode_reward[-1]*0.2 # 让曲线更平滑episode_reward.append(reward_ave)breakif step >= step_max - 1:# 当达到最大步数前 领航车可能会消失,所以 直接关sumotraci.close()# reward_ave = reward_ave / step_max / Platoonsize# episode.append(reward_aveif episode % episode_max == 0:episode_reward[0] = reward_ave / step_max / Platoonsizeelse:reward_ave = reward_ave / step_max / Platoonsize * 0.8 + episode_reward[-1]*0.2 # 让曲线更平滑episode_reward.append(reward_ave)breakif episode % 10 == 0:# plt.ion()plt.figure(0)plt.scatter(time_plot, position_plot, c=speed_plot, s=10, alpha=0.3)plt.colorbar()plt.xlabel('Time (s)')plt.ylabel('Location (km)')plt.grid(True)# plt.show()mkfile_time = datetime.datetime.strftime(datetime.datetime.now(), '%Y%m%d%H%M%S') # 这里是引用时间plt.savefig('.\\output\\Location time{}.png'.format(mkfile_time), dpi=300) # 分别创建文件夹,分别储存命名图片plt.close('all')if (episode+1) % episode_max ==0:# plt.ion()plt.figure(1)plt.plot(np.arange(len(episode_reward)),episode_reward)plt.xlabel('episode')plt.ylabel('reward')plt.grid(True)# plt.show()mkfile_time = datetime.datetime.strftime(datetime.datetime.now(), '%Y%m%d%H%M%S') # 这里是引用时间plt.savefig('.\\output\\Reward episode{}.png'.format(mkfile_time), dpi=300) # 分别创建文件夹,分别储存命名图片episode_reward = [0]replay_buffer.count = 0plt.close('all')if episode % 10 == 0:ppo.save_model()
说明:直接一路走到黑感觉中途很容易崩(训练发散了)
def train_once(arg,seed,Platoonsize):建议一步步地来。(当然有可能由于我奖励函数没弄好)。
SUMO的配置说明
SUMO的车辆都设置为内置的IDM模式,初始车辆间距为20m,初始速度也为20m/s.
值得一提的是,我不是用设置领航车的方法来实现领航车辆减速的。
原文作者是直接设置,我是通过在SUMO中添加一个停止区实现停车过程。
<stop lane="E0_0" startPos="1800.00" endPos="1810.00" duration="10.00"/>
rou文件如下所示:
<?xml version="1.0" encoding="UTF-8"?><!-- generated on 2022-11-17 16:21:11 by Eclipse SUMO netedit Version 1.15.0
--><routes><!-- VTypes --><vType id="DEFAULT_PEDTYPE" vClass="pedestrian"/><vType id="IDM" maxSpeed="33.00" vClass="ignoring" carFollowModel="IDM"/><!-- Vehicles, persons and containers (sorted by depart) --><trip id="a" type="IDM" depart="0.00" departPos="1000.00" departSpeed="20.00" color="red" from="E0" to="E0"><stop lane="E0_0" startPos="1800.00" endPos="1810.00" duration="10.00"/>
<!-- <stop lane="E0_0" startPos="2500.00" endPos="2510.00" speed="5.00"/>--></trip><trip id="b.0" type="IDM" depart="0.00" departPos="960.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="b.1" type="IDM" depart="0.00" departPos="920.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="b.2" type="IDM" depart="0.00" departPos="880.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="b.3" type="IDM" depart="0.00" departPos="840.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="b.4" type="IDM" depart="0.00" departPos="800.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="b.5" type="IDM" depart="0.00" departPos="760.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="b.6" type="IDM" depart="0.00" departPos="720.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="b.7" type="IDM" depart="0.00" departPos="680.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="c.0" type="IDM" depart="0.00" departPos="640.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="c.1" type="IDM" depart="0.00" departPos="600.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="c.2" type="IDM" depart="0.00" departPos="560.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="c.3" type="IDM" depart="0.00" departPos="520.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="c.4" type="IDM" depart="0.00" departPos="480.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="c.5" type="IDM" depart="0.00" departPos="440.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="c.6" type="IDM" depart="0.00" departPos="400.00" departSpeed="20.00" color="green" from="E0" to="E0"/><trip id="c.7" type="IDM" depart="0.00" departPos="360.00" departSpeed="20.00" color="green" from="E0" to="E0"/>
</routes>net文件如下所示:
<?xml version="1.0" encoding="UTF-8"?><net version="1.9" junctionCornerDetail="5" limitTurnSpeed="5.50" ><location netOffset="0.00,0.00" convBoundary="-1000.00,0.00,2500.00,0.00" origBoundary="10000000000.00,10000000000.00,-10000000000.00,-10000000000.00" projParameter="!"/><edge id="E0" from="J0" to="J1" priority="-1"><lane id="E0_0" index="0" speed="25.00" length="3500.00" shape="-1000.00,-1.60 2500.00,-1.60"/></edge><junction id="J0" type="dead_end" x="-1000.00" y="0.00" incLanes="" intLanes="" shape="-1000.00,0.00 -1000.00,-3.20"/><junction id="J1" type="dead_end" x="2500.00" y="0.00" incLanes="E0_0" intLanes="" shape="2500.00,-3.20 2500.00,0.00"/></net>严谨一点按照论文中的来。
在longitudinalmodel方面,由于SUMO主要用于研究车辆的外部行为、多车交互和交通流,对于单个车辆建模精度要求不高,可以近似看作质点,采用比较简单的car-followingmodel(跟车模型)来描述车辆速度和位置变化规律。
值得一提的是SUMO中的车辆的纵向运动学是白箱模型(应该是),就是啥都没有,要做更加复杂的模型的话,需要我们之间写出一个更复杂动力学环境,但是这样做的话,没必要用SUMO了,SUMO用来最终可视化就行了。
简单来说SUMO提供的模型是简单的一阶、二阶的牛顿动力学。(从我画的曲线可以看出)。
单积分模型是最简单的模型,它以车速为控制输入,以位置为单独状态,即
p ˙ i ( t ) = u i ( t ) {\dot{p}}_{i}(t)\!=\!u_{i}(t) p˙i(t)=ui(t)
式中,控制输入 u i ( t ) u_{i}(t) ui(t)是每一辆车的速度。
假设节点运动学为点集合,从而产生双积分模型:
{ p ˙ i ( t ) = v i ( t ) v ˙ i ( t ) = u i ( t ) \left\{{\dot{p}}_{i}(t)=v_{i}(t)\atop{\dot{v}}_{i}(t)=u_{i}(t)\right. {v˙i(t)=ui(t)p˙i(t)=vi(t)
SUMO结果可视化

代码
论文代码原作者:
CommPPO
论文代码复现:
CommPPO-for-platoon-by-pytorch:
强化学习训练框架:
来自这位大佬写的影响PPO算法性能的10个关键技巧
他开源了个训练框架,大家可以看一下:
DRL-code-pytorch
后记
很久之前复现的一篇文章,原论文的作者开源的代码跑不通(显然开源的代码写得比较随意tensorflow框架的,估计是中间探索的一个版本),就造着他提供的部分代码的思路用Pytorch,大体上还是实现论文中的部分内容。torch1.12之前应该都能实现。
现在不做这个方向了(已经很久没做了),所以分享出来,给大家提供一个思路。
代码改的稀烂,参考就好,不能提供很多有用的帮助。
这篇关于论文复现:一种基于强化学习的车辆队列控制策略,用于减少交通振荡中的能量消耗的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







