本文主要是介绍100%开源大模型OLMo:代码/权重/数据集/训练全过程公开,重定义AI共享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
近日,艾伦人工智能研究所联合多个顶尖学术机构发布了史上首个100%开源的大模型“OLMo”,这一举措被认为是AI开源社区的一大里程碑。OLMo不仅公开了模型权重,还包括了完整的训练代码、数据集和训练过程,为后续的开源工作设立了新的标准。这一开源模型的推出,无疑将极大促进自然语言处理(NLP)技术的发展和研究。
-
Huggingface模型下载:https://huggingface.co/allenai/OLMo-7B
-
AI快站模型免费加速下载:https://aifasthub.com/models/allenai

OLMo模型的创新之处
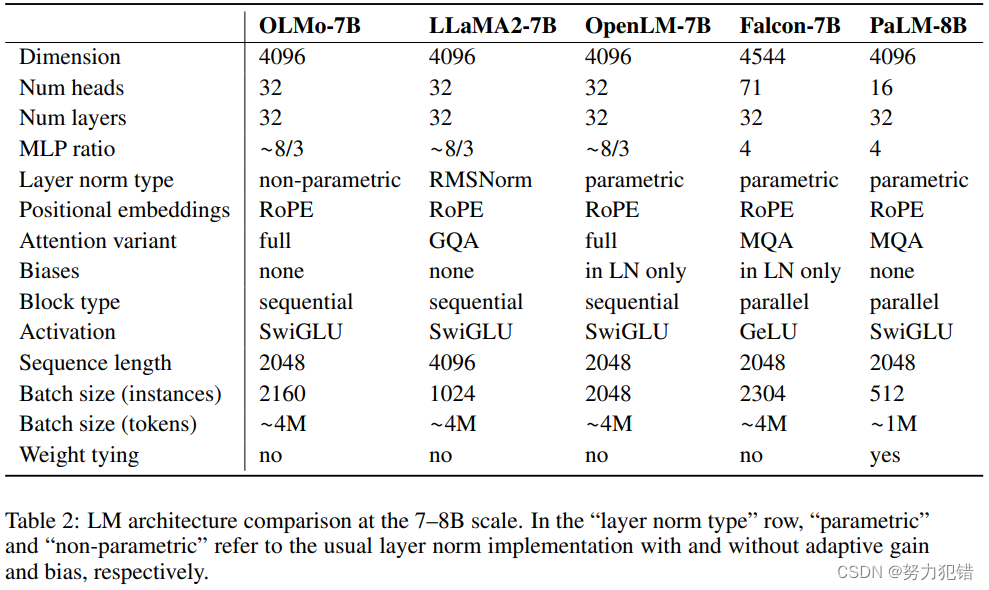
OLMo模型基于decoder-only的Transformer架构,采用了PaLM和Llama使用的SwiGLU激活函数,引入了旋转位置嵌入技术(RoPE),并改进了基于字节对编码(BPE)的分词器,以减少模型输出中的个人可识别信息。此外,该模型还采用了不使用偏置项的策略,以增强模型的稳定性。
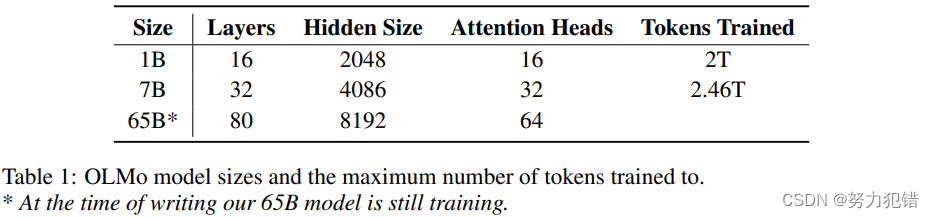
开源内容的全面性
OLMo的开源内容包括了模型的所有相关资料:
-
模型权重和训练代码:提供了四个不同架构、优化器和训练硬件体系下的7B大小的模型,以及一个1B大小的模型。
-
预训练语料库:包含高达3T token的开源语料库,及其生成代码。
-
评估工具套件:包括每个模型训练过程中每1000步中包含的超过500个的检查点以及评估代码。
性能评估
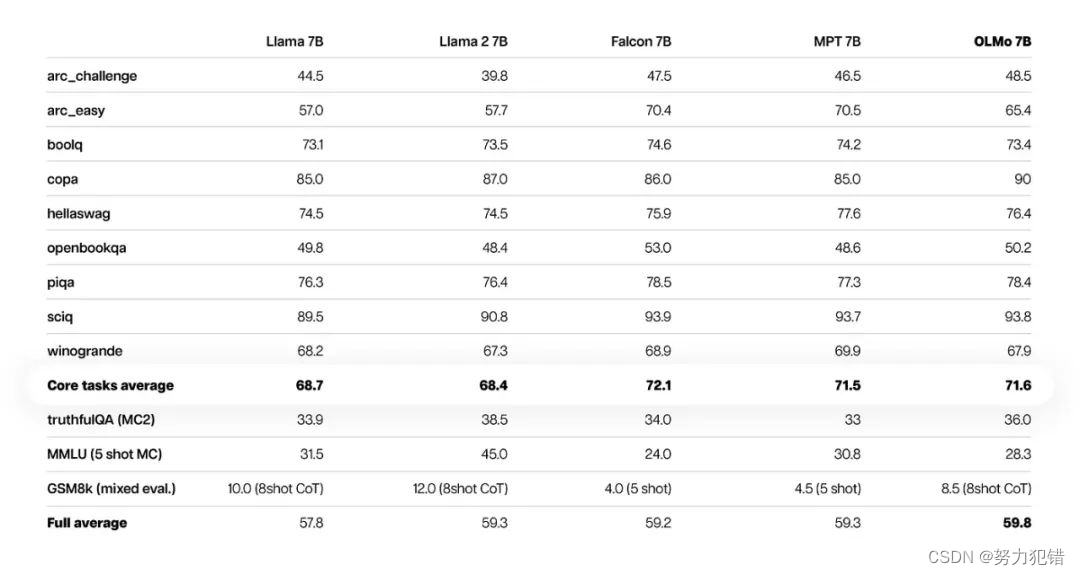
从评估结果来看,OLMo-7B模型在多个核心任务上的准确率呈现上升趋势,显示了良好的性能。尤其是在生成任务或阅读理解任务上,OLMo-7B甚至超过了Llama 2等同类开源模型,尽管在某些热门的问答任务上表现略逊。
在很多生成任务或阅读理解任务(例如truthfulQA)上,OLMo-7B都超过了Llama 2,但在一些热门的问答任务(如MMLU或Big-bench Hard)上表现则要差一些。
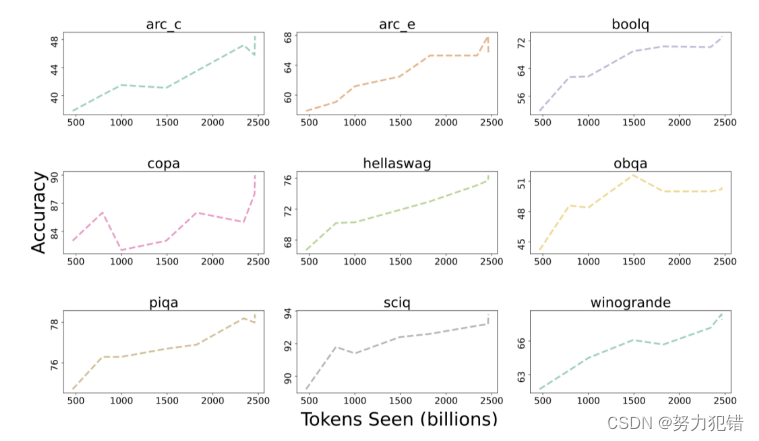
下图展示了9个核心任务准确率的变化趋势。
除了OBQA外,随着OLMo-7B接受更多数据的训练,几乎所有任务的准确率都呈现上升趋势。
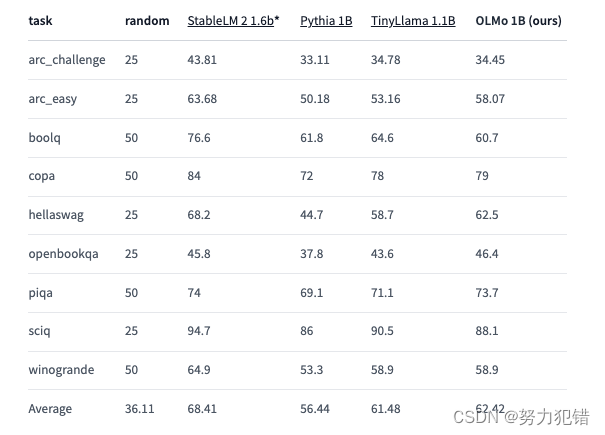
与此同时,OLMo 1B与其同类模型的核心评估结果表明,OLMo与它们处于同一水平。
开源带来的影响
OLMo的全面开源,不仅为AI研究提供了宝贵的资源,还有助于降低研究和开发的门槛,推动AI技术的创新和发展。通过这种开放的模式,研究人员可以更深入地探索AI模型的内部运作机制,共同推动语言模型科学的进步。
结论
OLMo的发布,标志着AI开源模型进入了一个新的时代。随着越来越多的研究机构和企业加入到开源的行列,我们有理由相信,未来的AI技术将更加开放、透明和创新。
模型下载
Huggingface模型下载
https://huggingface.co/allenai/OLMo-7B
AI快站模型免费加速下载
https://aifasthub.com/models/allenai
这篇关于100%开源大模型OLMo:代码/权重/数据集/训练全过程公开,重定义AI共享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






