权重专题


推荐模型-上下文感知-2015:FFM模型【在FM基础上引入特征域】【每个特征对应的不是唯一一个隐向量权重,而是一系列,与每个特征域都计算出一个隐向量权重】【FM:O(kn);FFM:O(knf)】
Yuchin Juan et al. “Field-aware Factorization Machines for CTR Prediction” in RecSys 2016. https://github.com/rixwew/pytorch-fm 2015年,Criteo基于FM提出的FFM在多项CTR预估大赛中夺魁,并被Criteo、美团等公司深度应用在推荐系统、CTR预估等领域。

AI芯片:Edge TPU(谷歌出品)【在边缘(edge)设备上运行的“专用集成芯片”】【量化操作:Edge TPU使用8 位权重进行计算,而通常使用32位权重。所以我们应该将权重从32位转换为8位】
谷歌Edge TPU的价格不足1000人民币,远低于TPU。实际上,Edge TPU基本上就是机器学习的树莓派,它是一个用TPU在边缘进行推理的设备。 一、云vs边缘 1、边缘运行没有网络延迟 Edge TPU显然是在边缘(edge)运行的,但边缘是什么呢?为什么我们不选择在云上运行所有东西呢? 在云中运行代码意味着使用的CPU、GPU和TPU都是通过浏览器提供的。边缘与云相反,即在

深度学习100问45:什么是权重共享
嘿,来认识一下权重共享吧! 想象一下有一群小机器人在干同一件活儿。要是每个小机器人都有自己独一无二的工具(权重),那可就乱套啦,而且还很浪费资源呢。权重共享呢,就像是让这些小机器人共用一套工具。 在一些模型里,比如卷积神经网络,就像有一群小侦探在检查图片。对于图片的不同地方,都用同样的“小魔法棒”(卷积核,也就是一组权重)。这就意味着,在处理图片不同部分的时候,都有着相同的识别本事。比如说

SEO之网站结构优化(十四-内部链接及权重分配2)
初创企业搭建网站的朋友看1号文章;想学习云计算,怎么入门看2号文章谢谢支持: 1、我给不会敲代码又想搭建网站的人建议 2、“新手上云”能够为你开启探索云世界的第一步 博客:阿幸SEO~探索搜索排名之道 4、翻页过多 稍大型的商务或信息类网站都可能会在产品列表,也就是最末一级的分类页面上,存在翻页过多的问题。通常产品列表会显示10个或20个产品,然后列出翻页链接,除了“上一页”和“下一页

优化TextRank文本摘要,自定义关键词增加句子的权重
关于textRank的原理,我这边就不多介绍了,搜一下很多,我也不确定自己是否讲的有那些大佬清楚,我们主要关注在优化点 痛点: 最近在做文章的摘要项目,一天的摘要量估计在300万篇左右,所以直接放弃了seq2seq的生成时摘要方法,主要还是使用深度学习,速度和精度都达不到要求了。采用textrank是一种解决办法 1. 目前使用FastTextRank, 速度上基本达到了要求, githu

Pytorch实现多层LSTM模型,并增加emdedding、Dropout、权重共享等优化
简述 本文是 Pytorch封装简单RNN模型,进行中文训练及文本预测 一文的延申,主要做以下改动: 1.将nn.RNN替换为nn.LSTM,并设置多层LSTM: 既然使用pytorch了,自然不需要手动实现多层,注意nn.RNN和nn.LSTM 在实例化时均有参数num_layers来指定层数,本文设置num_layers=2; 2.新增emdedding层,替换掉原来的nn.funct
数学建模学习(128):使用Python结合CILOS与熵法的多准则决策权重确定
本文介绍方法为:结合CILOS与熵法的多准则决策权重,请理解为主,代码可以当作模板使用。 文章目录 1 引言2 问题背景2.1. 熵法 (Entropy Method)2.2 准则影响损失法 (CILOS Method)2.3 Python代码实现2.4 结果的决策指导意义 2.4 结论 参考文献 1 引言 多准则决策(Multi-Criteria Decision-M
![动手学深度学习(pytorch)学习记录15-正则化、权重衰减[学习记录]](https://i-blog.csdnimg.cn/direct/0f95ecb887cb4ea48b40a36df67ce36a.png)
动手学深度学习(pytorch)学习记录15-正则化、权重衰减[学习记录]
我们可以通过收集更多的训练数据来缓解过拟合,但这可能成本很高,耗时很多或完全失去控制,在短期内难以做到。 假设已经有了足够多的数据,接下来将重点放在正则化技术上。 权重衰减是使用最广泛的正则化技术之一,它通常也被称为L2正则化 技术方法:通过函数与零之间的距离来度量函数的复杂度; 如何精确测量这种‘距离’? 一个简单的方法是通过线性函数f(x)=w^(T) x 中权重向量的某个范数(如||w||

java权重随机算法
Pair: package com.ruoyi.receipt.domain;/*** 表示选项和权重的类Pair*/public class Pair {Object item;double weight;public Pair(Object item, double weight) {this.item = item;this.weight = weight;}public Object
基于偏好启发的权重共生进化算法
论文信息 原始英文题目:Preference-inspired co-evolutionary algorithms using weight vectors 英文关键词:Evolutionary algorithms, Multi-objective optimisation, Many-objective, Co-evolution, Weights 中文题目:基于偏好启发的权重共生进化算法

怎么写出1688高权重标题,新手老板看这篇就够了!
标题是获取自然搜索流量的重要秘籍。可以说一个好标题=好的流量!顾客搜索产品关键词,你的品能更靠前,获得更多的展现和流量。 命名规则 通用公式、品牌词、核心词、类目词、属性词,相应的进行整合。给大家分享3种我常用的高曝光标题组合,直接抄作业拿走! a、品牌词+类目词+核心词+属性词 基础商品信息组合,利用品牌效应,获取精准流量 示例:A品牌2022夏新款个性西装连衣裙甜酷女 b、营销词

solr - defType - 查询权重排序
Solr的defType有dismax/edismax两种,这两种的区别,可参见:http://blog.csdn.net/duck_genuine/article/details/8060026 下面示例用于演示如下场景: 有一网站,在用户查询的结果中,需要按这样排序: VIP的付费信息需要排在免费信息的前头点击率越高越靠前发布时间越晚的越靠前 这样的查询排序使用

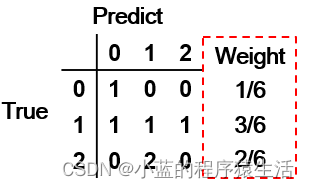
多分类问题中评价指标F1-Score 加权平均权重的计算方法
多分类问题中评价指标F1-Score 加权平均权重的计算方法 众所周知,F1分数(F1-score)是分类问题的一个衡量指标。在分类问题中,常常将F1-score作为评价分类结果好坏的指标。它是精确率和召回率的调和平均数,值域为[0,1]。 F 1 = 2 ∗ P ∗ R P + R F_1=2*\frac{P*R}{P+R} F1=2∗P+RP∗R 其中,P代表着准确率(
全球首个开源类Sora模型大升级,16秒720p画质电影感爆棚!代码和权重全面开源!
目录 01 视频界开源战士 02 深度解码技术 03 打破闭环,开源赋能 潞晨Open-Sora团队刚刚在720p高清文生视频质量和生成时长上实现了突破性进展! 全新升级的Open-Sora不仅支持无缝生成任意风格的高质量短片,更令人惊喜的是,团队选择继续全部开源。 GitHub地址:https://github.com/hpcaitech/Open-Sora

DL基础补全计划(四)---对抗过拟合:权重衰减、Dropout
PS:要转载请注明出处,本人版权所有。 PS: 这个只是基于《我自己》的理解, 如果和你的原则及想法相冲突,请谅解,勿喷。 环境说明 Windows 10VSCodePython 3.8.10Pytorch 1.8.1Cuda 10.2 前言 在《DL基础补全计划(三)—模型选择、欠拟合、过拟合》( https://blog.csdn.net/u011728480/article/d
TF-IDF算法:揭秘文本数据的权重密码
TF-IDF算法:揭秘文本数据的权重密码 在信息爆炸的时代,如何从海量的文本数据中提取出有价值的信息,是自然语言处理(NLP)领域面临的重要挑战之一。而TF-IDF算法,作为一种经典的文本加权技术,为我们提供了一种有效的解决方案。本文将深入解析TF-IDF算法的原理、应用以及Python实现,旨在帮助读者更好地理解和运用这一强大的工具。 一、TF-IDF算法简介 TF-IDF(Term Fr
联邦学习的基本流程,联邦学习权重聚合,联邦学习权重更新
目录 联邦学习的基本流程是 S_t = np.random.choice(range(K), m, replace=False) 联邦学习权重聚合 model.state_dict() 联邦学习权重更新 下载数据集 https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz 联邦学
java按权重随机算法
/*** @Description 方法描述:权重随机* @author leon 2018年1月26日 下午3:54:32* @CopyRight leon* @param map* @return*/public static String weightRandom(Map<String, String> map) {Set<String> keySet = map.keySet();Lis

网站主页权重提升外加二级栏目助力
网站主页权重提升外加二级栏目助力 文章目录 前言一、打造合理的网站结构,巧用二级栏目提示主页权重。二、用二级栏目给主页引权重的一些好处。三、内外配合让主页权重达到最佳效果。四、案例分析,有了成功才有了方法。总结 前言 每位做站的朋友都知道,一个网站有好的权重好的排名与自己网站的域名息息相关,通常一个内容不错,并且在外界曝光率较高的网站,在搜索引擎当中 都能够获得不错的排名
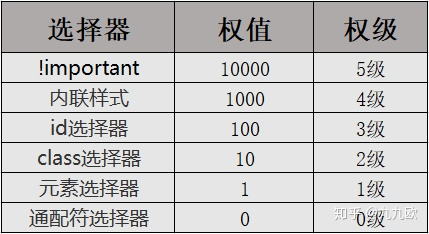
浅谈CSS权重计算规则
- [1. CSS权重计算规则](#1-css权重计算规则)- [1.1. 权重计算规则:](#11-权重计算规则) 1. CSS权重计算规则 1.1. 权重计算规则:1.2. 权重计算基于以下几点原则: 1.2.1. 重要性声明 (!important):1.2.2. 内联样式:1.2.3. 选择器类型:1.2.4. 计算规则: 2. 举例说明CSS权重计算规则 1. CSS权重计算规则

从反向传播过程看激活函数与权重初始化的选择对深度神经网络稳定性的影响
之前使用深度学习时一直对各种激活函数和权重初始化策略信手拈用,然而不能只知其表不知其里。若想深入理解为何选择某种激活函数和权重初始化方法卓有成效还是得回归本源,本文就从反向传播的计算过程来按图索骥。 为了更好地演示深度学习中的前向传播和反向传播,有必要图文结合,先按下面这个计算图造些数据。 这是一个输入只有单个样本、包含两个特征,两个隐藏层、分别带有2个神经元,以及一个输出的三层全

自养号测评防关联的关键点解析, 确保店铺权重和买家账号的安全稳定
现在很多大卖都是自己管理几百个账号,交给服务商不是特别靠谱。你不知道服务商账号质量怎么样,账号一天下了多少你也不清楚,如果下了很多单万一封号被关联了怎么办,你也不知道服务商用什么卡给你下单,用一些低汇率和黑卡下单, 会不会恶意给你退款。 自学测评的优势 1.成本低廉:一个买家账号的注册成本几毛钱就够了,且可长期使用。卖家可以根据自身需求控制测评的时间和数量,一个设备即可养育无限数量的账
【深度学习笔记3.1 正则化】权重衰减(weight decay)
权重衰减是什么?参考有关文献 这里参考文献[1]整理成如下代码:(详见文献[5]regularization/WeightDecay.py) import numpy as npimport tensorflow as tffrom matplotlib import pyplot as pltn_train = 20n_test = 100num_inputs = 200true_w
CSS的一些基础样式,继承性权重问题
一些基础小样式 shortcut icon,特指浏览器中地址栏左侧显示的图标,一般大小为16x16,后缀名为.icon; icon,指的是图标,格式可为PNG\GIF\JPEG,尺寸一般为16x16、24x24、36x36等 line-height:行高 设置文字间上下距离 height:高度 就是定义一个层 或某样东西的高度啦 也就是说line-height是特指单行高度,height